
- 1基于LSTM-Adaboost的电力负荷预测—附数据集|长短期记忆神经网络_电力负荷预测 lstm 数据集
- 2Hex和ASCII相互转换函数_hex2ascii
- 3向上管理的1000+篇文章总结_mohlw
- 4codeforce 387 (abc)水题_#include
#include #include - 5大模型实操与API调用 | 三十二、LLama3.1 模型调用_llama模型调用
- 6java毕业设计之影城管理系统 (ssm项目源码+LW+PPT)_电影管理系统ssm
- 7【GLM-4微调实战】GLM-4-9B-Chat模型之Lora微调实战
- 8ssh: Could not resolve hostname_ssh: could not resolve hostname d: name or service
- 9Swoole + WebRTC:开启跨平台音视频实时通信新纪元_swoole webrtc
- 10屏幕监控软件的创新之处:利用TensorFlow实现屏幕内容识别功能_基于屏幕进行内容识别和记忆
DINO / DINOv2 论文+代码深度解析_dino dinov2
赞
踩
目录
DINO论文
链接:https://arxiv.org/pdf/2104.14294
Abstract
总结贡献点如下:
- 发现自监督的ViT可以呈现图像的语义分割信息,这一点在监督ViT和CNN中都没有被发现。(具体可以看下文中的图片示意,but我还不知道可视化的是哪一层)
- 上述的语义分割特征在图像类间有良好的区分度(体现在通过一个KNN就可以达到很高的分类准确率,所以用于算图像相似度、以图搜图的话可能是个好的choice)

DINO的名字来自于 self-distillation with no labels (所以我认为读音应该是 /di nəʊ/,如果有其他官方的发音欢迎评论区更正 OHO!)
Introduction
用自监督训练ViT的灵感来自于BERT和GPT,作者总结了两个属性(同上Abstract),为了下文方便提及,我总结为:
- 语义分割信息
- 特征的线性可分离性(KNN good performance)
其中语义分割信息似乎是自监督训练的共性,但是KNN上的表现还依赖于其他的trick比如momentum encoder / multi-crop augmentation / ViT中使用更小的patch。
由此,DINO设计了一个教师网络(使用了momentum encoder + 标准的交叉熵损失),对于教师网络的输出,只采用了centering 和 sharpening来防止collapse,而并没有使用一些predictor, advanced normalization 或者 contrastive loss 的组件(这些组件在不管是网络稳定性还是精度上都没什么效果)。
DINO可适用于ViT或者CNN,官方代码写入了 ViTs 和 ResNet-50,后续会提到。
训练速度:2个8-GPU服务器,3天,ImageNet数据集。
Related work
我一般不会特意去看related work,不过这篇paper非常明确提到了自己与相关工作的差异点:
- 损失函数:cross-entropy loss. (不是这个损失比较特殊,而是用于自监督这种相似性差异上,确实很少用这个函数。至于原因……我数学不好,倾向于是结果导向吧)
- 教师网络参数通过ema更新 (即学生网络在一段时间内的参数平均值)
- 教师网络并非预先训练好的,而是同步进行训练,这意味着distillation不是作为自监督预训练的后处理步骤,而是直接作为一个自监督的目标。
Approach
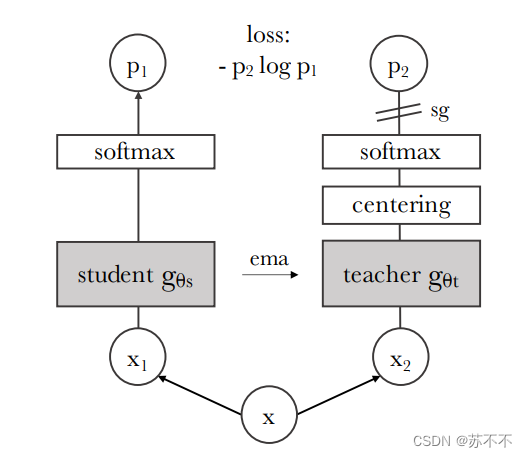

文中的示意图已经足够我们理解方法的框架,下面会解释一些细节和步骤:
- 对于一张输入的image,会有几个distorted views(我理解为一些图像形变操作?)和与之相对的crop图像,其中local图像输入学生网络(gs)而global图像输入教师网络(gt)。【 DINO的基础参数是:1. 2张global view,大小 224*224,覆盖原始图片 > 50%区域 ; 2. 若干张local view,大小 96*96,覆盖原始图片 < 50%区域 】
-
教师网络的更新: 即上文提过的momentum encoder(对于momentum encoder,在后文写了个补充介绍),更新公式是 θt ← λθt + (1 − λ)θs, 在每个iter,将教师网络的参数更新为当前时刻的教师网络和学生网络参数的加权和,这个加权系数由 λ 控制。λ 取值为 0.996 - 1之间,以余弦方式变化。(可以发现每次只是更新很小权重的学生网络影响)
-
示意图中深灰色的gs / gt由两部分组成,f & h。其中f为backbone,如ViT;h为projection head,如图
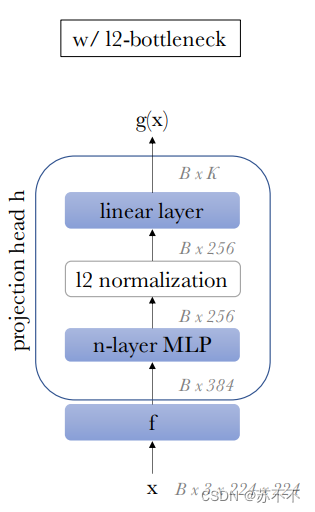 。需要注意的是,projection head存在的目的是为了辅助训练,下游任务的特征来自于 f 的输出!
。需要注意的是,projection head存在的目的是为了辅助训练,下游任务的特征来自于 f 的输出! -
DINO中的centering和sharpening:
-
centering避免一部分特征占据主导地位,具体是通过添加一个偏差项c到teacher模型中:gt(x) ← gt(x) + c,偏差项c是根据前段时刻的教师网络参数更新的,最终使不同batch激活值都在一个相近的范围内。
-
sharpening是在教师网络最后的softmax归一化中,通过一个小的温度系数τt,使最后的分布更加锐化
-
centering和sharpening其实可以看做是对抗学习,使参数不断抖动并收敛。
-
Appendix
不太能理解DINO的可视化方案,先记录在此,有空补上笔记
DINO V2论文
【学习ing ……

