
热门标签
热门文章
当前位置: article > 正文
Knowledge Graphs for RAG -- Constructing a Knowledge Graph from Text Documents (吴恩达-知识图谱在RAG中的应用 3)_call db.index.vector.querynodes(
作者:一键难忘520 | 2024-07-25 05:11:54
赞
踩
call db.index.vector.querynodes(
Constructing a Knowledge Graph from Text Documents
1 导包(python+langchain)
from dotenv import load_dotenv import os # Common data processing import json import textwrap # Langchain from langchain_community.graphs import Neo4jGraph from langchain_community.vectorstores import Neo4jVector from langchain_openai import OpenAIEmbeddings from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.chains import RetrievalQAWithSourcesChain from langchain_openai import ChatOpenAI # Warning control import warnings warnings.filterwarnings("ignore")

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
# Load from environment load_dotenv('.env', override=True) NEO4J_URI = os.getenv('NEO4J_URI') NEO4J_USERNAME = os.getenv('NEO4J_USERNAME') NEO4J_PASSWORD = os.getenv('NEO4J_PASSWORD') NEO4J_DATABASE = os.getenv('NEO4J_DATABASE') or 'neo4j' OPENAI_API_KEY = os.getenv('OPENAI_API_KEY') # Note the code below is unique to this course environment, and not a # standard part of Neo4j's integration with OpenAI. Remove if running # in your own environment. OPENAI_ENDPOINT = os.getenv('OPENAI_BASE_URL') + '/embeddings' # 全局变量 VECTOR_INDEX_NAME = 'form_10k_chunks' VECTOR_NODE_LABEL = 'Chunk' VECTOR_SOURCE_PROPERTY = 'text' VECTOR_EMBEDDING_PROPERTY = 'textEmbedding'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
2 查看并预分析一下10-K json文件(需要创建向量索引的文件)
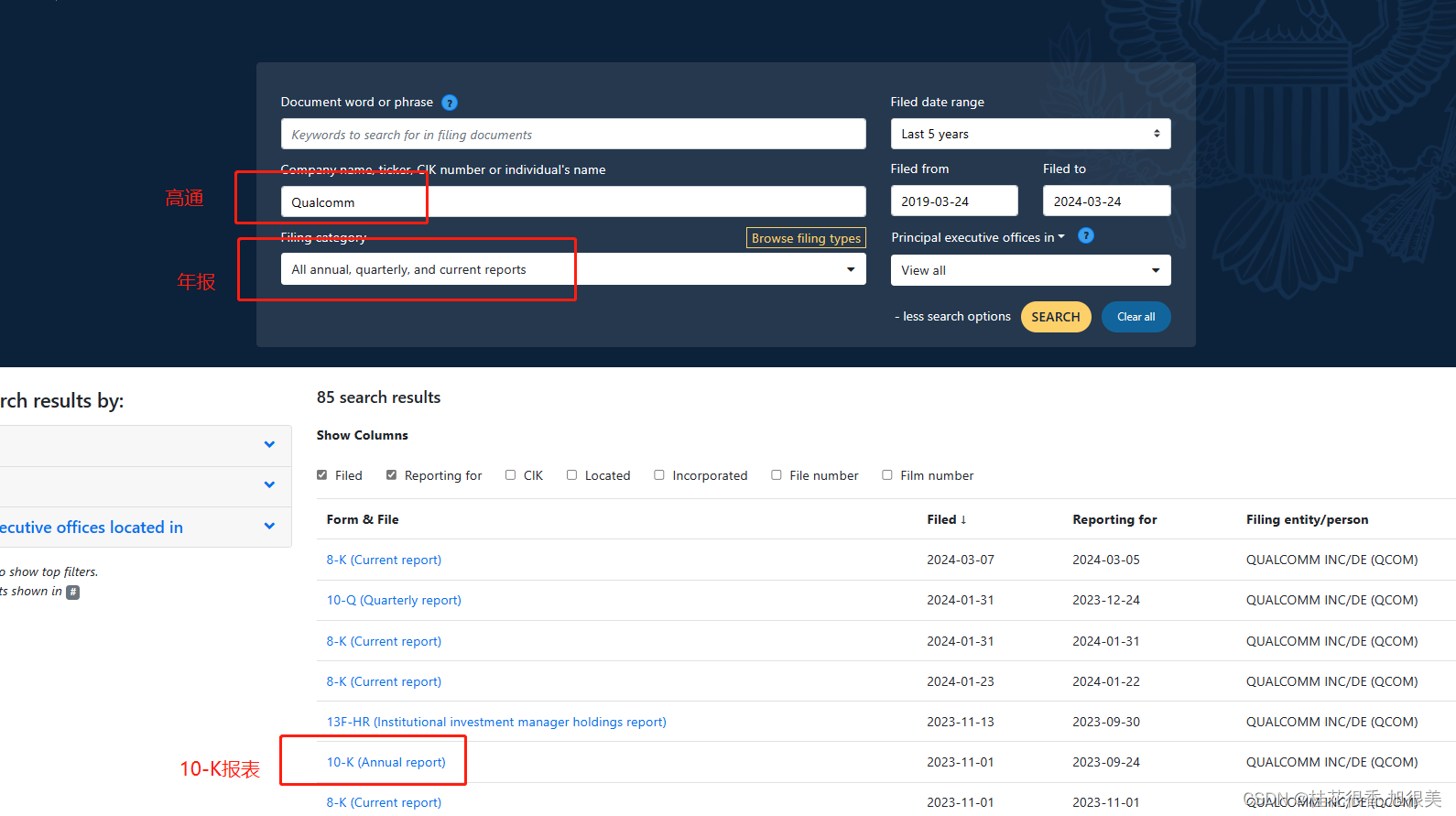
打开就长下面这个样子(随便截了几张)


将上面的文件构建知识图谱之后就可以对这些金融数据进行问答对话了,但是下载下来是XML 格式,需要对XML进行解析并对数据进行清洗。
2.1 数据清洗流程(得到JSON文件):
- 首先进行一些正则表达式清理,浏览XML,尝试找到我们真正想要的片段
- 然后使用Beautiful Soup 将其中一部分XML转换成干净的Python数据结构
- 提取关键内容,比如 CIK标识符:它是一个中心索引,用于在SEC中识别公司
- 对于大段的文本,查看(1,1A,7和7A条款)
- 最后将他们转换成JSON,用于后面导入并开始创建知识图谱
2.2 JSON文件到可检索的大体流程规划:
- 由于数据复杂性,每种形式都有不同的文本,首先要把他们拆分成块(使用langchain的textsplitter)
- 数据分块之后,将每个块设置成知识图谱中的一个节点,该节点将具有原始文本及一些元数据作为属性
- 然后创建一个向量索引
- 在该索引中我们计算每个文本块的嵌入向量
- 然后就可以进行相似度搜索相关的文本块了
3 导入处理过的JSON文件并切块
3.1 导入json文件
first_file_name = "./data/form10k/0000950170-23-027948.json"
first_file_as_object = json.load(open(first_file_name))
print(type(first_file_as_object))# dict
for k,v in first_file_as_object.items():
print(k, type(v))
- 1
- 2
- 3
- 4
- 5

item1_text = first_file_as_object['item1']
item1_text[0:1500]
- 1
- 2

3.2 将10-K表格数据切块
- 初始化一个LangChain的文本切块器
- 只切分"item 1"部分文本
#初始化 splitter:递归字符串文本分割器
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 2000,#每个块的大小:2000字符
chunk_overlap = 200,#前后块有200个字符的重叠(保持上下文用?)
length_function = len,
is_separator_regex = False,
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
#切块
item1_text_chunks = text_splitter.split_text(item1_text)
- 1
- 2
切块结果:
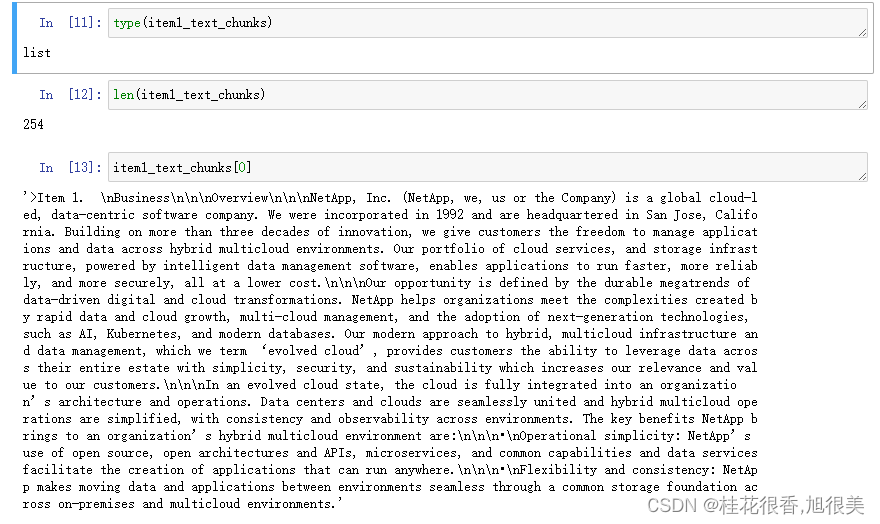
- 设置辅助函数来遍历所有文件和文件中的每个部分,并将它们创建成块,然后将所有这些块转换成可以用于加载数据到图(Graph)中的对象
- 为了加快速度,测试中只取每个item的前20个块进行处理
def split_form10k_data_from_file(file):#从文件中拆分10-k数据函数 chunks_with_metadata = [] # use this to accumlate chunk records file_as_object = json.load(open(file)) # open the json file for item in ['item1','item1a','item7','item7a']: # pull these keys from the json print(f'Processing {item} from {file}') item_text = file_as_object[item] # grab the text of the item item_text_chunks = text_splitter.split_text(item_text) # split the text into chunks chunk_seq_id = 0 for chunk in item_text_chunks[:20]: # only take the first 20 chunks(为了演示加速,实际情况要使用全部字符) #文件名的最后一部分作为表单的ID form_id = file[file.rindex('/') + 1:file.rindex('.')] # extract form id from file name # finally, construct a record with metadata and the chunk text chunks_with_metadata.append({ 'text': chunk, # metadata from looping... 'f10kItem': item, 'chunkSeqId': chunk_seq_id, # constructed metadata... 'formId': f'{form_id}', # pulled from the filename 'chunkId': f'{form_id}-{item}-chunk{chunk_seq_id:04d}', # metadata from file... 'names': file_as_object['names'], 'cik': file_as_object['cik'], 'cusip6': file_as_object['cusip6'], 'source': file_as_object['source'], }) chunk_seq_id += 1 print(f'\tSplit into {chunk_seq_id} chunks') return chunks_with_metadata
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
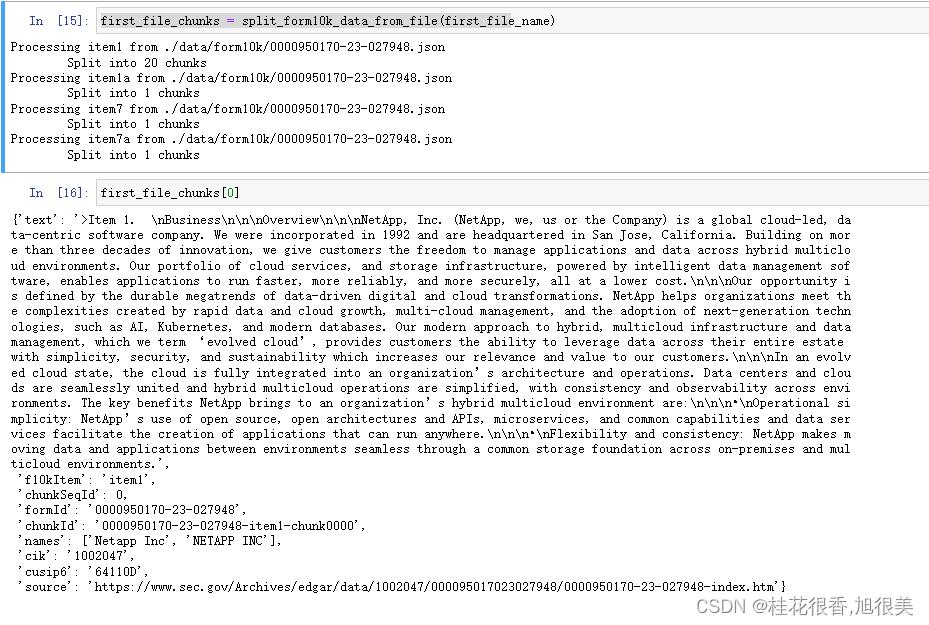
first_file_chunks = split_form10k_data_from_file(first_file_name)
- 1
切片结果:
4 用这些块创建图节点
# 这是一个merge语句,merge之前首先有一个match,如果match失败,就会执行一个create,create一个新节点 # 所以merge之前要么是查询要么是创建 # 下面创建时传入我们切块时整理的数据字典(比如:first_file_chunks[0]) merge_chunk_node_query = """ MERGE(mergedChunk:Chunk {chunkId: $chunkParam.chunkId}) ON CREATE SET mergedChunk.names = $chunkParam.names, mergedChunk.formId = $chunkParam.formId, mergedChunk.cik = $chunkParam.cik, mergedChunk.cusip6 = $chunkParam.cusip6, mergedChunk.source = $chunkParam.source, mergedChunk.f10kItem = $chunkParam.f10kItem, mergedChunk.chunkSeqId = $chunkParam.chunkSeqId, mergedChunk.text = $chunkParam.text RETURN mergedChunk """
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
4.1 从langchain_community.graphs 创建一个Neo4j的实例链接
kg = Neo4jGraph(
url=NEO4J_URI, username=NEO4J_USERNAME, password=NEO4J_PASSWORD, database=NEO4J_DATABASE
)
- 1
- 2
- 3
4.2 创建一个单块节点
#kg.query 是执行命令
#命令是merge_chunk_node_query
# 数据参数是 params,里面的chunkParam 将在merge_chunk_node_query 命令里替换$
kg.query(merge_chunk_node_query,
params={'chunkParam':first_file_chunks[0]})
- 1
- 2
- 3
- 4
- 5

在调用辅助函数批量创建知识图谱之前,我们需要采取额外的步骤来确保我们不会重复数据
kg.query("""
CREATE CONSTRAINT unique_chunk IF NOT EXISTS
FOR (c:Chunk) REQUIRE c.chunkId IS UNIQUE
""")
- 1
- 2
- 3
- 4
- 5
查看一下
kg.query("SHOW INDEXES")
- 1
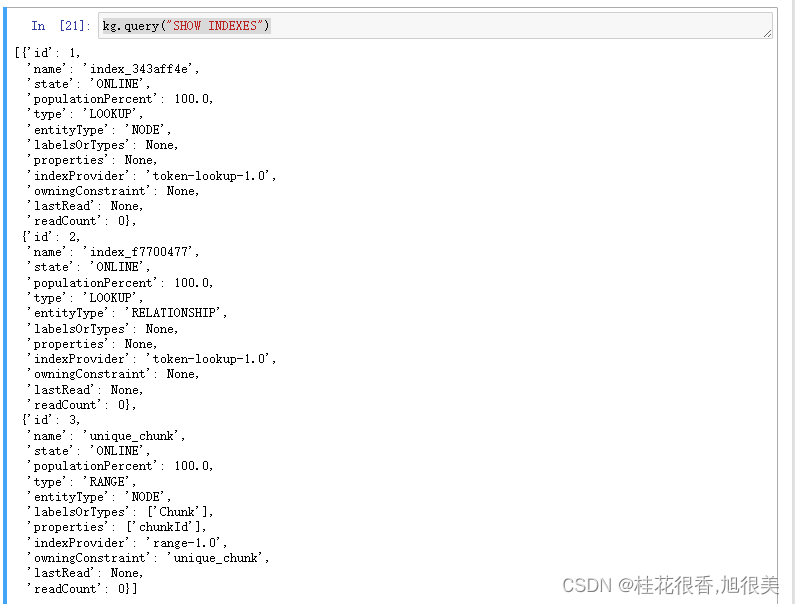
- 循环并为所有块创建节点
- 应该创建23个节点,因为在上面的文本分割函数中设置了20个块的限制
node_count = 0
for chunk in first_file_chunks:
print(f"Creating `:Chunk` node for chunk ID {chunk['chunkId']}")
kg.query(merge_chunk_node_query,
params={
'chunkParam': chunk
})
node_count += 1
print(f"Created {node_count} nodes")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

# 查询下所有节点
kg.query("""
MATCH (n)
RETURN count(n) as nodeCount
""")
- 1
- 2
- 3
- 4
- 5

5 创建一个向量索引(用于将创建文本嵌入的块)
# 索引被称为 form_10k_chunks
# 并且我们将为标记为块的节点存储在一个命名为 textEmbedding 的属性中的嵌入
kg.query("""
CREATE VECTOR INDEX `form_10k_chunks` IF NOT EXISTS
FOR (c:Chunk) ON (c.textEmbedding)
OPTIONS { indexConfig: {
`vector.dimensions`: 1536,
`vector.similarity_function`: 'cosine'
}}
""")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
查看所有索引看是否创建成功
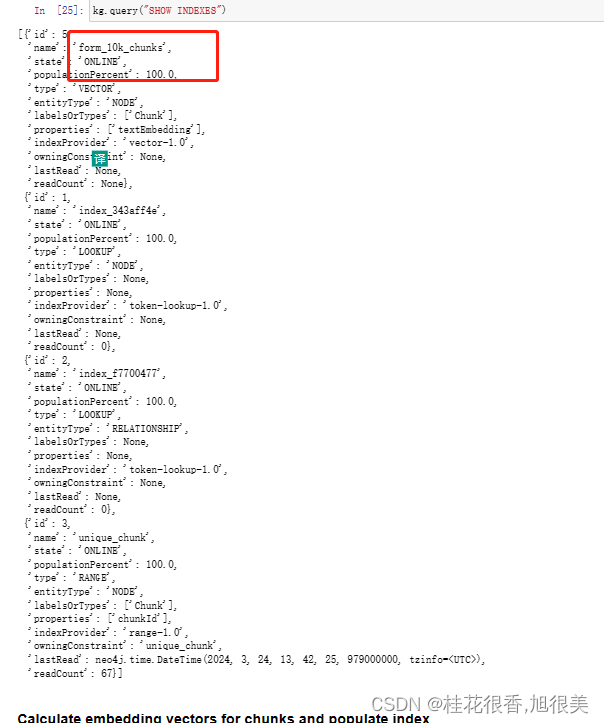
6 为块计算嵌入向量并填充索引
kg.query("""
MATCH (chunk:Chunk) WHERE chunk.textEmbedding IS NULL
WITH chunk, genai.vector.encode(
chunk.text,
"OpenAI",
{
token: $openAiApiKey,
endpoint: $openAiEndpoint
}) AS vector
CALL db.create.setNodeVectorProperty(chunk, "textEmbedding", vector)
""",
params={"openAiApiKey":OPENAI_API_KEY, "openAiEndpoint": OPENAI_ENDPOINT} )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
kg.refresh_schema()
print(kg.schema)
- 1
- 2

目前只有节点,节点之间没有关系
7 相似度搜索相关的块
创建辅助函数来使用Neo4j进行向量搜索
def neo4j_vector_search(question): """Search for similar nodes using the Neo4j vector index""" vector_search_query = """ WITH genai.vector.encode( $question, "OpenAI", { token: $openAiApiKey, endpoint: $openAiEndpoint }) AS question_embedding CALL db.index.vector.queryNodes($index_name, $top_k, question_embedding) yield node, score RETURN score, node.text AS text """ similar = kg.query(vector_search_query, params={ 'question': question, 'openAiApiKey':OPENAI_API_KEY, 'openAiEndpoint': OPENAI_ENDPOINT, 'index_name':VECTOR_INDEX_NAME, 'top_k': 10}) return similar
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
问个问题试一下
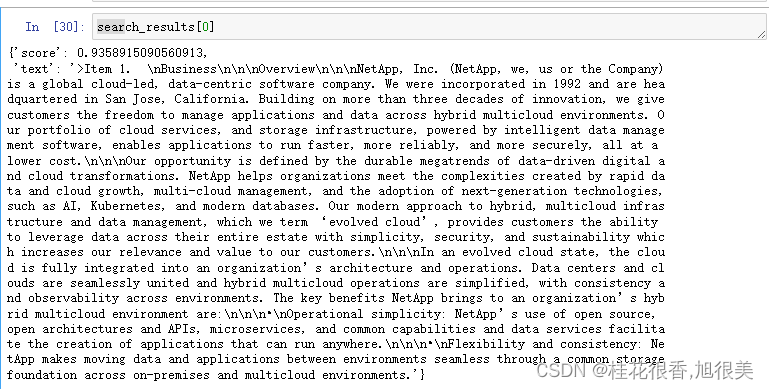
search_results = neo4j_vector_search(
'In a single sentence, tell me about Netapp.'
)
- 1
- 2
- 3
8 设置LangChain RAG工作流以与表单聊天
使用Neo4j和LangChain开始最简单的就是Neo4j向量接口
neo4j_vector_store = Neo4jVector.from_existing_graph(
embedding=OpenAIEmbeddings(),
url=NEO4J_URI,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
index_name=VECTOR_INDEX_NAME,
node_label=VECTOR_NODE_LABEL,
text_node_properties=[VECTOR_SOURCE_PROPERTY],
embedding_node_property=VECTOR_EMBEDDING_PROPERTY,
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
#将向量存储器转换为检索器
retriever = neo4j_vector_store.as_retriever()
- 1
- 2
建立RetrievalQAWithSourcesChain进行问答: LangChain documentation for this chain
#chain_type="stuff" 就是使用 prompt,吧参数或者数据组合到prompt中,然后传给LLM
chain = RetrievalQAWithSourcesChain.from_chain_type(
ChatOpenAI(temperature=0),
chain_type="stuff",
retriever=retriever)
- 1
- 2
- 3
- 4
- 5
#直接受一个问题,然后它用那个question调用chain,然后只是提取出答案文本,并将其以适合屏幕的方式漂亮的打印出来
def prettychain(question: str) -> str:
"""Pretty print the chain's response to a question"""
response = chain({"question": question},
return_only_outputs=True,)
print(textwrap.fill(response['answer'], 60))
- 1
- 2
- 3
- 4
- 5
- 6
问个问题试一下
question = "What is Netapp's primary business?"
- 1
prettychain(question)
- 1

再试几个
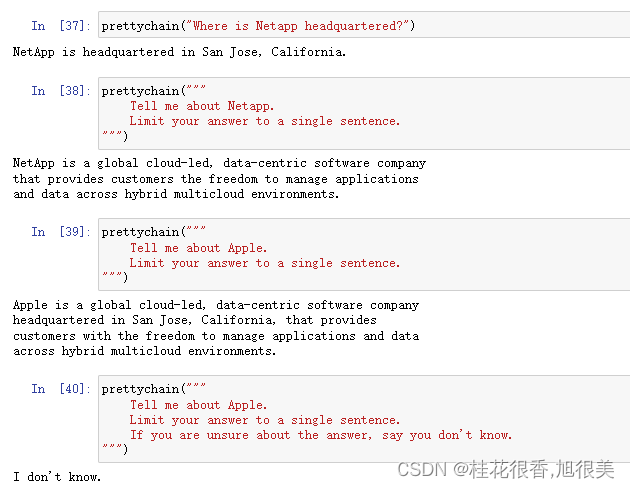
!!! 指定字数也行??

补充
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/一键难忘520/article/detail/878501?site
推荐阅读
相关标签

