
热门标签
热门文章
- 1【代码随想录训练营】【Day 41】【动态规划-1 and 2】| Leetcode 509, 70, 746, 62, 63
- 2拼写单词_有一个字符串数组words和一个字符串chars。 假如可以用chars中的字母拼写出words
- 3植物大战僵尸中文版修改器python实现_植物大战僵尸main修改
- 4给定平面上的n个点,求最多有多少个点共线_如何求共线次数
- 5失败了n次以后,我总结了5种Python爬虫伪装技巧!_python爬虫伪装成浏览器
- 6Java——TCP/IP超详细总结
- 7js日历库_js 计算日历的库
- 8【C/C++ 数据结构 】线索二叉树全解析:从数学原理到C++实现_索二叉树的应用场景 线索二叉树在需要频繁进行中序遍历的场景下非常有
- 9循环队列的定义,入队算法,出队算法,遍历算法,及其代码实现_循环队列入队和出队算法
- 10数据库课程设计(医院数据库系统)_医院管理系统数据库设计
当前位置: article > 正文
【一致性】redis+DB一致性如何保证? 从Cache Expiry到Double Delete双重删除
作者:小惠珠哦 | 2024-07-06 19:25:20
赞
踩
double delete
先提个问题,你们觉得 4个9(99.99%)的数据一致性 SLA Service Level Agreement是不是很高?但对于像 AWS S3这样的成熟服务,数据 SLA 高达11个9这的确很惊人;每增加一个9,其实现的难度和复杂性会呈指数级增长,因此对于创业公司基本上没有资源来维护非常高的 SLA。
名词解释:
- 【一致性】:缓存和数据库数据之间的一致性。
- 【SLA】:Service Level Agreement
- 【TAO】:TAO 是一个分布式缓存,具有非常高的 SLA (10个9)。然而,要操作这样一个服务,其背后有一个非常复杂的体系结构,甚至对缓存的监视也是非常大的,这对于普通公司来说是负担不起的。
1. 为什么要用缓存呢?直接数据库不行吗?原因有三点如下:
- 首先:数据库的价格很高。为了提供数据持久性和尽可能多的高可用性,即使是关系数据库也提供了 ACID 保证,这使得数据库的实现变得复杂,也消耗了硬件资源。无论是硬盘驱动器、内存还是 CPU,数据库都必须得到良好的硬件规范的支持才能正常工作,这也导致了数据库本身的高昂价格。
- 其次:数据库的性能是有限的。为了保持数据的持久性,写入数据库的数据必须写入硬盘,这也造成了数据库的性能瓶颈,毕竟,硬盘的读写效率比内存差得多
- 最后:数据库远离用户。在这里,“远”意味着物理距离。如第一点所述,由于数据库费用高昂,而且需要尽可能集中数据以便进一步分析和利用,因此没有在世界各地建立全球服务数据库。最常见的做法是选择一个固定的位置。例如, AWS的亚洲数据中心在新加坡数,亚洲用户经常选择它,但对于日本用户,网络距离增加,传输速率降低。
- 所以我们需要缓存,因为缓存不需要是持久的,所以它可以使用内存作为存储介质,所以它是廉价的并且具有优秀的性能。由于价格低廉,缓存可以放在离用户尽可能近的地方,例如,缓存可以放在河北廊坊、灵丘、怀来、青岛等,这样中国的用户就可以在附近使用它们。
2. 6种缓存模式
- Cache Expiry
- Read Aside
- Read Through
- Write Through
- Write Ahead (Write Behind)
- Double Delete
Cache Expiry
-
读路径
- 从缓存读取数据
- 如果缓存数据不存在
- 则从数据库读取
- 然后写回缓存(当写回缓存时,我们为每个数据添加一个 TTL)
-
写路径
- 仅将数据写入数据库
-
潜在问题
- 在更新数据时,会发生不一致,因为数据只写回数据库。不一致的时间取决于 TTL 的设置,然而,很难为 TTL 选择一个合适的值。如果 TTL 设置得太长,不一致性时间将增加,相反,缓存将不会有效。值得一提的是,构建缓存是为了减少数据库的负载并提供性能,而且非常短的 TTL 将使缓存无用。例如,如果某个数据的 TTL 被设置为1秒,但是没有人在1秒内读取它,那么缓存的数据将根本没有值。
-
如何改进
- 虽然是通常的做法,但是在更新数据库时,还应该有一种更新缓存数据的机制。这也是“Read Aside”。
Read Aside
-
读路径
- 从缓存读取数据
- 如果缓存数据不存在
- 则从数据库读取
- 然后写回缓存(这个过程与缓存期限相同,但是 TTL 的设置时间足够长。这允许缓存有尽可能多的生效时间。)
-
写路径
- 首先将数据写入数据库
- 然后清除缓存
-
潜在问题
- 这样的读写路径看起来不错,但是也有一些不可避免的情况
- 1 如下图:(slow for stw等等)
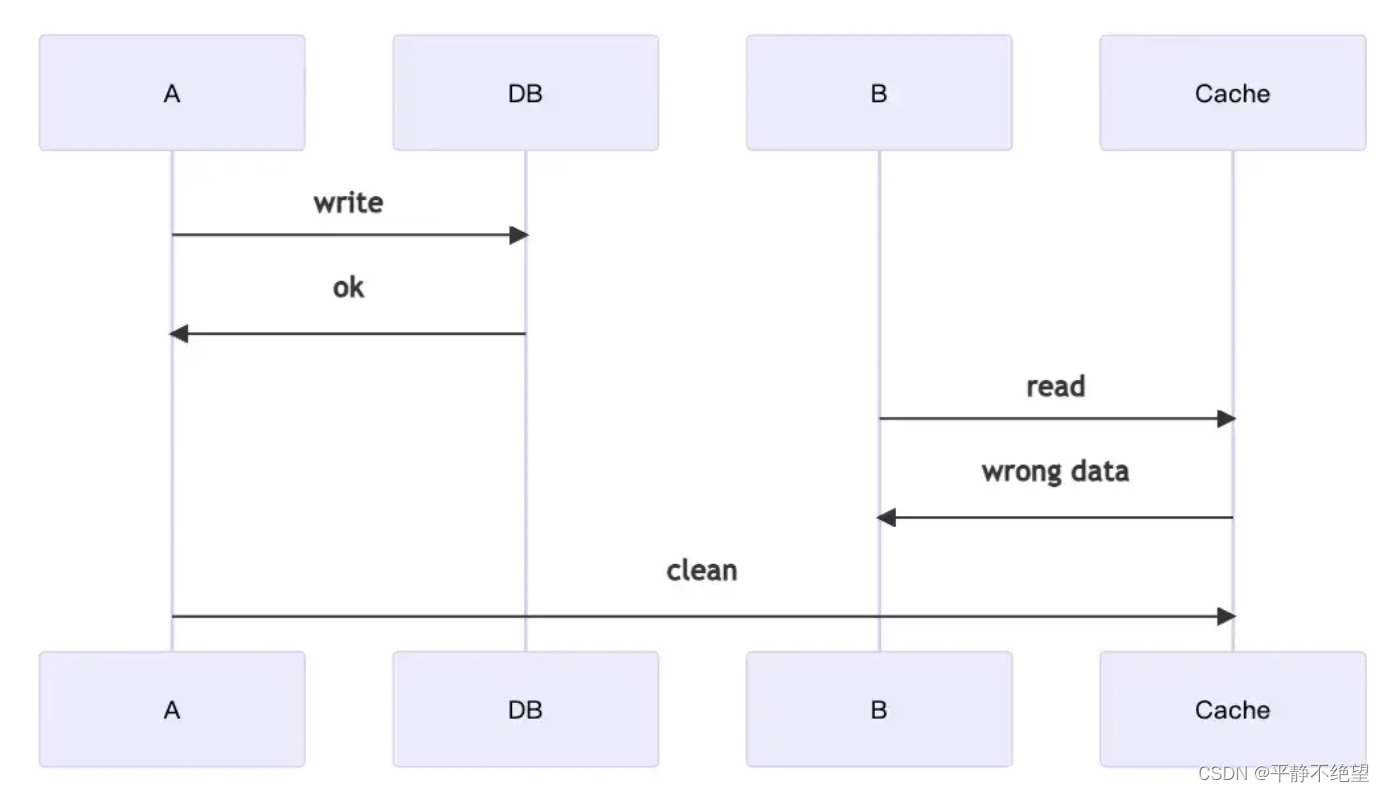
- A 希望更新数据,但 B 希望同时读取数据。单独来说,A 和 B 都有正确的过程,但当两者同时发生时,可能会出现问题。在上面的示例中,B 在 A 清除缓存之前已经从缓存中读取了数据,因此 B 此时获取的数据将是旧的。
- 2 如下图(killed)

- 当 A 正在更新数据时,数据库已经完成了更新,但是由于“某种原因”而被终止。此时,缓存中的数据将在一段时间内保持不一致,直到下次更新数据库或出现 TTL。程序被killed听起来很严重也很罕见,但事实上这种情况发生的可能性比你想象的要大。有几种情况下可能会发生killed
- 当通过容器或 VM 更改版本时,应用程序的旧版本必须替换为新版本,旧版本将被终止。
- 当缩容时,冗余的应用程序将被回收,并且也将被终止
- 最后,它是最常见的,当应用程序崩溃如go 常遇到的 panic,它将不可避免地被杀死。
- 3 如下图(也是slow 如 stop the word 、gc等)
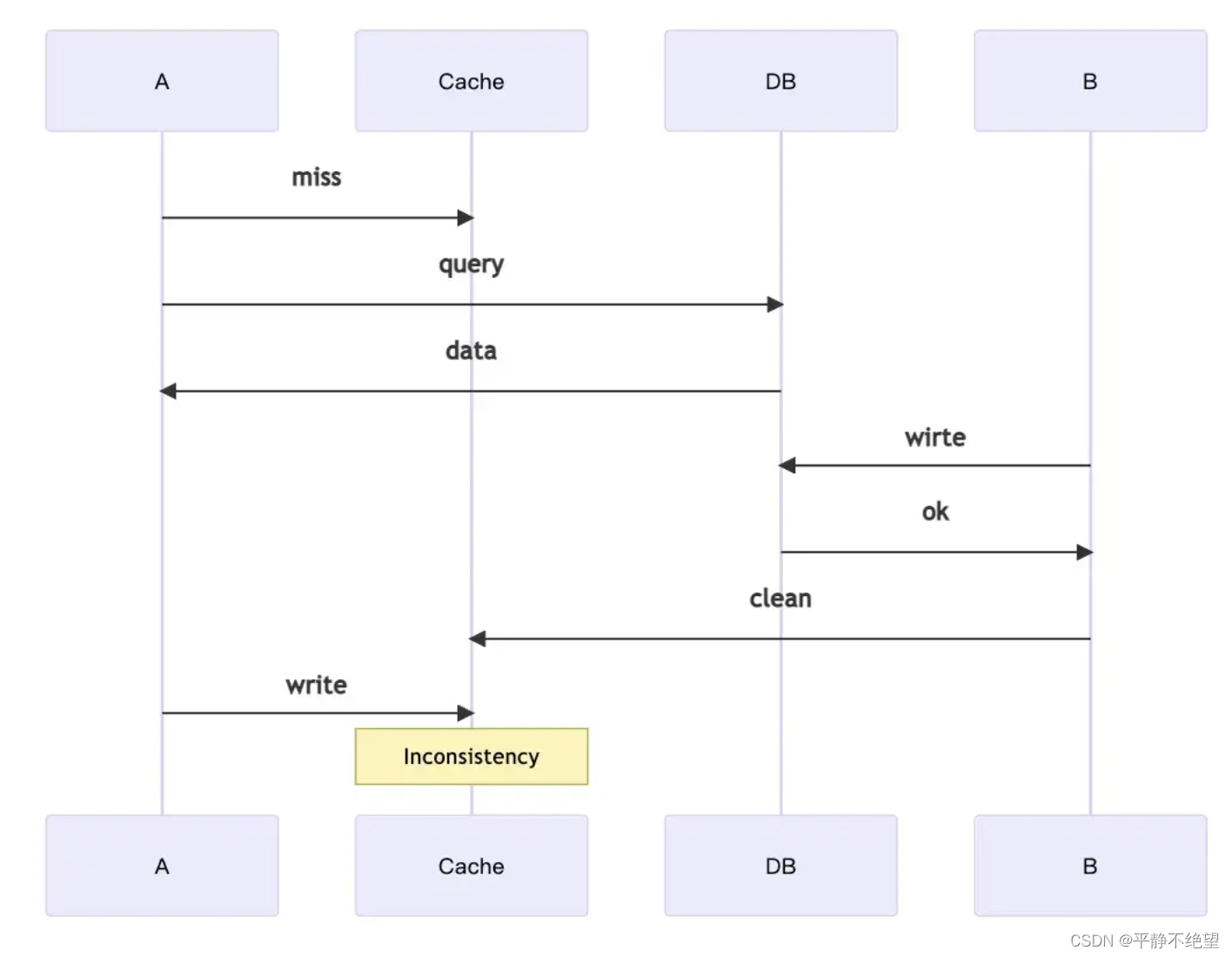 当 A 想要读取数据而 B 想要更新数据时,同样,两者都有正确的单独进程,但错误发生了。首先,A 尝试读取数据,因为在缓存中没有找到相应的结果,所以他从数据库中读取数据; 同时,B 尝试更新数据,所以他在数据库操作之后清除缓存。然后,A 将数据写入缓存,发生不一致,并且不一致将持续一段时间。
当 A 想要读取数据而 B 想要更新数据时,同样,两者都有正确的单独进程,但错误发生了。首先,A 尝试读取数据,因为在缓存中没有找到相应的结果,所以他从数据库中读取数据; 同时,B 尝试更新数据,所以他在数据库操作之后清除缓存。然后,A 将数据写入缓存,发生不一致,并且不一致将持续一段时间。
-
如何改进 (还是有尽可能降低的途径)
- 当应用程序正确地操作数据时,案例1和案例3可以将问题最小化。以案例1为例,在更新数据库后不要做任何额外的事情,并立即清理缓存,而在案例3中,从数据库读取数据后,不要做太多的格式转换,并尽快将结果写入缓存。通过这种方式,可以减少发生的几率,但即便如此,仍然存在一些不可避免的情况,例如垃圾收集生成的 stop-the-world。另一方面,案例2可以通过实现优雅的关闭来减少人为发生的几率,但是对于应用程序崩溃却无能为力。
- 有人提出:把写路径更改为:
- 首先清除缓存
- 然后将数据写入数据库
- 其实问题依然存在,如下图
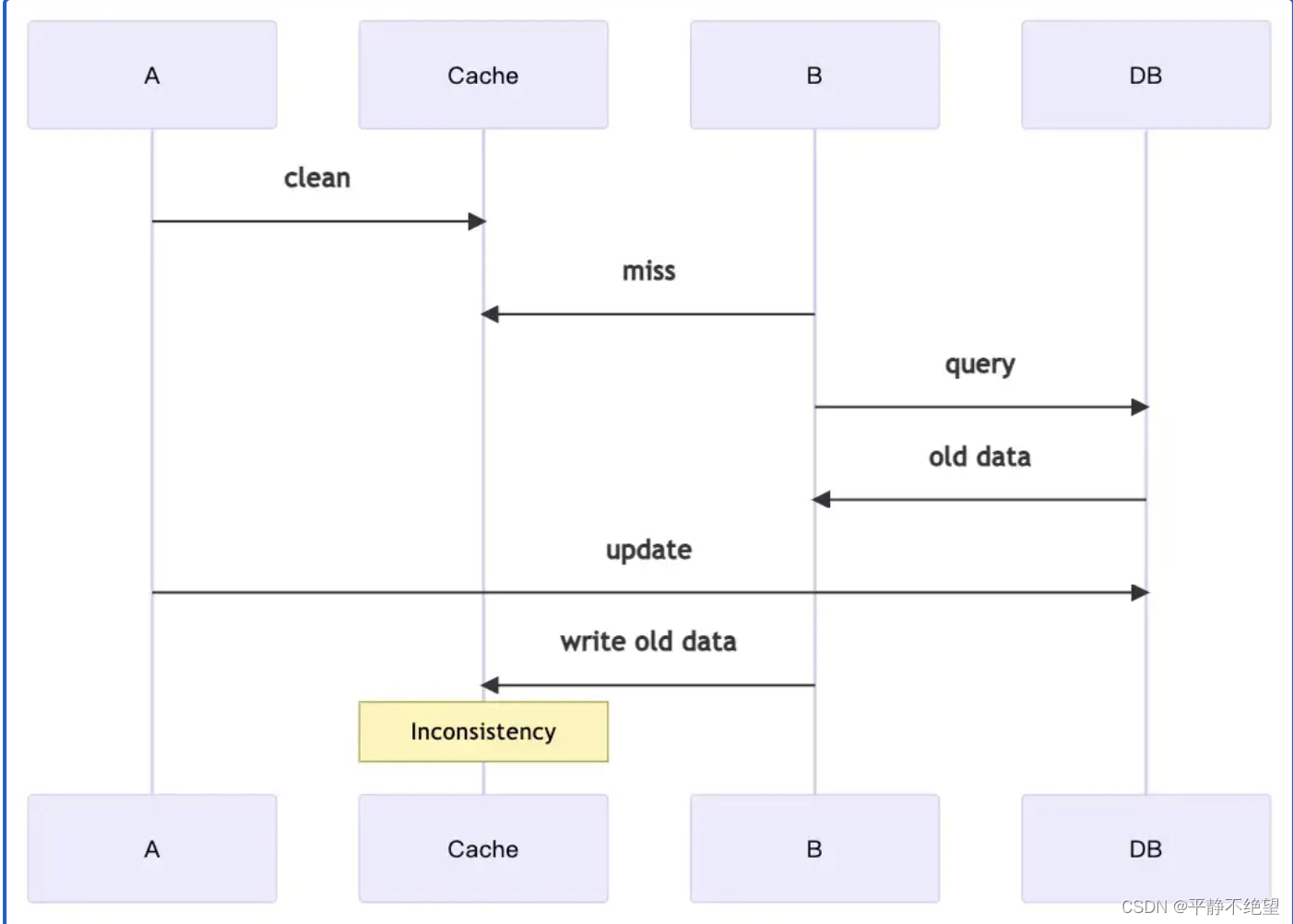
一般来说,Read ASide 可以实现相对较高的一致性,即使它只是一个简单的实现,但它也可以具有非常好的可靠性。
Read Through
-
读路径
- 从缓存读取数据
- 如果缓存数据不存在
- 通过缓存从数据库读取
- 缓存返回数据到应用程序客户端
-
写路径
- 同 Write Through or Write Ahead 实现
-
潜在问题
- 这种方法的最大问题是不支持所有缓存,本文中的 Redis 示例不支持这种方法。当然,也支持一些缓存,比如 NCache,但是 NCache 也有它的问题。首先,它不支持许多客户端 SDK。.NET Core 是本地支持语言,没有多少选项可供选择。此外,它还分为开放源码版本和企业版本,但是如果开放源码版本没有被很多人使用,那么出现问题就是一场悲剧。即便如此,企业版本还是需要许可证费用,不仅是基础设施,还包括软件许可证。
-
如何改进
- 由于 NCache 的成本很高,我们能够自己实现 Read Through 吗? 答案是肯定的。
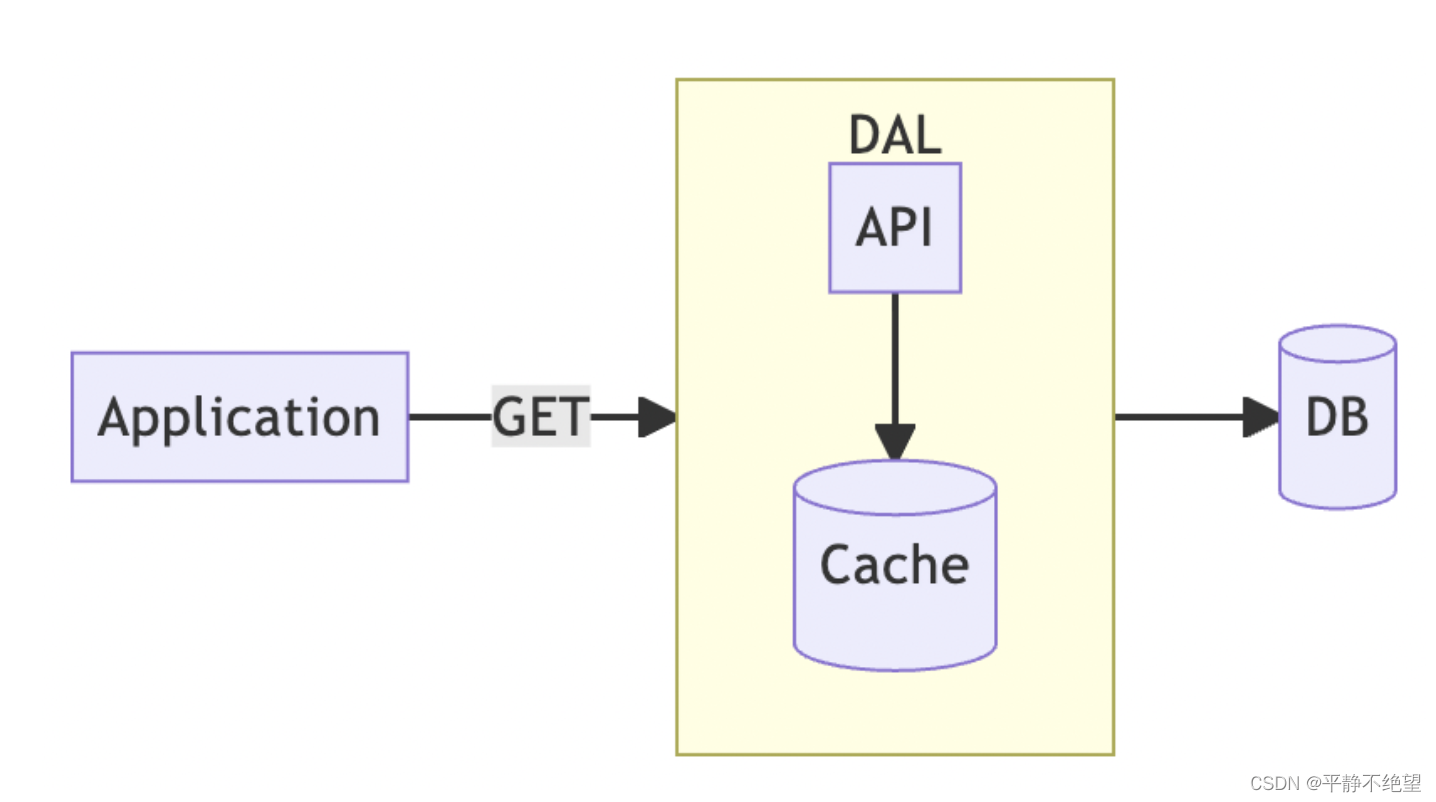 对于应用程序,我们并不真正关心它后面是什么类型的缓存,只要它能够足够快地为我们提供数据,这就是我们所需要的。因此,我们可以将 Redis 打包为称为数据访问层(DAL)的独立服务,并使用内部 API 服务器来协调缓存和数据库。应用程序只需要使用定义的 API 从 DAL 获取数据,而不需要关心缓存如何工作或数据库在哪里。
对于应用程序,我们并不真正关心它后面是什么类型的缓存,只要它能够足够快地为我们提供数据,这就是我们所需要的。因此,我们可以将 Redis 打包为称为数据访问层(DAL)的独立服务,并使用内部 API 服务器来协调缓存和数据库。应用程序只需要使用定义的 API 从 DAL 获取数据,而不需要关心缓存如何工作或数据库在哪里。
Write Through
-
读路径
- 同Read Through实现
-
写路径
- 只写数据到缓存缓存
- 缓存更新的数据库
-
潜在问题
- 与 Read Through 一样,并不支持每个缓存,而且必须自己实现。此外,缓存的设计目的不是用于数据操作。许多数据库具有缓存所不具备的功能,特别是关系数据库的 ACID 保证。更重要的是,缓存不适合于数据持久性。当应用程序写入缓存并考虑完成更新时,缓存仍然可能由于“某种原因”丢失数据。然后,当前的更新将永远不会再次发生。
-
如何改进
- 与 Read Through 一样,必须实现 DAL,但仍然没有解决 ACID 和持久性问题。因此,“Write Ahead”诞生了
Write Ahead (Write Behind)
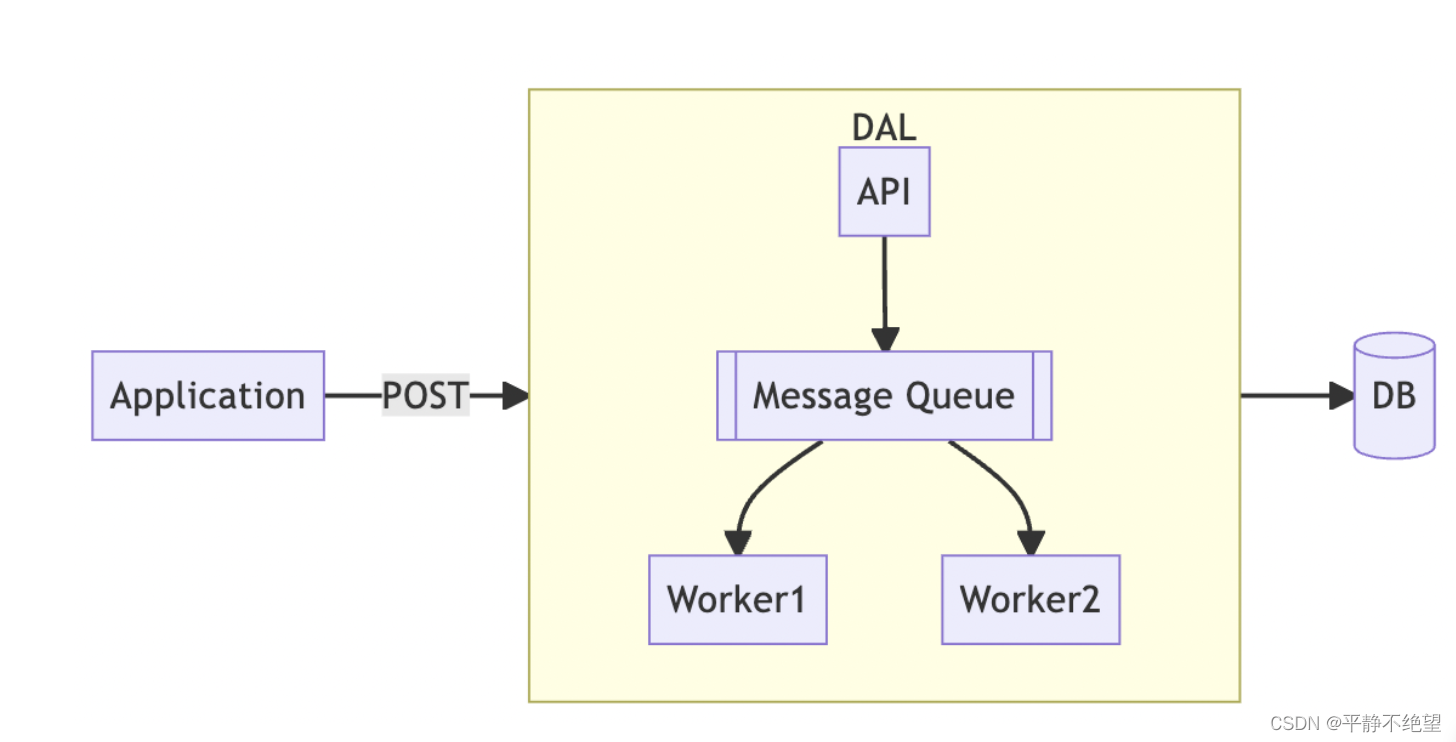
-
读路径
- 同ReadThrough
-
写路径
- 同WriteThrough
-
问题
- 尽管读取路径和写入路径看起来与 Write Through 相同,但它背后的实现却大不相同。“提前写入”是为了解决“完成写入”的问题而创建的。
- 我们还将实现一个 DAL,它实际上是一个内部消息队列,而不是一个缓存。从上面的图中可以看到,整个 DAL 体系结构变得更加复杂。正确使用消息队列需要更多的领域知识和更多的人力资源来设计和实现。
-
如何改进
- 通过使用消息队列,可以有效地确保更改的持久性,并且消息队列还保证一定程度的原子性和隔离性,这虽然不像关系数据库那样完整,但仍具有基本的可靠性。
- 此外,消息队列可以将片段更新合并为批处理。例如,当应用程序希望更新三个缓存以便发送三条消息时,DAL 工作者可以将三条消息合并为一个单独的 SQL 语法,以减少对数据库的访问。
- 需要注意的是,必须使用消息队列来确保消息的顺序,因为对于数据库更新,插入和然后删除的含义与删除和然后插入的含义非常不同。对于每个消息队列,确保消息顺序的方法略有不同,对于 Kafka,可以通过使用正确的分区键来实现。
- 然而,实现预写的复杂性非常高。如果您无法承受这样的复杂性,那么Read Aside仍然是一个更好的选择。
Double Delete
我们已经讨论了两种主要类型的缓存模式,它们分别是
- Read Aside
- Read Through, Write Through, Write Ahead
这两种类型之间最根本的区别在于实现的复杂性。在“Read Aside”的情况下,实现起来非常容易,而且做对也非常简单。但是,在许多交互中,Read ASide 有很多弊端case。
另一方面,通过实现 DAL 可以避免弊端问题,但是正确实现 DAL 非常困难,而且需要大量的领域知识才能正确实现,这使得 DAL 的实现更加困难。
那么,DAL 是否是减少弊端案例数量的唯一方法呢?其实不是的,这就是 Double Delete 模式试图解决的问题。
-
读路径
- Reading data from cache
- If the cache data does not exist
- Read from the database instead
- and write back to the cache
-
写路径
- Clear the cache first
- Then write the data into the database
- Wait for a while, then clear the cache again
- 潜在问题
- 双重删除的目的是尽量减少由于读取Read Aside 弊端case1 case3 案例而造成的灾难所花费的时间。整个不一致性完全取决于等待时间。case2 程序被killed的场景仍然无法解决。
-
如何改进
- 尽可能通过优雅关机避免case2 程序被killed的场景。
小结
- 在本文中,我们介绍了许多提高一致性的方法。一般来说,当一致性不是一个关键的需求时,Cache Expiry 就足够了,并且需要非常低的实现工作量。实际上,广泛使用的 CDN 仅仅是使用 Cache Expiry 的情况之一。
- 随着场景变得越来越关键,并且需要越来越高的一致性,那么考虑使用“读取旁边”甚至“双重删除”来实现它。这两种方法的正确实现足以保证满足大多数场景的一致性。
- 为了进一步提高一致性,有必要使用更高级的技术,如一致性算法,以确保缓存和数据库内容的多数一致性的一致性。这也是 TAO 背后的概念....
- 在一般组织中,对一致性的要求不像10个或更多个9那样严格,一般组织不能操作如此复杂和庞大的体系结构。我们可以选择上面简单的实践 Read Aside Cache Expiry Doubble Delete等,但是即使它们是简单的实践,如果正确实现的话,已经有了足够高的一致性。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小惠珠哦/article/detail/793781?site
推荐阅读
相关标签

