
热门标签
热门文章
- 1基于ros-qt 开发ui界面完成标定工具包_标定界面ui
- 2RK3568技术笔记十五 固件烧写_rk3568固件解sr
- 3ES聚合查询详解(二):桶聚合_mindoccount
- 4自己电脑做服务器需要装什么系统,自己电脑做服务器需要什么配置
- 5在idea下terminal输入git的status命令后出现中文乱码\346\240\210/的解决办法_idea使用git status之后无法输入命令了
- 6【Yarn】系统架构&高可用_yarn采用的体系架构是主从结构,其中主节点是 ,从节点是 。
- 7大数据的5V特征分别是什么?_大数据5v特性
- 8各种对抗神经网络(GAN)大合集_gan non-overlapping
- 9git合并分支(一看就懂)_合并分支成功后显示啥页面
- 10程序猿214情人节专题----基于GitHub打造个人网站及Android的录制功能使用_android 录像github
当前位置: article > 正文
(一)Pytorch快速搭建神经网络模型(代码+详细注解)_pytorch代码教程
作者:Guff_9hys | 2024-07-12 23:42:00
赞
踩
pytorch代码教程
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
最近开启了对深度学习的探索,在这记录学习到的内容,希望对大家有所帮助,代码直接按照顺序复制粘贴后就可以运行,代码参考唐宇迪人工智能课程中的深度学习入门课
一、数据读入
数据集使用的是mnist手写数字识别
from pathlib import Path
import requests
import pickle
import gzip
import torch
from torch import nn
import torch.nn.functional as F
from torch import optim
import numpy as np
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
# 下载文件,放到data目录下
DATA_PATH = Path("data")
PATH = DATA_PATH / "mnist"
PATH.mkdir(parents=True, exist_ok=True)
URL = "http://deeplearning.net/data/mnist/"
FILENAME = "mnist.pkl.gz"
if not (PATH / FILENAME).exists():
content = requests.get(URL + FILENAME).content
(PATH / FILENAME).open("wb").write(content)
# 读取文件
with gzip.open((PATH / FILENAME).as_posix(), "rb") as f:
((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding="latin-1")
# 将所有使用的数据格式转化为tensor的格式
# tensor:张量,通俗理解就是矩阵
# torch可以处理的数据就是tensor,需要进行一下数据转换
x_train, y_train, x_valid, y_valid = map(torch.tensor, (x_train, y_train, x_valid, y_valid))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
二、模型搭建
bs = 64
# batchsize是64,在数据集中每次读取64张图片
# 使用定义好的交叉熵损失作为损失函数
loss_func = F.cross_entropy
class Mnist_NN(nn.Module):
def __init__(self):
super().__init__()
# # nn.Linear就相当于xw+b,(784,128):输入784像素点,输出128个特征
# # 第一个全连接层 1*(784)×w1(784*128)->1*128
self.hidden1 = nn.Linear(784, 128)
# # 第二个全连接层:hidden2的输入是hidden1的输出 (1*128)×w2(128*256)->1*256
self.hidden2 = nn.Linear(128, 256)
# # 输出层,获得十个特征(1*256)×w2(256*10)->1*10
self.out = nn.Linear(256, 10)
# # dropout:避免过拟合,随机杀死一些神经元
# # 按照百分之0.5的概率杀死一些神经元
self.dropout=nn.Dropout(0.5)
# # 前向传播,输入——得到结果,
# # 前向传播需要自己定义,反向传播是自动进行的
# # 定义前向传播
# # x:就是一个batch,在这里是64*784
# # 设计一个前向传播
def forward(self, x):
x = F.relu(self.hidden1(x)) # 64*128
# 每一个全连接层都加dropout,卷积层不加
x = self.dropout(x)
x = F.relu(self.hidden2(x)) # 64*256
x = self.dropout(x)
# 输出层
x = self.out(x) # 64*10
return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
三、获取数据函数
def get_data(train_ds, valid_ds, bs):
return (
# shuffle=True:训练集数据打乱数据
# 测试集不用打乱顺序
DataLoader(train_ds, batch_size=bs, shuffle=True),
DataLoader(valid_ds, batch_size=bs * 2),
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
运行
四、定义损失
def loss_batch(model, loss_func, xb, yb, opt=None):
loss = loss_func(model(xb), yb)
# 计算损失 model(xb):预测 yb:真实值
# 优化器
if opt is not None:
# 反向传播,计算梯度
loss.backward()
# 更新w和b
opt.step()
# 每一次的迭代更新之间没关系,要及时归0
opt.zero_grad()
return loss.item(), len(xb)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
运行
五、模型实例化
def get_model():
# 模型实例化
model = Mnist_NN()
# optim.SGD(model.parameters(), lr=0.001)
# SGD梯度下降,model.parameters():w和b全部更新
# lr=0.001 学习率
return model, optim.SGD(model.parameters(), lr=0.001)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
运行
六、模型训练和测试
def fit(steps, model, loss_func, opt, train_dl, valid_dl):
# steps=epoch:整个数据集,
# batch:
for step in range(steps):
# 模型训练:更新w和b
# xb, yb:数据包和标签
model.train()
for xb, yb in train_dl:
loss_batch(model, loss_func, xb, yb, opt)
# 模型验证:不更新参数,直接验证
model.eval()
with torch.no_grad():
losses, nums = zip(
*[loss_batch(model, loss_func, xb, yb) for xb, yb in valid_dl]
)
# 计算验证集的loss,、得出的是平均损失
val_loss = np.sum(np.multiply(losses, nums)) / np.sum(nums)
print('当前step:'+str(step), '验证集损失:'+str(val_loss))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
运行
七、加载数据
# 该方法不常用,了解即可
train_ds = TensorDataset(x_train, y_train)
# DataLoader相当于打包员,打包成一个个batchsize的数据
train_dl = DataLoader(train_ds, batch_size=bs, shuffle=True)
valid_ds = TensorDataset(x_valid, y_valid)
valid_dl = DataLoader(valid_ds, batch_size=bs * 2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
八 、程序运行
train_dl, valid_dl = get_data(train_ds, valid_ds, bs)
model, opt = get_model()
fit(10, model, loss_func, opt, train_dl, valid_dl)
- 1
- 2
- 3
九 、计算准确率
# 计算准确率
correct=0
total=0
# 看验证集的正确率
for xb,yb in valid_dl:
outputs=model(xb)
_,predicted=torch.max(outputs.data,1)# 最大值和索引
total+=yb.size(0)# 验证的验证集数量,
# (predicted==yb).sum计算预测对的结果
# item的作用就是将数据结构由tensor换成数字
correct+=(predicted==yb).sum().item()
print("网络的准确率:%d %%"%(100*correct/total))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
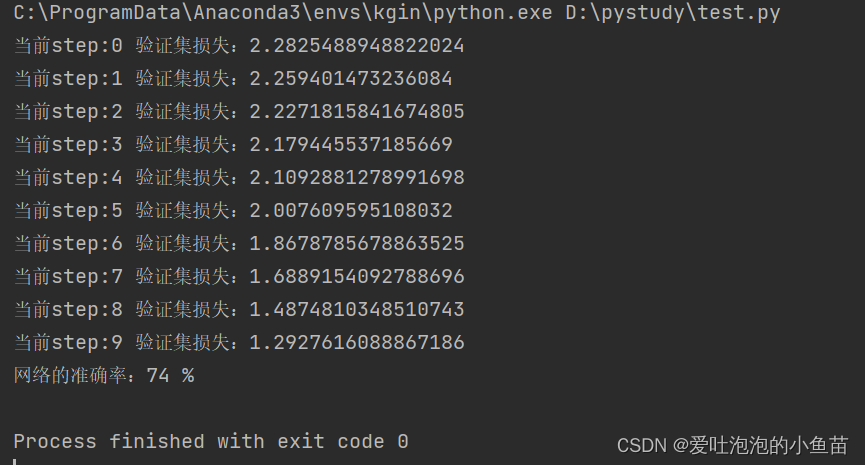
十、运行结果
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Guff_9hys/article/detail/816635?site
推荐阅读
相关标签

