
热门标签
热门文章
- 1JavaSE 数组的定义与使用_java s数组
- 2PostgreSQL分页count超级无敌巨慢_postgresql count
- 3【单片机毕业设计】【cl-025】儿童安全座椅 | 智能汽车儿童座椅_基于stm32的智能儿童汽车座椅控制系统设计
- 4C# WPF入门学习主线篇(十八)—— Border布局容器
- 5mysql 分页 pageindex_根据当前页号(pageIndex)和页大小(pageSize)获取分页数据
- 6Spark MLlib LinearRegression线性回归算法源码解析_spark mllib 线性 斜率
- 7传感器通过RS485转USB和电脑通信_485转usb驱动
- 8github/gitee码云文件上传提交记录教程_gitea官网 怎么查看提交记录
- 9No certificate for team matching 'iPhone Distribution
- 10MySQL开发技巧——并发控制_mysql开发技巧并发控制头歌
当前位置: article > 正文
Hadoop集群搭建_设置yarn核心参数,指定resourcemanager进程所在主机为master,端口为18141
作者:不正经 | 2024-06-15 05:32:46
赞
踩
设置yarn核心参数,指定resourcemanager进程所在主机为master,端口为18141;指定map
Hadoop集群搭建
- 8.设置HDFS参数,关闭hadoop集群权限校验(安全配置),允许其他用户连接集群
- 9.设置YARN运行环境$JAVA_HOME参数(yarn-env.sh,使用绝对路径)
- 10.设置YARN核心参数,指定mapreduce 获取数据的方式为mapreduce_shuffle (yarn-site.xml)
- 11.设置计算框架参数,指定MR运行在yarn上 (mapred-site.xml)
- 12.设置节点文件slaves,要求slave1、slave2为子节点
- 13.对文件系统进行格式化
- 14.启动Hadoop集群查看各节点服务
- 15.查看集群运行状态是否正常
- (补充)设置YARN核心参数,指定ResourceManager进程所在主机为master,端口为18141:
8.设置HDFS参数,关闭hadoop集群权限校验(安全配置),允许其他用户连接集群
在master、slave1、slave2上操作:
修改 hdfs-site.xml 文件以设置HDFS参数:
vim hdfs-site.xml
- 1
<property> <!--备份文本数量为2--> <name>dfs.replication</name> <value>2</value> </property> <property> <!--namenode节点数据存储目录--> <name>dfs.namenode.name.dir</name> <value>/root/hadoopData/name</value> </property> <!--datanode节点数据存储目录--> <property> <name>dfs.datanode.data.dir</name> <value>/root/hadoopData/data</value> </property> <!-- 设置HDFS的文件权限--> <property> <name>dfs.permissions</name> <value>false</value> </property> <property> <name>dfs.datanode.use.datanode.hostname</name> <value>true</value> </property>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
9.设置YARN运行环境$JAVA_HOME参数(yarn-env.sh,使用绝对路径)
在master、slave1、slave2上操作:
vim yarn-env.sh
- 1
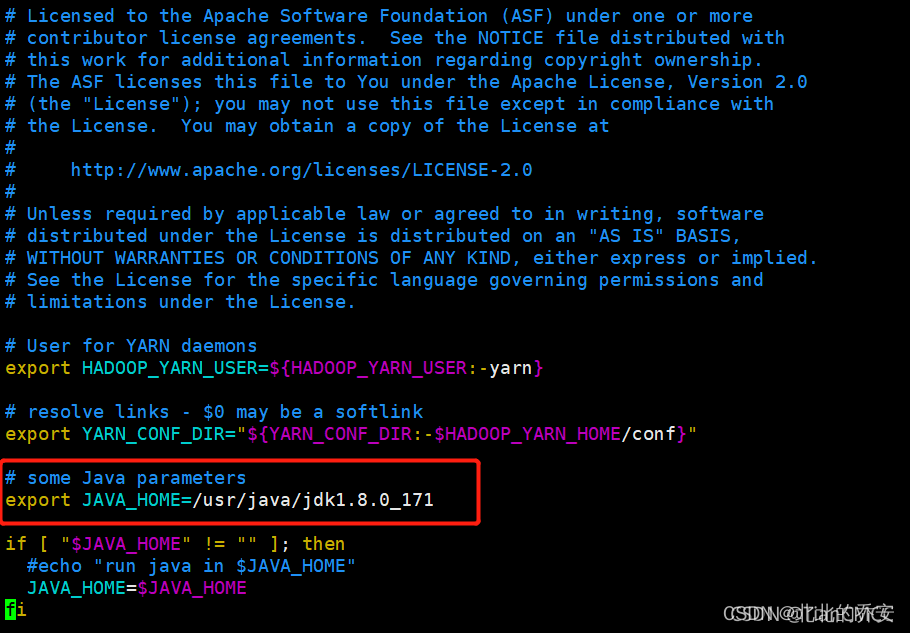
修改yarn-env.sh中的第23行为JAVA_HOME路径:
export JAVA_HOME=/usr/java/jdk1.8.0_171
- 1
10.设置YARN核心参数,指定mapreduce 获取数据的方式为mapreduce_shuffle (yarn-site.xml)
- 在master、slave1、slave2上操作:
Hadoop完全分布式集群[环境]
vim yarn-site.xml
- 1
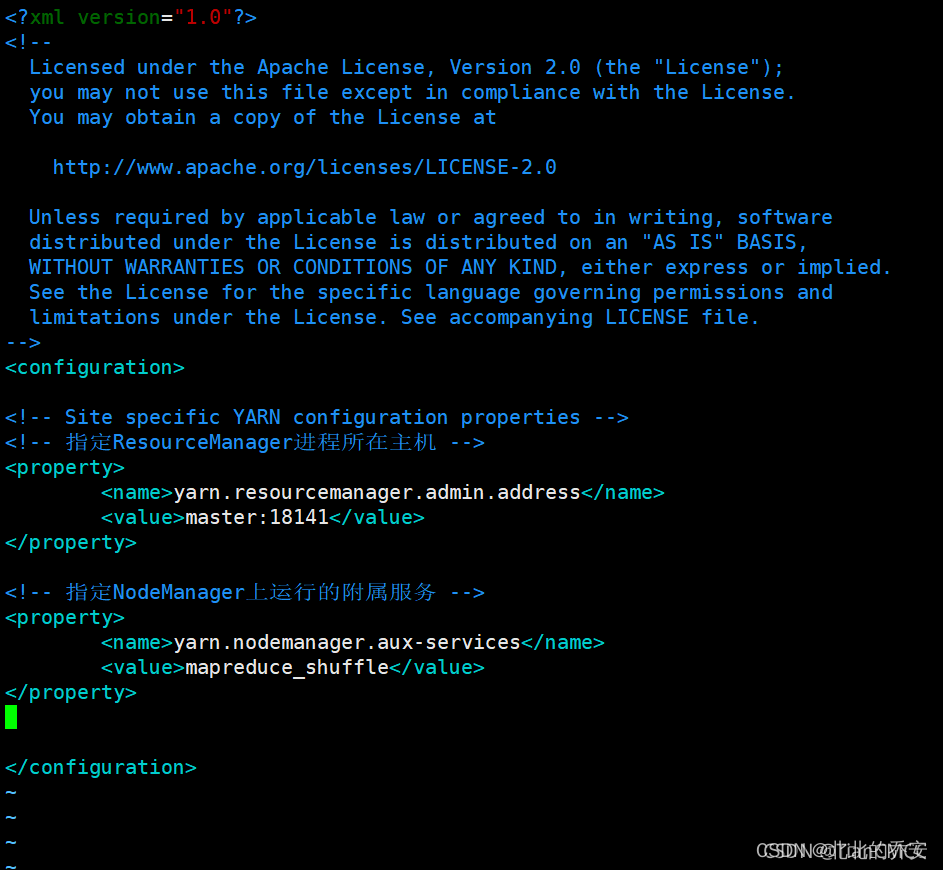
在< configuration></ configuration>中添加如下内容 :
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
- 1
- 2
- 3
- 4
11.设置计算框架参数,指定MR运行在yarn上 (mapred-site.xml)
在master、slave1、slave2上操作:
Hadoop集群中没有mapred-site.xml这个文件,因此需要把mapred-site.xml.template复制为mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
- 1
- 2
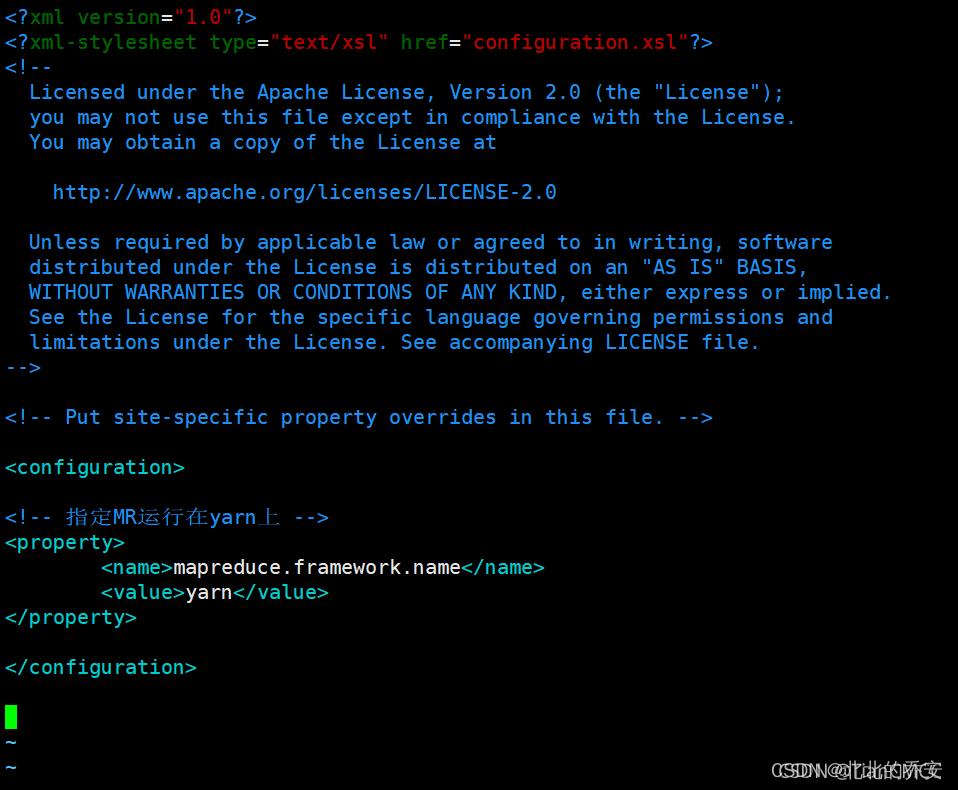
在< configuration></ configuration>中添加如下内容 :
<!-- 指定MR运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
- 1
- 2
- 3
- 4
- 5
12.设置节点文件slaves,要求slave1、slave2为子节点
在master、slave1、slave2上操作:
还是在 /usr/hadoop/hadoop-2.7.3/etc/hadoop 路径下,修改master、slaves文件:
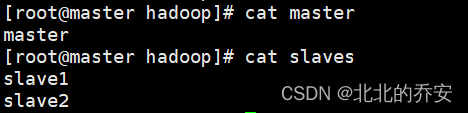
vim master
=== 写入 ===
master
- 1
- 2
- 3
vim slaves
=== 写入 ===
slave1
slave2
- 1
- 2
- 3
- 4
- 5
- 6
13.对文件系统进行格式化
在master上操作:
hadoop namenode -format
- 1

14.启动Hadoop集群查看各节点服务
在master上操作:
start-all.sh start
- 1
然后输入 yes 即可启动:
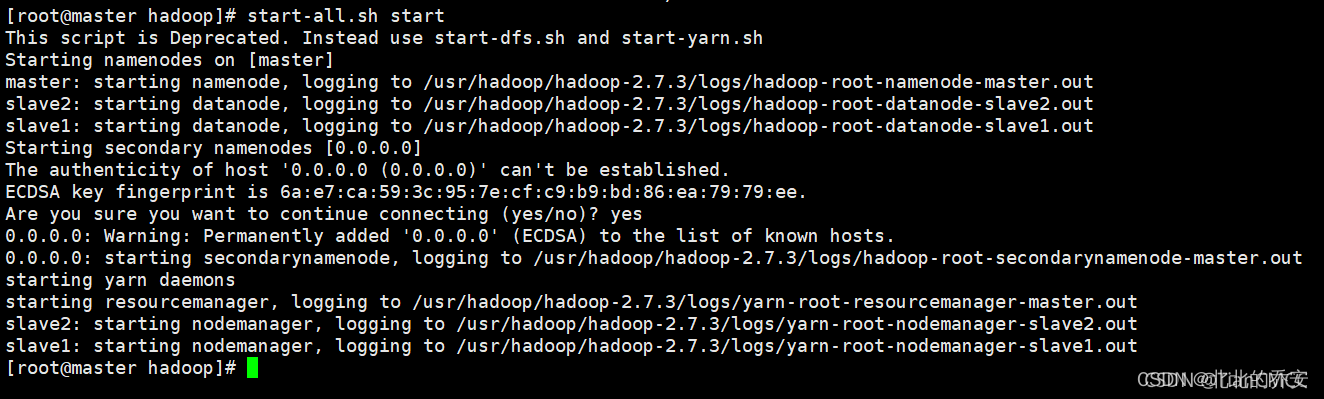
15.查看集群运行状态是否正常
hadoop dfsadmin -report
- 1
也可以查看java进程中的namenode和datanode是否启动jps
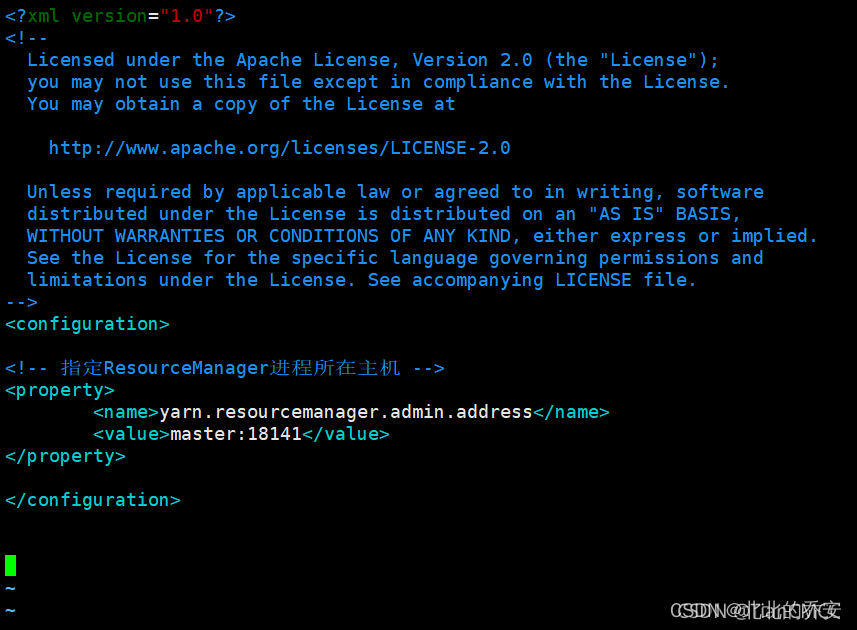
(补充)设置YARN核心参数,指定ResourceManager进程所在主机为master,端口为18141:
在master、slave1、slave2上操作:
vim yarn-site.xml
- 1
在< configuration></ configuration>中添加如下内容 :
<!-- 指定ResourceManager进程所在主机 -->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
- 1
- 2
- 3
- 4
- 5
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/不正经/article/detail/721090
推荐阅读
相关标签

