
- 1助企上云新举措!移动云网盘服务平台正式上线_移动云 云服务平台
- 2尝试LTP三天后终于成功了_pip install ltp
- 3IDEA如何配置 Gradle 及 Gradle 安装过程(详细版)_idea配置gradle
- 4android so文件不混淆_研发干货丨基于OK3399-C平台android系统下实现图像识别
- 5Android实现隐藏显示部分View_android slidingdrawer 能否只隐藏部分
- 6SpringCloud学习(十六):Gateway网关的基本介绍与搭建_springcloud gateway搭建
- 7面试经验总结_pcl 点云 面试
- 8C# 自动点击、发送消息
- 9关闭Eslint_eslint 关闭
- 10关于XML编译错误
图像兴趣点检测与描述 的深度学习方法总结_如何选择追踪哪些兴趣点深度学习
赞
踩
图像的兴趣点(关键点、特征点)检测和描述往往是图像配准、相机标定、场景识别、目标跟踪的首要步骤,是计算机视觉研究的重要课题。检测子的目的是为了提取可匹配的兴趣点,而描述子可用于匹配或识别,为下游任务作准备。网上很多文章[1,2]都只介绍了传统的SIFT、SURF、ORB等方法,关于深度学习的方法缺少一篇系统的总结性文章,本文将填一下这个坑。
本文重点用自己的理解介绍LIFT[3]、DeLF[4]、SuperPoint[5]、D2Net[6]几篇文章的发展脉络和创新点分析。
本文创作不易,转载请标明出处 @CSDN 窗外的千纸鹤
代表性工作
在介绍具体工作之前,先捋一下此任务的一种pipeline。 一种经典的pipeline来源于SIFT,可以分为三个模块,1)兴趣点检测子(detector):目的是检测出可匹配的点,输出的是这些点的坐标 { x , y } \{x,y\} {x,y}, 如果考虑尺度不变性(可参考我的下一篇文章),还返回该点的尺度。然后会以检测子为中心,根据尺度的大小取周围的像素点生成一个patch送入后面两个模块。2) 主方向估计子(Orientation Estimator)(非必须):目的是找到该patch的主方向,从而使描述子具有旋转不变性。3)特征描述子(descriptor):目的是为下游任务(如匹配、识别)作准备。
纵观整个pipeline, 其中最重要的是detector和descriptor。 而descriptor很容易学,CNN+对比损失 即可。我比较感兴趣的是detector, 根据SIFT的指导思想,找出具有局部差异性的点,而且是尺度空间的极值点,即“在尺度空间和坐标空间同时搜索极值点”。然而,因为SIFT不存在训练的过程,它自然不需要人告诉它关键点在哪,即不需要标签。但是,深度学习不需要标签怎么能行?且看下面这些方法如何解决这个问题。
1. LIFT (2016)
这是深度学习detector和descriptor的早期作品,我读完获得很多知识和灵感。废话不多说,先上这个模型的创新点
1.1 模型创新点
- 将上述三个模块统一成端到端的模式,并保持可微分性。这是作者放在摘要的一句话,可见是他认为全文最大的创新点。为什么这个点这个值得一提呢,因为这个任务里端到端有几个难点,1)detector返回一个坐标,这个过程怎么形式化表述,怎么保证他可微?2)端到端意味着将最后只会监督描述子,那么detector和Orientation Estimator没人监督(隐式表征),你怎么保证这个两个模块学的好?网络能收敛吗?待会且看这篇文章如何解决这个问题
- 效果上,比SIFT好,而且三个模块任何一个模块改成SIFT的方法就会变差,说明模型的设计不是纸上谈兵的。
1.2 模型实现

detector如何输出坐标,并保持可微分性?
在detector阶段,有两个Patch概念需要厘清,第一个patch P是网络的输入,文章假设一个patch只有一个关键点。在patch中提取出关键点后,再其周围再生成一个小patch p, 由于后面两个模块,显然p 是 P 的子集。
为了获得关键点的位置,作者先用一个CNN生成score map, 然后用softmax建立权重,最后使用patch内部的坐标加权得到(如下面的公式所示)。
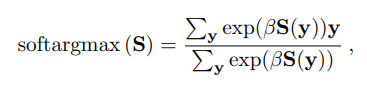
如何监督隐式表征的检测子?
首先是关键点的标签:来自于SIFT+SfM产生,具体操作可以参考原论文
作者使用了两种损失函数监督,一种是结果导向型的目标函数,一种是分类的损失函数

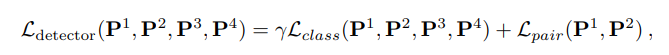
- 结果导向型:
图中 P 1 , P 2 P^1, P^2 P1,P2表示正样本,即是同一个目标区域但是不同视点下的图像。
作者用了一种很巧妙的训练策略,就是我先基于SIFT+SfM作为检测子把方向估计子和特征描述子的CNN预训练一下,然后反过来再来训练我自己的检测子。如下式子所示, h ρ h_\rho hρ是描述子,G是方向估计子,都是训练好的,只有 f μ f_\mu fμ检测子未训练,所以虽然我监督的是正样本的特征距离,但是我只学习检测子,理论上当两个patch检测到的位置一致时,他们的特征距离时最小的。
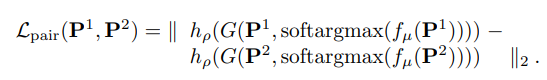
- 分类损失:
P 1 , P 2 , P 3 P^1, P^2,P^3 P1,P2,P3都含有关键点,但是 P 4 P^4 P4没有,因此可以类似分类的思想,让前三个P的score的最大值变大(用了一个relu防止score到无穷), P 4 P^4 P4的score最大值变小。

1.3 局限性
- 非单一网络:三个模块各自需要一个网络,且需要各自监督,不太unified
- 需要借助SIFT+SfM模块:关键点的标签由别人的模型产生,那么你的关键点检测子的上限是否就是别人的模型了呢
- 速度慢:三个网络,逐个patch卷积
2. DeLF (2017)
这篇文章的架构与上篇文章有很大不同:首先,这个模型用于图像检索而不是图像配准;其次,这不是端到端的架构而是“显示(explicit)“地监督检测子和描述子; 然后,这篇文章没有方向估计子模块,而是让网络自己学习旋转不变性。所以DeLF和LIFT属于两个流派,那么DeLF给这个领域带来了什么贡献呢,看下面的创新点部分

2.1 创新点
- 先描述再检测。传统的Pipeline都是先检测出关键点,然后进行关键点描述。这种模式的问题是检测子基于的是低级的特征。而DeLF的模式是先训练特征图,然后再在特征图上面检测关键点,好处是检测子基于的是高级语义特征。
- 基于注意力的关键点选取。如图(b)的黄色部分,通过在降采样的特征图上进行注意力机制得到关键点权重,然后经过特征加权得到全局特征,再用一个地标分类器(MLP)去拟合标签。(注意力具体怎么用文章根本没有介绍,后续可以参考其代码)
2.2 检测子训练方法
也是一种间接的方式,没有直接训练检测子,而是将检测子的分数作为权重 加权求和特征,最后去监督特征。
3. SuperPoint (2018)
十分精妙且易读的文章,非常值得一看!
关于SuperPoint与LIFT的差异,作者给出了下面这个表格,结合我前面分析的LIFT的局限性,可以很好地理解。当然还有一些其他差别,我放在创新点部分总结。
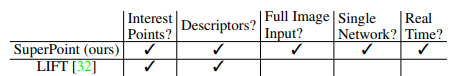
4. D2Net
以上大多是个人理解,如有问题欢迎指正
转载请注明出处@CSDN 窗外的千纸鹤
参考文献
- https://zhuanlan.zhihu.com/p/128937547
- https://blog.csdn.net/blateyang/article/details/76512398
- Kwang Moo Yi, Eduard Trulls, Vincent Lepetit, and Pascal Fua. Lift: Learned invariant feature transform. In European conference on computer vision, pages 467–483. Springer, 2016.
- Hyeonwoo Noh, Andre Araujo, Jack Sim, Tobias Weyand, and Bohyung Han. Large-scale image retrieval with attentive deep local features. In Proceedings of the IEEE international conference on computer vision, pages 3456–3465, 2017.
- Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Superpoint: Self-supervised interest point detection and description. In Proceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 224–236, 2018.
- Mihai Dusmanu, Ignacio Rocco, Tomas Pajdla, Marc Pollefeys, Josef Sivic, Akihiko Torii, and Torsten Sattler. D2-net: A trainable cnn for joint detection and description of local features. arXiv preprint arXiv:1905.03561, 2019.

