
热门标签
热门文章
- 1搜狐科技专访 | 澜舟科技CEO周明:不过度追求AGI,更看重大模型语言理解能力和应用落地性
- 2JavaScript基础09-day11【原型对象、toString()、垃圾回收、数组、数组字面量、数组方法】_js tostring 污染
- 3科普贴开篇:到底什么是人工智能(AI)、机器学习(ML)和深度学习(DL
- 4Flink: Could not find any factory for identifier kafka/jdbc/hive implements DynamicTableFactory 根治方法_org.apache.flink.table.api.validationexception: co
- 5现在转行学软件测试还有前景吗?最真实的数据告诉你答案_软件测试市场需求大不大
- 6电脑屏幕录制工具对比,这3款你都用过吗?
- 7【你也能从零基础学会网站开发】 SQL结构化查询语言应用基础---DDL、DML、DQL、DCL到底是什么_ddl dml
- 8java数组排序练习题_有一个整数数组,其中存放着序列1,3,25,7,9,11,69,15,4,19。请将该序列从小到大排
- 9GeoPandas安装保姆级教程
- 10python 用户输入命令,关于python:用户输入和命令行参数
当前位置: article > 正文
Python爬虫
作者:神奇cpp | 2024-08-09 19:54:46
赞
踩
python爬虫
一、爬虫概念
爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息。爬虫, 又称网页蜘蛛或网络机器人。爬虫是 模拟人操作客户端(浏览器, APP) ,向服务器发起网络请求,抓取数据的自动化程序或脚本。
二、爬虫的基本流程
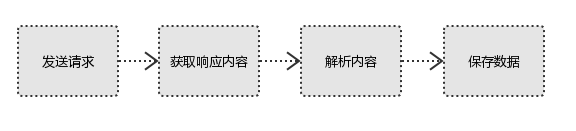
- 发起请求,通过使用HTTP库向目标站点发起请求,即发送一个Request,请求可以包含额外的headers等信息,并等待服务器响应。
- 获取响应内容如果服务器能正常响应,则会得到一个Response,Response的内容就是所要获取的页面内容,其中会包含:html,json,图片,视频等。
- 解析内容得到的内容可能是html数据,可以使用正则表达式、第三方解析库如Beautifulsoup,etree等,要解析json数据可以使用json模块,二进制数据,可以保存或者进一步的处理。
- 保存数据保存的方式比较多元,可以存入数据库(MySQL、Mongdb、Redis)也可以使用文件的方式进行保存。
三、正则表达式
正则表达式(regular expression),又称规则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一些过滤逻辑。在Python中正则表达式通过re模块来实现。
四、爬虫实例
1.爬取百度页面
import requests
# 1.确定url, 向服务器发送请求
url = - 1
- 2
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/神奇cpp/article/detail/954940
推荐阅读
相关标签

