
- 1鸿蒙培训开发:就业市场的新热点~
- 2LaTeX 文件扩展名笔记_latex中后缀为.cpx的是什么文件
- 3Skywalking使用篇(二):告警配置_skywalking告警配置
- 4【IOS学习之工具学习】 Xcode7 / Xcode8 模拟器调试和真机调试_xcode模拟器能代替真机测试吗
- 5Locale 及Locale.getDefault()
- 6专有钉钉H5小程序开发- 使用jsapi_dd.authconfig
- 7LeetCode OJ:Substring with Concatenation of All Words_given a list of words l, that are all the same len
- 8c mysql 插入返回id_Java MySQL使用MyBatis插入(insert)数据获取自动生成主键的方法及示例代码...
- 9智能优化算法-乌鸦搜索算法Crow search algorithm(附Matlab代码)
- 10鸿蒙OpenHarmony NAPI技术-基础学习
Prometheus监控系统在云搜中的应用与实践
赞
踩

概述

云搜集群的资源对象动态可变,无法进行预先配置;
云搜集群监控范围繁杂,各类监控融合难度大;
云搜实例间的调用关系复杂,故障排查更困难。
在工程角度也面临着不少考验,如:
监控系统必须要保证可靠性,保证系统不会因为单点故障而全局失效,监控数据有备份机制,系统各服务的实例均可通过备份数据得到恢复;
监控系统必须支持容器上快速部署及水平扩容,这既是云原生的基本要求,也符合企业系统容器化演进的实际情况。
Prometheus是一个开源的系统监控和警报工具包,自2012年启动以来,该项目收到了广泛的关注,项目拥有非常活跃的开发人员和用户社区,许多公司和组织诸如CoreOS、Maven、SoundCloud、网易云等都采用Prometheus。目前,Prometheus已经从CNCF孵化完成,是容器云场景中监控的首选解决方案,结合云搜的实际业务场景,选择Prometheus主要有以下几个原因。
灵活的数据模型
在Prometheus里,监控数据是由值、时间戳和标签表组成的,其中监控数据的源信息是完全记录在标签表里的;同时Prometheus支持在监控数据采集阶段对监控数据的标签表进行修改,这使其具备强大的扩展能力。
更契合的架构
云搜采用Kubernetes作为容器编排工具,支持Prometheus无缝部署和扩展。如将Node-exporter以Daemonset的方式能够直接部署到集群各节点上,直接获取各节点的状态信息。
强大的查询能力
Prometheus 提供有数据查询语言PromQL。从表现上来看,PromQL提供了大量的数据计算函数,大部分情况下都可以直接通过PromQL从 Prometheus 里查询到需要的聚合数据,便于快速获取监控数据。
丰富的组件支持
Prometheus监控主体是Prometheus Operator。除此以外,Prometheus方案加入了多种组件满足Kubernetes的监控场景,如Alertmanager报警组件、Node-exporter节点资源采集组件等,极大地丰富了Prometheus方案的功能。
成熟的社区
Prometheus拥有成熟的开源社区,有丰富的参考文档,便于快速的搭建监控系统。
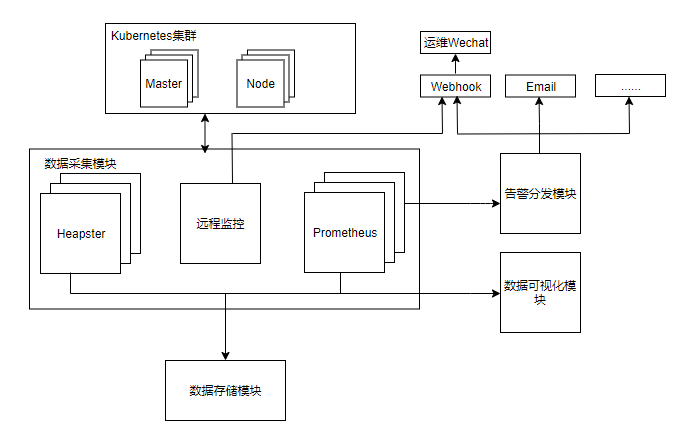
图1是云搜监控系统的物理架构,具体包括数据采集模块、数据存储模块、告警分发模块、告警上报模块、数据可视化模块五大模块。
数据采集模块:
数据采集模块主要采用以下三种方式协同采集集群数据。
采用Prometheus扩展组件Node-exporter采集底层服务器的各种运行参数,如CPU、diskstats,filesystem,loadavg,meminfo,netstat等信息。
采用Heapster采集Node节点上的cAdvisor数据,作为Node-exporter的有效补充,Heapster能够按照Kubernetes资源类型来整合资源,如pod,namespace,容器等状态信息,并将数据输出到外部存储,如本例中使用的InfluxDB,为数据可视化呈现提供有效的数据支持。
目前云搜集群的组件基本以二进制文件的方式部署,使用1、2中所述的方式无法完全监控到各组件的状态。因此采用Crontab的方式对集群各组件进行监测并收集数据,同时,支持对异常组件进行远程恢复。
数据存储模块:
数据存储模块为数据的可视化呈现提供有效的数据支持,在本例中,采用InfluxDB存储集群节点及Kubernetes资源对象的状态信息,并兼容集群已有的MySql数据库。
告警上报模块:
在运维过程中,发现邮件报警的查看率较低,报警效果差。在本例中,采用Webhook接入运维侧提供的微信报警平台,第一时间通知相关负责人。
数据可视化模块:
采用Grafana可视化工具,提供面向集群级的数据展示服务,图标可定制化,兼容多种数据源,便于用户监控管理。
在工程实现方面,云搜监控系统进行了如下设计:
采用命名空间隔离部署方式,将监控系统实例与线上搜索实例相隔离。启动数据采集组件的服务自动发现,当集群内部的节点和资源对象发生变更时,监控实例也将随之增加变化,自动发现变更后的节点或对象;
采用多监控实例作用于同一监控对象,使得单一实例失效也不会影响到此对象的监控,满足高可用的要求;
监控系统所有组件及配置均实现容器化并由Kubernetes编排;在任意 Kubernetes集群里都能够一键部署;系统需要变更时,仅需修改相关编排文件,即可完成改变。
系统详细设计
多维度集群监控
多维度集群监控旨在对集群内的资源对象及组件进行监控,并及时的上报异常信息。多维度体现在采用多种数据采集方式对集群内各组件及资源对象进行监控,监控对象主要包括以下几个方面:
集群基础组件监控:集群节点宕机、网络不可用、集群组件异常等;
集群资源对象监控:资源对象状态监控、容器状态监控等;
集群服务可用性监控:资源对象可用性监控。
集群基础资源监控
集群资源对象监控主要依赖Prometheus和Heapster模块实现,其监控流程如图2所示。Prometheus和Heapster都是Kubernetes集群内部的监控组件,但在使用场景和功能上有所区别。Prometheus既适用于面向服务器等硬件指标的监控,也适用于高动态的面向服务架构的监控,同时提供报警功能与页面的展示功能。但在容器监测上,还有所欠缺。cAdvisor是专门用来分析运行中的Docker容器的资源占用以及性能特性的工具,能够收集、聚集、处理并导出运行中容器的信息,Heapster通过调用cAdvisor接口获取当前节点上的数据。在本次设计中,采用Heapster搭配Prometheus的监控方式,对集群各资源状态及可用性进行统一的监控。

集群组件远程监控
远程状态监控模块是对Prometheus和Heapster监控方式的补充,主要采用拉模式进行对集群组件的数据采集。监控模块示意图如图3所示,监控模块流程如图4所示。


云搜集群中Master和Node逻辑上相互独立,均采用多机互备的方式,其之间的通信是依靠代理层进行流量转发。在监控上,无法单纯依赖容器原生的监控组件对Master和Node进行统一的监控。将监控数据统一汇总到告警上报模块。
集群资源告警合并
集群内的服务主要以Pod形式存在,每个Pod中包含至少一个容器。当遇到异常情况如宕机、网络异常时,势必造成大量的Pod及容器异常。因此,对于同一类告警不再是单条逐个提醒,采用简化报警,提示关键信息的方式,达到预警效果,同时避免告警风暴。
告警合并的关键是对Prometheus产生的告警进行分类,这里,我们采用的方法是自定义Prometheus的Metrics,只收集我们所关心的数据并进行分类。
Prometheus客户库提供了四个核心的Metrics类型,分别是Counter、Gauge、Histogram、Summary。这四个类型分别提供了在不同场景下的数据统计方法。我们利用这四类基础类型,搭配自定义的查询方法,过滤出我们所需要的告警数据集合。例如我们需要获取近30m中重启过的容器数,我们可以定义如图5所示的过滤表达式:

我们针对30分钟内出现的容器重启数量进行过滤。当容器出现异常情况时,Prometheus会首先向Alertmanager推送单条异常告警,如果异常情况大于1条,Prometheus会同时触发图5所示的过滤规则,此时Prometheus会将所有的告警合并成一条Json数据推送出来。根据这一特点,在接收到Alertmanager分发的告警时针对告警类型进行过滤,只提出异常情况大于一条的告警数据,从而有效的减少告警数量,监控告警过滤流程如图6所示。图7为用户接收到的告警示例。
 图6 监控告警过滤流程图
图6 监控告警过滤流程图

服务可用性监控
资源对象可用性监控依赖Pod对象的探针检测机制,被监控的对象需要先内置Liveness和Readiness探针,用来检测Pod的存活状态和可读性,当探针检测失效,会标记Pod内容器的状态。从而在集群监控检测容器状态时,一旦发现Pod或容器状态异常,第一时间上报。
定制化的监控呈现
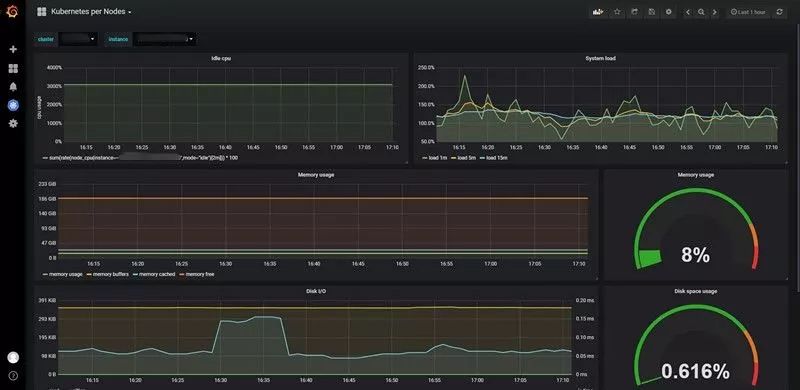
本例中采用了Grafana作为数据的主要呈现平台,辅助以PromDash进行监控项配置,为管理者提供完善的可视化监控管理平台。监控报警的选项直接通过修改Configmap资源并实时热加载,能够针对不同的监控场景快速的配置监控项目。下图8为Grafana的数据展示图表。
总结与展望
高可用:在云搜集群中,每个Prometheus监控组件实例均采用多副本方式部署;任意一个Prometheus实例失效都不会影响到监控系统的整体功能。
监控立体化:监控系统已经集成了基础组件、服务及应用等三个维度的监控告警;
可动态调整:在云搜集群架构中,支持对监控组件实例的动态可调。目前云搜支持通过调整监控组件实例数,来满足各种规模系统的监控需求。
另外,在不远的将来,还会在下面几个方面持续改进云搜监控系统:
目前系统尚不支持日志监控及分布式追踪等功能,考虑在日后加入ELK进行日志监控,通过Logstash搭配Elasticsearch方便监控日志的查询。
增强监控及告警响应的速度,加入更多的自处理机制。
引入Helm包管理工具管理系统的部署文件,简化部署的流程。
作者:李阳,来自58集团TEG云搜索部,后端高级开发工程师,专注于分布式高可用架构设计、微服务等领域。
本文转载自公众号:58架构师, 点击查看原文。



