
- 1使用原生 HTML + JS 实现类似 ChatGPT 的文字逐字显示效果_html实现一段话逐字输出
- 2手把手带你写一份优秀的开发求职简历(八)写一个项目经历_手把手带你写一份优秀的开发求职简历(八)写一个项目经历
- 3模板-资源-项目_pptist github
- 4vue3+openlayer调用geoserver发布的矢量地图服务并进行显示(清晰封装,简洁明了)_openlayers封装vue3
- 5selenium自动化设计框架之 page object设计模式介绍
- 6Tomcat服务安全加固和优化_当请求处理期间发生运行时错误时,apachetomcat将向请求者显示调试信息。建议不要
- 7Hadoop 重要监控指标
- 8HarmonyOS(鸿蒙)——Text(文本)组件介绍_鸿蒙next text组件设置最大显示字数
- 9GIT密码管理
- 10如何构建企业级的AI大模型?_行业大模型怎么做
Iceberg实战踩坑指南
赞
踩
目录
5.1 基于 Structured Streaming 落明细数据
前言
本文基于Iceberg0.11.1版本
第 1 章 介绍
Apache Iceberg 是一种用于大型分析数据集的开放表格,Iceberge 向 Trino 和 Spark 添加了使用高性能格式的表,就像 Sql 表一样。
Iceberg 为了避免出现不变要的一些意外,表结构和组织并不会实际删除,用户也不需要特意了解分区便可进行快速查询。
- Iceberg 的表支持快速添加、删除、更新或重命名操作
- 将分区列进行隐藏,避免用户错误的使用分区和进行极慢的查询。
- 分区列也会随着表数据量或查询模式的变化而自动更新。
- 表可以根据时间进行表快照,方便用户根据时间进行检查更改。
- 提供版本回滚,方便用户纠错数据。
Iceberg 是为大表而建的,Iceberg 用于生产中,其中单表数据量可包含 10pb 左右数据, 甚至可以在没有分布式 SQL 引擎的情况下读取这些巨量数据。
- 查询计划非常迅速,不需要分布式 SQL 引擎来读取数据
- 高级过滤:可以使用分区和列来过滤查询这些数据
- 可适用于任何云存储
- 表的任何操作都是原子性的,用户不会看到部分或未提交的内容。
- 使用多个并发器进行写入,并使用乐观锁重试的机制来解决兼容性问题
本文demo基于 0.11.1 版本较老,iceberg官网已经没有该版本样例了,同时改版本也不支持一些iceberg的新特性,比如:upsert功能,动态schema变更以及索引和小文件合并等问题。但是不影响对主要API和功能的学习和理解
第 2 章 构建 Iceberg
构建 Iceberge 需要 Grade 5.41 和 java8 或 java11 的环境
2.1 构建 Iceberg
1.上传 iceberg-apache-iceberg-0.11.1.zip,并进行解压
- [root@hadoop103 software]# unzip iceberg-apache-iceberg-0.11.1.zip -d /opt/module/
- [root@hadoop103 software]# cd /opt/module/iceberg-apache-iceberg-0.11.1/
2.修改对应版本
- [root@hadoop103 iceberg-apache-iceberg-0.11.1]# vim versions.props org.apache.flink:* = 1.11.0
- org.apache.hadoop:* = 3.1.3
- org.apache.hive:hive-metastore = 2.3.7
-
- org.apache.hive:hive-serde = 2.3.7
- org.apache.spark:spark-hive_2.12 = 3.0.1
- org.apache.hive:hive-exec = 2.3.7
- org.apache.hive:hive-service = 2.3.7
3.修改国内镜像
- [root@hadoop103 iceberg-apache-iceberg-0.11.1]# vim build.gradle buildscript {
- repositories { jcenter() gradlePluginPortal()
- maven{ url 'http://maven.aliyun.com/nexus/content/groups/public/' } maven{ url 'http://maven.aliyun.com/nexus/content/repositories/jcenter'} maven { url "http://palantir.bintray.com/releases" }
- maven { url "https://plugins.gradle.org/m2/" }
- }
-
- allprojects {
- group = "org.apache.iceberg" version = getProjectVersion() repositories {
- maven{ url 'http://maven.aliyun.com/nexus/content/groups/public/'} maven{ url 'http://maven.aliyun.com/nexus/content/repositories/jcenter'} maven { url "http://palantir.bintray.com/releases" }
- mavenCentral() mavenLocal()
- }
- }
4.构建项目
[root@hadoop103 iceberg-apache-iceberg-0.11.1]# ./gradlew build -x test第 3 章 Spark 操作
3.1.配置参数和 jar 包
1.将构建好的 Iceberg 的 spark 模块 jar 包,复制到 spark jars 下
- [root@hadoop103]/opt/module/iceberg-apache-iceberg-0.11.1/spark3-extensions/build/libs/ [root@hadoop103 libs]# cp *.jar /opt/module/spark-3.0.1-bin-hadoop2.7/jars/ [root@hadoop103 libs]# cd
- /opt/module/iceberg-apache-iceberg-0.11.1/spark3-runtime/build/libs/
- [root@hadoop103 libs]# cp *.jar /opt/module/spark-3.0.1-bin-hadoop2.7/jars/
2.配置 spark 参数,配置 Spark Sql Catlog,可以用两种方式,基于 hive 和基于 hadoop,这里先选择基于 hadoop。
- [root@hadoop103 libs]# cd /opt/module/spark-3.0.1-bin-hadoop2.7/conf/
- [root@hadoop103 conf]# vim spark-defaults.conf spark.sql.catalog.hive_prod = org.apache.iceberg.spark.SparkCatalog spark.sql.catalog.hive_prod.type = hive spark.sql.catalog.hive_prod.uri = thrift://hadoop101:9083
-
-
- spark.sql.catalog.hadoop_prod = org.apache.iceberg.spark.SparkCatalog
- spark.sql.catalog.hadoop_prod.type = hadoop
-
-
- spark.sql.catalog.hadoop_prod.warehouse = hdfs://mycluster/spark/warehouse
-
-
- spark.sql.catalog.catalog-name.type = hadoop spark.sql.catalog.catalog-name.default-namespace = db spark.sql.catalog.catalog-name.uri = thrift://hadoop101:9083
- spark.sql.catalog.catalog-name.warehouse= hdfs://mycluster/spark/warehouse
3.2 Spark sql 操作
- 正在上传…重新上传取消使用 spark sql 创建 iceberg 表,配置完毕后,会多出一个 hadoop_prod.db 数据库,但是注意这个数据库通过 show tables 是看不到的
- [root@hadoop103 ~]# spark-sql
- spark-sql (default)> use hadoop_prod.db; create table testA(
- id bigint, name string, age int,
- dt string) USING iceberg
- PARTITIONED by(dt);
2.插入数据
spark-sql (default)> insert into testA values(1,'张三',18,'2021-06-21');3.查询
spark-sql (default)> select *from testA;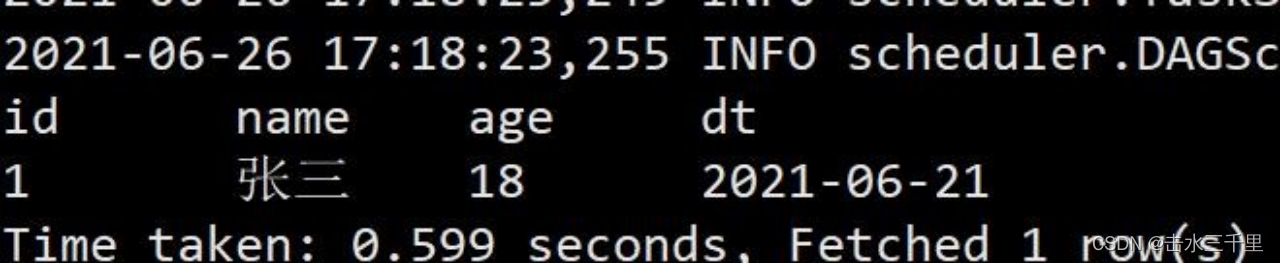
3.2.1over write 操作
(1)覆盖操作与 hive 一样,会将原始数据重新刷新
- spark-sql (default)> insert overwrite testA values(2,'李四',20,'2021-06-21');
- spark-sql (default)> select *from testA;
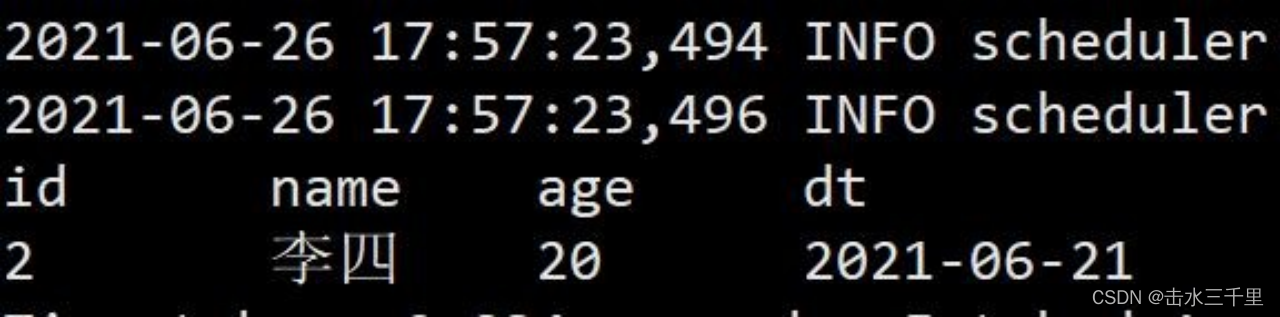
3.2.2动态覆盖
1.Spark 的默认覆盖模式是静态的,但在写入 iceberg 时建议使用动态覆盖模式。静态覆盖模式需要制定分区列,动态覆盖模式不需要。
- spark-sql (default)> insert overwrite testA values(2,'李四',20,'2021-06-21');
- spark-sql (default)> select *from testA;
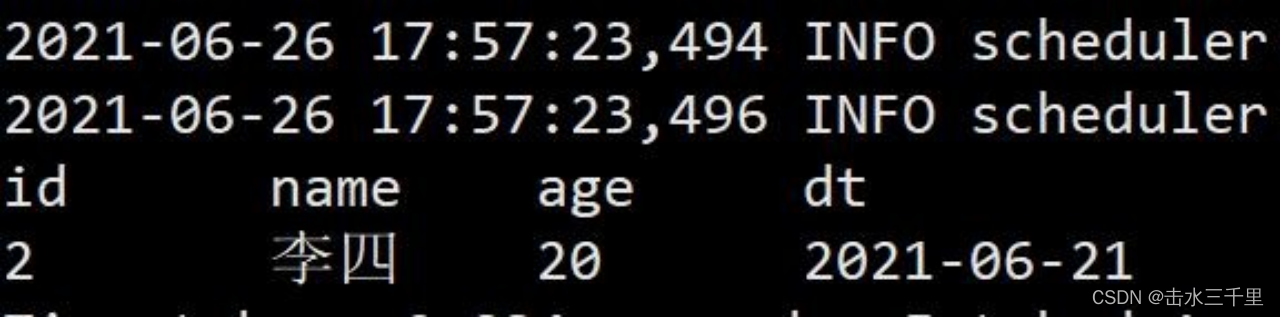
2.设置动态覆盖模式,修改 spark-default.conf,添加对应参数
- [root@hadoop103 conf]# vim spark-defaults.conf
- spark.sql.sources.partitionOverwriteMode=dynamic
3.创建一张表结构与 testA 完全一致的表 testB
- create table hadoop_prod.db.testB( id bigint,
- name string, age int,
- dt string) USING iceberg
- PARTITIONED by(dt);
4.向 testA 表中再插入一条数据
- spark-sql (default)> use hadoop_prod.db;
-
- spark-sql (default)> insert into testA values(1,'张三',18,'2021-06-22');
5.查询 testA 表,此时 testA 表中有两条记录
spark-sql (default)> select *from testA;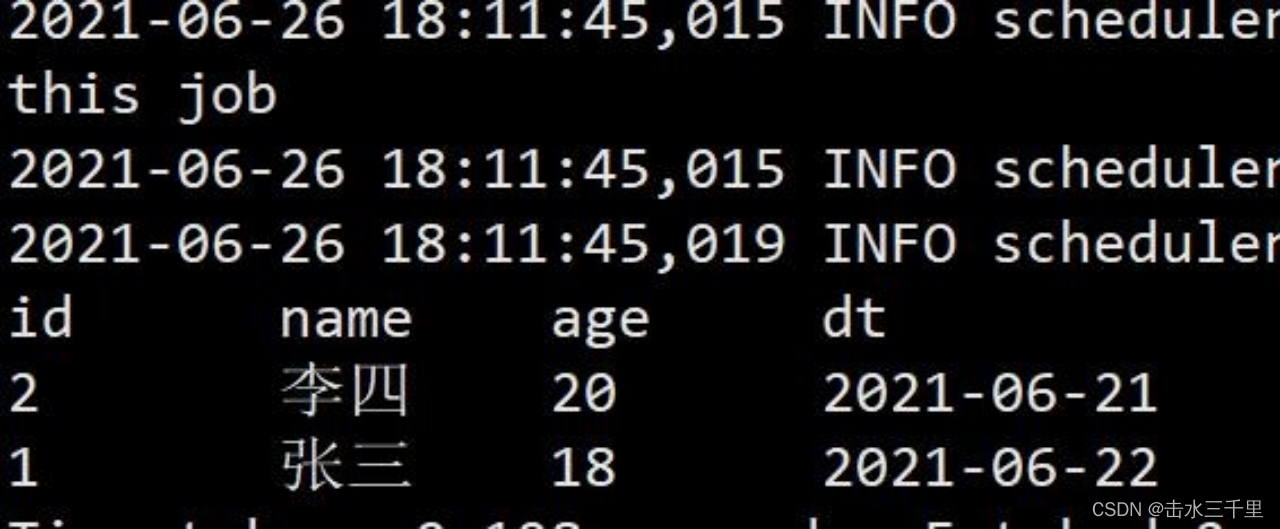
6.通过动态覆盖模式将 A 表插入到 B 表中
spark-sql (default)> insert overwrite testB select *from testA;7.查询 testB 表,可以看到效果与 hive 中的动态分区一样,自动根据列的顺序进行匹配插入,无须手动指定分区。
spark-sql (default)> select *from testB;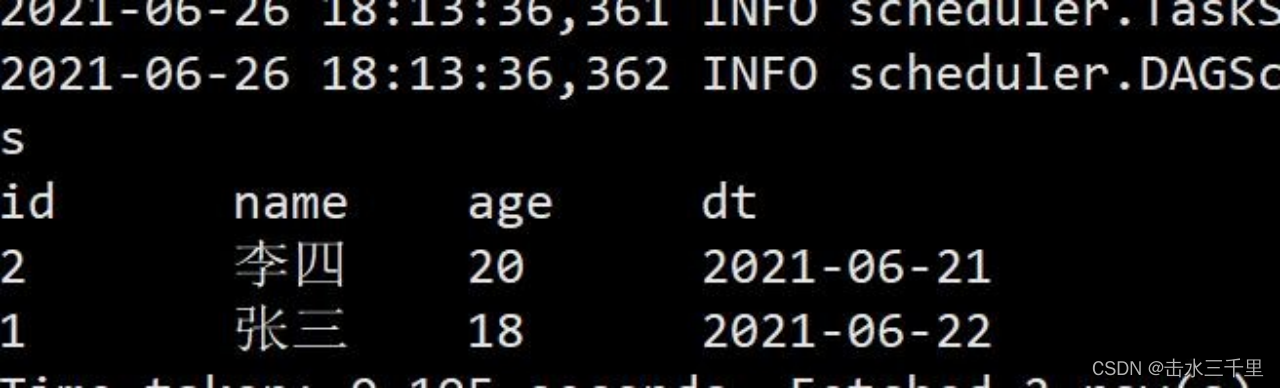
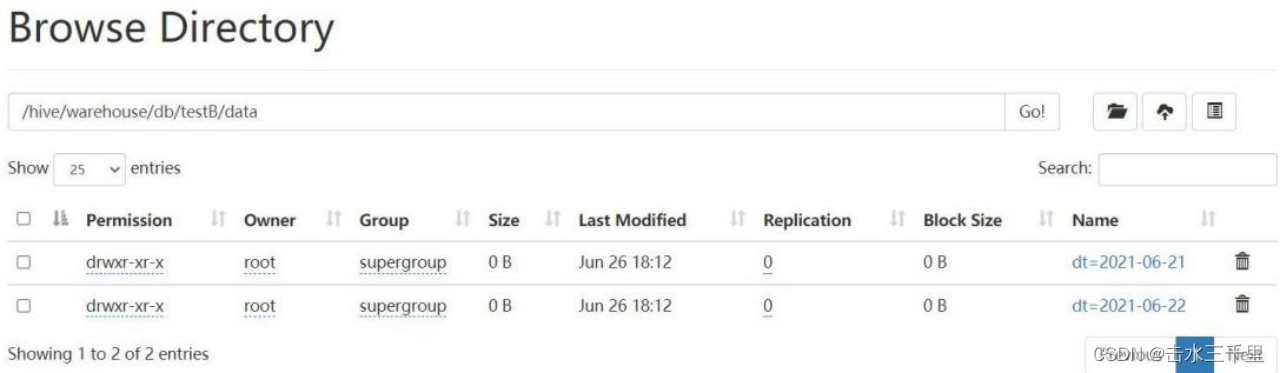
3.2.3静态覆盖
1.静态覆盖,则跟 hive 插入时手动指定分区一致,需要手动指定分区列的值
- spark-sql (default)> insert overwrite testB Partition(dt='2021-06-26')
- select id,name,age from testA;
2.查询表数据
spark-sql (default)> select *from testB;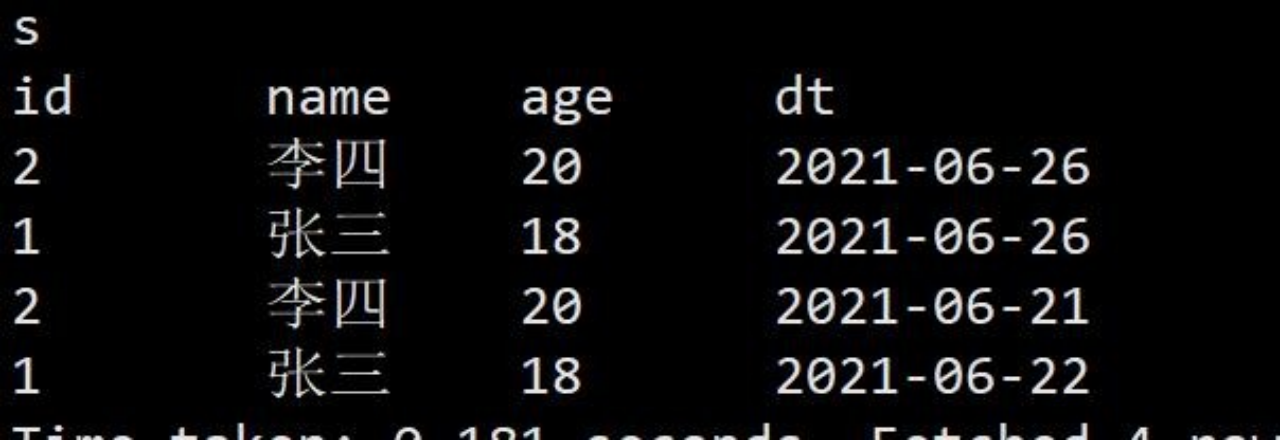
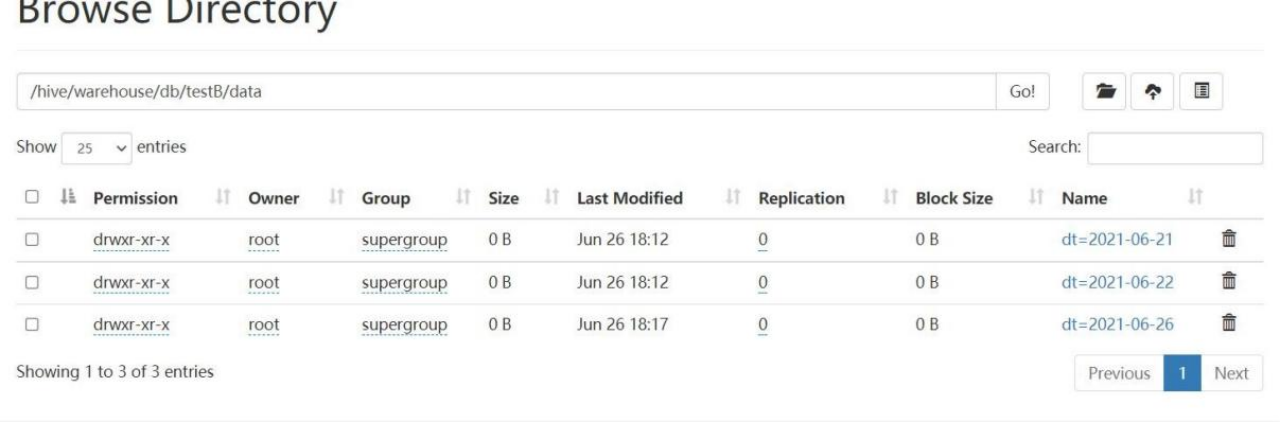
3.2.4删除数据
1.iceberg 并不会物理删除数据,下面演示 delete 操作,根据分区列进行删除 testB 表数据
spark-sql (default)> delete from testB where dt >='2021-06-21' and dt <='2021-06-26';2.提示删除成功,再次查询数据。发现表中已无数据,但是存在 hdfs 上的物理并没有实际删除

3.查看 hdfs 数据,仍然存在。
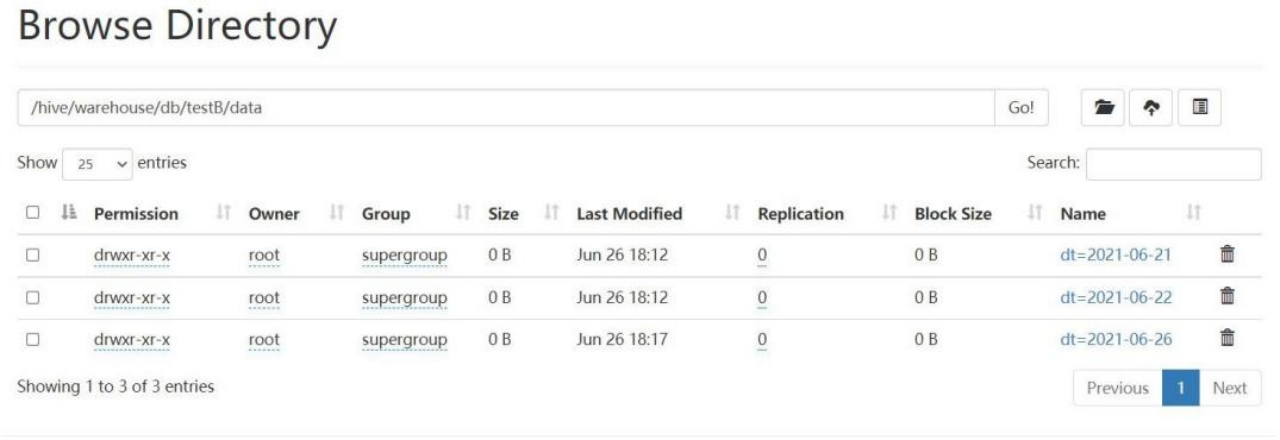
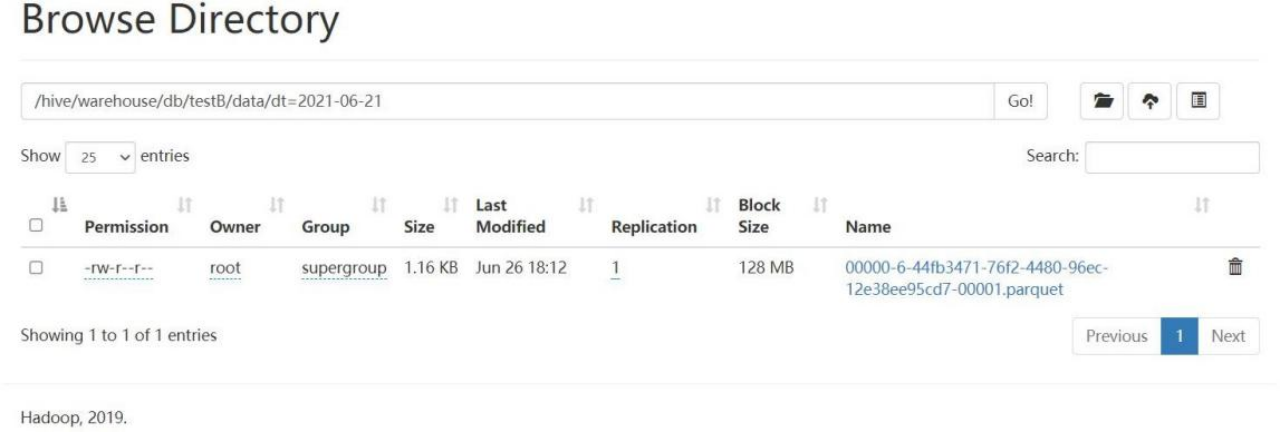
3.2.5历史快照
1.每张表都拥有一张历史表,历史表的表名为当前表加上后缀.history,注意:查询历史表的时候必须是表的全称,不可用先切到 hadoop.db 库中再查 testB
spark-sql (default)> select *from hadoop_prod.db.testB.history;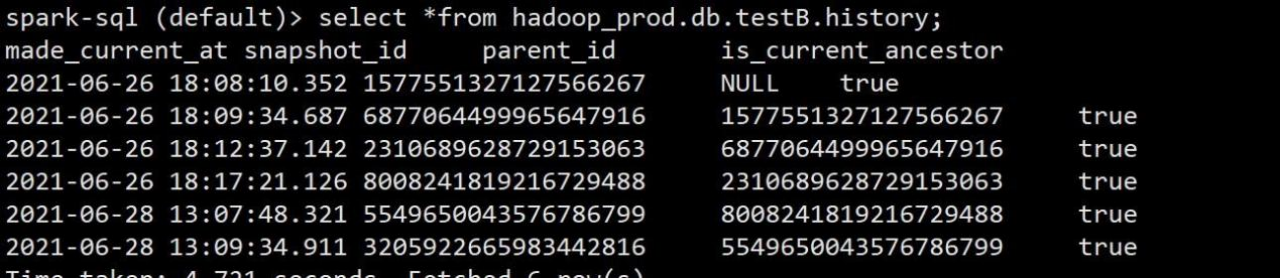
2.可以查看到每次操作后的对应的快照记录,也可以查询对应快照表,快照表的表名在 原表基础上加上.snapshots,也是一样必须是表的全称不能简写
spark-sql (default)> select *from hadoop_prod.db.testB.snapshots;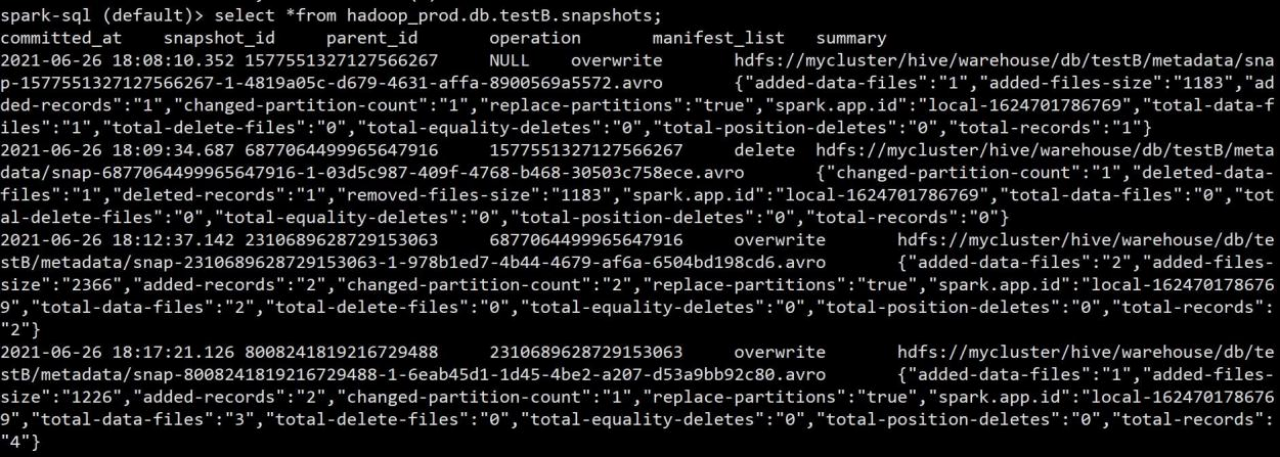
3.可以在看到 commit 的时间,snapshot 快照的 id,parent_id 父节点,operation 操作类型, 已经 summary 概要,summary 概要字段中可以看到数据量大小,总条数,路径等信息。
两张表也可以根据 snapshot_id 快照 id 进行 join 关联查询。
spark-sql (default)> select *from hadoop_prod.db.testB.history a join hadoop_prod.db.testB.snapshots b on a.snapshot_id=b.snapshot_id ;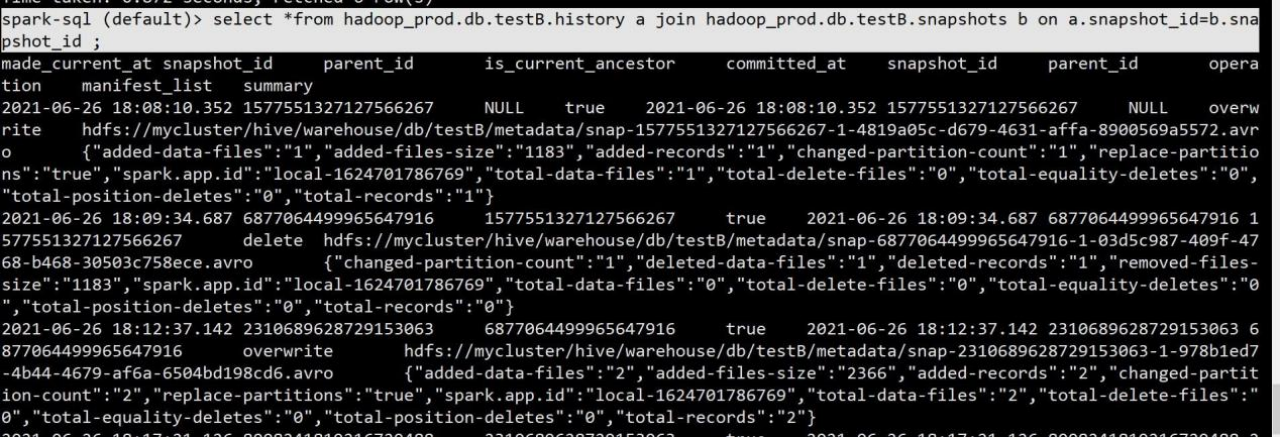
4.知道了快照表和快照信息后,可以根据快照 id 来查询具体的历史信息,发进行检测是否误操作,如果是误操作则可通过 spark 重新刷新数据。查询方式如下
- scala>
- spark.read.option("snapshot-id","5549650043576786799").format("iceberg").load("/hive/w arehouse/db/testB").show

3.2.6隐藏分区(有 bug 时区不对)
1.days 函数
1)上面演示了创建分区表, 接下来演示创建隐藏分区表。隐藏分区支持的函数有 years,months,days,hours,bucket,truncate。比如接下来创建一张 testC 表,表中有id,name 和 ts时间戳。
- create table hadoop_prod.db.testC(
- id bigint, name string, ts timestamp) using iceberg
- partitioned by (days(ts));
2)创建成功分别往里面插入不同天时间戳的数据
spark-sql (default)> insert into hadoop_prod.db.testC values(1,'张三',cast(1624773600 as timestamp)),(2,'李四',cast(1624860000 as timestamp));3)插入成功之后再来查询表数据。
spark-sql (default)> select *from hadoop_prod.db.testC;4)可以看到有两条数据,并且日期也不是同一天,查看 hdfs 上对应的分区。已经自动按天进行了分区。

2.years 函数
1)删除 testC 表,重新建表,字段还是不变,分区字段使用 years 函数
- spark-sql (default)> drop table hadoop_prod.db.testC; create table hadoop_prod.db.testC(
- id bigint, name string, ts timestamp) using iceberg
- partitioned by (years(ts));
2)同样,插入两条不同年时间戳的数据,进行查询对比
spark-sql (default)> insert into hadoop_prod.db.testC values(1,'张三',cast(1624860000 as timestamp)),(2,'李四',cast(1593324000 as timestamp));3)查询数据
spark-sql (default)> select *from hadoop_prod.db.testC;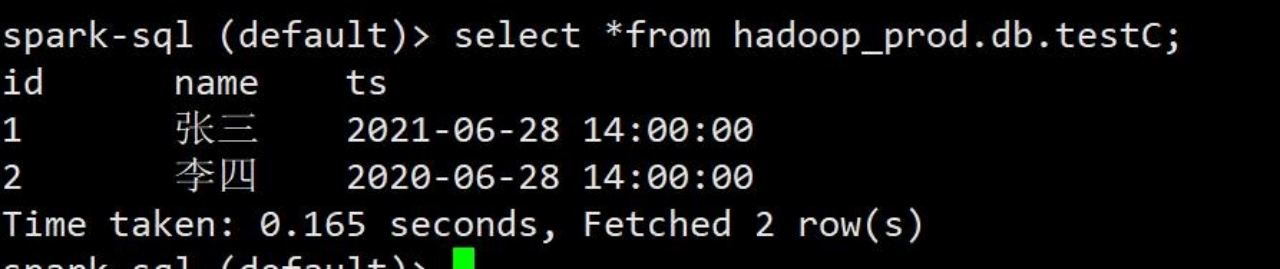
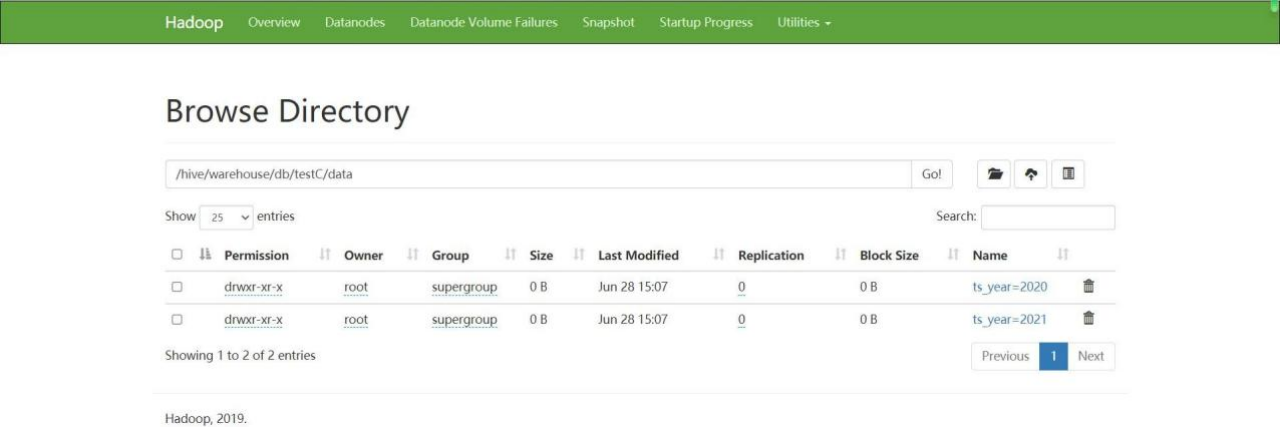
4)再查看 hdfs 对应的地址,已经按年建好分区
3.month 函数
1)删除 testC 表,重新建表,字段不变, 使用 month 函数进行分区
- spark-sql (default)> drop table hadoop_prod.db.testC; create table hadoop_prod.db.testC(
- id bigint, name string, ts timestamp) using iceberg
- partitioned by (months(ts));
2)同样,插入不同月份时间戳的两条记录
spark-sql (default)> insert into hadoop_prod.db.testC values(1,'张三',cast(1624860000 as timestamp)),(2,'李四',cast(1622181600 as timestamp));3)查询数据和 hdfs 对应地址
spark-sql (default)> select *from hadoop_prod.db.testC;4.hours 函数
1)删除 testC 表,重新建表,字段不变使用 hours 函数
- spark-sql (default)> drop table hadoop_prod.db.testC; create table hadoop_prod.db.testC(
- id bigint, name string, ts timestamp) using iceberg
- partitioned by (hours(ts));
2)插入两条不同小时的时间戳数据
spark-sql (default)> insert into hadoop_prod.db.testC values(1,'张三',cast(1622181600 as timestamp)),(2,'李四',cast(1622178000 as timestamp));3)查询数据和 hdfs 地址
spark-sql (default)> select *from hadoop_prod.db.testC;
4)发现时区不对,修改对应参数
root@hadoop103 ~]# vim /opt/module/spark-3.0.1-bin-hadoop2.7/conf/spark-defaults.conf spark.sql.session.timeZone=GMT+85)再次启动 spark sql 插入数据
- [root@hadoop103 ~]# spark-sql
- spark-sql (default)> insert into hadoop_prod.db.testC values(1,'张三',cast(1622181600 as timestamp)),(2,'李四',cast(1622178000 as timestamp));
6)查看 hdfs 路径,还是错误分区目录(bug)
5.bucket 函数(有 bug)
1)删除 testC 表,重新创建,表字段不变,使用 bucket 函数。分桶 hash 算法采用 Murmur3 hash,官网介绍 https://iceberg.apache.org/spec/#partition-transforms
- spark-sql (default)> drop table hadoop_prod.db.testC; create table hadoop_prod.db.testC(
- id bigint, name string, ts timestamp) using iceberg
- partitioned by (bucket(16,id));
2)插入一批测试数据,为什么分多批插入,有 bug:如果一批数据中有数据被分到同一个桶里会报错
- insert into hadoop_prod.db.testC values
- (1,'张 1',cast(1622152800 as timestamp)),(1,'李 1',cast(1622178000 as timestamp)), (2,'张 2',cast(1622152800 as timestamp)),(3,'李 2',cast(1622178000 as timestamp)), (4,'张 3',cast(1622152800 as timestamp)),(6,'李 3',cast(1622178000 as timestamp)), (5,'张 4',cast(1622152800 as timestamp)),(8,'李 4',cast(1622178000 as timestamp)); insert into hadoop_prod.db.testC values
- (9,'张 5',cast(1622152800 as timestamp)),(10,'李 5',cast(1622178000 as timestamp)), (11,'张 6',cast(1622152800 as timestamp)),(12,'李 6',cast(1622178000 as timestamp)); insert into hadoop_prod.db.testC values
- (13,'张 7',cast(1622152800 as timestamp)),(14,'李 7',cast(1622178000 as timestamp)),
- (15,'张 8',cast(1622152800 as timestamp)),(16,'李 8',cast(1622178000 as timestamp)); insert into hadoop_prod.db.testC values
- (17,'张 9',cast(1622152800 as timestamp)),(18,'李 9',cast(1622178000 as timestamp)),
- (18,'张 10',cast(1622152800 as timestamp)),(20,'李 10',cast(1622178000 as timestamp)); insert into hadoop_prod.db.testC values
- (1001,'张 9',cast(1622152800 as timestamp)),(1003,'李 9',cast(1622178000 as timestamp)),
- (1002,'张 10',cast(1622152800 as timestamp)),(1004,'李 10',cast(1622178000 as timestamp));
3)查看表数据和 hdfs 路径
spark-sql (default)> select *from hadoop_prod.db.testC;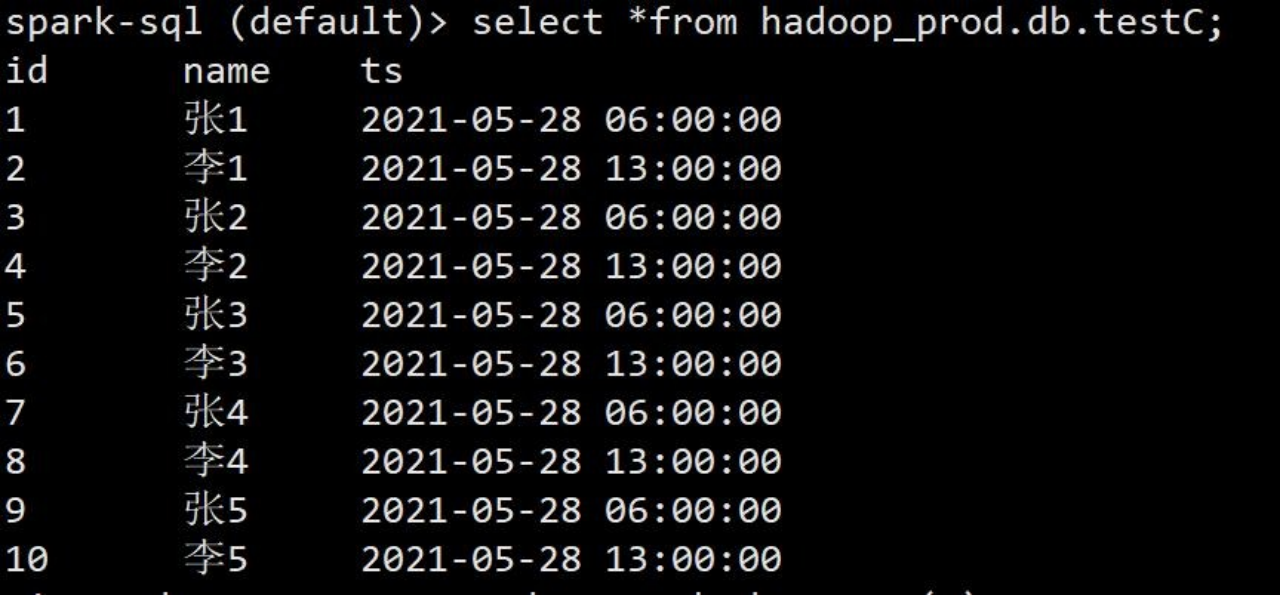
- spark-sql (default)> drop table hadoop_prod.db.testC; create table hadoop_prod.db.testC(
- id bigint, name string, ts timestamp) using iceberg
- partitioned by (truncate(4,id));
6.truncate 函数
1)删除表,重新建表,字段不变,使用 truncate 函数,截取长度来进行分区
- spark-sql (default)> drop table hadoop_prod.db.testC; create table hadoop_prod.db.testC(
- id bigint, name string, ts timestamp) using iceberg
- partitioned by (truncate(4,id));
2)插入一批测试数据
- insert into hadoop_prod.db.testC values
- (10010001,' 张 1',cast(1622152800 as timestamp)),(10010002,' 李 1',cast(1622178000 as timestamp)),
- (10010003,' 张 2',cast(1622152800 as timestamp)),(10020001,' 李 2',cast(1622178000
- as timestamp)),
- (10020002,' 张 3',cast(1622152800 as timestamp)),(10030001,' 李 3',cast(1622178000
- as timestamp)),
- (10040001,' 张 4',cast(1622152800 as timestamp)),(10050001,' 李 4',cast(1622178000 as timestamp));
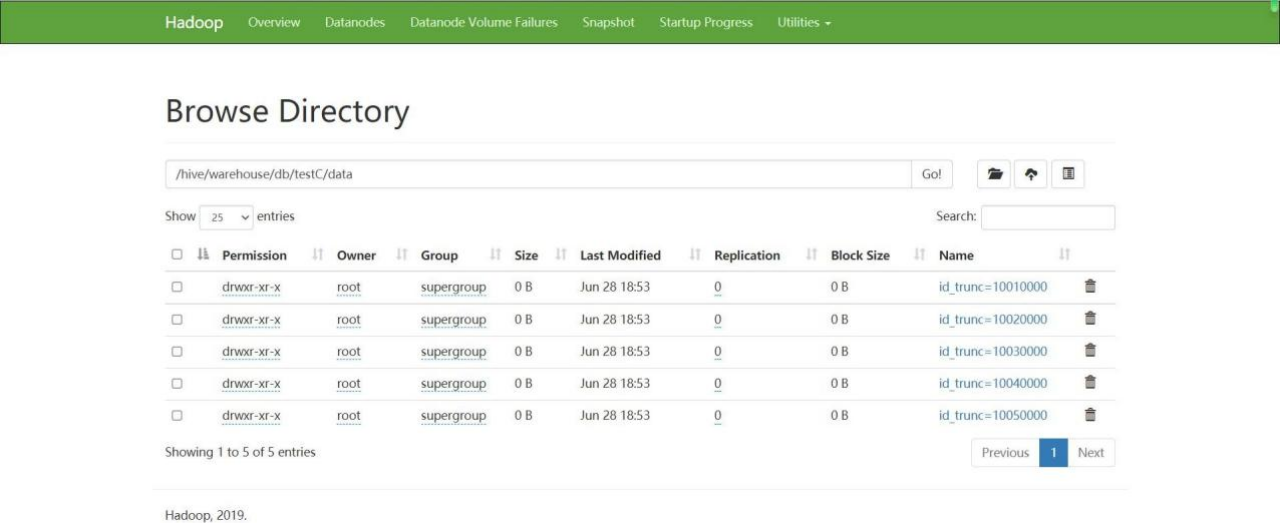
3)查询表数据和 hdfs 地址,分区目录为 id 数/4 得到的值(计算方式是 /不是%)。
spark-sql (default)> select *from hadoop_prod.db.testC;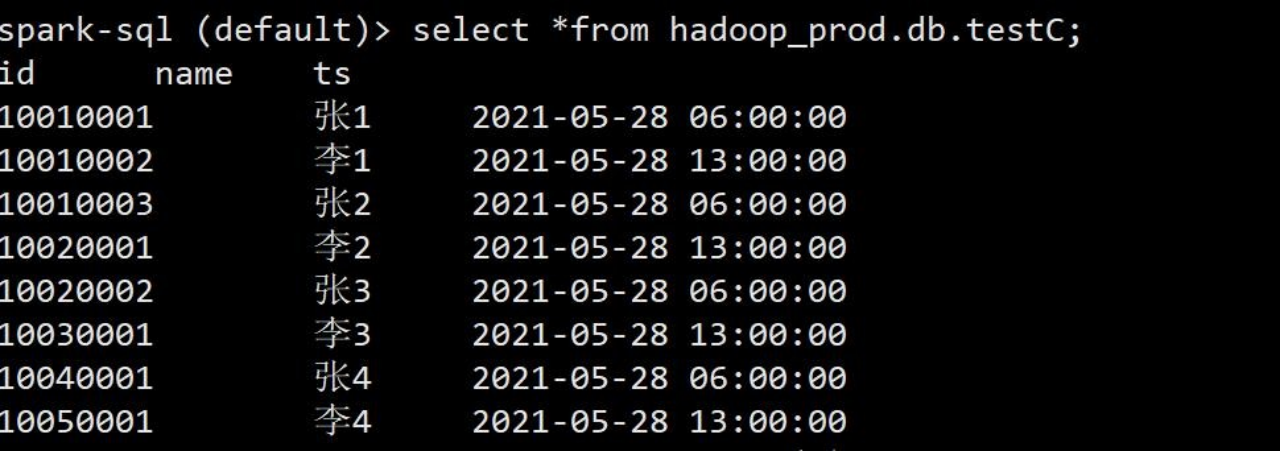
第 4 章 DataFrame 操作
4.1.配置 Resources
1)将自己 hadoop 集群的客户端配置文件复制到 resource 下,方便 local 模式调试
4.2配置 pom.xml
1)配置相关依赖
- <properties>
- <spark.version>3.0.1</spark.version>
- <scala.version>2.12.10</scala.version>
- <log4j.version>1.2.17</log4j.version>
- <slf4j.version>1.7.22</slf4j.version>
- <iceberg.version>0.11.1</iceberg.version>
- </properties>
-
- <dependencies>
- <!-- Spark 的依赖引入 -->
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-core_2.12</artifactId>
- <version>${spark.version}</version>
- </dependency>
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-sql_2.12</artifactId>
- <version>${spark.version}</version>
- </dependency>
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-hive_2.12</artifactId>
- <version>${spark.version}</version>
- </dependency>
- <!-- 引入Scala -->
- <dependency>
- <groupId>org.scala-lang</groupId>
- <artifactId>scala-library</artifactId>
- <version>${scala.version}</version>
- </dependency>
-
- <dependency>
- <groupId>org.apache.iceberg</groupId>
- <artifactId>iceberg-spark3-runtime</artifactId>
- <version>${iceberg.version}</version>
- </dependency>
-
- <dependency>
- <groupId>org.apache.iceberg</groupId>
- <artifactId>iceberg-spark3-extensions</artifactId>
- <version>${iceberg.version}</version>
- </dependency>
-
- <dependency>
- <groupId>com.alibaba</groupId>
- <artifactId>fastjson</artifactId>
- <version>1.2.47</version>
- </dependency>
-
- <!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java -->
- <dependency>
- <groupId>mysql</groupId>
- <artifactId>mysql-connector-java</artifactId>
- <version>5.1.46</version>
- </dependency>
- </dependencies>
-
-
- <build>
- <plugins>
- <plugin>
- <groupId>org.scala-tools</groupId>
- <artifactId>maven-scala-plugin</artifactId>
- <version>2.15.1</version>
- <executions>
- <execution>
- <id>compile-scala</id>
- <goals>
- <goal>add-source</goal>
- <goal>compile</goal>
- </goals>
- </execution>
- <execution>
- <id>test-compile-scala</id>
- <goals>
- <goal>add-source</goal>
- <goal>testCompile</goal>
- </goals>
- </execution>
- </executions>
- </plugin>
- <plugin>
- <groupId>org.apache.maven.plugins</groupId>
- <artifactId>maven-assembly-plugin</artifactId>
- <configuration>
- <archive>
- <manifest>
- </manifest>
- </archive>
- <descriptorRefs>
- <descriptorRef>jar-with-dependencies</descriptorRef>
- </descriptorRefs>
- </configuration>
- </plugin>
- </plugins>
- </build>

4.3读取表
- package com.atguigu.iceberg.spark.sql
-
- import org.apache.spark.SparkConf
- import org.apache.spark.sql.{DataFrame, SparkSession}
-
- object TableOperations {
-
- def main(args: Array[String]): Unit = { val sparkConf = new SparkConf()
- .set("spark.sql.catalog.hadoop_prod", "org.apache.iceberg.spark.SparkCatalog")
- .set("spark.sql.catalog.hadoop_prod.type", "hadoop")
- .set("spark.sql.catalog.hadoop_prod.warehouse", "hdfs://mycluster/hive/warehouse")
- .set("spark.sql.catalog.catalog-name.type", "hadoop")
- .set("spark.sql.catalog.catalog-name.default-namespace", "default")
- .set("spark.sql.sources.partitionOverwriteMode", "dynamic")
- .set("spark.sql.session.timeZone", "GMT+8")
- .setMaster("local[*]").setAppName("table_operations")
-
- val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
- readTale(sparkSession)
-
- }
-
- /**
- *读取iceberg 的表
- *@param sparkSession
- */
- def readTale(sparkSession: SparkSession) = {
- //三种方式sparkSession.table("hadoop_prod.db.testA").show()
- sparkSession.read.format("iceberg").load("hadoop_prod.db.testA").show()
- sparkSession.read.format("iceberg").load("/hive/warehouse/db/testA").show()// 路径到表就行,不要到具体文件
-
- }
- }
4.4读取快照
- def readSnapShots(sparkSession: SparkSession) = {
- //根据查询 hadoop_prod.db.testA.snapshots 快照表可以知道快照时间和快照id
- //根据时间戳读取,必须是时间戳 不能使用格式化后的时间
- sparkSession.read
- .option("as-of-timestamp", "1624961454000") //毫秒时间戳,查询比该值时间更早的快照
- .format("iceberg")
- .load("hadoop_prod.db.testA").show()
-
- //根据快照 id 查询
- sparkSession.read
- .option("snapshot-id", "9054909815461789342")
- .format("iceberg")
- .load("hadoop_prod.db.testA").show()
- }
- }
4.5写入表
4.5.1写入数据并创建表
1)编写代码执行
- case class Student(id: Int, name: String, age: Int, dt: String)
-
- def writeAndCreateTable(sparkSession: SparkSession) = {
- import sparkSession.implicits._
- import org.apache.spark.sql.functions._
- val data = sparkSession.createDataset[Student](Array(Student(1001, " 张 三 ", 18, "2021-06-28"),
- Student(1002, "李四", 19, "2021-06-29"), Student(1003, "王五", 20, "2021-06-29")))
- data.writeTo("hadoop_prod.db.test1").partitionedBy(col("dt")) //指定dt 为分区列
- .create()
- }
- }
2)验证,进入 spark sql 窗口,查看表结构和表数据
- spark-sql (default)> desc test1;
-
- spark-sql (default)> select *from test1;
spark-sql (default)> desc test1;
spark-sql (default)> select *from test1;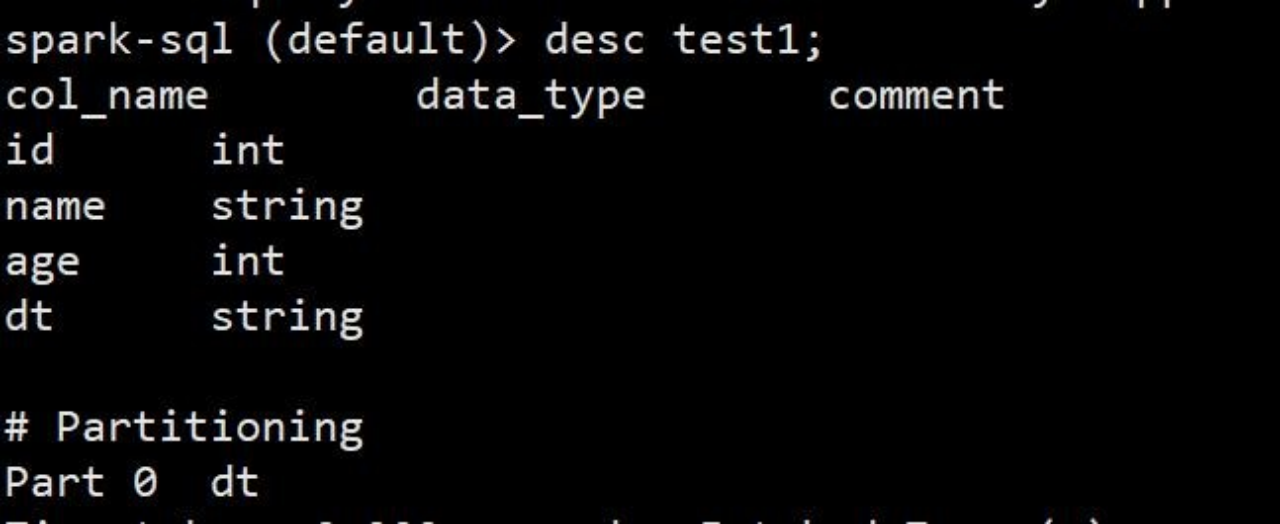
spark-sql (default)> select *from test1;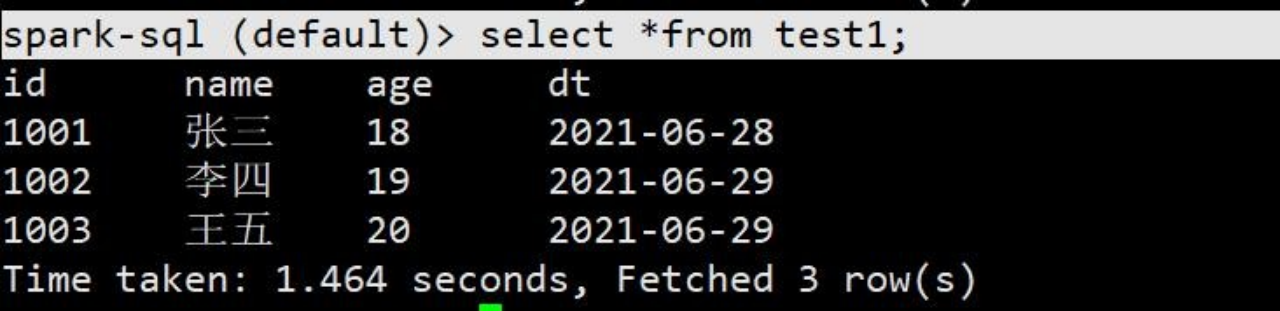 3)查看 hdfs,是否按 dt 进行分区
3)查看 hdfs,是否按 dt 进行分区
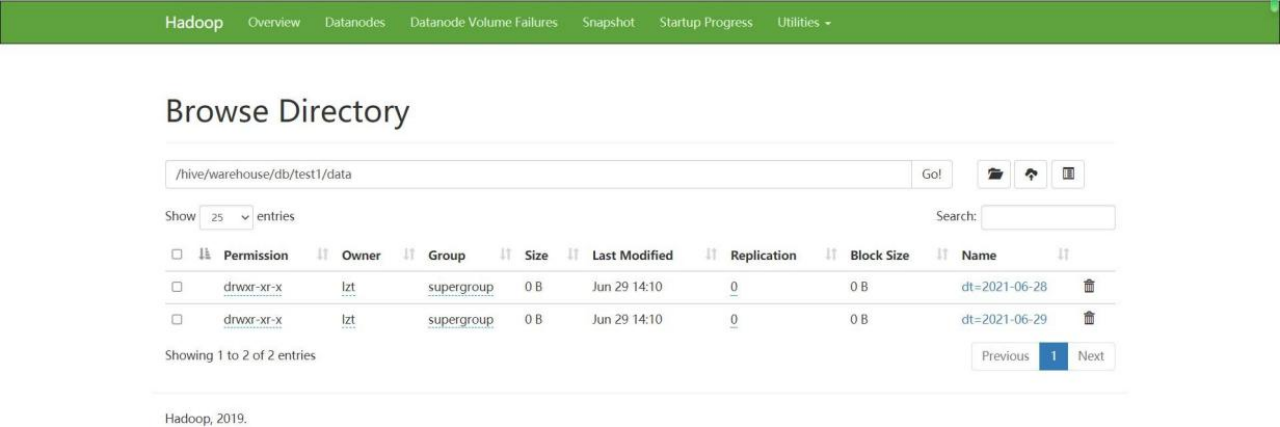
4.5.1写数据
4.5.1.1 Append
1)编写代码,执行
- def AppendTable(sparkSession: SparkSession) = {
- //两种方式
- import sparkSession.implicits._
- val data = sparkSession.createDataset(Array(Student(1003, "王五", 11, "2021-06- 29"), Student(1004, "赵六", 10, "2021-06-30")))
- data.writeTo("hadoop_prod.db.test1").append()// 使 用 DataFrameWriterV2 API
- data.write.format("iceberg").mode("append").save("hadoop_prod.db.test1") // 使 用
- DataFrameWriterV1 API
-
- }
- }
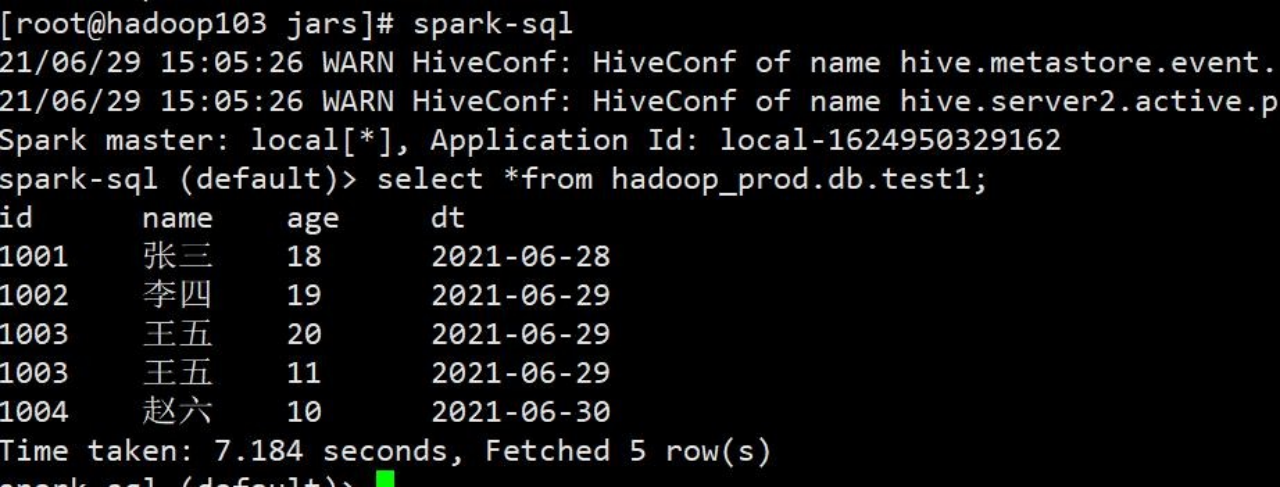
2)执行完毕后进行测试,注意:小 bug,执行完代码后,如果 spark sql 黑窗口不重新打开是不会刷新数据的,只有把 spark sql 窗口界面重新打开才会刷新数据。如果使用代码查询能看到最新数据
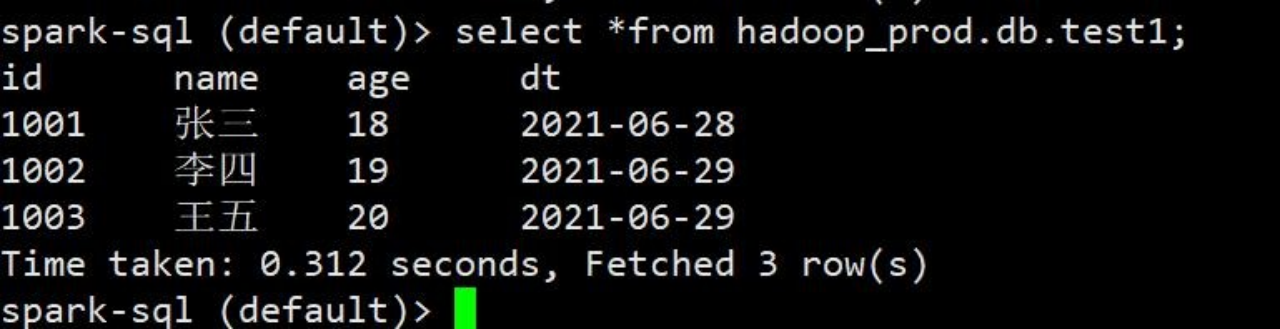
3)关闭,再次进入查询,可以查询到数据
4.5.1.2 OverWrite
1)编写代码,测试
- /**
- *动态覆盖
- *@param sparkSession
- */
- def OverWriteTable(sparkSession: SparkSession)={
- import sparkSession.implicits._
- val data = sparkSession.createDataset(Array(Student(1003, " 王五", 11, "2021-06-29"),
- Student(1004, "赵六", 10, "2021-06-30")))
- data.writeTo("hadoop_prod.db.test1").overwritePartitions() //动态覆盖,只会刷新所属分区数据
- }
2)查询

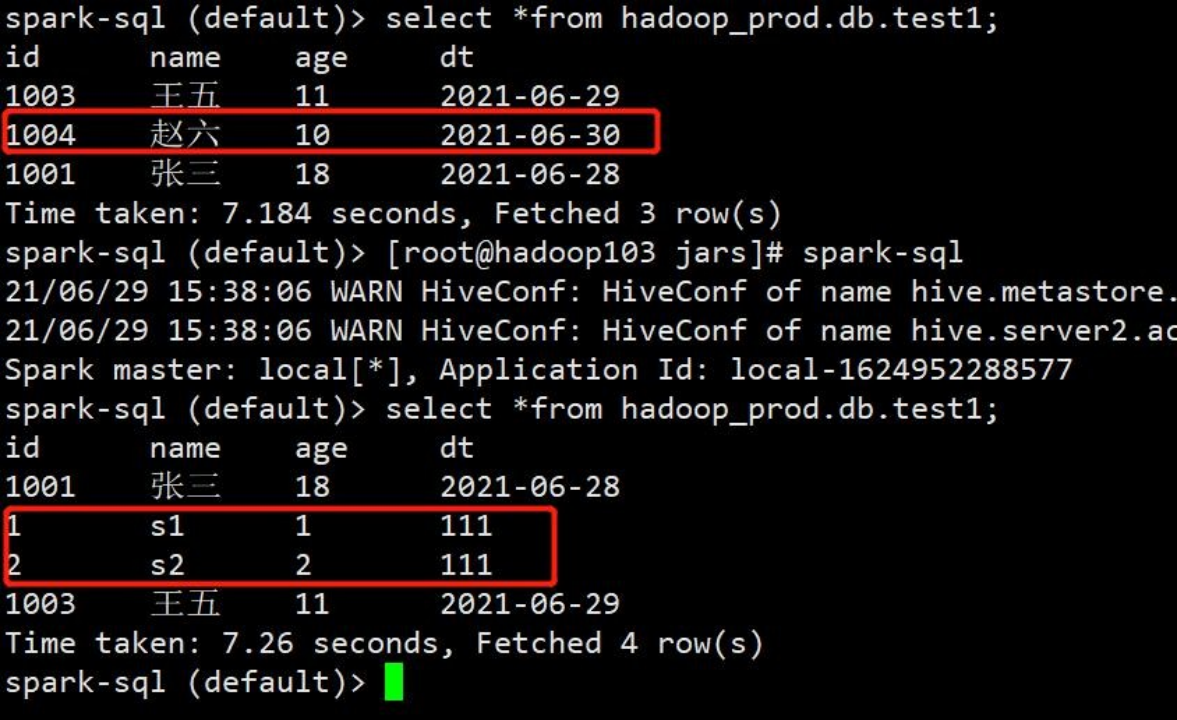
3)显示,手动指定覆盖分区
- def OverWriteTable2(sparkSession: SparkSession) = {
- import sparkSession.implicits._
- val data = sparkSession.createDataset(Array(Student(1, "s1", 1, "111"), Student(2, "s2", 2, "111")))
- data.writeTo("hadoop_prod.db.test1").overwrite($"dt" === "2021-06-30")
- }
4)查询,2021-06-30 分区的数据已经被覆盖走
4.6模拟数仓
4.6.1表模型
(1)表模型,底下 6 张基础表,合成一张宽表,再基于宽表统计指标

4.6.2建表语句
(1)建表语句
- create table hadoop_prod.db.dwd_member(
- uid int,
- ad_id int,
- birthday string,
- email string,
- fullname string,
- iconurl string,
- lastlogin string,
- mailaddr string,
- memberlevel string,
- password string,
- paymoney string,
- phone string,
- qq string,
- register string,
- regupdatetime string,
- unitname string,
- userip string,
- zipcode string,
- dt string)
- using iceberg
- partitioned by(dt);
-
-
- create table hadoop_prod.db.dwd_member_regtype(
- uid int,
- appkey string,
- appregurl string,
- bdp_uuid string,
- createtime timestamp,
- isranreg string,
- regsource string,
- regsourcename string,
- websiteid int,
- dt string)
- using iceberg
- partitioned by(dt);
-
-
- create table hadoop_prod.db.dwd_base_ad(
- adid int,
- adname string,
- dn string)
- using iceberg
- partitioned by (dn) ;
-
-
- create table hadoop_prod.db.dwd_base_website(
- siteid int,
- sitename string,
- siteurl string,
- `delete` int,
- createtime timestamp,
- creator string,
- dn string)
- using iceberg
- partitioned by (dn) ;
-
- create table hadoop_prod.db.dwd_pcentermempaymoney(
- uid int,
- paymoney string,
- siteid int,
- vip_id int,
- dt string,
- dn string)
- using iceberg
- partitioned by(dt,dn);
-
- create table hadoop_prod.db.dwd_vip_level(
- vip_id int,
- vip_level string,
- start_time timestamp,
- end_time timestamp,
- last_modify_time timestamp,
- max_free string,
- min_free string,
- next_level string,
- operator string,
- dn string)
- using iceberg
- partitioned by(dn);
-
-
- create table hadoop_prod.db.dws_member(
- uid int,
- ad_id int,
- fullname string,
- iconurl string,
- lastlogin string,
- mailaddr string,
- memberlevel string,
- password string,
- paymoney string,
- phone string,
- qq string,
- register string,
- regupdatetime string,
- unitname string,
- userip string,
- zipcode string,
- appkey string,
- appregurl string,
- bdp_uuid string,
- reg_createtime timestamp,
- isranreg string,
- regsource string,
- regsourcename string,
- adname string,
- siteid int,
- sitename string,
- siteurl string,
- site_delete string,
- site_createtime string,
- site_creator string,
- vip_id int,
- vip_level string,
- vip_start_time timestamp,
- vip_end_time timestamp,
- vip_last_modify_time timestamp,
- vip_max_free string,
- vip_min_free string,
- vip_next_level string,
- vip_operator string,
- dt string,
- dn string)
- using iceberg
- partitioned by(dt,dn);
-
-
- create table hadoop_prod.db.ads_register_appregurlnum(
- appregurl string,
- num int,
- dt string,
- dn string)
- using iceberg
- partitioned by(dt);
-
- create table hadoop_prod.db.ads_register_top3memberpay(
- uid int,
- memberlevel string,
- register string,
- appregurl string,
- regsourcename string,
- adname string,
- sitename string,
- vip_level string,
- paymoney decimal(10,4),
- rownum int,
- dt string,
- dn string)
- using iceberg
- partitioned by(dt);
4.6.3测试数据
(1)测试数据上传到 hadoop,作为第一层 ods
- [root@hadoop103 software]# hadoop dfs -mkdir /ods
- [root@hadoop103 software]# hadoop dfs -put *.log /ods
4.6.4 编写代码
4.6.4.1 dwd 层
1)创建目录,划分层级
2)编写所需实体类
- package com.atguigu.iceberg.warehouse.bean
- import java.sql.Timestamp
-
- case class BaseWebsite(
- siteid: Int, sitename: String, siteurl: String, delete: Int, createtime:
- Timestamp, creator: String,
- dn: String
- )
-
- case class MemberRegType(
- uid: Int, appkey: String,
- appregurl: String,
- bdp_uuid: String, createtime: Timestamp,
- isranreg: String, regsource: String, regsourcename: String, websiteid: Int,
- dt: String
- )
-
- case class VipLevel(
- vip_id: Int, vip_level: String, start_time: Timestamp, end_time: Timestamp,
- last_modify_time: Timestamp, max_free: String,
- min_free: String, next_level: String, operator: String, dn: String
- )
3)编写 DwdIcebergService
- package com.atguigu.iceberg.warehouse.service
-
-
- import java.sql.Timestamp import java.time.LocalDate
- import java.time.format.DateTimeFormatter
- import com.atguigu.iceberg.warehouse.bean.{BaseWebsite, MemberRegType, VipLevel} import org.apache.spark.sql.SparkSession
-
-
-
- object DwdIcebergService {
-
-
- def readOdsData(sparkSession: SparkSession) = {
-
- import org.apache.spark.sql.functions._
- import sparkSession.implicits._
- sparkSession.read.json("/ods/baseadlog.log")
- .withColumn("adid", col("adid").cast("Int"))
- .writeTo("hadoop_prod.db.dwd_base_ad").overwritePartitions()
-
-
- sparkSession.read.json("/ods/baswewebsite.log").map(item => { val createtime = item.getAs[String]("createtime")
-
- val str = LocalDate.parse(createtime, DateTimeFormatter.ofPattern("yyyy-MM-dd")).atStartOfDay().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"))
-
- BaseWebsite(item.getAs[String]("siteid").toInt, item.getAs[String]("sitename"),
-
- item.getAs[String]("siteurl"), item.getAs[String]("delete").toInt,
- Timestamp.valueOf(str), item.getAs[String]("creator"), item.getAs[String]("dn"))
-
- }).writeTo("hadoop_prod.db.dwd_base_website").overwritePartitions()
-
-
-
- sparkSession.read.json("/ods/member.log").drop("dn")
- .withColumn("uid", col("uid").cast("int"))
- .withColumn("ad_id", col("ad_id").cast("int"))
- .writeTo("hadoop_prod.db.dwd_member").overwritePartitions()
-
-
-
- sparkSession.read.json("/ods/memberRegtype.log").drop("domain").drop("dn")
- .withColumn("regsourcename", col("regsource"))
- .map(item => {
-
- val createtime = item.getAs[String]("createtime")
- val str = LocalDate.parse(createtime, DateTimeFormatter.ofPattern("yyyy-MM-dd")).atStartOfDay().
- format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")) MemberRegType(item.getAs[String]("uid").toInt, item.getAs[String]("appkey"),
-
-
-
- item.getAs[String]("appregurl"), item.getAs[String]("bdp_uuid"), Timestamp.valueOf(str), item.getAs[String]("isranreg"), item.getAs[String]("regsource"), item.getAs[String]("regsourcename"), item.getAs[String]("websiteid").toInt, item.getAs[String]("dt"))
-
- }).writeTo("hadoop_prod.db.dwd_member_regtype").overwritePartitions()
-
-
-
- sparkSession.read.json("/ods/pcenterMemViplevel.log").drop("discountval")
-
- .map(item => {
-
- val startTime = item.getAs[String]("start_time") val endTime = item.getAs[String]("end_time")
-
- val last_modify_time = item.getAs[String]("last_modify_time")
-
- val startTimeStr = LocalDate.parse(startTime, DateTimeFormatter.ofPattern("yyyy-MM-
- dd")).atStartOfDay().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"))
-
- val endTimeStr = LocalDate.parse(endTime, DateTimeFormatter.ofPattern("yyyy-MM-dd")).atStartOfDay().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"))
-
- val last_modify_timeStr = LocalDate.parse(last_modify_time,
- DateTimeFormatter.ofPattern("yyyy-MM-dd")).atStartOfDay().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"))
- VipLevel(item.getAs[String]("vip_id").toInt, item.getAs[String]("vip_level"),
-
- Timestamp.valueOf(startTimeStr), Timestamp.valueOf(endTimeStr),
- Timestamp.valueOf(last_modify_timeStr),
-
- item.getAs[String]("max_free"), item.getAs[String]("min_free"),
- item.getAs[String]("next_level"), item.getAs[String]("operator"),
- item.getAs[String]("dn"))
-
- }).writeTo("hadoop_prod.db.dwd_vip_level").overwritePartitions()
-
-
-
- sparkSession.read.json("/ods/pcentermempaymoney.log")
-
- .withColumn("uid", col("uid").cast("int"))
- .withColumn("siteid", col("siteid").cast("int"))
- .withColumn("vip_id", col("vip_id").cast("int"))
- .writeTo("hadoop_prod.db.dwd_pcentermempaymoney").overwritePartitions()
-
- }
-
- }
4).编写 DwdIcebergController
- package com.atguigu.iceberg.warehouse.controller
-
- import com.atguigu.iceberg.warehouse.service.DwdIcebergService import org.apache.spark.SparkConf
- import org.apache.spark.sql.SparkSession
-
- object DwdIcebergController {
-
- def main(args: Array[String]): Unit = {
- val sparkConf = new SparkConf()
- .set("spark.sql.catalog.hadoop_prod", "org.apache.iceberg.spark.SparkCatalog")
- .set("spark.sql.catalog.hadoop_prod.type", "hadoop")
- .set("spark.sql.catalog.hadoop_prod.warehouse",
- "hdfs://mycluster/hive/warehouse")
- .set("spark.sql.catalog.catalog-name.type", "hadoop")
- .set("spark.sql.catalog.catalog-name.default-namespace", "default")
- .set("spark.sql.sources.partitionOverwriteMode", "dynamic")
- .set("spark.sql.session.timeZone", "GMT+8")
- .setMaster("local[*]").setAppName("table_operations")
- val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
- DwdIcebergService.readOdsData(sparkSession)
- }
-
- }
4.6.4.2 dws 层(表指定多个分区列会有 bug)
1)创建 case class
- case class DwsMember(
- uid: Int, ad_id: Int,
- fullname: String, iconurl: String, lastlogin: String, mailaddr: String,
- memberlevel: String, password: String, paymoney: String, phone: String,
- qq: String, register: String,
- regupdatetime: String, unitname: String, userip: String, zipcode: String, appkey:
- String, appregurl: String, bdp_uuid: String, reg_createtime: String, isranreg:
- String, regsource: String, regsourcename: String, adname: String, siteid:
- String, sitename: String, siteurl: String, site_delete: String,
- site_createtime: String, site_creator: String, vip_id: String, vip_level: String,
- vip_start_time: String, vip_end_time: String,
- vip_last_modify_time: String, vip_max_free: String, vip_min_free: String,
- vip_next_level: String, vip_operator: String,
- dt: String, dn: String
- )
-
-
- case class DwsMember_Result(
- uid: Int, ad_id: Int,
- fullname: String, iconurl: String, lastlogin: String, mailaddr: String,
- memberlevel: String,
- password: String,
- paymoney: String, phone: String, qq: String, register: String,
- regupdatetime: String, unitname: String, userip: String, zipcode: String, appkey:
- String, appregurl: String, bdp_uuid: String,
- reg_createtime: Timestamp, isranreg: String, regsource: String, regsourcename:
- String, adname: String,
- siteid: Int, sitename: String, siteurl: String, site_delete: String,
- site_createtime: String, site_creator: String, vip_id: Int,
- vip_level: String, vip_start_time: Timestamp, vip_end_time: Timestamp,
- vip_last_modify_time: Timestamp, vip_max_free: String, vip_min_free: String,
- vip_next_level: String, vip_operator: String,
- dt: String, dn: String
- )
2)创建 DwdIcebergDao 操作六张基础表
- package com.atguigu.iceberg.warehouse.dao
-
- import org.apache.spark.sql.SparkSession
-
-
- object DwDIcebergDao {
- def getDwdMember(sparkSession: SparkSession) = {
- sparkSession.sql("selectuid,ad_id
- ,birthday,email,fullname,iconurl,lastlogin,mailaddr,memberlevel," +
- "password,phone,qq,register,regupdatetime,unitname,userip,zipcode,dt
- from hadoop_prod.db.dwd_member")
- }
-
- }
-
-
- def getDwdPcentermempaymoney(sparkSession: SparkSession) = {
-
- sparkSession.sql("select uid,paymoney,siteid,vip_id,dt,dn
- hadoop_prod.db.dwd_pcentermempaymoney")
- }
-
- def getDwdVipLevel(sparkSession: SparkSession) = {
-
- sparkSession.sql("select vip_id,vip_level,start_time as
- vip_start_time,end_time as vip_end_time," +
- "last_modify_time as vip_last_modify_time,max_free as vip_max_free,min_free
- as vip_min_free,next_level as vip_next_level," +
- "operator as vip_operator,dn from hadoop_prod.db.dwd_vip_level")
- }
-
- def getDwdBaseWebsite(sparkSession: SparkSession) = {
-
- sparkSession.sql("select siteid,sitename,siteurl,delete as
- site_delete,createtime as site_createtime,creator as site_creator" +
- ",dn from hadoop_prod.db.dwd_base_website")
-
- }
-
- def getDwdMemberRegtyp(sparkSession: SparkSession) = {
- sparkSession.sql("select uid,appkey,appregurl,bdp_uuid,createtime as
- reg_createtime,isranreg,regsource,regsourcename,websiteid," +
- "dt from hadoop_prod.db.dwd_member_regtype")
- }
-
- def getDwdBaseAd(sparkSession: SparkSession) = {
- sparkSession.sql("select adid as ad_id,adname,dn from
- hadoop_prod.db.dwd_base_ad;")
- }
3)编写 DwsIcebergService,处理业务
- package com.atguigu.iceberg.warehouse.service
-
- import java.sql.Timestamp import java.time.LocalDateTime
- import java.time.format.DateTimeFormatter
-
- import com.atguigu.iceberg.warehouse.bean.{DwsMember, DwsMember_Result} import com.atguigu.iceberg.warehouse.dao.DwDIcebergDao
- import org.apache.spark.sql.SparkSession
-
- object DwsIcebergService {
-
-
- def getDwsMemberData(sparkSession: SparkSession, dt: String) = {
-
- import sparkSession.implicits._
- val dwdPcentermempaymoney =
- DwDIcebergDao.getDwdPcentermempaymoney(sparkSession).where($"dt" === dt)
- val dwdVipLevel = DwDIcebergDao.getDwdVipLevel(sparkSession)
- val dwdMember = DwDIcebergDao.getDwdMember(sparkSession).where($"dt" === dt)
- val dwdBaseWebsite = DwDIcebergDao.getDwdBaseWebsite(sparkSession)
- val dwdMemberRegtype =
- DwDIcebergDao.getDwdMemberRegtyp(sparkSession).where($"dt" ===dt)
-
-
- val dwdBaseAd = DwDIcebergDao.getDwdBaseAd(sparkSession)
- val result = dwdMember.join(dwdMemberRegtype.drop("dt"), Seq("uid"), "left")
- .join(dwdPcentermempaymoney.drop("dt"), Seq("uid"), "left")
- .join(dwdBaseAd, Seq("ad_id", "dn"), "left")
- .join(dwdBaseWebsite, Seq("siteid", "dn"), "left")
- .join(dwdVipLevel, Seq("vip_id", "dn"), "left_outer")
- .select("uid", "ad_id", "fullname", "iconurl", "lastlogin", "mailaddr",
- "memberlevel","password", "paymoney", "phone", "qq",
- "register","regupdatetime", "unitname", "userip", "zipcode", "appkey",
- "appregurl", "bdp_uuid", "reg_createtime", "isranreg", "regsource",
- "regsourcename", "adname", "siteid", "sitename", "siteurl", "site_delete",
- "site_createtime", "site_creator", "vip_id", "vip_level",
- "vip_start_time", "vip_end_time", "vip_last_modify_time", "vip_max_free",
- "vip_min_free", "vip_next_level", "vip_operator", "dt", "dn").as[DwsMember]
-
- val resultData = result.groupByKey(item => item.uid + "_" + item.dn)
- .mapGroups {
- case (key, iters) => val keys = key.split("_")
- val uid = Integer.parseInt(keys(0)) val dn = keys(1)
- val dwsMembers = iters.toList
- val paymoney =
- dwsMembers.filter(_.paymoney!=null).map(item=>BigDecimal.apply(item.paymoney)).reduceOption(_ +
- _).getOrElse(BigDecimal.apply(0.00)).toString
- val ad_id = dwsMembers.map(_.ad_id).head
- val fullname = dwsMembers.map(_.fullname).head
- val icounurl = dwsMembers.map(_.iconurl).head
- val lastlogin = dwsMembers.map(_.lastlogin).head
- val mailaddr = dwsMembers.map(_.mailaddr).head
- val memberlevel = dwsMembers.map(_.memberlevel).head
- val password = dwsMembers.map(_.password).head
- val phone = dwsMembers.map(_.phone).head
- val qq = dwsMembers.map(_.qq).head
- val register = dwsMembers.map(_.register).head
- val regupdatetime = dwsMembers.map(_.regupdatetime).head
- val unitname = dwsMembers.map(_.unitname).head
- val userip = dwsMembers.map(_.userip).head
- val zipcode = dwsMembers.map(_.zipcode).head
- val appkey = dwsMembers.map(_.appkey).head
- val appregurl = dwsMembers.map(_.appregurl).head
- val bdp_uuid = dwsMembers.map(_.bdp_uuid).head
- val reg_createtime = if (dwsMembers.map(_.reg_createtime).head != null)
- dwsMembers.map(_.reg_createtime).head else "1970-01-01 00:00:00" val isranreg =
- dwsMembers.map(_.isranreg).head
- val regsource = dwsMembers.map(_.regsource).head
- val regsourcename = dwsMembers.map(_.regsourcename).head val adname =
- dwsMembers.map(_.adname).head
- val siteid = if (dwsMembers.map(_.siteid).head != null)
- dwsMembers.map(_.siteid).head else "0"
- val sitename = dwsMembers.map(_.sitename).head val siteurl =
- dwsMembers.map(_.siteurl).head
- val site_delete = dwsMembers.map(_.site_delete).head
- val site_createtime = dwsMembers.map(_.site_createtime).head val site_creator =
- dwsMembers.map(_.site_creator).head
- val vip_id = if (dwsMembers.map(_.vip_id).head != null)
- dwsMembers.map(_.vip_id).head else "0"
- val vip_level = dwsMembers.map(_.vip_level).max
- val vip_start_time = if (dwsMembers.map(_.vip_start_time).min != null)
- dwsMembers.map(_.vip_start_time).min else "1970-01-01 00:00:00"
- val vip_end_time = if (dwsMembers.map(_.vip_end_time).max != null)
- dwsMembers.map(_.vip_end_time).max else "1970-01-01 00:00:00"
- val vip_last_modify_time = if (dwsMembers.map(_.vip_last_modify_time).max != null)
- dwsMembers.map(_.vip_last_modify_time).max else "1970-01-01 00:00:00"
- val vip_max_free = dwsMembers.map(_.vip_max_free).head val vip_min_free =
- dwsMembers.map(_.vip_min_free).head val vip_next_level =
- dwsMembers.map(_.vip_next_level).head val vip_operator =
- dwsMembers.map(_.vip_operator).head
- val formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")
- val reg_createtimeStr = LocalDateTime.parse(reg_createtime, formatter); val
- vip_start_timeStr = LocalDateTime.parse(vip_start_time, formatter) val
- vip_end_timeStr = LocalDateTime.parse(vip_end_time, formatter)
- val vip_last_modify_timeStr = LocalDateTime.parse(vip_last_modify_time, formatter)
- DwsMember_Result(uid, ad_id, fullname, icounurl, lastlogin, mailaddr,
- memberlevel,password, paymoney,phone, qq, register, regupdatetime,
- unitname,userip, zipcode, appkey,
- appregurl,bdp_uuid,Timestamp.valueOf(reg_createtimeStr), isranreg,
- regsource,regsourcename, adname, siteid.toInt,
- sitename, siteurl, site_delete, site_createtime, site_creator, vip_id.toInt,
- vip_level,Timestamp.valueOf(vip_start_timeStr),
- Timestamp.valueOf(vip_end_timeStr),
- Timestamp.valueOf(vip_last_modify_timeStr), vip_max_free, vip_min_free,
- vip_next_level, vip_operator, dt, dn)
-
- }
-
- resultData.write.format("iceberg").mode("overwrite").
- save("hadoop_prod.db.dws_member")
-
- }
-
-
- }
4)编写 DwsIcebergController,进行运行测试
- package com.atguigu.iceberg.warehouse.controller
-
- import com.atguigu.iceberg.warehouse.service.DwsIcebergService
- import org.apache.spark.SparkConf
- import org.apache.spark.sql.SparkSession
-
- object DwsIcebergController {
-
- def main(args: Array[String]): Unit = {
- val sparkConf = new SparkConf()
- .set("spark.sql.catalog.hadoop_prod", "org.apache.iceberg.spark.SparkCatalog")
- .set("spark.sql.catalog.hadoop_prod.type", "hadoop")
- .set("spark.sql.catalog.hadoop_prod.warehouse",
- "hdfs://mycluster/hive/warehouse")
- .set("spark.sql.catalog.catalog-name.type", "hadoop")
- .set("spark.sql.catalog.catalog-name.default-namespace", "default")
- .set("spark.sql.sources.partitionOverwriteMode", "dynamic")
- .set("spark.sql.session.timeZone", "GMT+8")
- .setMaster("local[*]").setAppName("table_operations")
-
- val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
- DwsIcebergService.getDwsMemberData(sparkSession, "20190722")
- }
- }
5)发生报错,和上面在 spark sql 黑窗口测试的错误一致,当有批量数据插入分区时提示分区已关闭无法插入
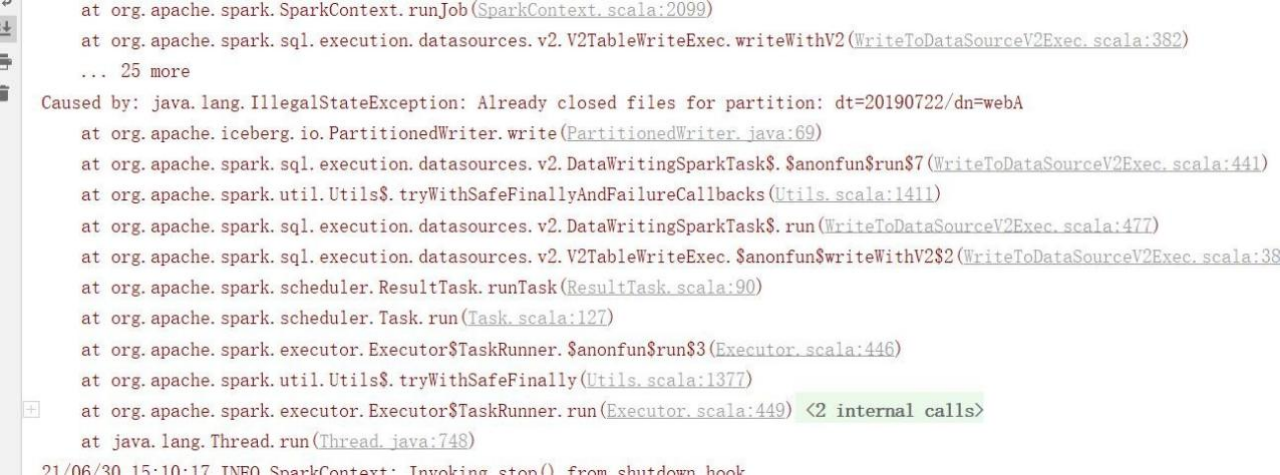
6)重新建表,分区列去掉 dn,只用 dt,bug:不能指定多个分区,只能指定一个分区列
- spark-sql (default)> drop table hadoop_prod.db.dws_member; create table hadoop_prod.db.dws_member(
- uid int, ad_id int,
- fullname string, iconurl string, lastlogin string, mailaddr string, memberlevel
- string, password string, paymoney string, phone string,
- register string, regupdatetime string, unitname string, userip string, zipcode
- string, appkey string, appregurl string, bdp_uuid string,
- reg_createtime timestamp, isranreg string, regsource string, regsourcename
- string, adname string,
- siteid int, sitename string, siteurl string, site_delete string,
- site_createtime string, site_creator string, vip_id int,
- vip_level string, vip_start_time timestamp, vip_end_time timestamp,
- vip_last_modify_time timestamp, vip_max_free string, vip_min_free string,
- vip_next_level string, vip_operator string,
- dt string, dn string)
- using iceberg
- partitioned by(dt);
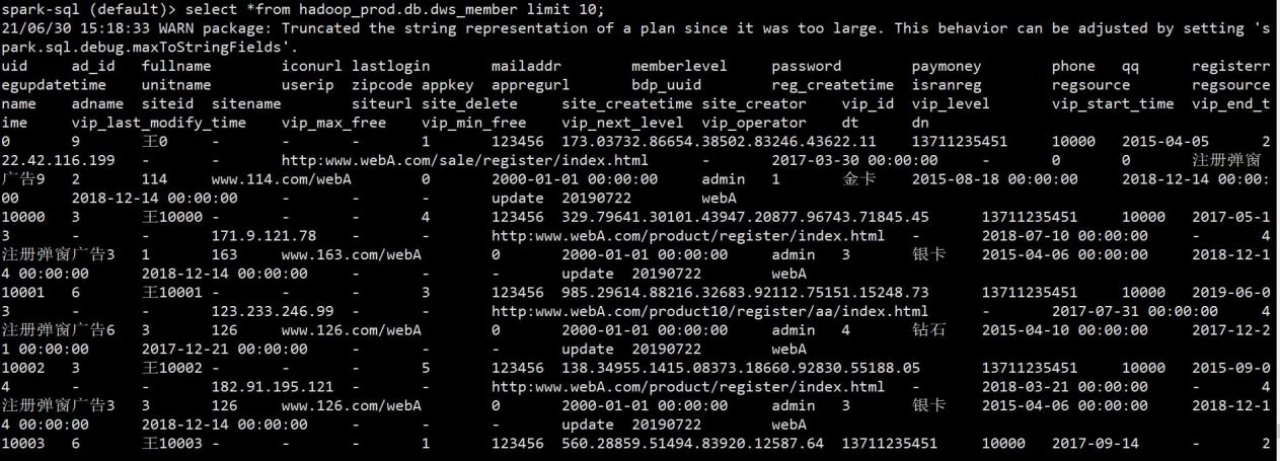
7)建完表后,重新测试,插入数据成功
4.6.4.3 ads 层
1)编写所需 case class
- case class QueryResult(
- uid: Int, ad_id: Int,
- memberlevel: String, register: String,
- appregurl: String, //注册来源url
- regsource: String, regsourcename: String,
- adname: String, siteid: String, sitename: String, vip_level: String, paymoney:
- BigDecimal, dt: String,
- dn: String
- )
2)编写 DwsIcebergDao,查询宽表
- package com.atguigu.iceberg.warehouse.dao
-
- import org.apache.spark.sql.SparkSession
-
- object DwsIcebergDao {
- /**
- *查询用户宽表数据
- *
- *@param sparkSession
- *@return
- */
- def queryDwsMemberData(sparkSession: SparkSession) = {
- sparkSession.sql("select
- uid,ad_id,memberlevel,register,appregurl,regsource,regsourcename,adname,"
- + "siteid,sitename,vip_level,cast(paymoney as decimal(10,4)) as
- paymoney,dt,dn from hadoop_prod.db.dws_member ")
- }
- }
3)编写 AdsIcebergService,统计指标
- package com.atguigu.iceberg.warehouse.service
-
- import com.atguigu.iceberg.warehouse.bean.QueryResult
- import com.atguigu.iceberg.warehouse.dao.DwsIcebergDao
- import org.apache.spark.sql.expressions.Window
- import org.apache.spark.sql.{SaveMode, SparkSession}
-
- object AdsIcebergService {
-
- def queryDetails(sparkSession: SparkSession, dt: String) = {
- import sparkSession.implicits._
- val result =
- DwsIcebergDao.queryDwsMemberData(sparkSession).as[QueryResult].where(s"dt='${dt}'")
- result.cache()
-
- //统计根据 url 统计人数 wordcount result.mapPartitions(partition => {
- partition.map(item => (item.appregurl + "_" + item.dn + "_" + item.dt, 1))
- }).groupByKey(_._1).mapValues(item => item._2).reduceGroups(_ + _).map(item => {
- val keys = item._1.split("_") val appregurl = keys(0)
- val dn = keys(1) val dt = keys(2)
- (appregurl, item._2, dt, dn)
- }).toDF("appregurl", "num", "dt", "dn").writeTo("hadoop_prod.db.ads_register_appregurlnum").overwritePartitions()
-
- //统计各 memberlevel 等级 支付金额前三的用户
- import org.apache.spark.sql.functions._
-
- result.withColumn("rownum",row_number().over(Window.partitionBy("memberlevel").
- orderBy(desc("paymoney"))))
- .where("rownum<4").orderBy("memberlevel", "rownum")
- .select("uid", "memberlevel", "register", "appregurl", "regsourcename",
- "adname", "sitename", "vip_level", "paymoney", "rownum", "dt", "dn")
- .writeTo("hadoop_prod.db.ads_register_top3memberpay").overwritePartitions()
- }
- }
4)编写 AdsIcebergController,进行本地测试
- package com.atguigu.iceberg.warehouse.controller
-
- import com.atguigu.iceberg.warehouse.service.AdsIcebergService
- import org.apache.spark.SparkConf
- import org.apache.spark.sql.SparkSession
-
- object AdsIcebergController {
- def main(args: Array[String]): Unit = {
- val sparkConf = new SparkConf()
- .set("spark.sql.catalog.hadoop_prod", "org.apache.iceberg.spark.SparkCatalog")
- .set("spark.sql.catalog.hadoop_prod.type", "hadoop")
- .set("spark.sql.catalog.hadoop_prod.warehouse", "hdfs://mycluster/hive/warehouse")
- .set("spark.sql.catalog.catalog-name.type", "hadoop")
- .set("spark.sql.catalog.catalog-name.default-namespace", "default")
- .set("spark.sql.sources.partitionOverwriteMode", "dynamic")
- .set("spark.sql.session.timeZone", "GMT+8")
- .setMaster("local[*]").setAppName("dwd_app")
- val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
- AdsIcebergService.queryDetails(sparkSession, "20190722")
- }
- }
5)查询,验证结果
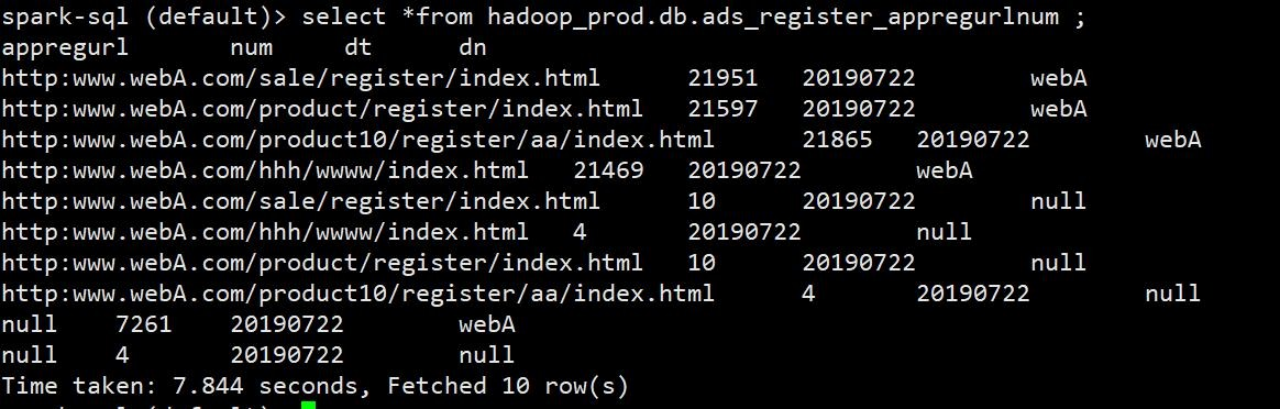
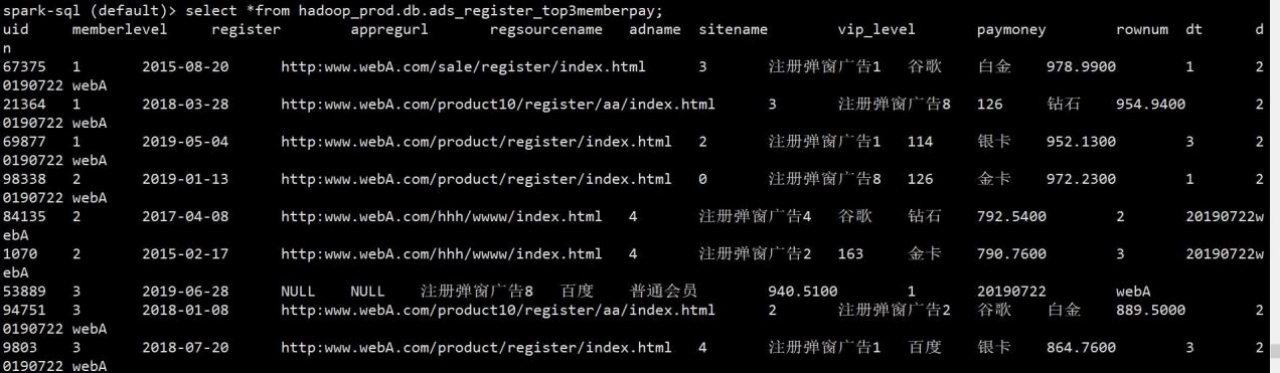
4.6.5 yarn 测试
1)local 模式测试完毕后,将代码打成 jar 包,提交到集群上进行测试,那么插入模式当前都是为 overwrite 模式,所以在 yarn 上测试的时候也无需删除历史数据
2)打 jar 包之前,注意将代码中 setMast(local[*]) 注释了,把集群上有的依赖也可用<scope>provided</scope>剔除了打一个瘦包
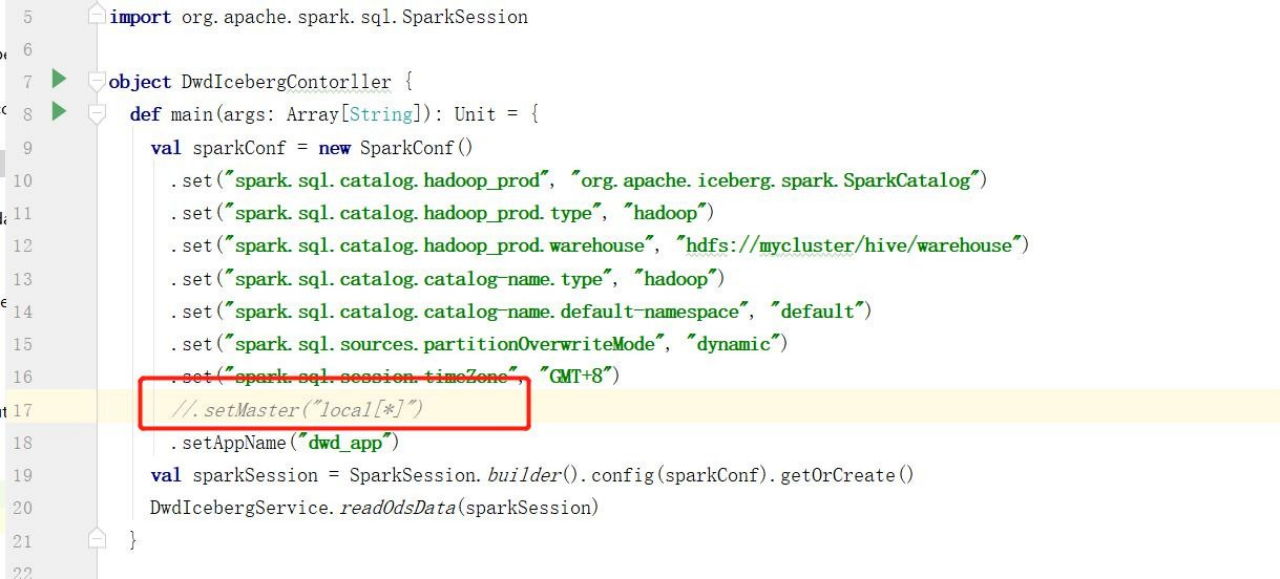
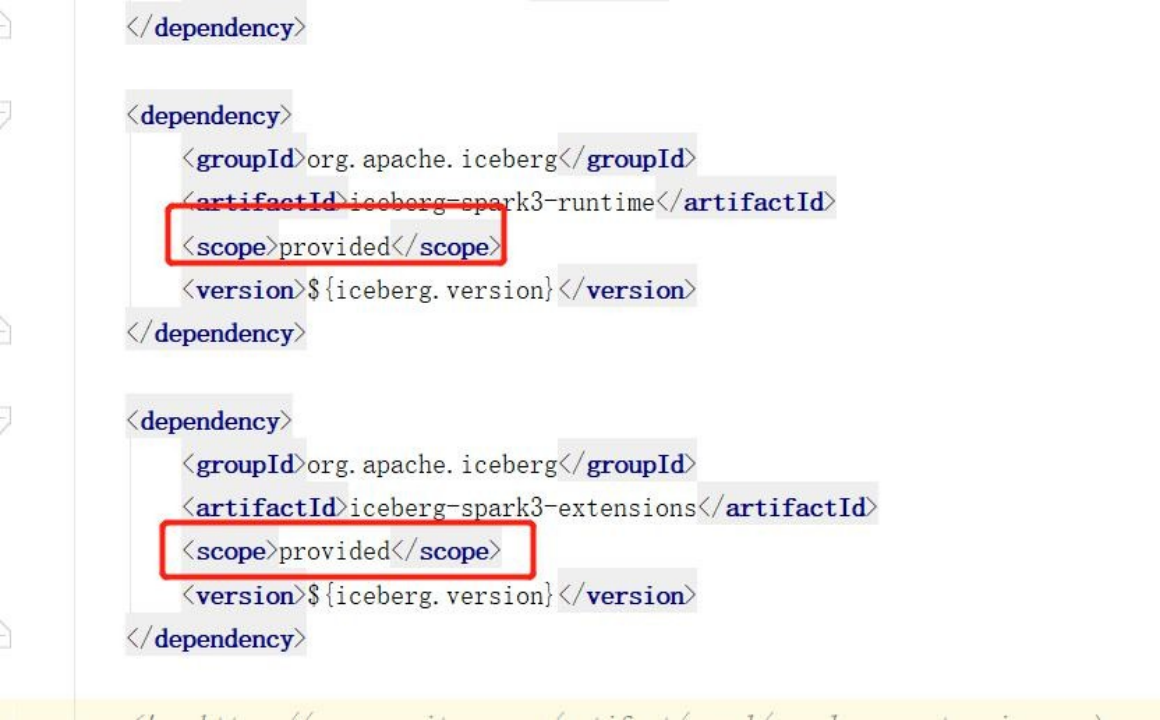
3)打成 jar 包提交到集群,运行 spark-submit 命令运行 yarn 模式。
- spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3
- --executor-cores 4 --executor-memory 2g --queue spark --class com.atguigu.iceberg.warehouse.controller.DwdIcebergContorller
- iceberg-spark-demo-1.0-SNAPSHOT-jar-with-dependencies.jar
-
- spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3
- --executor-cores 4 --executor-memory 2g --queue spark --class com.atguigu.iceberg.warehouse.controller.DwsIcebergController
- iceberg-spark-demo-1.0-SNAPSHOT-jar-with-dependencies.jar
-
- spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3
- --executor-cores 4 --executor-memory 2g --queue spark --class com.atguigu.iceberg.warehouse.controller.AdsIcebergController
- iceberg-spark-demo-1.0-SNAPSHOT-jar-with-dependencies.jar
第 5 章 Structured Streaming 操作
5.1 基于 Structured Streaming 落明细数据
5.1.1创建测试 topic
- [root@hadoop103 kafka_2.11-2.4.0]# bin/kafka-topics.sh --zookeeper
- hadoop102:2181/kafka_2.4 --create --replication-factor 2 --partitions 12 --topic test1
1)启动 kafka,创建测试用的 topic
2)导入依赖
编写 producer 往 topic 里发送测试数据
- package com.atguigu.iceberg.spark.structuredstreaming;
-
- import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord;
-
- import java.util.Properties; import java.util.Random;
-
- public class TestProducer {
-
- public static void main(String[] args) {
- Properties props = new Properties();
- props.put("bootstrap.servers", "hadoop101:9092,hadoop102:9092,hadoop103:9092");
- props.put("acks", "-1");
- props.put("batch.size", "1048576");
- props.put("linger.ms", "5"); props.put("compression.type", "snappy");
- props.put("buffer.memory", "33554432"); props.put("key.serializer",
- "org.apache.kafka.common.serialization.StringSerializer");
- props.put("value.serializer",
- "org.apache.kafka.common.serialization.StringSerializer"); KafkaProducer<String,
- String> producer = new KafkaProducer<String, String>(props); Random random = new
- Random();
- for (int i = 0; i < 10000000; i++) {
- producer.send(new ProducerRecord<String,String>
- ("test1",i+"\t"+random.nextInt(100)+"\t"+random.nextInt(3)
- +"\t"+System.currentTimeMillis()));
- }
- producer.flush(); producer.close();
- }
- }
3)创建测试表
- create table hadoop_prod.db.test_topic( uid bigint,
- courseid int, deviceid int, ts timestamp)
- using iceberg partitioned by(days(ts));
5.3 编写代码
基于 test1 的测试数据,编写结构化流代码,进行测试
- package com.atguigu.iceberg.spark.structuredstreaming
-
- import java.sql.Timestamp
-
- import org.apache.spark.SparkConf
- import org.apache.spark.sql.{Dataset, SparkSession}
-
- object TestTopicOperators {
- def main(args: Array[String]): Unit = {
- val sparkConf = new SparkConf()
- .set("spark.sql.catalog.hadoop_prod", "org.apache.iceberg.spark.SparkCatalog")
- .set("spark.sql.catalog.hadoop_prod.type", "hadoop")
- .set("spark.sql.catalog.hadoop_prod.warehouse",
- "hdfs://mycluster/hive/warehouse")
- .set("spark.sql.catalog.catalog-name.type", "hadoop")
- .set("spark.sql.catalog.catalog-name.default-namespace", "default")
- .set("spark.sql.sources.partitionOverwriteMode", "dynamic")
- .set("spark.sql.session.timeZone", "GMT+8")
- .set("spark.sql.shuffle.partitions", "12")
- //.setMaster("local[*]")
- .setAppName("test_topic")
- val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate() val
- df = sparkSession.readStream.format("kafka")
- .option("kafka.bootstrap.servers",
- "hadoop101:9092,hadoop102:9092,hadoop103:9092")
- .option("subscribe", "test1")
- .option("startingOffsets", "earliest")
- .option("maxOffsetsPerTrigger", "10000").load()
-
-
- import sparkSession.implicits._
-
-
- val query = df.selectExpr("cast (value as string)").as[String]
- .map(item => {
- val array = item.split("\t") val uid = array(0)
- val courseid = array(1) val deviceid = array(2) val ts = array(3)
- Test1(uid.toLong, courseid.toInt, deviceid.toInt, new Timestamp(ts.toLong))
- }).writeStream.foreachBatch { (batchDF: Dataset[Test1], batchid: Long) =>
- batchDF.writeTo("hadoop_prod.db.test_topic").overwritePartitions()
- }.option("checkpointLocation", "/ss/checkpoint")
- .start() query.awaitTermination()
- }
-
- case class Test1(uid: BigInt,
- courseid: Int, deviceid: Int, ts: Timestamp)
5.4 提交 yarn 测试速度
1)打成 jar 包,上传到集群,运行代码跑 yarn 模式 让 vcore 个数和 shuffle 分区数保持1:1 最高效运行
- [root@hadoop103 lizunting]# spark-submit --master yarn --deploy-mode client
- --driver-memory 1g --num-executors 3 --executor-cores 4 --executor-memory 2g --queue spark --class com.atguigu.iceberg.spark.structuredstreaming.TestTopicOperators
- iceberg-spark-demo-1.0-SNAPSHOT-jar-with-dependencies.jar
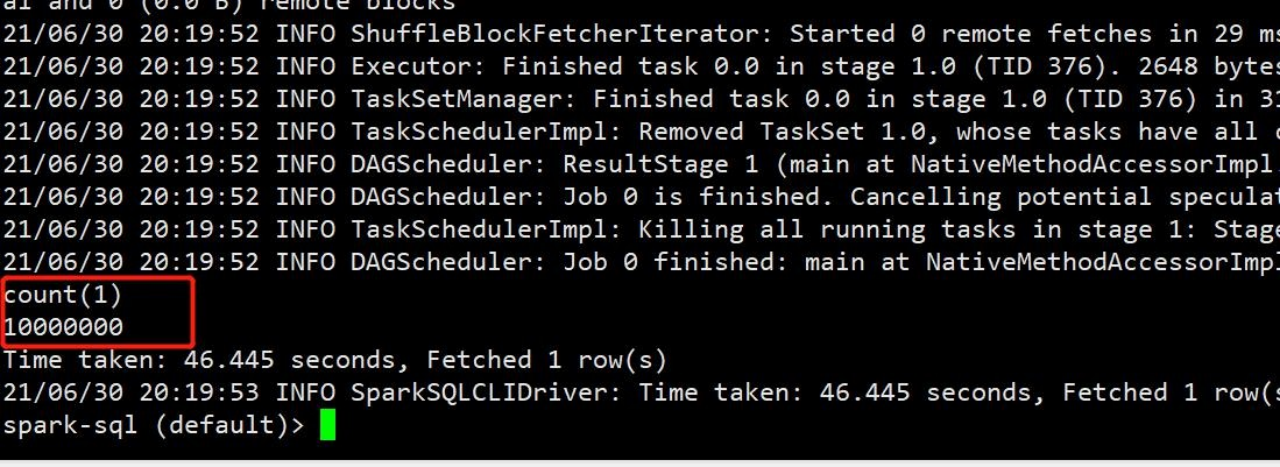
2)运行起来后,查看 Spark Web UI 界面监控速度。趋于稳定后,可以看到速度能到每秒10200,条左右,已经达到了我参数所设置的上限。当然分区数(kafka 分区和 shuffle 分区) 和 vcore 越多实时性也会越高目前测试是 12 分区。

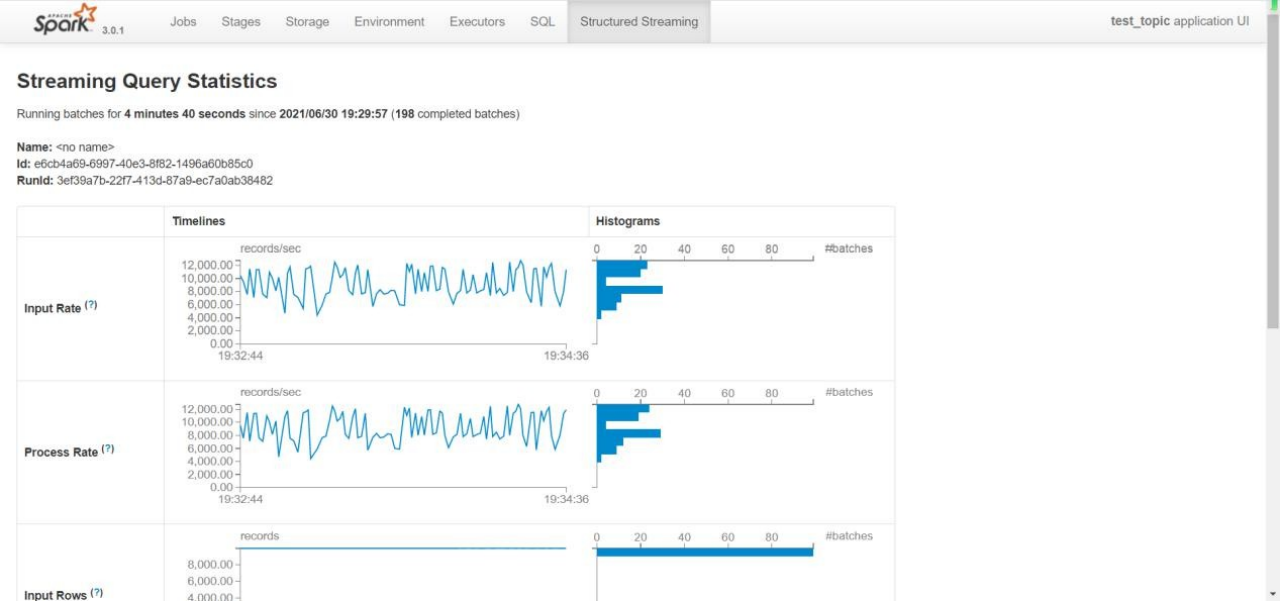
3)实时性没问题,但是有一个缺点,没有像 hudi 一样解决小文件问题。解决过多文件数可以更改 trigger 触发时间,但也会影响实时效率,两者中和考虑使用。
4)最后是花了 18 分钟跑完 1000 万条数据,查询表数据观察是否有数据丢失。数据没有丢失。
 第 6 章存在的问题和缺点
第 6 章存在的问题和缺点
6.1问题
- 时区无法设置
- Spark Sql 黑窗口,缓存无法更新,修改表数据后,得需要关了黑窗口再重新打开,查询才是更新后的数据
- 表分区如果指定多个分区或分桶,那么插入批量数据时,如果这一批数据有多条数据在同一个分区会报错
6.2缺点
- 与 hudi 相比,没有解决小文件问题
- 与 hudi 相比,缺少行级更新,只能对表的数据按分区进行 overwrite 全量覆盖
第 7 章 Flink 操作
7.1配置参数和 jar 包
- /opt/module/iceberg-apache-iceberg-0.11.1/flink-runtime/build/libs/
- [root@hadoop103 libs]# cp *.jar /opt/module/flink-1.11.0/lib/
- root@hadoop103 flink-1.11.0]# vim bin/config.sh
- export HADOOP_COMMON_HOME=/opt/module/hadoop-3.1.3
- export HADOOP_HDFS_HOME=/opt/module/hadoop-3.1.3
- export HADOOP_YARN_HOME=/opt/module/hadoop-3.1.3
- export HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3
- export HADOOP_CLASSPATH=`hadoop classpath`
- export PATH=$PATH:$HADOOP_CLASSPATH
1)Flink1.11 开始就不在提供 flink-shaded-hadoop-2-uber 的支持,所以如果需要 flink 支hadoop 得配置环境变量 HADOOP_CLASSPATH
2)目前 Iceberg 只支持 flink1.11.x 的版本,所以我这使用 flink1.11.0,将构建好的 Iceberg的 jar 包复制到 flink 下
7.2 Flink SQL Client
- [root@hadoop103 ~]# cd /opt/module/flink-1.11.0/
- [root@hadoop103 flink-1.11.0]# bin/start-cluster.sh
1)在 hadoop 环境下,启动一个单独的 flink 集群
2)启动 flin sql client
[root@hadoop103 flink-1.11.0]# bin/sql-client.sh embedded shell7.3 使用 Catalogs 创建目录
1) flink 可以通过 sql client 来创建 catalogs 目录, 支持的方式有 hive catalog,hadoop catalog,custom catlog。我这里采用 hadoop catlog。
- CREATE CATALOG hadoop_catalog WITH (
- 'type'='iceberg',
- 'catalog-type'='hadoop', 'warehouse'='hdfs://mycluster/flink/warehouse/', 'property-version'='1'
- );
2)使用当前 catalog
3)创建 sql-client-defaults.yaml,方便以后启动 flink-sql 客户端,走 iceberg 目录
- Flink SQL> exit;
- [root@hadoop103 flink-1.11.0]# cd conf/ [root@hadoop103 conf]# vim sql-client-defaults.yaml catalogs:
- - name: hadoop_catalog
- type: iceberg catalog-type: hadoop
- warehouse: hdfs://mycluster/flink/warehouse/
7.4 Flink SQL 操作
7.4.1建库
[root@hadoop103 flink-1.11.0]# bin/sql-client.sh embedded shell1)再次启动 Flink SQL客户端
2)可以使用默认数据库,也可以创建数据库
- Flink SQL> CREATE DATABASE iceberg_db;
- Flink SQL> show databases;
3)使用 iceberg 数据库
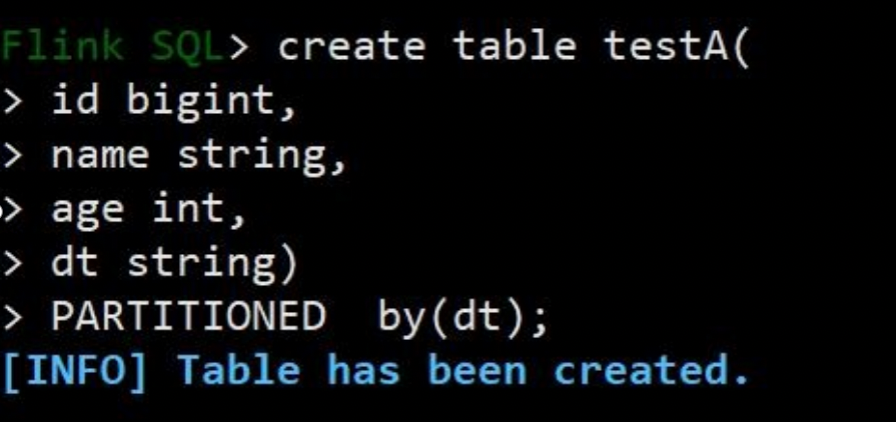
7.4.2建表(flink 不支持隐藏分区)
建表,我这里直接创建分区表了,使用 flink 对接 iceberg 不能使用 iceberg 的隐藏分区这一特性,目前还不支持。
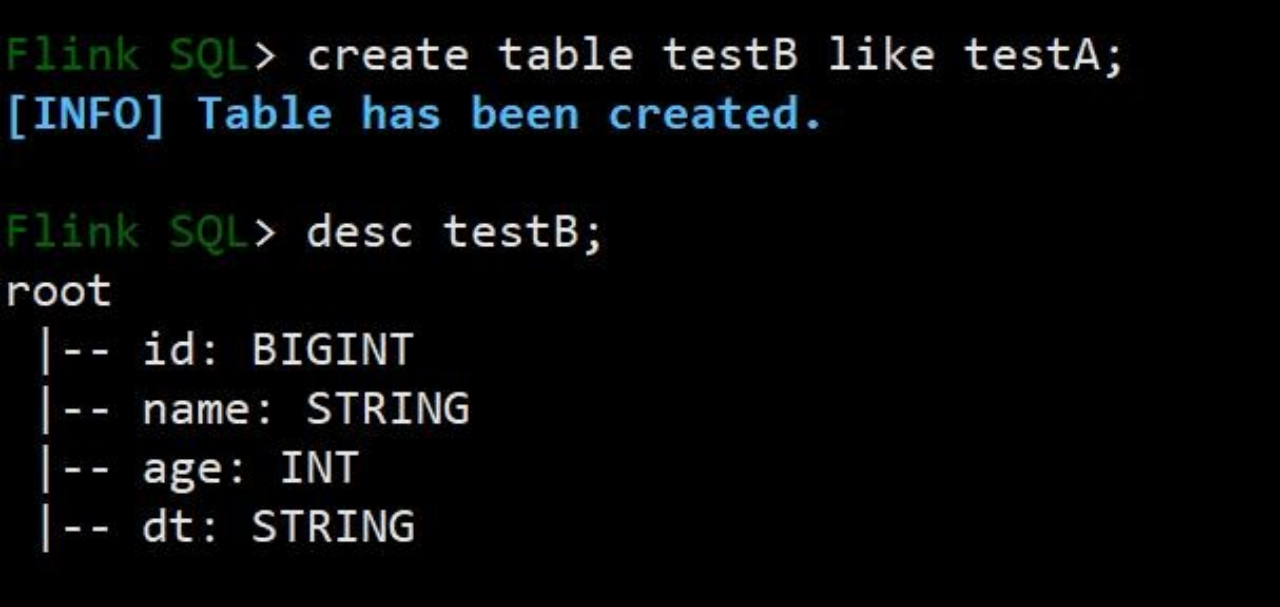
7.4.3 like 建表
可以使用create table 表名 like 的 sql 语句创建表结构完全一样的表
7.4.4 insert into
- Flink SQL> insert into iceberg.testA values(1001,' 张三',18,'2021-07-01'),(1001,' 李四
- ',19,'2021-07-02');
7.4.5查询
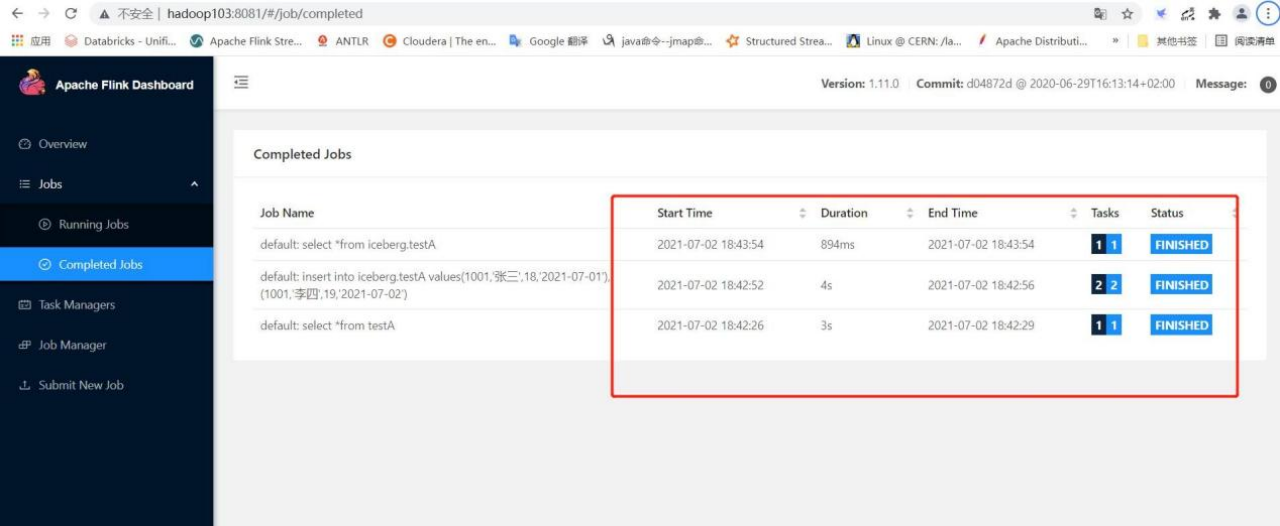
7.4.6任务监控
1) 可 查 看 hadoop103 默 认 端 口 8081 查 看 standlone 模 式 任 务 是 否 成 功
 2)插入数据后,同样 hdfs 路径上也是有对应目录和数据块
2)插入数据后,同样 hdfs 路径上也是有对应目录和数据块
7.4.7 insert overwrite
1)使用 overwrite 插入
- Flink SQL> insert overwrite iceberg.testA values(1,' 王 五 ',18,'2021-07-01'),(2,' 马 六
- ',19,'2021-07-02');
2)flink 默认使用流的方式插入数据,这个时候流的插入是不支持 overwrite 操作的
3)需要将插入模式进行修改,改成批的插入方式,再次使用 overwrite 插入数据。如需要改回流式操作参数设置为 SET execution.type = streaming ;

4)查询结果,已经将结果根据分区进行覆盖操作
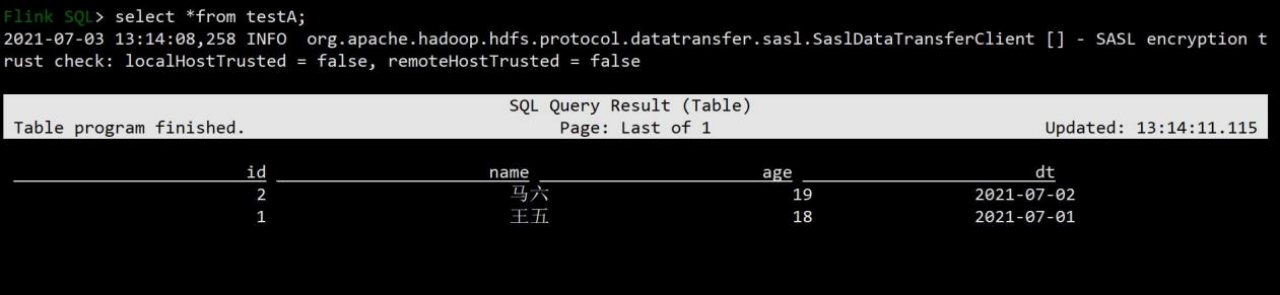
第 8 章 Flink API 操作
8.1配置 pom.xml
(1)配置相关依赖
- <?xml version="1.0" encoding="UTF-8"?>
- <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
- http://maven.apache.org/xsd/maven-4.0.0.xsd">
- <parent>
- <artifactId>iceberg-demo</artifactId>
- <groupId>com.atguigu.iceberg</groupId>
- <version>1.0-SNAPSHOT</version>
- </parent>
- <modelVersion>4.0.0</modelVersion>
-
- <artifactId>icberg-flink-demo</artifactId>
- <properties>
- <flink.version>1.11.0</flink.version>
- <scala.version>2.12.10</scala.version>
- <scala.binary.version>2.12</scala.binary.version>
- <log4j.version>1.2.17</log4j.version>
- <slf4j.version>1.7.22</slf4j.version>
- <iceberg.version>0.11.1</iceberg.version>
- </properties>
-
- <dependencies>
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-java</artifactId>
- <version>${flink.version}</version>
- </dependency>
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
- <version>${flink.version}</version>
- </dependency>
- <dependency>
- <groupId>org.scala-lang</groupId>
- <artifactId>scala-library</artifactId>
- <version>${scala.version}</version>
- </dependency>
-
- <!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table -->
-
- <!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-common -->
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-table-common</artifactId>
- <version>${flink.version}</version>
- </dependency>
- <!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-api-java -->
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-table-api-java</artifactId>
- <version>${flink.version}</version>
- </dependency>
- <!--
- https://mvnrepository.com/artifact/org.apache.flink/flink-table-api-java-bridge -->
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId>
- <version>${flink.version}</version>
- </dependency>
- <!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-planner -->
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-table-planner_${scala.binary.version}</artifactId>
- <version>${flink.version}</version>
- </dependency>
-
- <!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-planner-blink -->
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId>
- <version>${flink.version}</version>
- </dependency>
- <dependency>
- <groupId>org.apache.iceberg</groupId>
- <artifactId>iceberg-flink-runtime</artifactId>
- <version>0.11.1</version>
- </dependency>
- <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
- <dependency>
- <groupId>org.apache.hadoop</groupId>
- <artifactId>hadoop-client</artifactId>
- <version>3.1.3</version>
- </dependency>
- <!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-clients_${scala.binary.version}</artifactId>
- <version>${flink.version}</version>
- </dependency>
- </dependencies>
- </project>
8.2.1读取表数据
8.2.1.1batch read
- package com.atguigu.iceberg.flink.sql;
-
- import org.apache.flink.streaming.api.datastream.DataStream;
- import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.data.RowData;
- import org.apache.iceberg.flink.TableLoader; import org.apache.iceberg.flink.source.FlinkSource;
-
- public class TableOperations {
-
- public static void main(String[] args) throws Exception {
-
- StreamExecutionEnvironment env =
- StreamExecutionEnvironment.getExecutionEnvironment();
- TableLoader tableLoader =
-
- TableLoader.fromHadoopTable("hdfs://mycluster/flink/warehouse/iceberg/testA");
- batchRead(env, tableLoader); env.execute();
- }
-
- public static void batchRead(StreamExecutionEnvironment env, TableLoader
- tableLoader){
-
- DataStream<RowData> batch =
- FlinkSource.forRowData().env(env).
- tableLoader(tableLoader).streaming(false).build();
- batch.map(item ->
- item.getInt(0)+"\t"+item.getString(1)+"\t"+item.getInt(2)
- +"\t"+item.getString(3)).prin t();
- }
- }
8.2.1.2streaming read
- public static void streamingRead(StreamExecutionEnvironment env, TableLoader tableLoader){
-
- DataStream<RowData> stream =
-
- FlinkSource.forRowData().env(env).
- tableLoader(tableLoader).streaming(true).build();
- stream.print();
- }
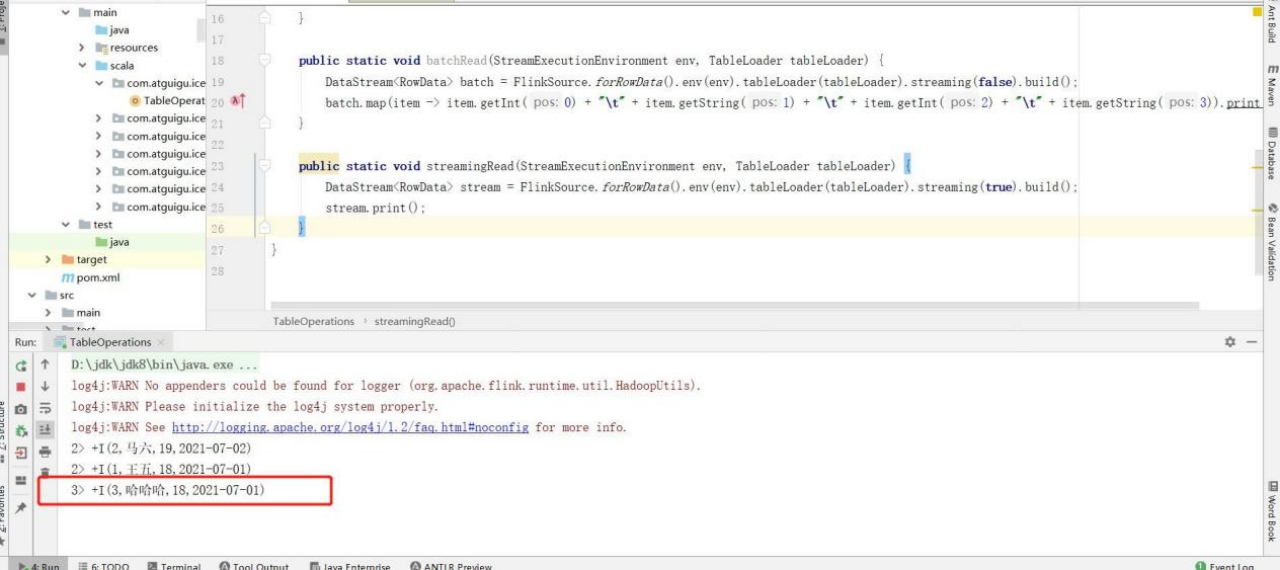
1)通过 streaming 的方式去读取数据
2)启动之后程序不会立马停止
3)因为是流处理,这个时候手动往表中追加一条数据
Flink SQL> insert into iceberg.testA values(3,'哈哈哈',18,'2021-07-01'); 可以看到控制台,实时打印出了数据
可以看到控制台,实时打印出了数据
8.3写数据
8.3.1Appending Data
- public static void appendingData(StreamExecutionEnvironment env,TableLoader tableLoader){
-
- DataStream<RowData> batch =. FlinkSource.forRowData().env(env).
- tableLoader(tableLoader).streaming(false).build(); TableLoader tableB =
-
- TableLoader.fromHadoopTable("hdfs://mycluster/flink/warehouse/iceberg/testB");
- FlinkSink.forRowData(batch).tableLoader(tableB).build();
- }
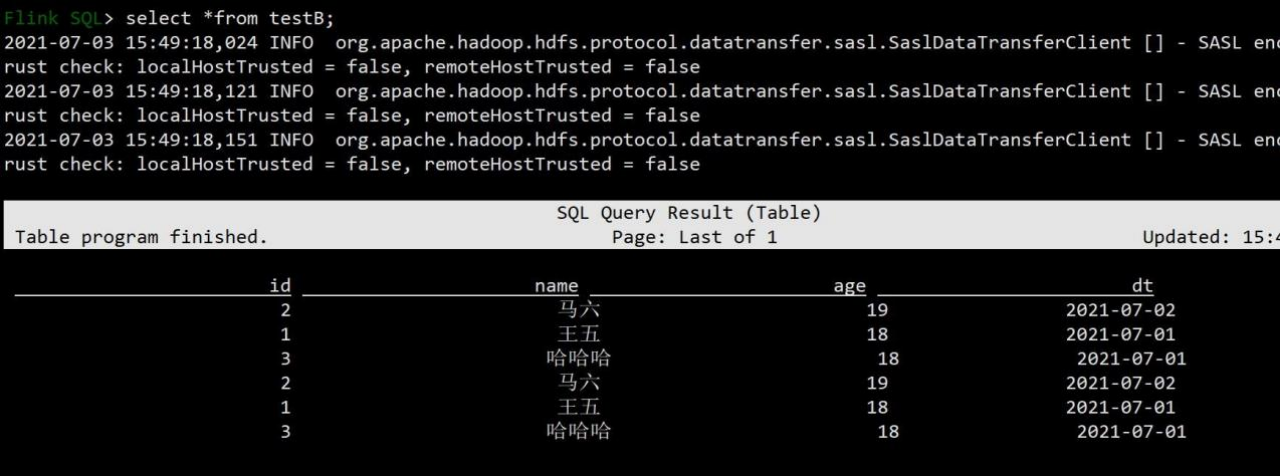
使用上面 create table testB like testA 的 testB 表,读取 A 表数据插入到 B 表数据采用的是 batch 批处理,代码执行两次并查询查看 append 效果
8.3.3Overwrite Data
1)编写代码,将 overwrite 设置为 true
- public static void overtData(StreamExecutionEnvironment env,TableLoader tableLoader){
- DataStream<RowData> batch =
- FlinkSource.forRowData().env(env).
- tableLoader(tableLoader).streaming(false).build(); TableLoader tableB =
- TableLoader.fromHadoopTable(
- "hdfs://mycluster/flink/warehouse/iceberg/testB");
- FlinkSink.forRowData(batch).
- tableLoader(tableB).overwrite(true).build();
- }
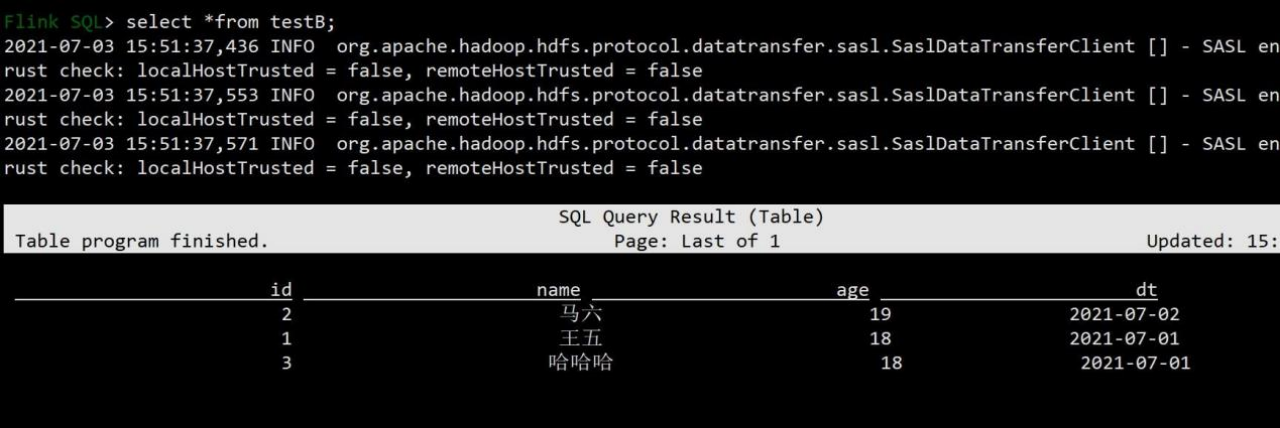
2)查询 testB 表查看 overwrite 效果,根据分区将数据进行了覆盖操作
8.4模拟数仓
flink 操作iceberg 的示例代码
第 9 章 Flink 存在的问题
- Flink 不支持 Iceberg 隐藏分区
- 不支持通过计算列创建表
- 不支持创建带水位线的表
- 不支持添加列、删除列、重命名列

