
- 1下载vue.min.js_vue.min.js下载
- 2平方数键值对-第11届蓝桥杯国赛Python真题精选_输入一个正整数n,将1到n之间所有正整数(包含1和n)作为python字典的键,将正整数的
- 3解决visio卡顿问题,亲测有效
- 4HCIA-AI华为认证AI工程师在线课程——人工智能技术概述_华为hcia-ai
- 5linux操作系统进程阻塞原理_操作系统如何做到进程阻塞的
- 6Python 简单使用 RabbitMQ
- 7什么是PriorityQueue优先级队列,使用PriorityQueue建立大顶堆和小顶堆_java priorityqueue大顶堆
- 8华为c语言技术面试问题大全,C语言面试题大汇总之华为面试题
- 9Android开发技巧:AndroidWiFiADB-无线调试工具_无线调试github
- 10订了吗
python nlp_将Python用于NLP:Pattern 库简介
赞
踩
Python部落(python.freelycode.com)组织翻译,禁止转载,欢迎转发。
这是我有关使用Python进行自然语言处理系列文章中的第八篇。在上一篇文章中,我解释了如何使用Python的TextBlob库来执行各种NLP任务,从分词到词性标注,从文本分类到情感分析。在本文中,我们将探索Python的Pattern库,这是另一个非常有用的自然语言处理库。
Pattern库是一个多用途的库,它可以处理以下任务:
自然语言处理: 执行诸如标记、词干提取、词性标注、情感分析等任务。
数据挖掘: 它包含从Twitter、Facebook、Wikipedia等网站挖掘数据的API。
机器学习: 它包含SVM、KNN、感知机等机器学习模型,可用于分类、回归和聚类任务。
在本文中,我们将看一下上述列表中关于Pattern库用途的前两个的应用实例。我们将通过执行标记、词干提取和情感分析等任务来探索用于NLP的Pattern库的用法。我们还将看到如何将Pattern库用于web数据挖掘。
安装
你可以使用以下pip命令来安装这个库:

或者,如果你使用的是Python的Anaconda发布版的话,你可以使用以下Anaconda命令去下载这个库:

用于NLP的Pattern 库函数
在本节,我们将看一些Pattern库的NLP应用实例。
标记, 词性标注,和分块
在NLTK和spaCy库中,我们有一个单独的函数用于标记、词性标注和在文本文档中查找名词短语。相反,在Pattern库中有一个多用途的parse方法,它接受一个文本字符串作为输入参数,并返回字符串中相应的标记和词性标注。
parse方法还会告诉我们一个标记是名词短语还是动词短语、主语还是宾语。你还可以通过将lemmata参数设置为True来检索词元化的标记。parse方法的语法以及不同参数的默认值如下:
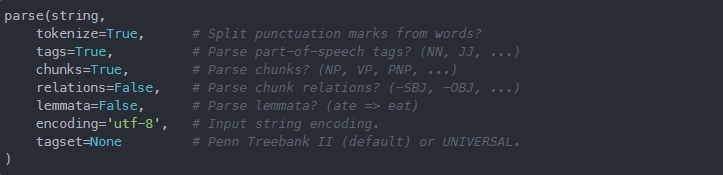
我们来实际查看一下 parse 方法:

要使用parse方法,你必须从pattern库导入en模块。en模块包含英语NLP函数。如果你使用pprint方法在控制台上打印parse方法的输出,你将会看到如下输出:
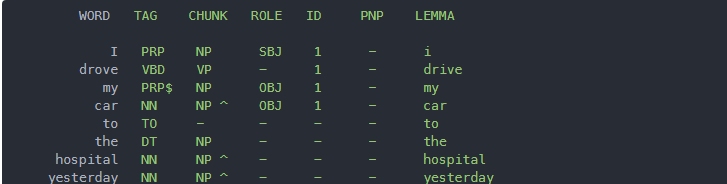
在输出中,你可以看到标记化的单词及其词性标注、该标记所属的块和角色。你还会看到这些标记的词元化形式。
如果你对parse方法返回的对象调用split方法,输出将是一个句子的列表,其中每个句子都是一个标记列表,每个标记都是一个单词列表,以及与单词关联的标记。
例如,看看下面的脚本:

上面脚本的输出如下:

复数化和单数化标记
pluralize 和 singularize 方法可分别用于将单数形式单词转换为复数形式,反之亦然。

