
- 1【sqlmap工具】Windows/Linux下载,使用方法、常用命令_sqlmap下载
- 2数据结构:(1)线性表
- 3学位论文重复率多少 ai写作_本科论文aigc不超过多少
- 4VS2019编译和使用gtest测试(C++)
- 5图像采集——OV5640摄像头简介、硬件电路及上电控制的Verilog代码实现并进行modelsim仿真
- 6如何将Python文件.py打包成.exe可执行程序(最简教程吗)_python封装成可执行的小程序
- 7Python下解决AttributeError: module ‘cv2.cv2‘ has no attribute ‘TrackerCSRT_create‘_attributeerror: module 'cv2' has no attribute 'obj
- 8第八章-PID 速度控制 PID控制 PID调参 PID温度控制 蓝桥杯 单片机 串级PID 模糊PID STM32f103c8t6最小系统板 STM32项目 STM32cubemx正点原子 江科大协_csdnpid速度控制
- 9生成对抗网络——GAN深度卷积实现(代码+理解)_卷积实现生成器和判别器
- 10【ArcGIS Pro二次开发】(42):GeometryEngine用法详解
Vision Transformer详解
赞
踩
论文名称: An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale
论文下载链接:https://arxiv.org/abs/2010.11929
原论文对应源码:https://github.com/google-research/vision_transformer
Pytorch实现代码: pytorch_classification/vision_transformer
Tensorflow2实现代码:tensorflow_classification/vision_transformer
在bilibili上的视频讲解:https://www.bilibili.com/video/BV1Jh411Y7WQ

目录
3.2 可学习的嵌入 (Learnable Embedding)
3.3 位置嵌入 (Position Embeddings)

ViT 动态示意图
摘要
虽然 Transformer 架构已成为 NLP 任务的事实标准,但它在 CV 中的应用仍然有限。在视觉上,注意力要么与卷积网络结合使用,要么用于替换卷积网络的某些组件,同时保持其整体结构。我们证明了这种对 CNNs 的依赖是不必要的,直接应用于图像块序列 (sequences of image patches) 的纯 Transformer 可以很好地执行 图像分类 任务。当对大量数据进行预训练并迁移到多个中小型图像识别基准时 (ImageNet、CIFAR-100、VTAB 等),与 SOTA 的 CNN 相比,Vision Transformer (ViT) 可获得更优异的结果,同时仅需更少的训练资源。
一、介绍
基于自注意力的架构,尤其是 Transformer,已成为 NLP 中的首选模型。主要方法是 在大型文本语料库上进行预训练,然后在较小而特定于任务的数据集上进行微调。 由于 Transformers 的计算效率和可扩展性,训练具有超过 100B 个参数的、前所未有的模型成为了可能。随着模型和数据集的增长,仍未表现出饱和的迹象。
然而,在 CV 中,卷积架构仍然占主导地位。受到 NLP 成功的启发,多项工作尝试将类似 CNN 的架构与自注意力相结合,有些工作完全取代了卷积。后一种模型虽然理论上有效,但由于使用了特定的注意力模式,尚未在现代硬件加速器上有效地扩展。因此,在大规模图像识别中,经典的类 ResNet 架构仍是最先进的。
受 NLP 中 Transformer 成功放缩/扩展 (scaling / scale up) 的启发,我们尝试将标准 Transformer 直接应用于图像,并尽可能减少修改。为此,我们 将图像拆分为块 (patch),并将这些图像块的线性嵌入序列作为 Transformer 的输入。图像块 (patches) 的处理方式同 NLP 的标记 (tokens) (故经过线性嵌入后又叫 patch token)。我们以有监督方式训练图像分类模型。
当在没有强正则化的中型数据集(如 ImageNet)上进行训练时,这些模型产生的准确率比同等大小的 ResNet 低几个百分点。 这种看似令人沮丧的结果可能是意料之中的:Transformers 缺乏 CNN 固有的一些归纳偏置 (inductive biases) —— 如 平移等效性 和 局部性 (translation equivariance and locality),因此在数据量不足时,训练不能很好地泛化。
但若在更大的数据集 (14M-300M 图像) 上训练,情况就会发生变化。我们发现 大规模训练 胜过 归纳偏置。Vision Transformer (ViT) 在以足够的规模进行预训练并迁移到具有较少数据点的任务时获得了出色结果。当在公共 ImageNet-21k 数据集或内部 JFT-300M 数据集上进行预训练时,ViT 在多个图像识别基准上接近或击败了最先进的技术。特别是,最佳模型在 ImageNet 上的准确率达到 88.55%,在 ImageNet-RealL 上达到 90.72%,在 CIFAR-100 上达到 94.55%,在 19 个任务的 VTAB 上达到 77.63%。
二、相关工作
Transformers 是由 Vaswani 等人提出的 机器翻译 方法,并已成为许多 NLP 任务中的 SOTA 方法。基于大型 Transformers 的模型通常在大型语料库 (corpus) 上预训练,然后根据所需的下游任务 (down-stream tasks) 进行微调 (finetune)。注意,BERT 使用 去噪自监督 预训练任务,而 GPT 系列使用 语言建模 (LM) 作为预训练任务。
应用于图像的简单自注意力要求 每个像素关注所有其他像素。由于像素数量的二次方成本,其无法放缩到符合实际的输入尺寸。因此,曾经有研究者尝试过几种近似方法 以便于在图像处理中应用 Transformer。Parmar 等人只在每个 query 像素的局部邻域而非全局应用自注意力,这种局部多头点积自注意力块完全可以代替卷积。在另一种工作中,稀疏 Transformer 采用可放缩的全局自注意力,以便适用于图像。衡量注意力的另一种方法是将其应用于大小不同的块中,在极端情况下仅沿单个轴。许多这种特殊的注意力架构在 CV 任务上显示出很好的效果,但是需要在硬件加速器上有效地实现复杂的工程。
与我们最相关的是 Cordonnier 等人的模型,该模型从输入图像中提取 2×2 大小的块,并在顶部应用完全的自注意力。该模型与ViT 非常相似,但我们的工作进一步证明了 大规模的预训练使普通的 Transformers 能够与 SOTA 的 CNNs 竞争 (甚至更优)。此外,Cordonnier 等人使用 2×2 像素的小块,使模型只适用于小分辨率图像,而我们也能处理中分辨率图像。
将 CNN 与自注意力的形式相结合有很多有趣点,例如增强用于图像分类的特征图,或使用自注意力进一步处理CNN 的输出,如用于目标检测、视频处理、图像分类,无监督目标发现,或统一文本视觉任务。
另一个最近的相关模型是图像 GPT (iGPT),它在降低图像分辨率和颜色空间后对图像像素应用 Transformers。该模型以无监督的方式作为生成模型进行训练,然后可以对结果表示进行微调或线性探测以提高分类性能,在 ImageNet 上达到 72% 的最大精度。
我们的工作增加了在比标准 ImageNet 数据集更大尺度上探索图像识别的论文的数量。使用额外的数据源可以在标准基准上取得 SOTA 的成果。此外,Sun 等人研究了 CNN 性能如何随数据集大小而变化,Kolesnikov、Djolonga 等人从 ImageNet-21k 和JFT-300M 等大规模数据集对 CNN 迁移学习进行了实证研究。我们也关注后两个数据集,但是是训练 Transformers 而非以前工作中使用的基于 ResNet 的模型。
三、方法
在模型设计中,我们尽可能地遵循原始 Transformer (Vaswani 等, 2017)。 这种有意简单设置的优势在于,可扩展的 NLP Transformer 架构及其高效实现几乎可以开箱即用。
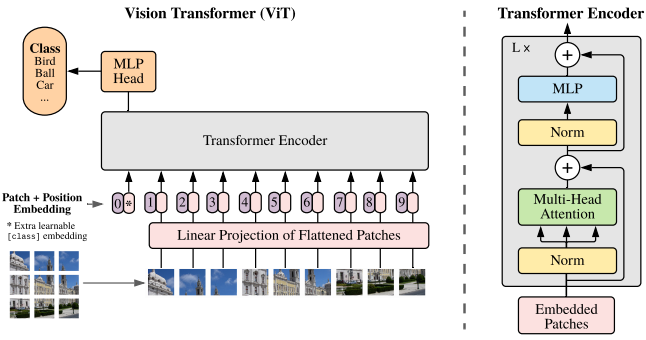
Figure 1: Model overview. We split an image into fifixed-size patches, linearly embed each of them, add
position embeddings, and feed the resulting sequence of vectors to a standard Transformer encoder. In order
to perform classifification, we use the standard approach of adding an extra learnable “classifification token”
to the sequence. The illustration of the Transformer encoder was inspired by Vaswani et al. (2017).
3.1 图像块嵌入 (Patch Embeddings)
该模型的概述如图 1 所示。标准 Transformer 使用 一维标记嵌入序列 (Sequence of token embeddings) 作为输入。
为处理 2D 图像,将图像 x∈RH×W×C
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

