
- 12024华数杯数学建模A题完整论文讲解(含每一问python代码+结果+可视化图)
- 224.8.2数据结构|双链表
- 3Python3智联招聘网爬虫学习_北京雅正创意品牌科技有限公司
- 4玄机——第九章-查杀linux挖矿病毒 kswapd0(应急响应) wp_linux kswapd0
- 5Windows安装了pnpm后无法在Vscode中使用
- 6论文解读《基于伪标签自训练的局部对比损失半监督医学图像分割》_local contrastive loss with pseudo-label based sel
- 7可视采耳设备哪个品牌好?五大实力出众产品安利
- 8数据结构与算法(1)——动态规划_动态规划法数据结构与算法描述
- 9SQL Server2000 索引结构及其使用_sqlsever2000 列存储索引作用
- 10Redis服务器配置-RDB持久化_redis的服务器地址
图解大模型计算加速系列:vLLM源码解析1,整体架构_vllm的重要传参有哪些
赞
踩
大家好,这段时间精读了一下vLLM源码实现,打算开个系列来介绍它的源码,也把它当作我的总结和学习笔记。
整个vLLM代码读下来,给我最深的感觉就是:代码呈现上非常干净历练,但是逻辑比较复杂,环环嵌套,毕竟它是一个耦合了工程调度和模型架构改进的巨大工程。
所以在源码解读的第一篇,我想先写一下对整个代码架构的介绍。**在本篇中,我特意少涉及对源码本身的解读,而是把源码中的信息总结出来,配合图例先做整体介绍。**如果你不想阅读源码细节,但又想对vLLM代码有整体把握,方便后续能知道从哪里查bug的话,这篇文章或许可以帮到你。如果你后续想更深入阅读源码的话,这篇文章可以作为一个引子,后续的细节解读都将在本文的基础上扩展开。
阅读本文前,建议先看vLLM原理篇讲解。
话不说,进入正文吧~
【如果本文有帮助,欢迎大家点赞、收藏和在看~】
一、调用vLLM的两种方式
根据vLLM的官方文档,它向用户提供了两种调用它的方法,分别是:
-
Offline Batched Inference(同步,离线批处理)
-
API Server For Online Serving(异步,在线推理服务),在这下面又提供了2种支持的API类型:
-
OpenAI-Compatible API Server(官方推荐):兼容了OpenAI请求格式的server,包括OpenAI Completions API和OpenAI Chat API。
-
Simple Demo API Server(测试开发用,官方不推荐,相关脚本也不再维护)
**在代码实现上,vLLM首先实现了一个推理内核引擎(LLMEngine),在此基础上封装了上述两种调用方法。**在本系列的讲解中,我们会先以“offline bacthed inference”作为入口,详细解说内核引擎LLMEngine的各块细节。在此基础上我们再来看“online serving”的运作流程。
现在,让我们来看这两种调用方法的具体例子。
1.1 Offline Batched Inference
from vllm import LLM, SamplingParams # =========================================================================== # batch prompts # =========================================================================== prompts = ["Hello, my name is", "The president of the United States is", "The capital of France is", "The future of AI is",] # =========================================================================== # 采样参数 # =========================================================================== sampling_params = SamplingParams(temperature=0.8, top_p=0.95) # =========================================================================== # 初始化vLLM offline batched inference实例,并加载指定模型 # =========================================================================== llm = LLM(model="facebook/opt-125m") # =========================================================================== # 推理 # =========================================================================== outputs = llm.generate(prompts, sampling_params) # =========================================================================== # 对每一条prompt,打印其推理结果 # =========================================================================== for output in outputs: prompt = output.prompt generated_text = output.outputs[0].text print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
在传统离线批处理中,我们每次给模型发送推理请求时,都要:
-
等一个batch的数据齐全后,一起发送
-
整个batch的数据一起做推理
-
等一个batch的数据全部推理完毕后,一起返回推理结果
这种“团体间等成员到齐,再一起行动”的行为,就被称为“同步”。
在vLLM中,当我们使用离线批处理模式时,表面上是在做“同步”推理,也即batch_size是静态固定的。**但推理内核引擎(LLMEngine)在实际运作时,batch_size是可以动态变更的:在每一个推理阶段(prefill算1个推理阶段,每个decode各算1个推理阶段)**处理的batch size可以根据当下显存的实际使用情况而变动。
举个例子来说:
-
给定一个很大的batch,此时尽管vLLM采用了PagedAttention这样的显存优化技术,我们的gpu依然无法同时处理这么大的batch。
-
所以batch中的每一条数据,会被先放到一个waiting队列中。vLLM会用自己的调度策略从waiting队列中依次取数,加入running队列中,直到它认为取出的这些数据将会打满它为1个推理阶段分配好的显存。此时waiting队列中可能还会剩一些数据。
-
在每1个推理阶段,vLLM对running队列中的数据做推理。如果这1个推理阶段执行完毕后,有的数据已经完成了生成(比如正常遇到
<eos>了),就将这些完成的数据从running队列中移开,并释放它占据的物理块显存。 -
这时,waiting队列中的数据就可以继续append进running队列中,做下1个阶段的推理。
-
因此在每1个推理阶段,vLLM处理的batch size可能会动态变更。
-
将LLMEngine包装成离线批处理形式后,所有的数据必须等到一起做完推理才能返给我们。所以从体感上,我们可能很难感知到内核引擎的“动态”逻辑。
**以上是一个浅显粗暴的例子,目的是帮助大家理解“在vLLM中,即使是同步形式的离线批处理,其背后的内核引擎也是按动态batch的形式来实现的”,**实际的调度策略(Scheduler)要更加复杂,我们将在后续的解读中来具体看它。
也正是因为LLMEngine这种“动态处理”的特性,才使得它同时也能成为异步在线服务的内核引擎:当一条条请求发来时,它们都先进入LLMEngine调度器(Scheduler)的waiting队列中(实际并不是直接进入waiting队列中的,而是在传给LLMEngine前先进入asyncio.Queue()中,然后再由LLMEngine调度进waiting队列中的,这些细节我们也放在后面说,这里不影响理解就行)。此时模型正常执行它的1个推理阶段,调度器也正常处理新来的请求。当模型准备执行下1个推理阶段时,调度器再根据设定的策略,决定哪些数据可以进入running队列进行推理。由于在线服务是异步的,先推理完成的数据就可以先发给客户端了(如果采用流式传输,也可以生成多少先发多少)。
在这个过程中,vLLM通过PagedAttention技术和“先来先服务(FCFS),后来先抢占,gpu不够就先swap到cpu上”的调度策略,在1个推理阶段处理尽可能多的请求,解决高并发场景下的推理吞吐问题。这就是整个vLLM运作的核心思想。(对这行黑体字里的术语有疑惑的朋友,建议先看vLLM原理篇讲解)
1.2 API Server For Online Serving
# =========================================================================== # Server:起服务 # =========================================================================== $ python -m vllm.entrypoints.openai.api_server --model meta-llama/Llama-2-7b-hf # =========================================================================== # Client:发请求(OpenAI API) # =========================================================================== $ curl http://localhost:8000/v1/completions \ -H "Content-Type: application/json" \ -d '{ "model": "meta-llama/Llama-2-7b-hf", "prompt": "San Francisco is a", "max_tokens": 7, "temperature": 0 }'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
vLLM在实现在线服务时,采用uvicorn部署fastapi app实例,以此实现异步的请求处理。而核心处理逻辑封装在AsyncLLMEngine类中(它继承自LLMEngine)。所以,只要我们搞懂了LLMEngine,对vLLM的这两种调用方式就能举一反三了。
1.3 总结
vLLM的两种调用方式与内核引擎LLMEngine的关系如下(图片来自vLLM团队2023 first meetup PPT):
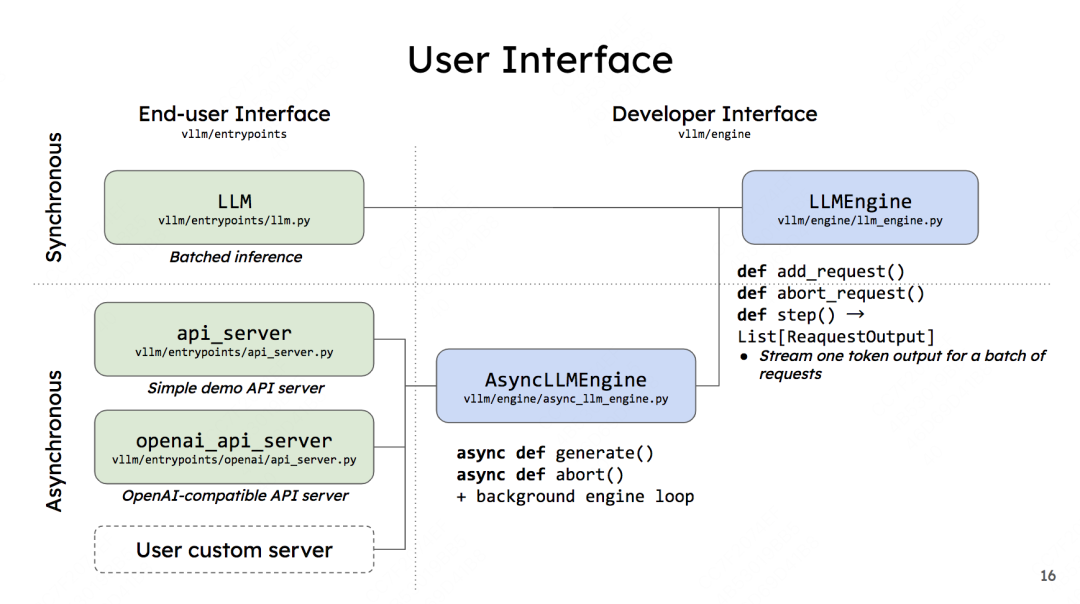
图中左侧是用户使用界面,罗列了上述所说的两种调用方式(注意,如前文所说,做demo用的api server官方已经不再维护了,openai_api_server才是官方推荐的使用方式,user custom server目前还没有实现)。右侧则是开发者界面,不难发现LLMEngine是vLLM的核心逻辑。
我们来看开发者界面下的几个函数,先来看LLMEngine:
-
add_request():该方法将每一个请求包装成vLLM能处理的数据类型(SequenceGroup,后面我们会详细解释),并将其加入调度器(Scheduler)的waiting队列中。在LLMEngine中,这个函数是按照“同步”的方式设计的,也就是它被设计为“遍历batch中的每条数据,然后做相应处理”。所以这个函数本身只适合批处理场景。在异步的online serving中将会把它重写成异步的形式。 -
abort_request:在推理过程中,并不是所有的请求都能有返回结果。比如客户端断开连接时,这个请求的推理就可以终止了(abort),这个函数就被用来做这个操作。 -
step():**负责执行1次推理过程(1个prefill算1个次推理,每个decode各算1次推理)。**在这个函数中,vLLM的调度器会决定要送那些数据去执行本次推理,并负责给这些数据分配好物理块(这些信息都被作为metadata放在要送给模型做推理的数据中)。模型会根据这些信息,采用PagedAttention方法,实际完成推理。
AsyncLLMEngine下的函数也是同理类推,这里不赘述了。
从上面的解读你可能发现了,其实只要掌握了add_request()和step()这两个函数,就等于掌握LLMEngine的全部思想了!于是你兴奋地打开这两个函数,发现它们的实现代码只有十几行,你突然感觉自己好像是去项羽那吃席的刘邦,因为你渐渐发现:
背后有万行代码逻辑正在等你


Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

