
- 1转载:count(*)和count(1)的区别_count* conut1
- 2git的七个重要基本原则
- 3hive参数调整及优化_hive参数优化
- 4node中后台安全的防护,h5前端开发_node html页面可以直接打开不能保护吗
- 5Java操作kafka_java 操作 kafka
- 6Transformer解码层用mask解释_transformer推理有mask吗
- 7Hive命令行常用操作(数据库操作,表操作)_hive show tables like in
- 8【LeetCode刷题】1.两数之和
- 9Hive3:表操作常用语句-字段类型、创建、删除、修改_hive 删除字段新创建表
- 106. 从0开始学ARM-异常及中断处理、异常向量表、swi_中断异常和向量表
基于Python的卷积神经网络(CNN)识别MNIST数据集_卷积神经网络(可以用vgg16或者resnet20等网络模型)训练mnist数据集python
赞
踩
资源下载地址:https://download.csdn.net/download/sheziqiong/85787751
资源下载地址:https://download.csdn.net/download/sheziqiong/85787751
简介
深度学习发展迅速,MNIST手写数字数据集作为机器学习早期的数据集已经被公认为是机器学习界的果蝇实验(Hinton某年),卷积神经网络是识别图像非常有效的一种架构,于是用CNN识别手写数字也就成为了机器学习界的经典实验。在这个repo中我会呈现最基本的CNN识别MNIST数据集过程。
主要步骤如下:
使用工具
主要使用的语言和平台如下:
安装
安装包括Python语言和几个必备的Pytorch包,使用Linux系统的安装方式如下:
语言
检查一下Python语言:
- Python
$ python3 --version
Python 3.7.7
- 1
- 2
Pytorch包
- 安装Pytorch
pip install torch
- 1
- 安装Torchvision
pip install torchvision
- 1
- 安装Matplotlib
pip install matplotlib
- 1
开始识别数字吧!
完成了安装,我们就可以开始训练神经网络识别数字了,第一步载入数据。
载入数据
首先载入数据,全部MNIST手写数字数据集来自于Yann LeCun网站,这里我们使用torchvision.datasets里已经有的MNIST数据集,与从网站下载效果相同:
from torchvision.datasets import MNIST
train_data = MNIST(root='./data', train=True, download=True, transform=transform)
test_data = MNIST(root='./data', train=False, download=True, transform=transform)
- 1
- 2
- 3
看看数据啥样儿
要想建立一个好的模型,首先我们要熟悉所处理的数据集是怎样的,MNIST的数据集中每一张手写数字图片均是灰度的28*28的图片,同上配有一个正确的0-9的label。先来一起看看训练集和测试集:
print(train_data)
- 1
Dataset MNIST
Number of datapoints: 60000
Root location: ./data
Split: Train
StandardTransform
Transform: Compose(
ToTensor()
Normalize(mean=(0.5,), std=(0.5,))
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
print(test_data)
- 1
Dataset MNIST
Number of datapoints: 10000
Root location: ./data
Split: Test
StandardTransform
Transform: Compose(
ToTensor()
Normalize(mean=(0.5,), std=(0.5,))
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
训练集中有60000个手写数字及其label,测试集有10000个,接下来我们看看手写数字长啥样儿:
# 展示前40张手写数字
import matplotlib.pyplot as plt
num_of_images = 40
for index in range(1, num_of_images + 1):
plt.subplot(4, 10, index)
plt.axis('off')
plt.imshow(train_data.data[index], cmap='gray_r')
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这段code用matplotlib画出前40张训练集里的手写数字,在同一张图里呈现,图如下:

我们的任务就是通过只看到手写数字的图片,建立一个CNN模型成功的识别出它是0-9的哪一个数字。
建立模型
我们选择的模型不算复杂,首先两层卷积提取图片的features,接下来两层完全连接进行识别(注意最后一层的output是10个,对应数字0-9):
# 卷积网络层
self.conv1 = nn.Conv2d(in_channels=1, out_channels=5, kernel_size=3, stride=1, padding=1)
self.maxpool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(in_channels=5, out_channels=10, kernel_size=3, stride=1, padding=1)
self.maxpool2 = nn.MaxPool2d(kernel_size=2, stride=2)
# 完全连接网络层
self.fc1 = nn.Linear(in_features=7*7*10, out_features=128)
self.fc2 = nn.Linear(in_features=128, out_features=10)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
有个卷积神经网络的结构就可以定义forward函数了:
def forward(self, x): """forward.""" # 第一层卷积和取最大值 x = F.relu(self.conv1(x)) x = self.maxpool1(x) # 第二层卷积和取最大值 x = F.relu(self.conv2(x)) x = self.maxpool2(x) # 完全连接层 x = x.view(-1, 7*7*10) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) return x

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
这样就完成了CNN模型的建立。
训练模型
先来看一下我们的模型有多少参数需要训练(剧透:很多)
total_params = sum(p.numel() for p in model.parameters())
print(total_params)
- 1
- 2
64648
- 1
6万多的参数等待训练…首先定义Loss Function和optimizer,这里使用CrossEntropy和Adam:
# 定义神经网络和训练参数
model = CNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=3e-4, weight_decay=0.001)
batch_size = 100
epoch_num = int(train_data.data.shape[0]) // batch_size
- 1
- 2
- 3
- 4
- 5
- 6
这里的batch_size是100,也就意味着我们一共有60000个数据在训练集里,要训练600个回合才能全部训练完。训练过程:
for epoch in range(1, epoch_num+1):
# 每个batch一起训练,更新神经网络weights
for idx, (img, label) in enumerate(train_loader):
optimizer.zero_grad()
output = model(img)
loss = criterion(output, label)
loss.backward()
optimizer.step()
print("Training Epoch {} Completed".format(epoch))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
训练的时间比较长,建议使用Amazon Web Service或者其他计算能力比较强的机器。
由于我的机器实在太弱了,我训练了两轮就掐掉了,也就意味着只用了200个训练集的数字,估计表现会比较差(此处留下悬疑)

测试模型
完成了训练后我们的主要任务就已经完成了,接下来就要看看我们的CNN训练的究竟好不好,测试集的10000个手写数字对于我们的CNN模型而言是全新的数据,因此我们用测试集看看效果:
total = 0
correct = 0
for i, (test_img, test_label) in enumerate(test_loader):
# 正向通过神经网络得到预测结果
outputs = model(test_img)
predicted = torch.max(outputs.data, 1)[1]
print("Correct label is", test_label)
print("Prediction is", predicted)
# 总数和正确数
total += len(test_label)
correct += (predicted == test_label).sum()
accuracy = correct / total
print('Testing Results:\n Loss: {} \nAccuracy: {} %'.format(loss.data, accuracy*100))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
一起来看看测试结果:
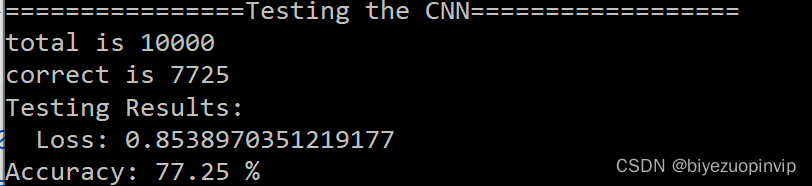
竟然高达77%……我才只用了200个训练集。
资源下载地址:https://download.csdn.net/download/sheziqiong/85787751
资源下载地址:https://download.csdn.net/download/sheziqiong/85787751

