
热门标签
热门文章
- 1百度Comate:你的智能编程助手,让代码编写更高效_comate 私域知识
- 2matlab对xml文件操作,Matlab读写xml文件
- 3Java中数组的学习_java数组学习
- 4Android UI控件
- 5Apache Kylin与Impala:深入比较与应用场景分析
- 6vue 前端框架构建踩坑记录(自用)_npm warn ebadengine unsupported engine { npm warn
- 7【数智化人物展】数势科技创始人兼CEO黎科峰:数智化时代To B软件行业面临颠覆与重塑...
- 8ChatGPT的真实能力如何?七大NLP任务一探究竟!
- 9VTK中获取STL模型点的坐标以及对其进行变换
- 10SSL网关国密标准GMT0024-2014_gmt0024标准
当前位置: article > 正文
Kafka集成flume
作者:不正经 | 2024-06-16 00:16:23
赞
踩
Kafka集成flume
1.flume作为生产者集成Kafka
kafka作为flume的sink,扮演消费者角色
1.1 flume配置文件
vim $kafka/jobs/flume-kafka.conf
- # agent
- a1.sources = r1
- a1.sinks = k1
- a1.channels = c1 c2
-
- # Describe/configure the source
- a1.sources.r1.type = TAILDIR
- #记录最后监控文件的断点的文件,此文件位置可不改
- a1.sources.r1.positionFile = /export/server/flume/job/data/tail_dir.json
- a1.sources.r1.filegroups = f1 f2
- a1.sources.r1.filegroups.f1 = /export/server/flume/job/data/.*file.*
- a1.sources.r1.filegroups.f2 =/export/server/flume/job/data/.*log.*
-
- # Describe the sink
- a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
- a1.sinks.k1.kafka.topic = customers
- a1.sinks.k1.kafka.bootstrap.servers =node1:9092,node2:9092
- a1.sinks.k1.kafka.flumeBatchSize = 20
- a1.sinks.k1.kafka.producer.acks = 1
- a1.sinks.k1.kafka.producer.linger.ms = 1
- a1.sinks.k1.kafka.producer.compression.type = snappy
-
-
- # Use a channel which buffers events in memory
- a1.channels.c1.type = memory
- a1.channels.c1.capacity = 1000
- a1.channels.c1.transactionCapacity = 100
-
- # Bind the source and sink to the channel
- a1.sources.r1.channels = c1
- a1.sinks.k1.channel = c1
1.2开启flume监控
flume-ng agent -n a1 -c conf/ -f /export/server/kafka/jobs/kafka-flume.conf
1.3开启Kafka消费者
kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092 --topic consumers --from-beginning
1.4生产数据
往被监控文件输入数据
[ljr@node1 data]$echo hello >>file2.txt
[ljr@node1 data]$ echo ============== >>file2.txt
查看Kafka消费者
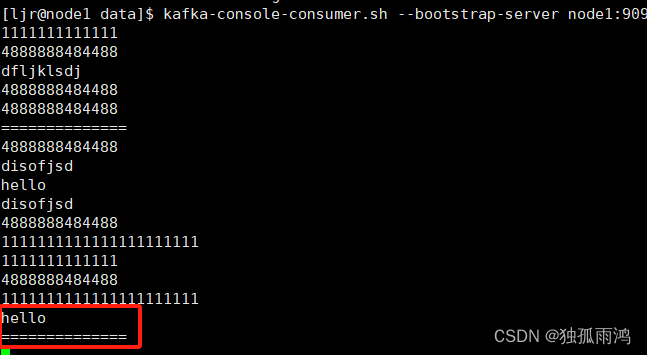
可见Kafka集成flume生产者成功。
2.flume作为消费者集成Kafka
kafka作为flume的source,扮演生产者角色
2.1flume配置文件
vim $kafka/jobs/flume-kafka.conf
-
- # agent
- a1.sources = r1
- a1.sinks = k1
- a1.channels = c1
-
- # Describe/configure the source
- a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
- #注意不要大于channel transactionCapacity的值100
- a1.sources.r1.batchSize = 50
- a1.sources.r1.batchDurationMillis = 200
- a1.sources.r1.kafka.bootstrap.servers =node1:9092, node1:9092
- a1.sources.r1.kafka.topics = consumers
- a1.sources.r1.kafka.consumer.group.id = custom.g.id
-
- # Describe the sink
- a1.sinks.k1.type = logger
-
- # Use a channel which buffers events in memory
- a1.channels.c1.type = memory
- a1.channels.c1.capacity = 1000
- #注意transactionCapacity的值不要小于sources batchSize的值50
- a1.channels.c1.transactionCapacity = 100
-
- # Bind the source and sink to the channel
- a1.sources.r1.channels = c1
- a1.sinks.k1.channel = c1
2.2开启flume监控
flume-ng agent -n a1 -c conf/ -f /export/server/kafka/jobs/kafka-flume1.conf
2.3开启Kafka生产者并生产数据
kafka-console-producer.sh --bootstrap-server node1:9092,node2:9092 --topic consumers

查看flume监控台

可见Kafka集成flume消费者成功。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/不正经/article/detail/724407?site
推荐阅读
相关标签

