
- 1Android Audio Subsystem - AudioTrack - play_android_media_audiotrack_start
- 2VS code必备前端插件
- 3高并发下接口幂等性的解决方案_高并发下接口幂等性解决方案
- 4Spring Boot源码解读与原理分析_linkedbear
- 5使用Git LFS下载大文件到本地(Linux)
- 6python机器学习(3)线性模型:回归_sklearn.linear_model lasso
- 7EXT.JS2.2ajax请求_ext.js 创建ajax请求
- 8【面试经典150 | 矩阵】有效的数独_1到81输入9×9网格,每行每列乘积能被3整除的最少行数和列数
- 9转WIN11安装VMware Fusion_vmware fusion安装windows
- 10玩转 GPT4All
【word2vec】python读取pdf文件,通过词向量寻找相关词语_python pdf中检索关键词并定位
赞
踩
1. 什么是Word2vec
对于自然语音处理而言,首先要做的就是将文字转换为计算机能看懂的数字,也就是说,将词语进行数字化。
(1)one-hot编码,比较常用的一种编码方式,又叫独热编码。
对于一个有n个词语的序列,建立一个有n项的数组,将其中一项,记为1,其他n-1项记为0。如若n=3,则对应的所有one-hot编码为:
- 一: 1,0,0
- 二: 0,1,0
- 三: 0,0,1
优势与劣势:
-
从数值上每个字典序转换后都是1,而且有且只有一个1,避免字典序带来的数值问题;被当作连续变量来训练时,可以代表出现的概率。
-
维度灾难,有多少个词语就要扩大到多少维度,词语数量较大时候计算机的计算量太大;无法度量词语之间的相似性。
(2)词向量word2vec
为了解决独热编码的主要缺点,引入词向量,很好的避免了维度灾难!
重要假设:文本中离得越近的词语相似度越高。基于该假设,使用CBOW和skip-gram来计算词向量矩阵。通常使用后者。
-
CBOW:使用上下文词语来预测中心词
-
skip-gram:使用中心词来预测上下文词语
对词向量的评估:
-
对比现实意义中相关度比较高的词语的词向量的相似度
-
对词向量进行可视化(可能使用PCA降维)
-
类比使用:国王 - 王后 = 男人 - 女人 ?
Word2Vec的缺点:
-
没有考虑多义词和全局的文本信息
-
不是严格意义上的语序
2. 本文的目标工作
本文欲通过某个领域的一组pdf文件,以及该领域的一些关键词,通过词向量相似度找到这些关键词的相关词语。
具体的工作流程图如下:
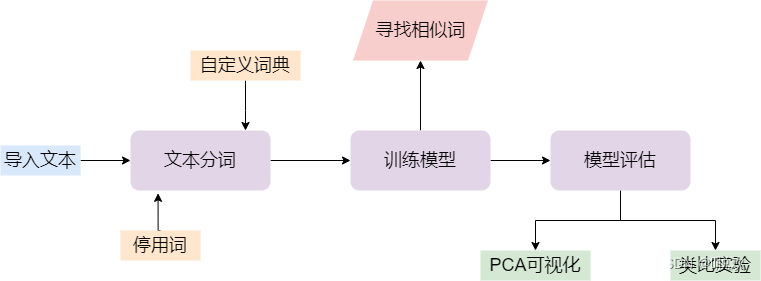
3. 文本分词
首先导入相关库:
- # 导入相关库
- import jieba
- import re
- import numpy as np
- import pandas as pd
- from sklearn.decomposition import PCA
- import matplotlib.pyplot as plt
- import matplotlib
- import gensim
- from gensim.models import Word2Vec
(1)导入停用词
在源文本中,有大量的词语,如“年”、“月”等等这样的例子似乎与我们的目标并没有什么关系,因此我们选择在进行文本分析时,忽略掉这部分词语。停用词文件的格式应为一行一词。
- stop = []
- with open('stop_words.txt','r',encoding='utf-8-sig') as f :
- lines = f.readlines() # lines是list类型
- for line in lines:
- lline = line.strip() # line 是str类型,strip 去掉\n换行符
- stop.append(lline) # stop是一维列表形式
(2)导入自定义词典
不同专业领域有不同的专有名词,而这些往往并没有出现在jieba的内置词库里,因此我们便可以认为收集/写下一些词汇,而后进行导入。userdict.txt的格式应为一行一词。
jieba.load_userdict("userdict.txt")当然,也可以添加单个词语:
jiaba.add_word('鸡你太美')(3)读取pdf文本
首先导入读取pdf文本的相关库,本文采用pdfminer。
- # 导入pdfminer相关库
- from io import StringIO
- from pdfminer.pdfinterp import PDFResourceManager
- from pdfminer.pdfinterp import process_pdf
- from pdfminer.converter import TextConverter
- from pdfminer.layout import LAParams
而后,我们根据该库定义一个读取pdf文本的函数。
- # 定义一个读取pdf的函数
- def read_from_pdf(file_path):
- # 读取pdf文件
- with open(file_path,'rb') as file:
- resource_manager = PDFResourceManager()
- return_str = StringIO()
- lap_params = LAParams()
- device = TextConverter(resource_manager,return_str,laparams=lap_params)
- process_pdf(resource_manager,device,file)
- device.close()
- content = return_str.getvalue()
- return_str.close()
- return re.sub('\s+','',content)
本文欲要处理50篇pdf,将其统一放置在一个文件夹内。为了方便遍历,我将其分别改名为1-50。遍历读取每一篇pdf,最终拼接一个大的文本。
- position = " " # 文件夹位置
- txt = ''
- for i in range(1,51):
- path = position + str(i) + '.pdf'
- temp = read_from_pdf(path)
- txt = txt + temp
- print("你已经读取好了第{}篇pdf".format(i)) # 标记一下读取到了第几篇pdf
(4)进行分词
值得注意的是,前文中我们读取pdf文本,最后合并为一个大的字符串。而我们以往常常逐行读取,而后进行分词,这样似乎能提高分词的运行效率,最终得到的结果是一个二维列表。
而这里的txt就是一行文本(不带换行符),显然无法使用这种方法。另外,后面我们调用word2vec函数,发现这个函数的参数sentence(分词列表)要求每一个元素均为列表,因此直接对txt使用jieba.lcut也是不合理的。综上,我们选择,对字符串进行500词一组的手动切割。
- i = 0
- flag = 1 # 标记是否读完文件
- lines = []
- while(flag == 1):
- if 500*(i+1) <= len(txt):
- line = txt[500*i:500*(i+1)]
- else:
- line = txt[500*i:len(txt)]
- flag = 0 # 读完文本后将flag标记为0,终止循环
- i = i + 1
- temp = jieba.lcut(line) # 结巴分词 精确模式
- words = []
- for item in temp:
- # 过滤掉所有的标点符号
- item = re.sub("[\s+\.\!\/_,$%^*(+\"\'””《》]+|[+——!,。?、~@#¥%……&*():;‘]+", "", item)
- if len(item) > 0 and item not in stop:
- words.append(item)
- if len(words) > 0:
- lines.append(words)

4. 模型训练
- # 调用Word2Vec训练
- # 参数:size: 词向量维度;window: 上下文的宽度,min_count为考虑计算的单词的最低词频阈值
- model = Word2Vec(lines,vector_size = 20, window = 2 , min_count = 3, epochs=7, negative=10,sg=1)
- print("人工智能的词向量:\n",model.wv.get_vector('人工智能')) # 测试一下,能否得出词向量
根据训练出来的模型,进一步去寻找已知关键词的相似词语。
- # 将每一个种子词语的相似词存进dataframe结构
- result = pd.DataFrame()
- for i in range(len(keywords)):
- seed = keywords[i]
- try:
- list = [item[0] for item in model.wv.most_similar(seed, topn = 30)]
- result[seed] = list
- except:
- print("There is something error with the word {}".format(seed))
- result.to_excel('result.xlsx')
- result.head(20)
5. 模型评估
(1)PCA可视化
使用PCA对高维度的词向量进行降维,将其映射为二维向量,而后可视化展现在坐标系中。
- # 将词向量投影到二维空间
- rawWordVec = []
- word2ind = {}
- for i, w in enumerate(model.wv.index_to_key): #index_to_key 序号,词语
- rawWordVec.append(model.wv[w]) #词向量
- word2ind[w] = i #{词语:序号}
- rawWordVec = np.array(rawWordVec)
- X_reduced = PCA(n_components=2).fit_transform(rawWordVec)
- print(rawWordVec) # 降维之前20维
- print(X_reduced) # 降维之后2维
加下来,对二维向量进行可视化:
- # 绘制所有单词向量的二维空间投影
- fig = plt.figure(figsize = (15, 10))
- ax = fig.gca()
- ax.set_facecolor('white')
- ax.plot(X_reduced[:, 0], X_reduced[:, 1], '.', markersize = 1, alpha = 0.3, color = 'black')
- # 绘制几个特殊单词的向量
- words = ['A', 'B', 'C', 'D', 'E', 'F']
- # 设置中文字体 否则乱码
- zhfont1 = matplotlib.font_manager.FontProperties(size=16)
- for w in words:
- if w in word2ind:
- ind = word2ind[w]
- xy = X_reduced[ind]
- plt.plot(xy[0], xy[1], '.', alpha =1, color = 'orange',markersize=10)
- plt.text(xy[0], xy[1], w, fontproperties = zhfont1, alpha = 1, color = 'red')
(2)类比关系实验
- # A-B=?- C
- words = model.wv.most_similar(positive=['A', 'B'], negative=['C'])
- print(words)
6. 不足和改进
(1)在读取pdf文本时候,本文使用的是pdfminer,以往我也使用过其它的库去解析pdf,但当进行批量处理时,往往仅一篇pdf就需要耗费十几秒甚至更长的时间,导致程序总体的运行时间很长。之后,我也查阅了相关资料,发现了以速度著称的PyMuPDF,在很大程度上优化了程序速度。
(2)在批量打开pdf时,我选择了对PDF进行改名。。。事后我也发现了使用python的os模块的相关函数可以获取所有文件名。
- import os
- filePath = ''
- list = os.listdir(filePath) # 返回一个包含所有文件名称的列表
(3)参数调优。可以进一步改善Word2Vec()函数的参数,通过比较模型评估的相关结果,以选出更优的参数组合。


