
- 1第五章 神经网络_78m696.top
- 2Python 基于pytorch实现多头自注意力机制代码;Multiheads-Self-Attention代码实现_python编写attention代码
- 3通俗易懂讲解大模型:Tokenizer_大模型 tokenizer
- 4wireshark 实用过滤表达式(针对ip、协议、端口、长度和内容)_wireshark过滤端口
- 5tensorflow2实现unet, 完成眼底血管分割任务
- 6AIGC: 4 IT从业者如何构建自己的AI知识体系
- 716进制颜色代码#FF000000 (css颜色值)
- 8Pandas数值运算与缺失值处理_本关任务:获取鸢尾花数据集前30行并转换成dataframe,然后让每一行都减去第一行的
- 9python对文件进行MD5验证——我的运维平台_python 切片upload md5校验
- 10【React】antd上传文件组件customRequest自定义上传解析_antd customrequest
深度学习pytorch——减少过拟合的几种方法(持续更新)
赞
踩
1、增加数据集
2、正则化(Regularization)
正则化:得到一个更加简单的模型的方法。
以一个多项式为例:![]()
随着最高次的增加,会得到一个更加复杂模型,模型越复杂就会更好的拟合输入数据的模型(图-1),拟合的程度越大,表现在参数上的现象就是高次的系数趋近于0,如果直接将趋近于0的高次去掉,就可以得到一个更加简单的模型,这种方法称为正则化。
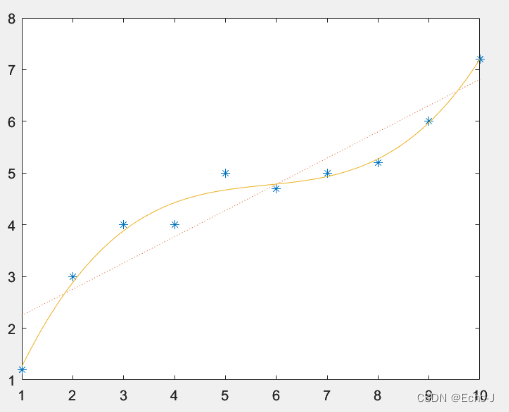
直观的看,经过正则化的模型更加平滑(图-2).
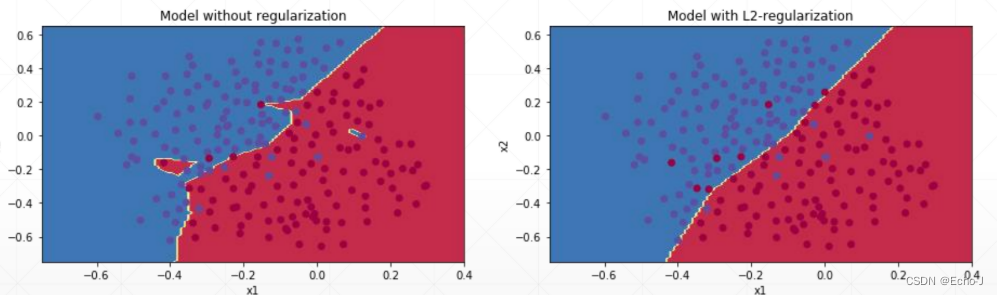
正则化的方法:
(1)L1-正则化:在原来的模型基础上加上一个 1-范数(这里使用二分类模型作为示例):
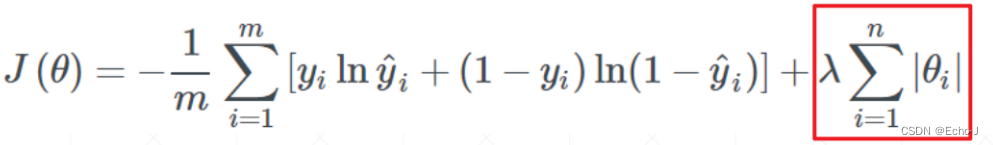
(2)L2-正则化:在原来的模型基础上加上一个 2-范数(这里使用二分类模型作为示例):
![]()
代码示例:
- # L2-正则化
- device = torch.device('cuda:0')
- net = MLP.to(device)
- optimizer = optim.SGD(net.parameters,lr = learning_rate,weight_decay=0.01) #weight_decay=0.01就代表进行L2-正则化
- criteoon = nn.CrossEntropyLoss().to(device)
- # L1-正则化
- # 对于L1-正则化,pytorch并没有提供直接的方法,就只能使用人工去做了
- regularization_loss = 0
- for param in model.parameters(): # 相求1-范数的总和
- regularization_loss += torch.sum(torch.abs(param))
-
- classify_loss = criteon(logits,target)
- loss = classify_loss + 0.01*regularization_loss # 再将得到的正则损失加入模型损失,其中0.01是1-范数总和前面的系数
-
- optimizer.zero_grad()
- loss.backward()
- optimizer.step()
3、加入动量(momentum)
动量即惯性——本次向哪移动,还需要考虑上一次移动的方向。
正常更新梯度的公式(公式-1):
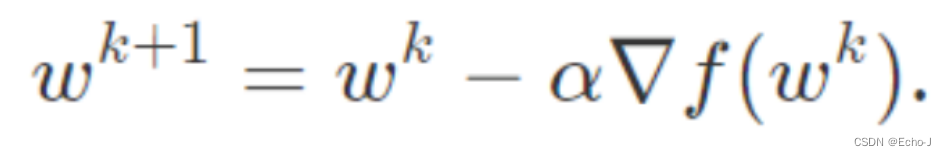
加入动量之后的公式(公式-2):
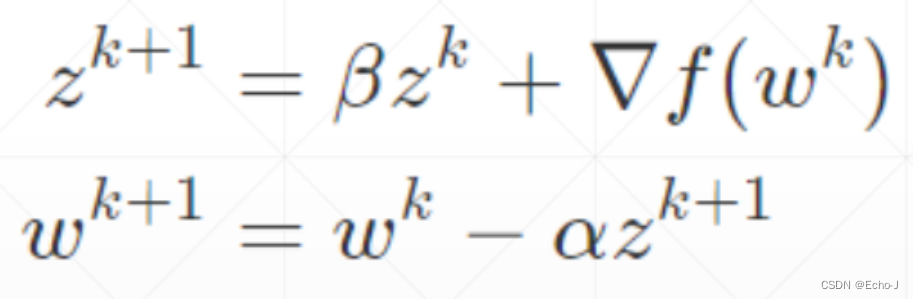
将z(k+1)带入梯度更新公式,即公式-1减去![]() ,其中Z(k)相当于上一次的梯度,系数
,其中Z(k)相当于上一次的梯度,系数和β的大小决定了是当前梯度对方向的决定性大,还是上一梯度对方向的决定性大。
当动量为0时的梯度更新情况(图-3):
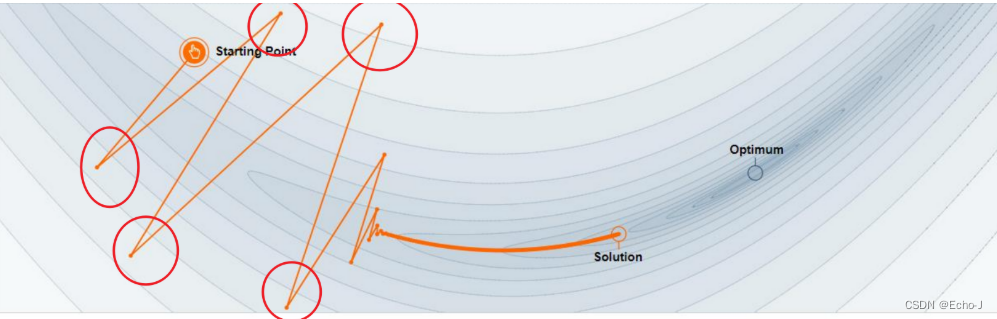
动量不为0时的梯度更新情况(图-4):
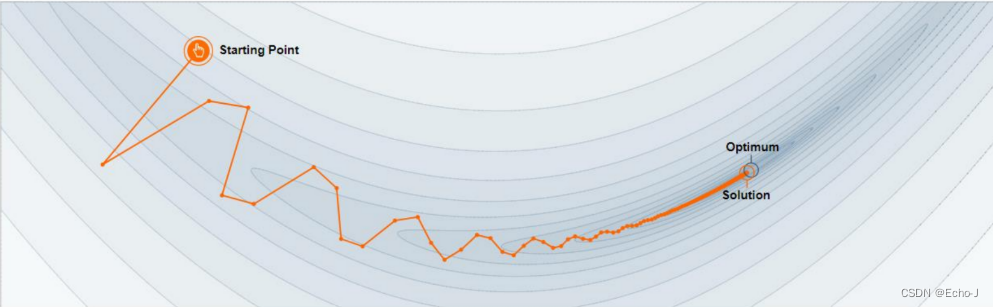
将图-3和图-4对比,可以得出动量不为0,即考虑上一梯度,梯度更新更加稳定,不会出现巨大的跳跃情况,并且不加动量的没有找到最小点,一直在局部最小值点徘徊,如果加入动量,考虑到上一梯度,可以在一定程度上解决这种情况(图-4是加入动量之后最好的情况)。
代码演示,直接在优化器部分使用momentum属性就可以了,但是如果使用Adam优化器,就不需要添加,因为在Adam优化器内部定义的有momentum属性:

4、学习率(Learning Rate )
不同学习率梯度更新情况(图-5):
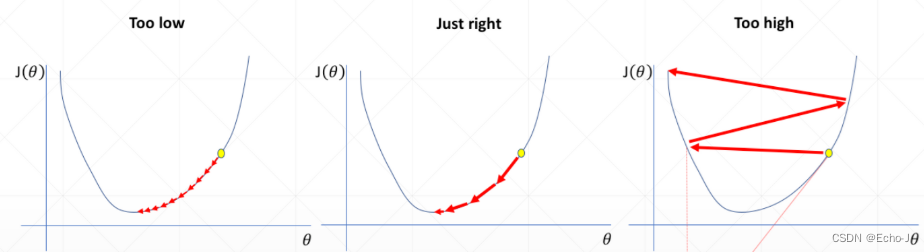
当学习率太小的时候,梯度更新比较慢,需要较多次的更新。
当学习率太大的时候,梯度更新比较激烈,找到的极值点Loss太大。
如何找到正确的的学习率?
在训练之初,可以先设置一个较大的学习率加快更新的速度,然后逐步减小学习率,即设置一个动态学习率。
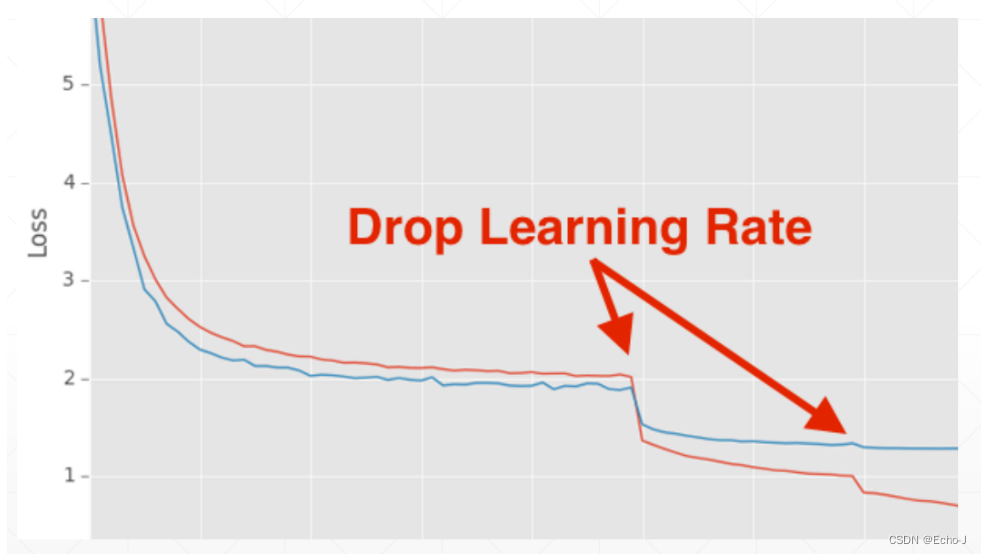
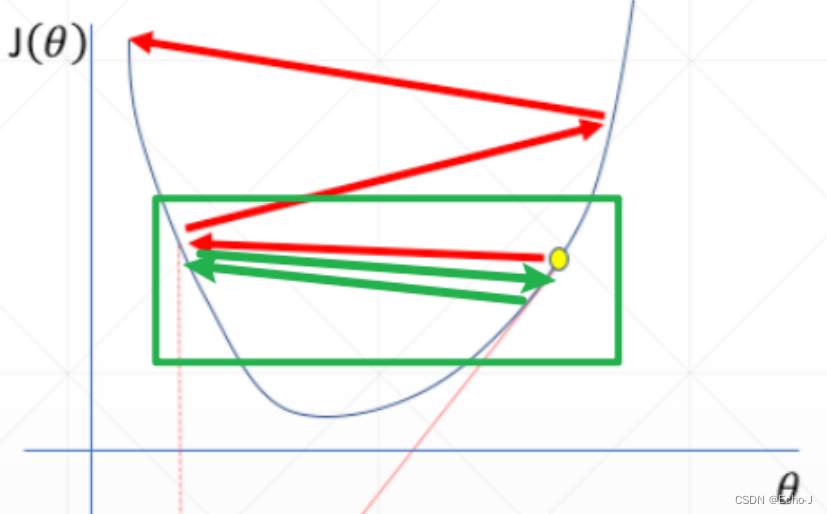
从图-6,可以看到有一个突然下降的点,这个点就是学习率训练一些数据之后,学习率突然变小导致的结果。在此之前可以看到Loss趋于不变,可以合理的猜测是因为学习率太大了,出现了来回摇摆不定的情况(图-7):
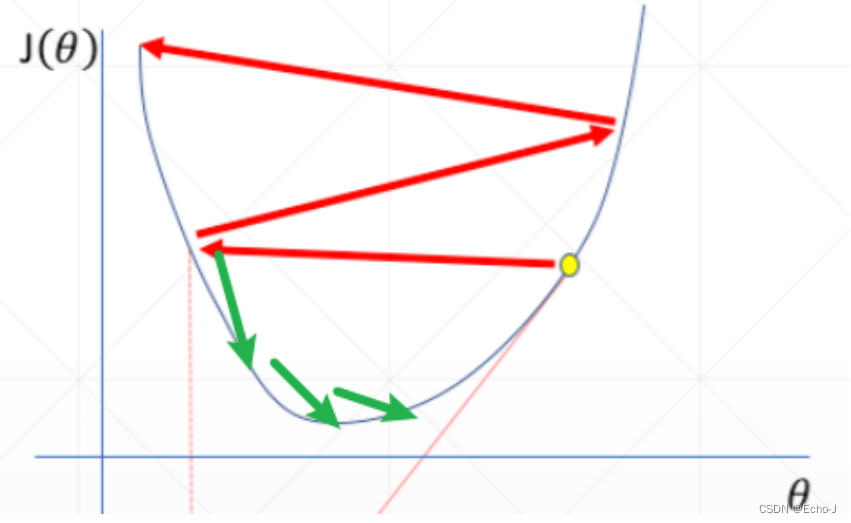
当学习率突然减小,梯度更新变慢,易找到极小点(图-8):
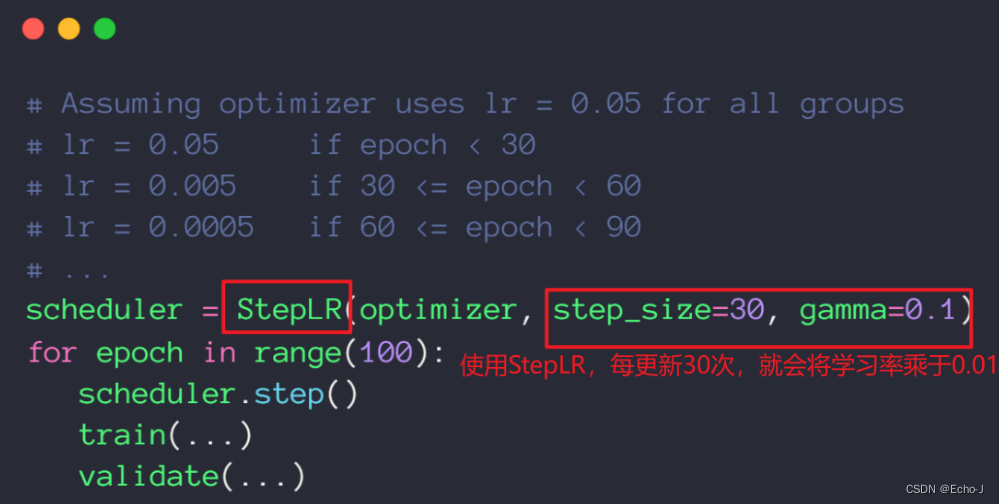
代码演示:

 5、dropout
5、dropout
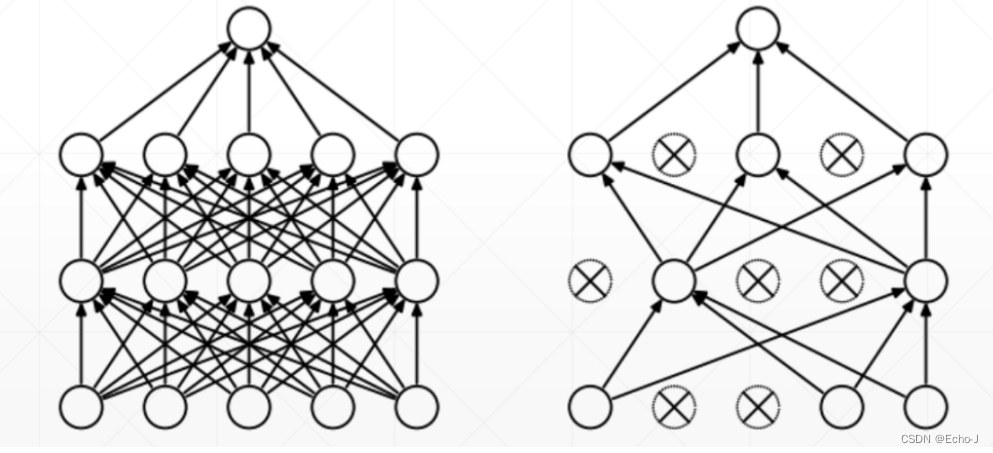
dropout:减少神经元之间的连接,减少模型的学习量。标准的神经网络是全连接的,相比经过dropout的神经网络减少了一些连接(图-9)。
代码演示,可以使用Dropout方法断开连接,0.5代表断开两层之间的50% :

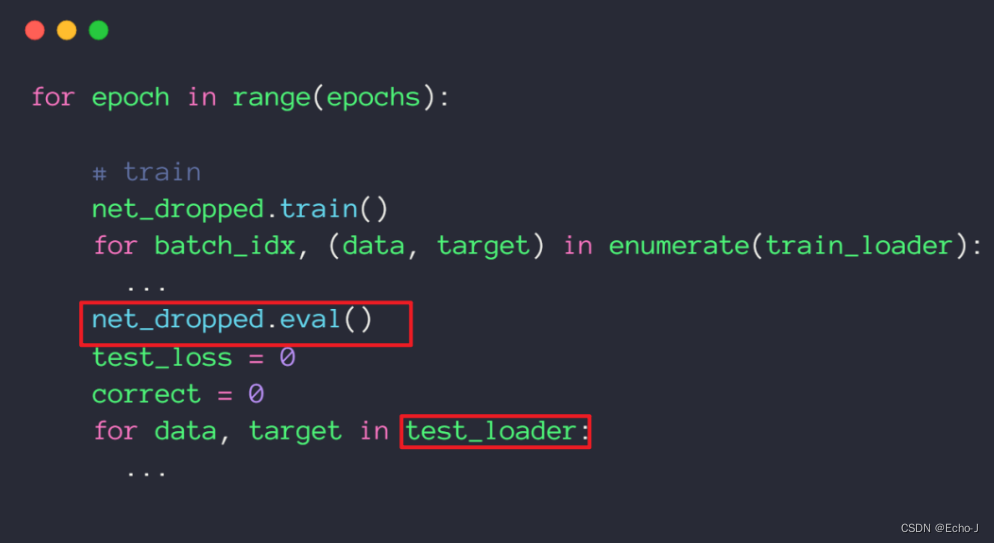
这种方法被用在模型训练中,但当模型测试过程中,为了提高test的表现,要结束这个操作,将所有的连接都使用上,可以使用net_dropped.eval()方法结束这个操作,代码演示如下:
6、随机梯度下降 (Strochastic Gradient Descent )
这里的随机并不是指任意,这里面是有一套规则的,是一套映射的关系,即将原来的数据x送入f(x)得到一种分布。经过随机从原数据中得到一组小数据,使用这一小组数据训练模型。

