
- 1python 连接MySQL数据库,前端使用HTML并引用bootstrap/css 模板_python如何使用bootstrap
- 2无线网络加密方式
- 3【二】软核学习_tf 软核
- 4【算法】六大排序 插入排序 希尔排序 选择排序 堆排序 冒泡排序 快速排序_简单排序,简单插入排序,堆排序,快速排序
- 515个最流行的免费3D CAD模型下载网站【2023】_cad免费素材库
- 6python爬取2345天气网气象数据
- 7MYSQL: 渐行渐远的开源关系型数据库典范_mysql关系型数据库
- 8van-list 遇到的问题
- 9Java设置PPT幻灯片背景——纯色、渐变、图片背景
- 10SQL数据库邮件定时发送_hivesql定时邮件
Vision Transformer(Vit)网络模型_vit模型的transformer的结构的数学公式
赞
踩
前言
Google团队于2017年发表论文并提出Transformer模型,最早用于机器翻译,随后不久也用到图像方面。不同于传统的CNN模型,Transformer模型完全基于注意力机制。有利于降低模型结构的复杂性,提高模型的扩展性和训练效率。
论文地址:Transformers for Image Recognition at Scale
网络结构
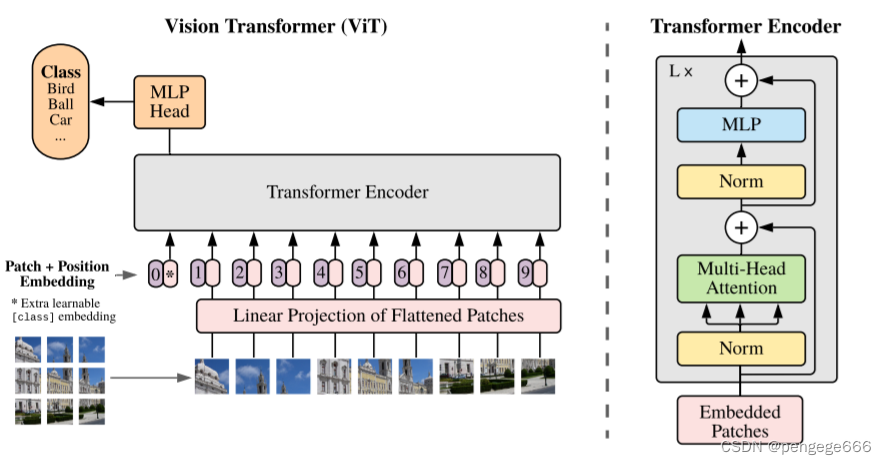
整体流程
-
给定一张图片
X,并将它分割成9个patch分别为x1~x9。然后再将这个9个patch 拉平,则有x1~x9; -
利用矩阵
W将拉平后的向量x1~x9经过线性变换得到图像编码向量z1~z9,具体的计算公式为:

-
然后将图像编码向量
z1~z9和类编码向量z0分别与对应的位置编进行加和得到输入编码向量,则有:

-
接着将输入编码向量输入到 Vision Transformer Encoder 中得到对应的输出
o0 -
最后将类编码向量
o0输入全连接神经网络中 MLP 得到类别预测向量y^,并与真实类别向量y计算交叉熵损失得到损失值 loss,利用优化算法更新模型的权重参数。
编码器和解码器
Transformer
编码器的每个层由2个子层所组成,多头注意力和前馈层。解码器的每层由3个子层所组成,掩码多头注意力机制、多头注意和前馈连接层。每个子层的最后都连接着残差神经网络和规范化层。
该图片取自Transformer模型详细介绍

Vision Transformer
Vision Transformer 里没有 Decoder 模块,所以不需要计算 Encoder 和 Decoder 的交叉注意力分布。

注意:
假设我们按照论文切成了9块,但是在输入的时候变成了10个向量??这是人为增加的一个向量。
因为传统的Transformer采取的是类似seq2seq编解码的结构
而ViT只用到了Encoder编码器结构,缺少了解码的过程,假设你9个向量经过编码器之后,你该选择哪一个向量进入到最后的分类头呢因此这里作者给了额外的一个用于分类的向量,与输入进行拼接。同样这是一个可学习的变量。
自注意力机制
注意力机制源于人类感知行为。注意力机制是模型设计的精髓。

- 步骤一: 创建向量。从
Encoder的输入创建3个向量,分别为q,k,v。 - 步骤二:计算每个向量的得分。得分值是当前向量对输入的其他部分的关注程度。方法是将(query,Q)和(key,K) 做点乘操作。
- 步骤三:除以缩放因子。将步骤二的结果除以缩放因子(键向量的维数的平方根)。这样可使梯度更加稳定。
- 步骤四:
softmax标准化。通过softmax函数标准化计算向量间的相关性。 - 步骤五:将每个值
(value,V)向量乘以softmax的结果。将关注放在相关的信息上面。 - 步骤六:加权求和。将步骤五获得的向量进行相加操作,最终的向量表示自注意力层在当前位置的输出结果。

用公式表示为:

多头注意力机制
多头注意机制中,将查询(query,Q) 、键 (key,K) 和值(value,V)三个参数拆分成多组,每组拆分的参数投影到高维空间的不同表示子空间中。每个头学习到的注意力的关注重点各不相同

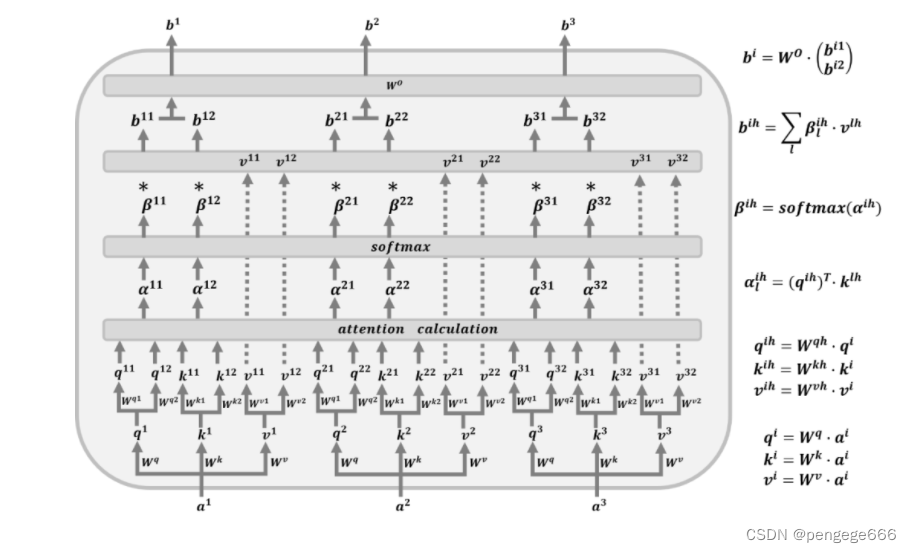
Multi-Head Attention 的工作原理与 Self-Attention 的工作原理非常类似。为了方便图解可视化将 Multi-Head 设置为 2-Head。这部分详细讲解可见一文详解Vision Transformer
代码详解
多头注意力机制代码
#多头注意力机制 class SelfAttention(nn.Module): #pytorch里面自定义层也是通过继承自nn.Module类来实现的 def __init__(self, embed_size, heads): # 继承一下 super(SelfAttention, self).__init__() self.embed_size = embed_size #embed_size: 每个单词用多少长度的向量来表示 self.heads = heads #自注意力机制的头数 self.head_dim = embed_size // heads #计算出每个头的维度 #判断是否整除 assert (self.head_dim * heads == embed_size), "Embed size needs to be div by heads" #三个全连接分别计算qkv,全连接层有定义W^q ,W^k ,W^v的意思 #nn.Linear(in_features,out_features,bias) #图像中的个人理解:改变输出通道数 #参数in_features:输入的[batch_size, size]中的size。 #参数out_features:二维张量的形状为[batch_size,output_size] self.values = nn.Linear(self.head_dim, self.head_dim, bias=False) self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False) self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False) # 输出层 self.fc_out = nn.Linear(heads * self.head_dim, embed_size) # 前向传播 qkv.shape==[b,seq_len,embed_size] def forward(self, values, keys, query): N =query.shape[0]# 词的数量 value_len , key_len , query_len = values.shape[1], keys.shape[1], query.shape[1] # 维度调整 [b,seq_len,embed_size] ==> [b,seq_len,heads,head_dim] values = values.reshape(N, value_len, self.heads, self.head_dim) keys = keys.reshape(N, key_len, self.heads, self.head_dim) queries = query.reshape(N, query_len, self.heads, self.head_dim) # 对原始输入数据计算q、k、v values = self.values(values) keys = self.keys(keys) queries = self.queries(queries) # way1 # 爱因斯坦简记法矩阵元素,其中query_len == keys_len == value_len # attention.shape = [N, heads, query_len, keys_len] # values.shape = [N, value_len, heads, head_dim] # out.shape = [N, query_len, heads, head_dim] # way2 # queries shape: (N, query_len, heads, heads_dim) # keys shape : (N, key_len, heads, heads_dim) # energy shape: (N, heads, query_len, key_len) energy = torch.einsum("nqhd,nkhd->nhqk", queries, keys) #softmax attention = torch.softmax(energy/ (self.embed_size ** (1/2)), dim=3) # out = torch.einsum("nhql, nlhd->nqhd", [attention, values]).reshape(N, query_len, self.heads*self.head_dim) # attention shape: (N, heads, query_len, key_len) # values shape: (N, value_len, heads, heads_dim) # (N, query_len, heads, head_dim) out = self.fc_out(out) return out

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
查看数据在网络中传输
#测试
net=SelfAttention(64,8)
q = torch.rand(64, 15, 64)
# batch_size 为 64,有 12 个词,每个词的 Key 向量是 64维
k = torch.rand(64, 15, 64)
# batch_size 为 64,有 10 个词,每个词的 Value 向量是 64 维
v = torch.rand(64, 15, 64)
print(net(q,k,v).shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
结果
torch.Size([64, 15, 64])
- 1
代码中多头注意力机制不改变张量的形状
编码模块代码

class TransformerBlock(nn.Module): ''' embed_size: wordembedding之后, 每个单词用多少长度的向量来表示 heads: 多头注意力的heas个数 drop: 杀死神经元的概率 forward_expansion: 在FFN中第一个全连接上升特征数的倍数 ''' def __init__(self, embed_size, heads, dropout, forward_expansion): super(TransformerBlock, self).__init__() # 实例化自注意力模块 self.attention = SelfAttention(embed_size, heads) # 层归一化 self.norm = nn.LayerNorm(embed_size) # self.feed_forward = nn.Sequential( nn.Linear(embed_size, forward_expansion*embed_size), nn.ReLU(), nn.Linear(forward_expansion*embed_size, embed_size) ) self.dropout = nn.Dropout(dropout) # 前向传播, qkv.shape==[b,seq_len,embed_size] def forward(self, value, key, query, x, type_mode): if type_mode == 'original': attention = self.attention(value, key, query) x = self.dropout(self.norm(attention + x)) forward = self.feed_forward(x) out = self.dropout(self.norm(forward + x)) return out else: attention = self.attention(self.norm(value), self.norm(key), self.norm(query)) x =self.dropout(attention + x) forward = self.feed_forward(self.norm(x)) out = self.dropout(forward + x) return out
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
class TransformerEncoder(nn.Module): ''' embed_size: wordembedding之后, 每个单词用多少长度的向量来表示 num_layers: 堆叠多少层TransformerBlock heads: 多头注意力的heas个数 forward_expansion: 在FFN中第一个全连接上升特征数的倍数 ''' def __init__( self, embed_size, num_layers, heads, forward_expansion, dropout = 0, type_mode = 'original' ): super(TransformerEncoder, self).__init__() self.embed_size = embed_size self.type_mode = type_mode self.Query_Key_Value = nn.Linear(embed_size, embed_size * 3, bias = False) #将多个TransformerBlock保存在列表中 self.layers = nn.ModuleList( [ TransformerBlock( embed_size, heads, dropout=dropout, forward_expansion=forward_expansion, ) for _ in range(num_layers)] ) self.dropout = nn.Dropout(dropout) def forward(self, x): for layer in self.layers: print(self.Query_Key_Value(x).shape) QKV_list = self.Query_Key_Value(x).chunk(3, dim = -1) print(len(QKV_list)) print(QKV_list[0].shape) x = layer(QKV_list[0], QKV_list[1], QKV_list[2], x, self.type_mode) print(x.shape) return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
查看数据在网络中传输
net=TransformerEncoder(64,1,8,2)
print(net(torch.rand(64, 15, 64)).shape)# batch_size 为 64,有 15 个词,每个词的 Key 向量是 64 维
- 1
- 2
torch.Size([64, 15, 192])#192=64*3
3
torch.Size([64, 15, 64])
torch.Size([64, 15, 64])
torch.Size([64, 15, 64])
- 1
- 2
- 3
- 4
- 5
VisionTransformer
class VisionTransformer(nn.Module): def __init__(self, image_size, patch_size, num_classes, embed_size, num_layers, heads, mlp_dim, pool = 'cls', channels = 3, dropout = 0, emb_dropout = 0.1, type_mode = 'vit'): super(VisionTransformer, self).__init__() img_h, img_w = inputs_deal(image_size) # 图形形状 =》变成元组类型 patch_h, patch_w = inputs_deal(patch_size) assert img_h % patch_h == 0 and img_w % patch_w == 0, 'Img dimensions can be divisible by the patch dimensions' # 分块数量 num_patches = (img_h // patch_h) * (img_w // patch_w) # 每个图片块展平成一维向量 patch_size = channels * patch_h * patch_w #接着对每个向量都做一个线性变换(即全连接层) self.patch_embedding = nn.Sequential( # rearrange: 用于对张量的维度进行重新变换排序 Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_h, p2=patch_w), nn.Linear(patch_size, embed_size, bias=False) ) # pos_embedding位置编码 # nn.Parameter是继承自torch.Tensor的子类,其主要作用是作为nn.Module中的可训练参数使用。 # 假设num_patches=10,这里shape为(1, 11, 256) self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, embed_size)) # 假设dim=256,这里shape为(1, 1, 256) self.cls_token = nn.Parameter(torch.randn(1, 1, embed_size)) self.dropout = nn.Dropout(emb_dropout) self.transformer = TransformerEncoder(embed_size, num_layers, heads, mlp_dim, dropout) self.pool = pool self.to_latent = nn.Identity() self.mlp_head = nn.Sequential( nn.LayerNorm(embed_size), nn.Linear(embed_size, num_classes) ) def forward(self, img): #img.shape=torch.Size([3, 256, 256]) x = self.patch_embedding(img) # print(x.shape)#torch.Size([3, 256, 256]) b, n, _ = x.shape # print(b,n,_) #repeat: 用于对张量的某一个维度进行复制 # forward前向代码 # 假设batchsize=3,这里shape是从原先的(1,1,256)变为(3, 1, 256) cls_tokens = repeat(self.cls_token, '() n d ->b n d', b = b) # print(cls_tokens.shape) # 跟前面的分块为x(3,256,256)的进行concat # 得到(3, 257(256+1),256)向量 x = torch.cat((cls_tokens, x), dim = 1) print("1:",x.shape) # torch.Size([3, 257, 256]) x += self.pos_embedding[:, :(n + 1)] print("2:",x.shape) x = self.dropout(x) print("3:",x.shape) x = self.transformer(x) print("4:",x.shape) x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0] print("5:",x.shape) x = self.to_latent(x) print("6:",x.shape) return self.mlp_head(x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
if __name__ == '__main__':
vit = VisionTransformer(
image_size = 256,
patch_size = 16,
num_classes = 10,
embed_size = 256,
num_layers = 6,
heads = 8,
mlp_dim = 512,
dropout = 0.1,
emb_dropout = 0.1
)
img = torch.randn(3, 3, 256, 256)
pred = vit(img)
print(pred.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
1: torch.Size([3, 257, 256]) 2: torch.Size([3, 257, 256]) 3: torch.Size([3, 257, 256]) torch.Size([3, 257, 768]) 3 torch.Size([3, 257, 256]) torch.Size([3, 257, 256]) torch.Size([3, 257, 768]) 3 torch.Size([3, 257, 256]) torch.Size([3, 257, 256]) torch.Size([3, 257, 768]) 3 torch.Size([3, 257, 256]) torch.Size([3, 257, 256]) torch.Size([3, 257, 768]) 3 torch.Size([3, 257, 256]) torch.Size([3, 257, 256]) torch.Size([3, 257, 768]) 3 torch.Size([3, 257, 256]) torch.Size([3, 257, 256]) torch.Size([3, 257, 768]) 3 torch.Size([3, 257, 256]) torch.Size([3, 257, 256]) 4: torch.Size([3, 257, 256]) 5: torch.Size([3, 256]) 6: torch.Size([3, 256]) torch.Size([3, 10])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
完整代码
import torch import torch.nn as nn import os from einops import rearrange from einops import repeat from einops.layers.torch import Rearrange def inputs_deal(inputs): #isinstance() 函数来判断一个对象是否是一个已知的类型 #如果inputs是元组的话,那么就输出inputs,否则,输出(inputs, inputs) return inputs if isinstance(inputs, tuple) else(inputs, inputs) #多头注意力机制 class SelfAttention(nn.Module): #pytorch里面自定义层也是通过继承自nn.Module类来实现的 def __init__(self, embed_size, heads): # 继承一下 super(SelfAttention, self).__init__() self.embed_size = embed_size #embed_size: 每个单词用多少长度的向量来表示 self.heads = heads #自注意力机制的头数 self.head_dim = embed_size // heads #计算出每个头的维度 #判断是否整除 assert (self.head_dim * heads == embed_size), "Embed size needs to be div by heads" #三个全连接分别计算qkv,全连接层有定义W^q ,W^k ,W^v的意思 #nn.Linear(in_features,out_features,bias) #图像中的个人理解:改变输出通道数 #参数in_features:输入的[batch_size, size]中的size。 #参数out_features:二维张量的形状为[batch_size,output_size] self.values = nn.Linear(self.head_dim, self.head_dim, bias=False) self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False) self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False) # 输出层 self.fc_out = nn.Linear(heads * self.head_dim, embed_size) # 前向传播 qkv.shape==[b,seq_len,embed_size] def forward(self, values, keys, query): N =query.shape[0] value_len , key_len , query_len = values.shape[1], keys.shape[1], query.shape[1] # 维度调整 [b,seq_len,embed_size] ==> [b,seq_len,heads,head_dim] values = values.reshape(N, value_len, self.heads, self.head_dim) keys = keys.reshape(N, key_len, self.heads, self.head_dim) queries = query.reshape(N, query_len, self.heads, self.head_dim) # 对原始输入数据计算q、k、v values = self.values(values) keys = self.keys(keys) queries = self.queries(queries) # way1 # 爱因斯坦简记法矩阵元素,其中query_len == keys_len == value_len # attention.shape = [N, heads, query_len, keys_len] # values.shape = [N, value_len, heads, head_dim] # out.shape = [N, query_len, heads, head_dim] # way2 # queries shape: (N, query_len, heads, heads_dim) # keys shape : (N, key_len, heads, heads_dim) # energy shape: (N, heads, query_len, key_len) energy = torch.einsum("nqhd,nkhd->nhqk", queries, keys) #softmax attention = torch.softmax(energy/ (self.embed_size ** (1/2)), dim=3) # out = torch.einsum("nhql, nlhd->nqhd", [attention, values]).reshape(N, query_len, self.heads*self.head_dim) # attention shape: (N, heads, query_len, key_len) # values shape: (N, value_len, heads, heads_dim) # (N, query_len, heads, head_dim) out = self.fc_out(out) return out # Transformer模块 class TransformerBlock(nn.Module): ''' embed_size: wordembedding之后, 每个单词用多少长度的向量来表示 heads: 多头注意力的heas个数 drop: 杀死神经元的概率 forward_expansion: 在FFN中第一个全连接上升特征数的倍数 ''' def __init__(self, embed_size, heads, dropout, forward_expansion): super(TransformerBlock, self).__init__() # 实例化自注意力模块 self.attention = SelfAttention(embed_size, heads) # 层归一化 self.norm = nn.LayerNorm(embed_size) # self.feed_forward = nn.Sequential( nn.Linear(embed_size, forward_expansion*embed_size), nn.ReLU(), nn.Linear(forward_expansion*embed_size, embed_size) ) self.dropout = nn.Dropout(dropout) # 前向传播, qkv.shape==[b,seq_len,embed_size] def forward(self, value, key, query, x, type_mode): if type_mode == 'original': attention = self.attention(value, key, query) x = self.dropout(self.norm(attention + x)) forward = self.feed_forward(x) out = self.dropout(self.norm(forward + x)) return out else: attention = self.attention(self.norm(value), self.norm(key), self.norm(query)) x =self.dropout(attention + x) forward = self.feed_forward(self.norm(x)) out = self.dropout(forward + x) return out # Transformer编码器 class TransformerEncoder(nn.Module): ''' embed_size: wordembedding之后, 每个单词用多少长度的向量来表示 num_layers: 堆叠多少层TransformerBlock heads: 多头注意力的heas个数 forward_expansion: 在FFN中第一个全连接上升特征数的倍数 ''' def __init__( self, embed_size, num_layers, heads, forward_expansion, dropout = 0, type_mode = 'original' ): super(TransformerEncoder, self).__init__() self.embed_size = embed_size self.type_mode = type_mode self.Query_Key_Value = nn.Linear(embed_size, embed_size * 3, bias = False) #将多个TransformerBlock保存在列表中 self.layers = nn.ModuleList( [ TransformerBlock( embed_size, heads, dropout=dropout, forward_expansion=forward_expansion, ) for _ in range(num_layers)] ) self.dropout = nn.Dropout(dropout) def forward(self, x): for layer in self.layers: QKV_list = self.Query_Key_Value(x).chunk(3, dim = -1) x = layer(QKV_list[0], QKV_list[1], QKV_list[2], x, self.type_mode) return x class VisionTransformer(nn.Module): def __init__(self, image_size, patch_size, num_classes, embed_size, num_layers, heads, mlp_dim, pool = 'cls', channels = 3, dropout = 0, emb_dropout = 0.1, type_mode = 'vit'): super(VisionTransformer, self).__init__() img_h, img_w = inputs_deal(image_size)# 变成元组类型 patch_h, patch_w = inputs_deal(patch_size) assert img_h % patch_h == 0 and img_w % patch_w == 0, 'Img dimensions can be divisible by the patch dimensions' #原始输入的图片数据是 H x W x C,我们先对图片作分块,再进行展平。假设每个块的长宽为(patch_h,patch_w),那么分块的数目为 # 求解分块数量 num_patches = (img_h // patch_h) * (img_w // patch_w) # 每个图片块展平成一维向量,每个向量大小为patch_size patch_size = channels * patch_h * patch_w # Patch Embedding操作:对每个向量都做一个线性变换(即全连接层) self.patch_embedding = nn.Sequential( # rearrange: 用于对张量的维度进行重新变换排序 Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_h, p2=patch_w), nn.Linear(patch_size, embed_size, bias=False) ) # nn.Parameter是继承自torch.Tensor的子类,其主要作用是作为nn.Module中的可训练参数使用。 # pos_embedding用一个可训练的变量替代 self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, embed_size)) self.cls_token = nn.Parameter(torch.randn(1, 1, embed_size)) self.dropout = nn.Dropout(emb_dropout) self.transformer = TransformerEncoder(embed_size, num_layers, heads, mlp_dim, dropout) self.pool = pool self.to_latent = nn.Identity() self.mlp_head = nn.Sequential( nn.LayerNorm(embed_size), nn.Linear(embed_size, num_classes) ) def forward(self, img): x = self.patch_embedding(img) print(x) b, n, _ = x.shape print(b,n,_) #repeat: 用于对张量的某一个维度进行复制 cls_tokens = repeat(self.cls_token, '() n d ->b n d', b = b) x = torch.cat((cls_tokens, x), dim = 1) x += self.pos_embedding[:, :(n + 1)] x = self.dropout(x) x = self.transformer(x) x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0] x = self.to_latent(x) return self.mlp_head(x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
if __name__ == '__main__':
vit = VisionTransformer(
image_size = 256,
patch_size = 16,
num_classes = 10,
embed_size = 256,
num_layers = 6,
heads = 8,
mlp_dim = 512,
dropout = 0.1,
emb_dropout = 0.1
)
img = torch.randn(3, 3, 256, 256)
pred = vit(img)
print(pred)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15

