
热门标签
热门文章
- 1MySQL数据分析进阶(八)存储过程
- 2harbor升级 从1.10.2升级到2.2.2_harbor安装pgupgrade版本问题
- 3Linux常用指令大全_linux基本命令大全
- 42.5、队列(队列存储结构)
- 5探索智能自动化:Zheng-Shaozhuo的`wxAuto`
- 6跟我一起阅读并修复源码(3:编译工程,源码分析)之六_transferhelper: transfer from failed
- 7数字化转型的金融科技:如何应用科技驱动金融发展
- 8git项目在idea中update操作出现Could not read from remote repository._error: couldn鈥檛 fetch updates from remote reposito
- 9Datawhale AI 夏令营 Task1_大模型后端开发
- 10WinAircrackPack无线破解
当前位置: article > 正文
ZooKeeper选举机制_zk的选举机制
作者:weixin_40725706 | 2024-08-09 09:41:46
赞
踩
zk的选举机制
ZooKeeper选举机制
ZooKeeper 的选举机制是保证分布式系统中各个节点能够选举出一个领导者或协调者来负责处理一些重要任务的关键组成部分。在 ZooKeeper 集群中,每个节点都可以成为领导者候选者,但最终只有一个节点会成为领导者。
-
节点状态:
- 在 ZooKeeper 集群中,每个节点都有一个状态,主要包括
FOLLOWER、LEADER和OBSERVER三种状态。节点的状态取决于它在集群中的角色和当前的选举状态。
- 在 ZooKeeper 集群中,每个节点都有一个状态,主要包括
-
选举过程:
- 初始状态下,所有节点都是 FOLLOWER。
- 当一个节点启动或者检测到当前的领导者无法通信时,它会发起一次选举。
- 节点会向其他节点发送投票请求,并将自己作为候选者。
- 其他节点在接收到投票请求后,会检查自己的选票情况,如果没有投票给其他节点,则会投票给候选者节点。
- 当候选者节点收到了大多数节点的选票时(超过半数),它就会成为新的领导者,并将自己的身份更新为 LEADER。同时,它会向其他节点发送心跳信号,以表明自己的领导者身份。
-
选举算法:
- ZooKeeper 使用了基于 Paxos 算法的 ZAB(ZooKeeper Atomic Broadcast)协议来实现选举过程。
- 在 ZAB 协议中,每个节点都有一个唯一的递增编号,称为 ZXID(ZooKeeper Transaction ID)。
- 当一个节点发起一次选举时,它会提议一个 ZXID,并将其广播给其他节点。
- 其他节点会比较提议的 ZXID,如果它比自己的最新 ZXID 要大,则会投票给候选者节点。这样就保证了选举过程的一致性和正确性。
-
容错机制:
- ZooKeeper 的选举机制具有良好的容错性。即使在网络分区或节点故障的情况下,选举过程仍然能够继续进行,并最终选举出一个新的领导者。
- 这是因为 ZooKeeper 集群中的节点是通过相互通信来达成一致性的,而不是依赖于单个节点的状态。
-
观察者节点:
- 在 ZooKeeper 集群中,除了 FOLLOWER 和 LEADER 节点之外,还可以有 OBSERVER 节点。
- 观察者节点不参与选举过程,但可以接收集群中其他节点的更新信息,从而提高系统的扩展性和性能。
示例:
第一次启动:
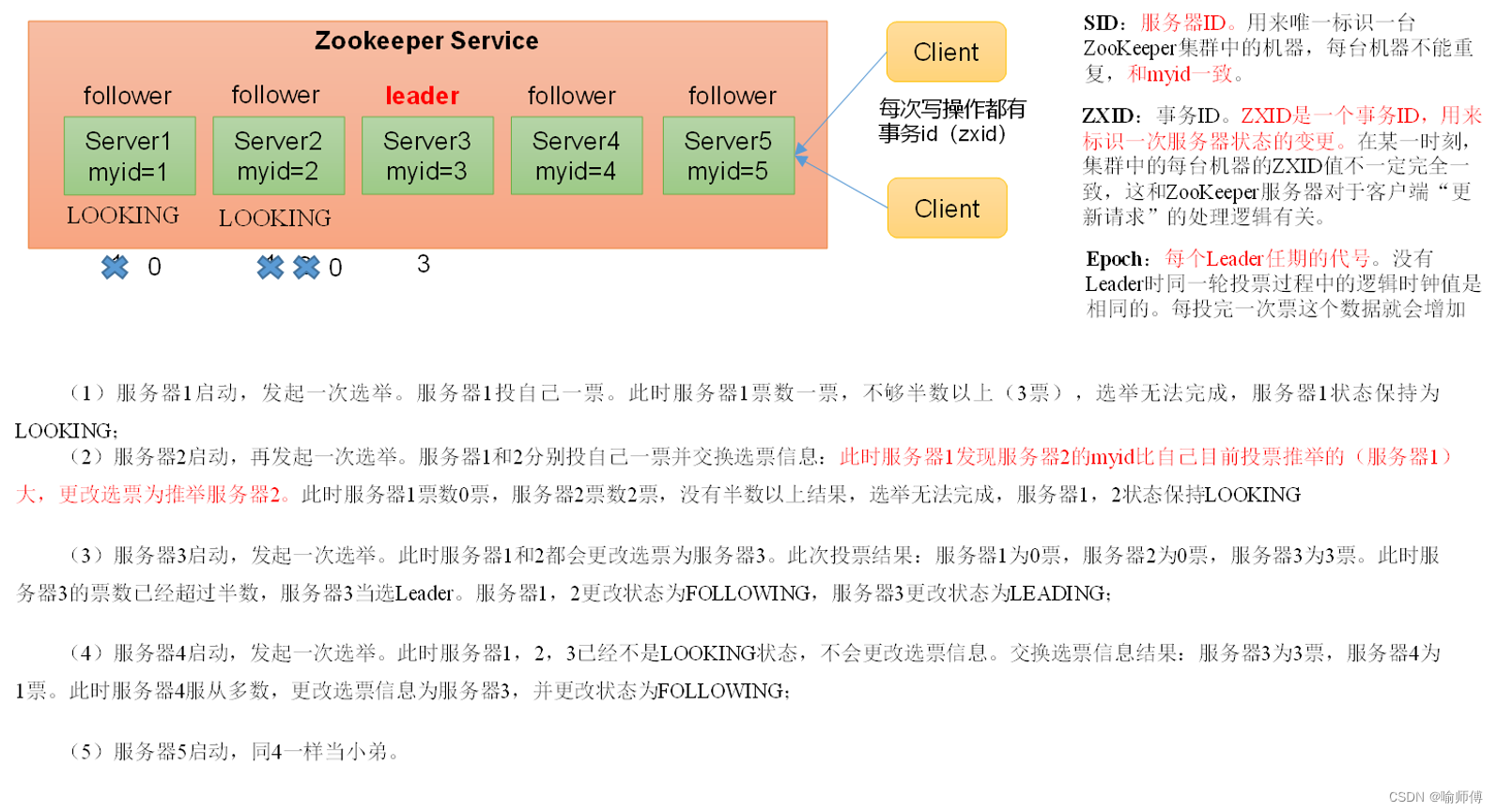
非第一次启动

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/weixin_40725706/article/detail/952608?site
推荐阅读
相关标签

