
热门标签
热门文章
- 1我30岁,软件工程师,年薪30万,辞职考公上岸,月薪4千_软件工程专业考公岗位工资
- 2Flutter 毛玻璃效果案例实现_flutter 实现毛玻璃效果
- 3python exec format error_Python Selenium chromedriver OSError:[Errno 8] Exec格式错误
- 4ActiveMq和RabbitMq区别及其解析_activemq rabbitmq区别
- 5【数据挖掘工程师-笔试】2022年SHEIN 公司_shein 牛客 数据分析
- 6国标GB/T28181视频转S3云存储,支持阿里云OSS、腾讯云COS、天翼云存储,视频转云存大大降低运营商项目运营成本_gb28181转s3云存储
- 7药物人必备科研技能!CADD计算机辅助药物设计联合AIDD人工智能药物发现+深度学习蛋白质设计
- 8JQuery+HTML+JavaScript:实现地图位置选取和地址模糊查询_百度地图坐标选择html
- 9ZXing 初步使用_zxing-js
- 10P71-前端基础项目开发-网页导航栏开发首页header头部左侧导航栏_左侧导航栏前端代码
当前位置: article > 正文
TF-IDF 统计算法介绍与代码实现_tf-idf代码
作者:小舞很执着 | 2024-08-06 12:32:23
赞
踩
tf-idf代码
目录
一、什么是TF-IDF?
一种统计方法,
用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
字词的重要性随着它在文件中出现的次数成正比增加,但随着它在语料库中出现的频率成反比下降。
TF-IDF实际上是:TF * IDF。主要思想是
:如果某个词或短语在一篇文章中出现的频率高(即TF高),并且在其他文章中很少出现(即IDF高),则认为此词或者短语具有很好的类别区分能力,适合用来分类。通俗理解TF-IDF就是:TF刻画了词语t对某篇文档的重要性,IDF刻画了词语t对整个文档集的重要性。

二、TF与IDF的计算
词频 (TF) 是一词语出现的次数除以该文件的总词语数。假如一篇文件的总词语数是100个,而词语“中国”出现了8次,那么“中国””一词在该文件中的词频就是8/100=0.08。一个计算文件频率 (IDF) 的方法是文件集里包含的文件总数除以测定有多少份文件出现过“中国””一词。所以,如果“中国””一词在1,000份文件出现过,而文件总数是10,000,000份的话,其逆向文件频率就是 lg(10,000,000 / 1,000)=4。最后的TF-IDF的分数为0.08 * 4=0.32。
下面是某篇文章中的解释:
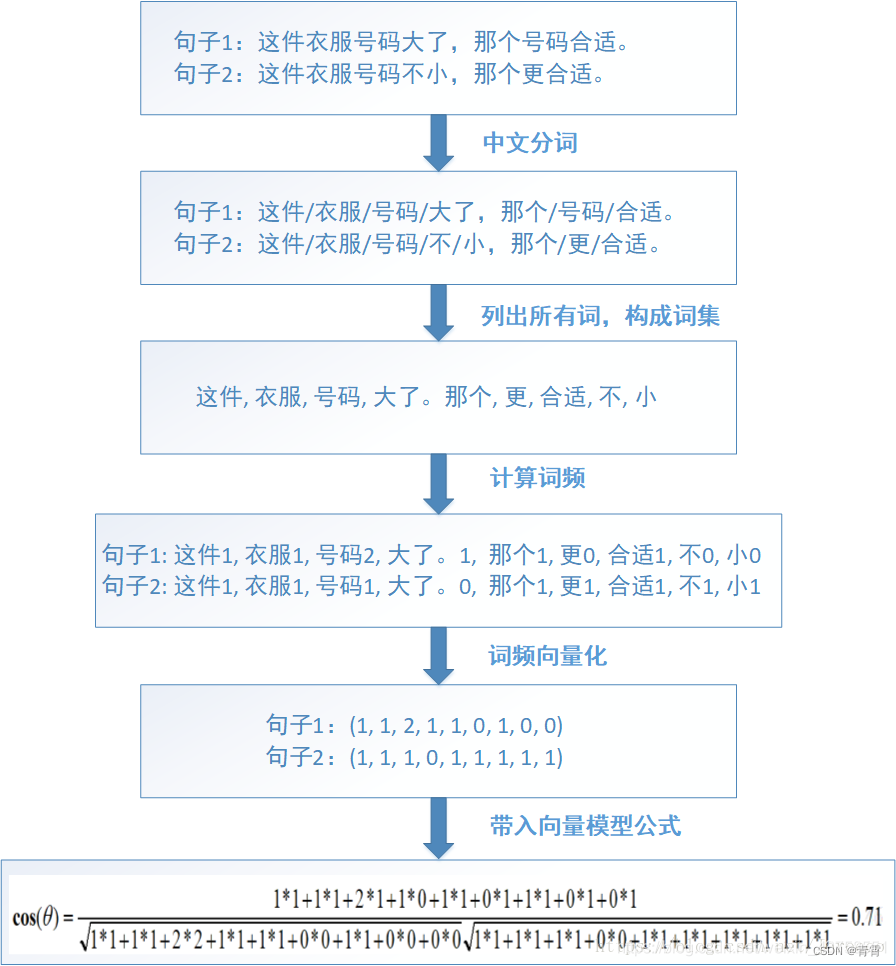
三、TF-IDF应用
-
搜索引擎,Elasticsearch的相关性得分_score
-
关键词提取
-
文本相似度
-
文本摘要
四、TF-IDF代码实现
4.1、初始实现
- import numpy as np
- import pandas as pd
- import math
- import jieba
-
- # 定义数据
- docA = "The cat sat on my bed"
- docB = "The dog sat on my knees"
- bowA = docA.split(" ") # list(jieba.cut(docA)) split适合英文语句分词,jieba更适用于中文语句分词
- bowB = docB.split(" ") # list(jieba.cut(docB)) # 关键词的提取可以使用jieba分词提取
-
- # 构建词库
- wordSet = set(bowA).union(set(bowB))
- print("wordSet:%s" % wordSet) # {'on', 'bed', 'cat', 'my', 'dog', 'The', 'knees', 'sat'}
-
- # 次数统计
- wordDictA = dict.fromkeys(wordSet, 0) # 用统计字典来保存词出现的次数
- wordDictB = dict.fromkeys(wordSet, 0)
- for word in bowA:
- wordDictA[word] += 1
- for word in bowB:
- wordDictB[word] += 1
- print("wordDictA:%s" % wordDictA) # {'bed': 1, 'The': 1, 'sat': 1, 'on': 1, 'my': 1, 'cat': 1, 'dog': 0, 'knees': 0}
- print("wordDictB:%s" % wordDictB) # {'bed': 0, 'The': 1, 'sat': 1, 'on': 1, 'my': 1, 'cat': 0, 'dog': 1, 'knees': 1}
-
- data_frame = pd.DataFrame([wordDictA, wordDictB])
- print("data_frame:\n%s" % data_frame)
- '''
- data_frame:
- bed The sat on my cat dog knees
- 0 1 1 1 1 1 1 0 0
- 1 0 1 1 1 1 0 1 1
- '''
-
-
- # 计算词频TF
- def compute_TF(word_dict, bow):
- """
- func:用一个字典对象记录tf,把所有的词对应在bow文档里的tf都算出来
- :param word_dict: 文件中的单词次数字典
- :param bow: 文件内容
- :return:
- """
- tf_dict = {}
- n_bow_count = len(bow)
- for word, count in word_dict.items():
- tf_dict[word] = count/n_bow_count
- return tf_dict
-
- tfA = compute_TF(wordDictA, bowA)
- tfB = compute_TF(wordDictB, bowB)
- print("tfA:%s, \ntfB:%s" % (tfA, tfB))
- '''
- tfA:{'dog': 0.0, 'cat': 0.16666666666666666, 'The': 0.16666666666666666, 'bed': 0.16666666666666666, 'sat': 0.16666666666666666, 'my': 0.16666666666666666, 'knees': 0.0, 'on': 0.16666666666666666},
- tfB:{'dog': 0.16666666666666666, 'cat': 0.0, 'The': 0.16666666666666666, 'bed': 0.0, 'sat': 0.16666666666666666, 'my': 0.16666666666666666, 'knees': 0.16666666666666666, 'on': 0.16666666666666666}
- '''
-
-
- # 计算逆文档频率IDF
- def compute_IDF(wordDictList):
- """
- func:用一个字典对象保存idf结果,每个词作为key,初始值为0
- :param wordDictList: 文件内容组成的列表
- :return:
- """
- idfDict = dict.fromkeys(wordDictList[0], 0)
- N = len(wordDictList)
- for wordDict in wordDictList:
- for word, count in wordDict.items():
- if count > 0:
- idfDict[word] += 1
- for word, ni in idfDict.items(): # {'dog': 1, 'on': 2, 'The': 2, 'bed': 1, 'sat': 2, 'knees': 1, 'cat': 1, 'my': 2}
- idfDict[word] = math.log10((N + 1) / (ni + 1))
- return idfDict
-
-
- idfs = compute_IDF([wordDictA, wordDictB])
- print("idfs:%s" % idfs) # {'dog': 0.17609125905568124, 'on': 0.0, 'The': 0.0, 'bed': 0.17609125905568124, 'sat': 0.0, 'knees': 0.17609125905568124, 'cat': 0.17609125905568124, 'my': 0.0}
-
-
- # 计算TF-IDF
- def compute_TFIDF(tf, idfs):
- tfidf = {}
- for word, tfval in tf.items():
- tfidf[word] = tfval * idfs[word]
- return tfidf
- tfidfA = compute_TFIDF(tfA, idfs)
- tfidfB = compute_TFIDF(tfB, idfs)
- result = pd.DataFrame([tfidfA, tfidfB])
- print("result:\n %s" % result)
- '''
- result:
- bed The my cat on knees sat dog
- 0 0.029349 0.0 0.0 0.029349 0.0 0.000000 0.0 0.000000
- 1 0.000000 0.0 0.0 0.000000 0.0 0.029349 0.0 0.029349
- '''
-
-
- # 余弦相似度,利用词频TF
- import scipy.spatial
- def cos(a, b):
- '''
- a和b都要是2维,a和b中的元素个数不定
- '''
- dis = scipy.spatial.distance.cdist(a, b, 'cosine')
- cos = 1 - dis[0]
- return cos
- a = np.array([list(wordDictA.values())])
- b = np.array([list(wordDictB.values())])
- print(cos(a, b)) # [0.66666667]
-

4.2、改写成类实现
- # https://baijiahao.baidu.com/s?id=1668933015186340529&wfr=spider&for=pc
-
- import numpy as np
- import pandas as pd
- import math
- import jieba
- import collections
- import scipy.spatial
-
-
- class TFIDF(object):
- def __init__(self, documents):
- self.document_list = documents
- self.word_dict_list = []
- self.word_set = set([word for doc in self.document_list for word in jieba.lcut_for_search(doc)]) # 构建词库
- print("self.word_set:%s" % self.word_set) # {'自古', '长存', '不朽', '中国'}
-
- def word_num(self):
- """
- func:次数统计
- """
- for doc in self.document_list:
- word_dict = dict.fromkeys(self.word_set, 0)
- bow = jieba.lcut_for_search(doc)
- for word in bow:
- word_dict[word] += 1
- self.word_dict_list.append(word_dict)
-
- data_frame = pd.DataFrame(self.word_dict_list)
- print("data_frame:\n%s" % data_frame)
-
- def compute_tf(self):
- """
- func:计算词频TF
- """
- tf_list = []
- for word_dict, document in zip(self.word_dict_list, self.document_list):
- tf_dict = {}
- n_bow_count = len(jieba.lcut_for_search(document))
- for word, count in word_dict.items():
- tf_dict[word] = count / n_bow_count # 某个词在单文件中的词频
- tf_list.append(tf_dict)
-
- tf_data_frame = pd.DataFrame(tf_list)
- print("tf_data_frame:\n%s" % tf_data_frame)
- return tf_list
-
- def compute_idf(self):
- """
- func:计算逆文档频率IDF.用一个字典对象保存idf结果,每个词作为key,初始值为0
- """
- N = len(self.document_list) # 语料库的文档总数
- idfDict = dict.fromkeys(self.word_dict_list[0], 0)
- for word_dict in self.word_dict_list:
- for word, count in word_dict.items():
- if count > 0:
- idfDict[word] += 1 # 某个词在多少份文档中出现
-
- for word, ni in idfDict.items():
- print("word:%s, N+1:%s, ni+1:%s" % (word, N+1, ni+1))
- idfDict[word] = math.log10((N + 1) / (ni + 1)) # log(语料库文档总数/(某个词在多少份文档中出现+1))
-
- print("idfDict:%s" % idfDict)
- return idfDict
-
- def compute_tdidf(self, tf_dict, idfs_dict):
- """
- 计算TF-IDF
- """
- tfidf = {}
- for word, tfval in tf_dict.items():
- tfidf[word] = tfval * idfs_dict[word]
- return tfidf
-
-
- # 定义数据
- docA = "中国自古长存"
- docB = "中国长存"
- docC = "中国自古长存不朽"
- # docA = "The cat sat on my bed"
- # docB = "The dog sat on my knees" # 分词用split
-
- document_list = [docA, docB, docC]
- tf_idf = TFIDF(document_list)
- tf_idf.word_num()
- tf_list = tf_idf.compute_tf()
- idf_dict = tf_idf.compute_idf()
-
- tf_idf_list = []
- for tf in tf_list:
- tdidf = tf_idf.compute_tdidf(tf, idf_dict)
- tf_idf_list.append(tdidf)
- tfidf_data_frame = pd.DataFrame(tf_idf_list)
- print("tfidf_data_frame:\n%s" % tfidf_data_frame)
-
-
- # 余弦相似度
- def cos_similarity(a, b):
- """
- a和b都要是2维,a和b中的元素个数不定
- """
- dis = scipy.spatial.distance.cdist(a, b, 'cosine')
- cos = 1 - dis[0]
- return cos
-
-
- # 利用词频TF
- array = [list(item.values()) for item in tf_list]
- cos_list = []
- for i in range(len(array) - 1):
- cos_list.append(cos_similarity([array[i]], array[i+1:]))
- print("余弦相似度:%s" % cos_list)
五、TF-IDF算法特点
TF-IDF算法实现简单快速,但是仍有许多不足之处:
(1)没有考虑特征词的位置因素对文本的区分度,词条出现在文档的不同位置时,对区分度的贡献大小是不一样的。
(2)按照传统TF-IDF,往往一些生僻词的IDF(反文档频率)会比较高、因此这些生僻词常会被误认为是文档关键词。
(3)传统TF-IDF中的IDF部分只考虑了特征词与它出现的文本数之间的关系,而忽略了特征项在一个类别中不同的类别间的分布情况。
(4)对于文档中出现次数较少的重要人名、地名信息提取效果不佳。
六、参考
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小舞很执着/article/detail/937436?site
推荐阅读

相关标签

