
- 1netstat 命令详解_netstat命令
- 2计算机视觉:分割一切AI大模型segment-anything
- 3git流程_on branch dev your branch is up to date with 'orig
- 4声纹识别(说话人识别)技术_声纹识别算法
- 5深度学习工程师能力评估标准_aigc工程能力要求
- 6请问centos系统/etc/cron.daily/下的脚本,是在哪里设置的定时执行呢?
- 7使用Android Studio 开发APP入门经验_androidstudio与idea交互完成app开发
- 8人工智能语音如何实现?_人工智能语言是怎样实现的
- 9MTK日志adb指令开启和关闭方法_adb 判断mtk日志是否打开
- 10Android Framework 全面分析 FallbackHome
fastllm移植到Windows加快LLM推理_fastllm windows部署
赞
踩
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
最近在搞一个关于Chatglm-6B的项目,一个普通的回答要接近5秒钟,经过研究发现fastllm有明显的加速,加速后1.5秒,而且也没发现损失什么精度。
一、fastllm是什么?
fastllm是纯C++实现,无第三方依赖的高性能大模型推理库。6~7B级模型在安卓端上也可以流畅运行。今天不讨论安卓,讨论在CUDA上的部署。
二、环境准备
开始之前你需要准备一些必要的环境。对于相关开发人员来说,这些环境应该基本都是有的。
1.操作系统
Windows10和Windows11是可以的,经过实际测试的。
2.Clion
Clion-2023.2或2023.3版本都可以。我是在Clion上编译的,也可以在VS上编译,但是我这里只提供Clion的方法,VS的方法请自行研究。
3.Visual Studio
2019和2022经过测试都是可以的,需要安装C++编译工具链。你也可以不完整安装VS,只安装工具链也行,这里就不说方法了,请自行研究。
4.Python
经过测试3.9和3.10的版本都是可以的,最好使用Anaconda环境,操作起来方便。
5.CUDA
CUDA环境是一定需要的,我这里使用的是11.8,其它的环境应该也是没问题的。Windows安装CUDA环境的教程网上一大堆,大家自行搜索下。
三、配置环境
Python环境比较容易,创建一个基于3.9的虚拟环境就行了。Windows上CUDA安装会自行配置环境变量。重点说下Clion,这里需要配置VS的编译环境,自带的MingW环境不行。
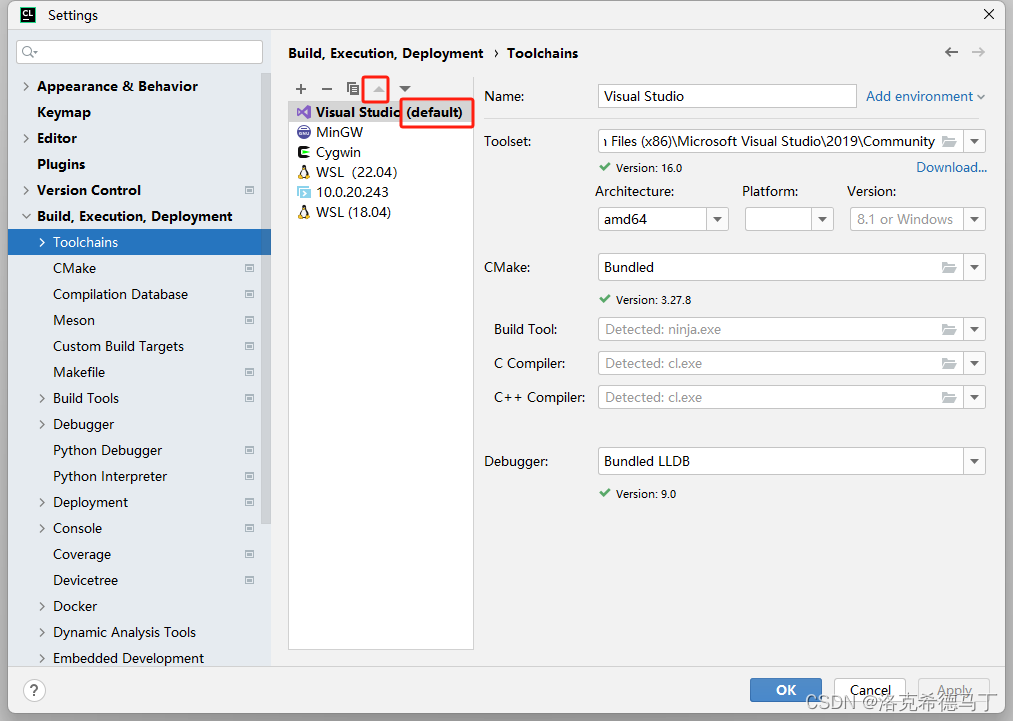
点击File->Settings->Build->Toolchains,找不到的请把IDE改成英文,我是习惯了使用英文。
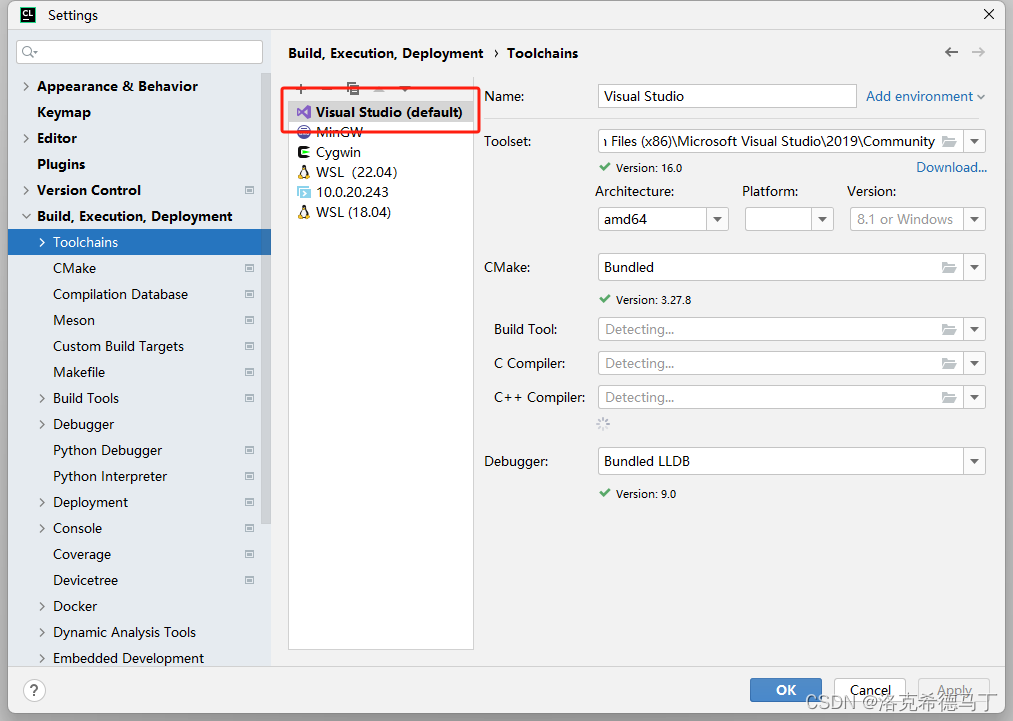
默认可能是没有VS环境的,需要手动添加的看下面的教程。前提是你已经安装好VS环境了。
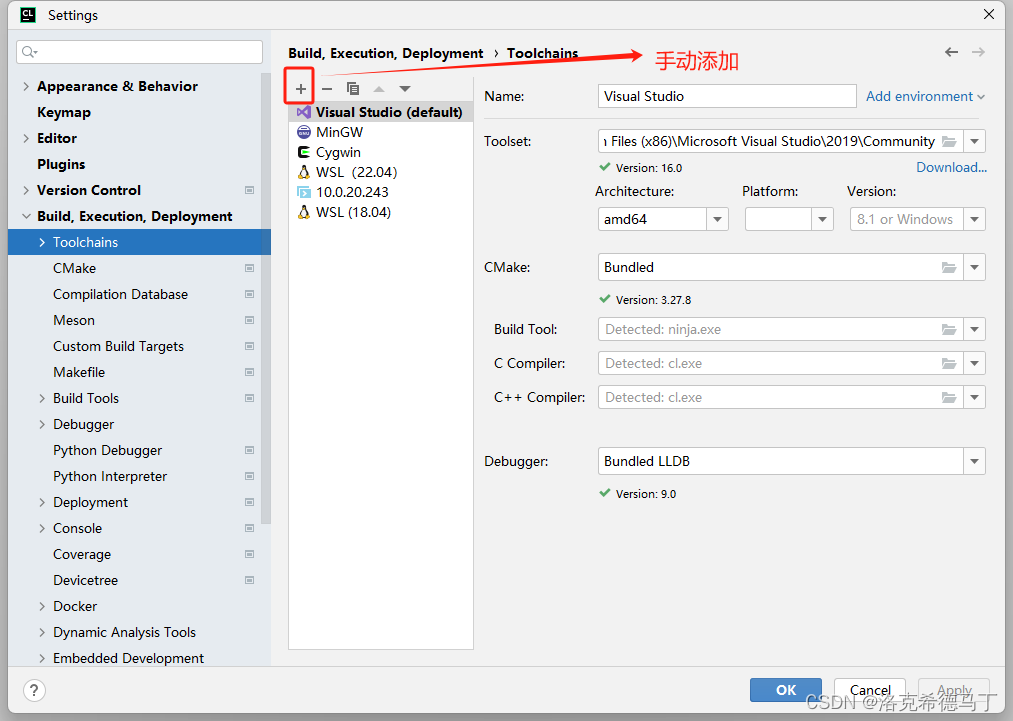
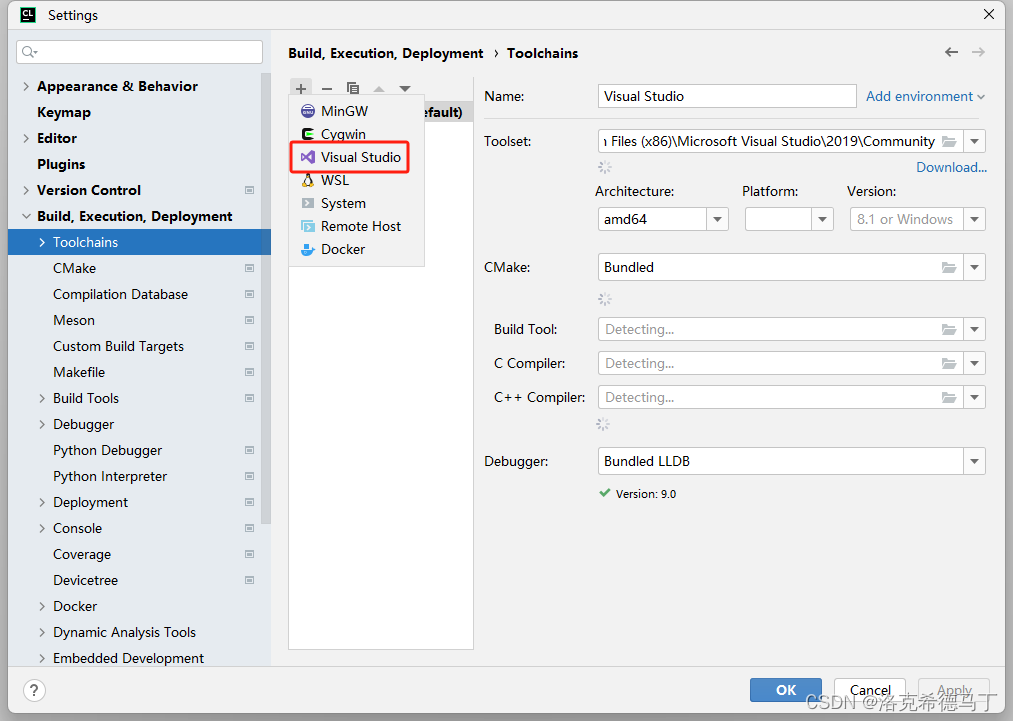
主要是Toolset,这里只说2019和2022,略有差别,我也不可能在自己电脑上都装上。
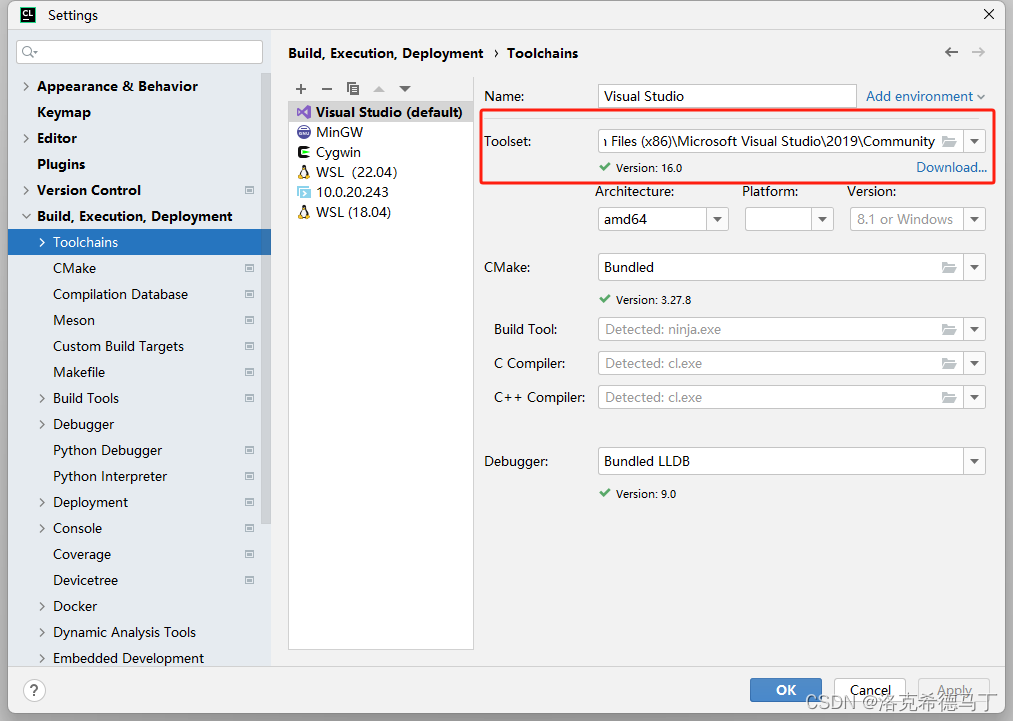
VS2019:
选择安装路径下的Community
VS2022:
选择安装路径下的BuildTools
然后Archtecture和你的操作系统有关系,我是64位系统就选amd64,其它的不用选会自动检测的。
切记:选完后将VS编译工具链移动到最顶上。
四、构建
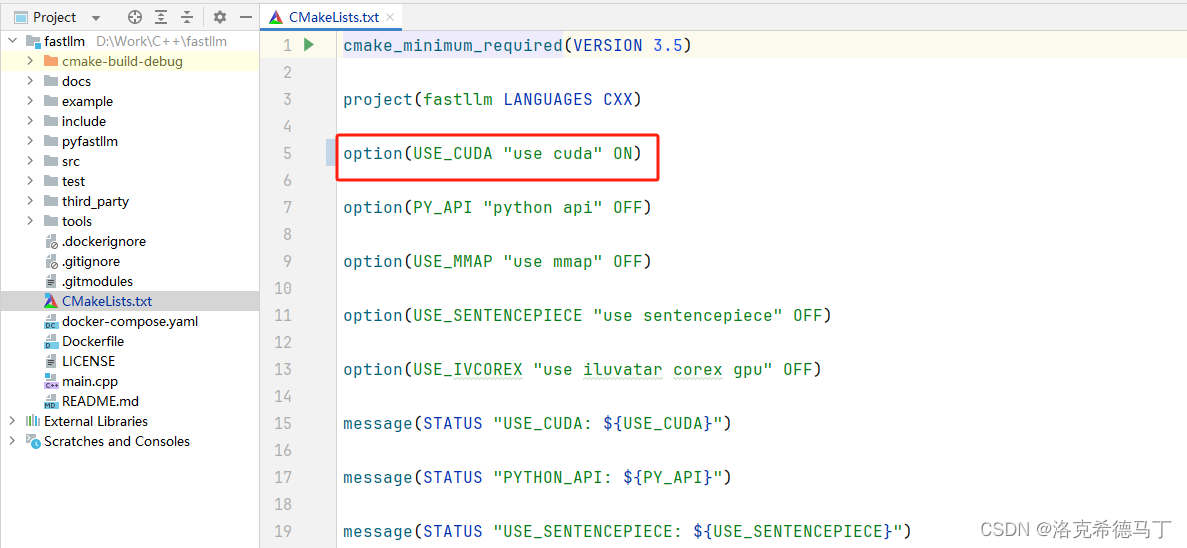
1.打开CUDA选项
2.配置Compute
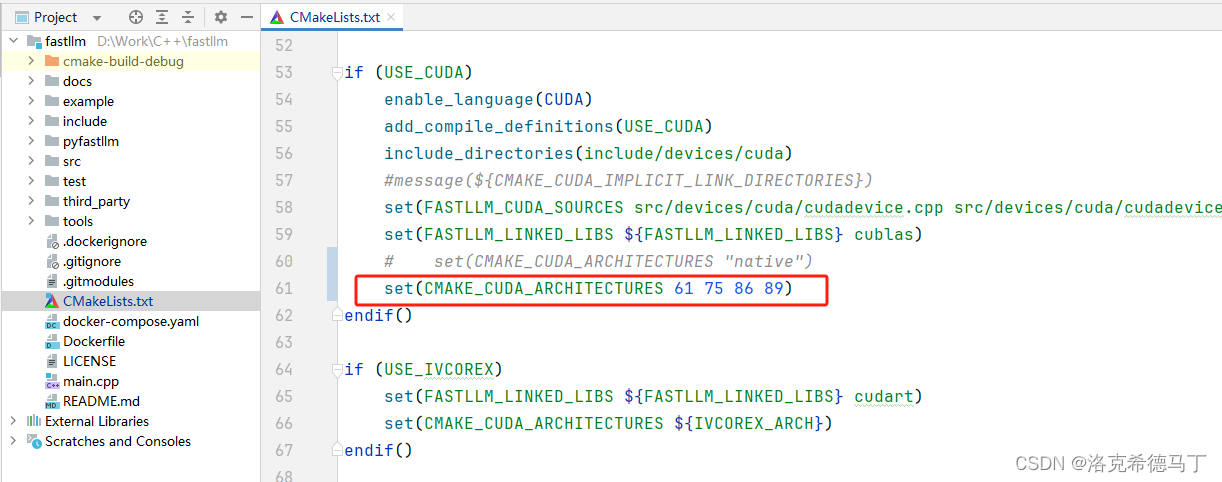
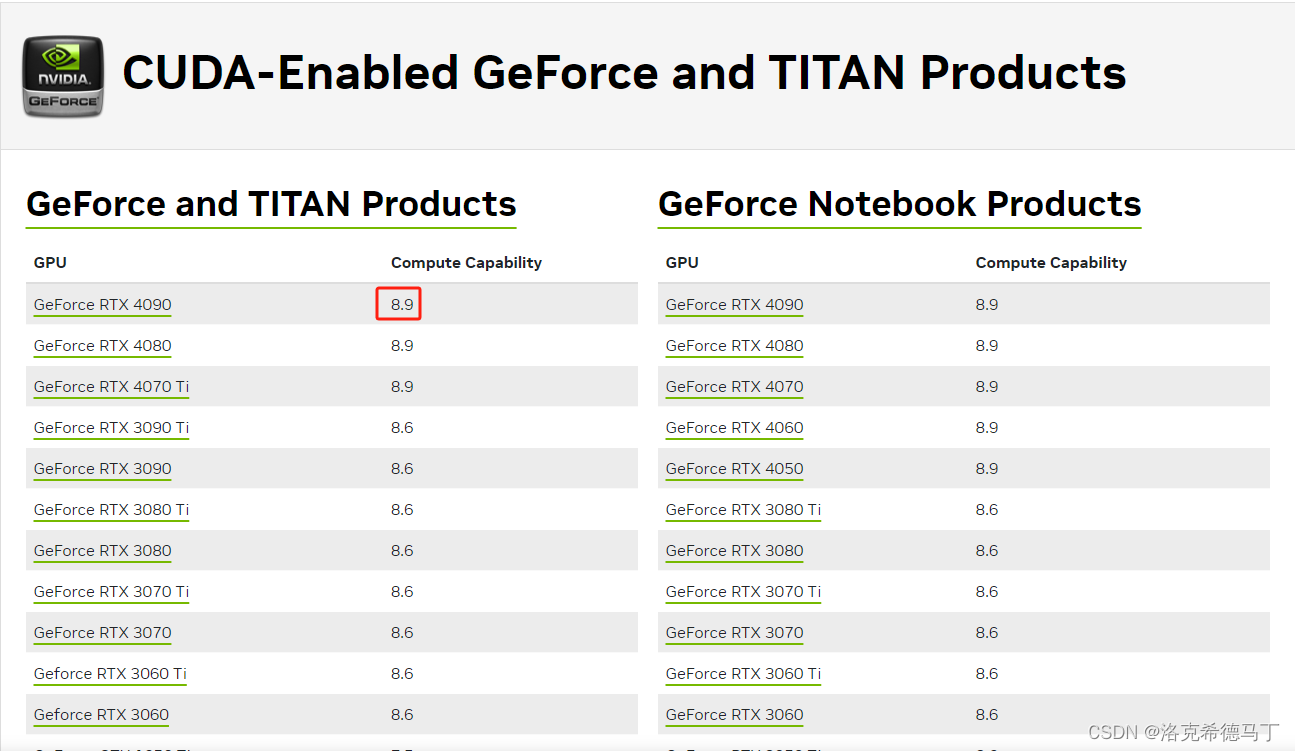
不知道自己的显卡的Compute就去英伟达官网查询。
五、编译
这个就不用教了吧,等待结束就行了,代码里出现了很多的Warning,不用担心,不影响使用。
总结
1、原作者只给了Linux上的编译方法,Windows的还是费了些波折。

