
- 12024-06-21 问AI: 在大语言模型中,什么是LLama Index
- 2域名注册后能改吗?
- 3git 如何回滚到某个节点_git回退到指定节点
- 4Java性能优化面试题汇总_java程序性能优化题目及答案
- 5【理论学习】Vision-Transformer_vision transformer多头注意力公式
- 6ActiveMQ,RocketMQ,RabbitMQ,Kafka区别对比_kafka、activemq、rabbitmq、rocketmq 有 什么优缺点?
- 7HuggingFace中模型量化_huggingface 量化int8
- 8数据结构:树(Tree)【详解】_数据结构 树
- 9Job的任务执行流程之JobCleanup阶段
- 10微信小程序自定义导航栏 胶囊菜单按钮高度完美适配_微信自定义导航栏
NLP基础任务—序列标注任务_nlp数据标注任务
赞
踩
资源下载地址:https://download.csdn.net/download/sheziqiong/86178744
资源下载地址:https://download.csdn.net/download/sheziqiong/86178744
一、思路
本次要完成 nlp 四大基础任务之一的序列标注任务,也叫做命名实体识别。即是在给定文本中能够对词性、人名地名等特定信息进行标注。
实验主要采用循环神经网络进行搭建,每一条样本输入是一条句子(对应的嵌入向量表示),该样本的标签也是一个等长的句子标签,其中每一个元素对应句子中每一个字的标签。如样本为‘我 爱 北 京’,则该样本的标签为‘O O B-LOC I-LOC’。然后通过循环神经网络再结合交叉熵损失函数进行训练。但根据课上所学知识,我们知道直接用 LSTM 虽然可以完成该任务,但是往往会预测出现一些不可能真实存在的结果,如连续两个 B-LOC 标签。因此我们可以增加条件随机场 CRF 模型在 LSTM 层之后,使用梯度下降自动去学习 CRF 模型的参数,这样可以获得比只使用 LSTM 好的结果。
二、模型概况
| Input() |
|---|
| Embedding(input_dim=5000, output_dim=50) |
| BiLSTM(units=100) |
| BiLSTM(units=150) |
| CRF(units=7) |
三、编程实现
为了实现上述模型我们首先需要对输入进行处理。首先使用 Tokenizer 库进行分词,词典大小设置为 5000,之后对训练样本进行padding(这里选择 maxlength进行padding),之后对标签也要做相应的 padding(这里 padding 的内容直接选用 O 标签)。
使用 keras 库进行模型的搭建,堆叠型模型声明如下

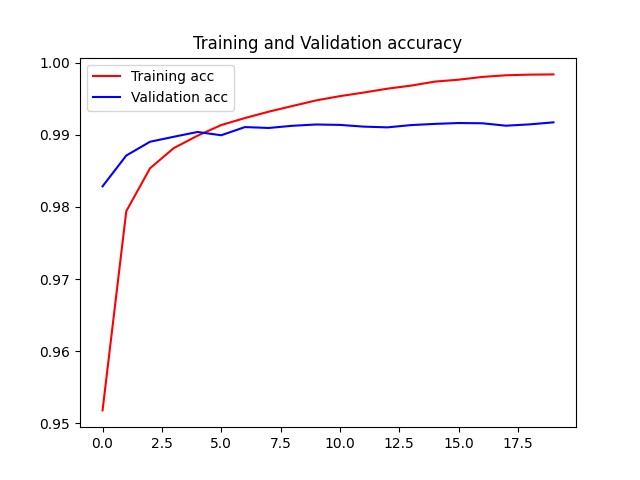
优化器选用 Adam,损失函数使用稀疏交叉熵,batchsize 设为 128,训练 20 轮。之后用训练好的模型,在测试集上测试即可。 www.biyezuopin.vip
四、实验结果
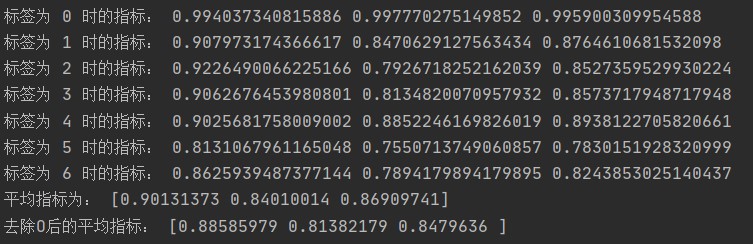
1.两层双向 LSTM 结果:
| O | B-LOC | I-LOC | B-PER | I-PER | B-ORG | I-ORG | |
|---|---|---|---|---|---|---|---|
| Precision | 0.9940 | 0.9080 | 0.9226 | 0.9063 | 0.9026 | 0.8131 | 0.8626 |
| Recall | 0.9978 | 0.8471 | 0.7927 | 0.8135 | 0.8852 | 0.7551 | 0.7894 |
| F1 | 0.9959 | 0.8765 | 0.8527 | 0.8574 | 0.8938 | 0.7830 | 0.8244 |
| With ‘O’ | Without ‘O’ | |
|---|---|---|
| Macro-precision | 0.9013 | 0.8859 |
| Macro-recall | 0.8401 | 0.8138 |
| Macro-f1 | 0.8691 | 0.8480 |
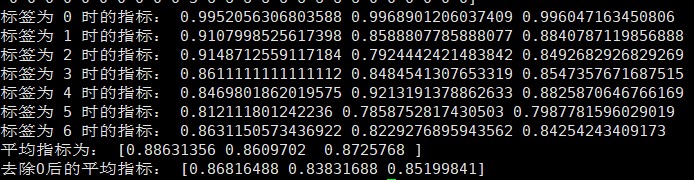
2.三层双向 LSTM 结果,效果提升不明显
| With ‘O’ | Without ‘O’ | |
|---|---|---|
| Macro-precision | 0.8863 | 0.8682 |
| Macro-recall | 0.8610 | 0.8383 |
| Macro-f1 | 0.8726 | 0.8520 |
资源下载地址:https://download.csdn.net/download/sheziqiong/86178744
资源下载地址:https://download.csdn.net/download/sheziqiong/86178744

