
- 1程序员如何成为自由职业者或者数字游民?_前端开发如何从事自由职业
- 2Spring Boot 集成 ZooKeeper,及其简单应用和分布式锁_springboot集成zookeeper
- 3MVM、MVP、MVVM架构联系与区别_;,_mvm:m.m.mn.
- 4bat脚本生成快捷方式并改变图标_批处理文件图标怎么改
- 5HCIA-HarmonyOS应用开发工程师 V2.0 模拟考试_以下哪一个文件可以用于查看hap包的配置信息、应用/服务在具体设备上的配置信息以
- 6华为云计算HCIA笔记——第一二章_hcia云服务 obs笔记
- 7opencv#41 轮廓检测
- 8转载windows的网络错误问题,备需要时查看
- 9SpringBoot实现自定义异常类。_springboot自定义异常
- 10ubuntu20.04中安装mysql8.0步骤_ubuntu20.04安装mysql8.0
大模型基础知识汇总_大模型 norm
赞
踩
本文总结大模型相关基础知识,用于大模型学习入门
- 注:本文不再维护更新,后续更新请查阅 git 仓库:https://github.com/kebijuelun/Awesome-LLM-Learning
文章目录
NLP 基础知识
Transformer 相关知识
Transformer 的 Self Attention Layer 实现
-
Transformer 模型的自注意力(Self Attention)机制涉及三种线性变换:查询(Q)、键(K)、值(V),以及通过计算注意力权重和加权求和来生成最终的输出。以下是自注意力机制的公式:
-
假设输入序列为 X ∈ R L × d X \in \mathbb{R}^{L \times d} X∈RL×d,其中 L L L 是序列长度, d d d 是特征维度。自注意力层中的线性变换矩阵为 W q ∈ R d × d k W_q \in \mathbb{R}^{d \times d_k} Wq∈Rd×dk、 W k ∈ R d × d k W_k \in \mathbb{R}^{d \times d_k} Wk∈Rd×dk 和 W v ∈ R d × d v W_v \in \mathbb{R}^{d \times d_v} Wv∈Rd×dv,其中 d k d_k dk 和 d v d_v dv 是分割查询、键和值时的维度。
-
查询(Q)、键(K)和值(V)的线性变换:
- Q = X ⋅ W q Q=X⋅W_{q} Q=X⋅Wq
- K = X ⋅ W k K=X⋅W_{k} K=X⋅Wk
- V = X ⋅ W v V=X⋅W_{v} V=X⋅Wv
-
多头拆分:
- 在多头自注意力中,将查询(Q)、键(K)和值(V)分成 h h h 个头,其中 h h h 是注意力头的数量。对于每个头,使用不同的线性变换权重。
-
注意力得分计算:
- 使用查询(Q)和键(K)计算注意力得分,可以使用点积注意力(Scaled Dot-Product Attention):
- A t t e n t i o n ( Q , K ) = s o f t m a x ( Q K T d k ) Attention(Q,K)=softmax(\frac{QK^{T}}{\sqrt{d_{k}}}) Attention(Q,K)=softmax(dk QKT)
- 使用查询(Q)和键(K)计算注意力得分,可以使用点积注意力(Scaled Dot-Product Attention):
-
注意力加权求和:
- 使用注意力权重对值(V)进行加权求和,得到自注意力的输出:
- O u t p u t = A t t e n t i o n ( Q , K ) V Output=Attention(Q,K)V Output=Attention(Q,K)V
- 使用注意力权重对值(V)进行加权求和,得到自注意力的输出:
-
上述公式涵盖了Transformer模型中自注意力层的基本计算步骤。在实际应用中,通常还会考虑添加缩放(scaling)、掩码(masking)等操作来优化注意力机制的计算过程。多头自注意力则在每个头上分别进行这些计算,然后将多个头的输出拼接或串联起来,进一步提取序列中的信息
-
-
一个多头 Self Attention 代码实现如下:
import torch
import torch.nn.functional as F
class SelfAttentionLayer(torch.nn.Module):
def __init__(self, d_model, num_heads):
super(SelfAttentionLayer, self).__init__()
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
# 线性变换矩阵
self.W_q = torch.nn.Linear(d_model, d_model, bias=False)
self.W_k = torch.nn.Linear(d_model, d_model, bias=False)
self.W_v = torch.nn.Linear(d_model, d_model, bias=False)
def split_heads(self, x, batch_size):
x = x.view(batch_size, -1, self.num_heads, self.d_k)
return x.permute(0, 2, 1, 3)
def forward(self, x):
batch_size, seq_len, d_model = x.size()
q = self.W_q(x)
k = self.W_k(x)
v = self.W_v(x)
q = self.split_heads(q, batch_size)
k = self.split_heads(k, batch_size)
v = self.split_heads(v, batch_size)
# Scaled Dot-Product Attention
attn_scores = torch.matmul(q, k.transpose(-2, -1)) / (self.d_k ** 0.5)
attn_weights = F.softmax(attn_scores, dim=-1)
# Attention加权求和
output = torch.matmul(attn_weights, v)
output = output.permute(0, 2, 1, 3).contiguous().view(batch_size, seq_len, -1)
return output
# 测试自注意力层
d_model = 512
num_heads = 8
seq_len = 10
batch_size = 16
input_data = torch.randn(batch_size, seq_len, d_model)
self_attention = SelfAttentionLayer(d_model, num_heads)
output = self_attention(input_data)
print(output.size()) # 输出: torch.Size([16, 10, 512])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
Transformer 中 Self Attention 计算为什么要除以特征维度数量的平方根
-
上面 Transformer 代码中有使用 d k \sqrt{d_{k}} dk 来对 softmax 之后的结果进行 scale,解释如下:
We suspect that for large values of d k d_{k} dk, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients. To counteract this effect, we scale the dot products by 1 d k \frac{1}{d_{k}} dk1. To illustrate why the dot products get large, assume that the components of q and k are independent random variables with mean 0 and variance 1. Then their dot product q ⋅ k = ∑ i = 1 d k ( q i k i ) q ⋅ k=\sum_{i=1}^{d_{k}}(q_{i}k_{i}) q⋅k=∑i=1dk(qiki), has mean 0 and variance d k d_{k} dk.
- 首先要除以一个数,防止输入 softmax 的值过大,导致偏导数趋近于 0;
- 选择根号 d_k 是因为可以使得 q*k 的结果满足期望为 0,方差为 1 的分布,类似于归一化。
为什么要引入位置编码 (Position Embedding)
-
对于任何一门语言,单词在句子中的位置以及排列顺序是非常重要的,它们不仅是一个句子的语法结构的组成部分,更是表达语义的重要概念。一个单词在句子的位置或排列顺序不同,可能整个句子的意思就发生了偏差。
I do not like the story of the movie, but I do like the cast.
I do like the story of the movie, but I do not like the cast.
上面两句话所使用的的单词完全一样,但是所表达的句意却截然相反。那么,引入词序信息有助于区别这两句话的意思。 -
Transformer 模型抛弃了 RNN、CNN 作为序列学习的基本模型。我们知道,循环神经网络本身就是一种顺序结构,天生就包含了词在序列中的位置信息。当抛弃循环神经网络结构,完全采用 Attention 取而代之,这些词序信息就会丢失,模型就没有办法知道每个词在句子中的相对和绝对的位置信息。因此,有必要把词序信号加到词向量上帮助模型学习这些信息,位置编码(Positional Encoding)就是用来解决这种问题的方法。
RoPE 位置编码
- RoPE
- 二维情况下用复数表示的 RoPE
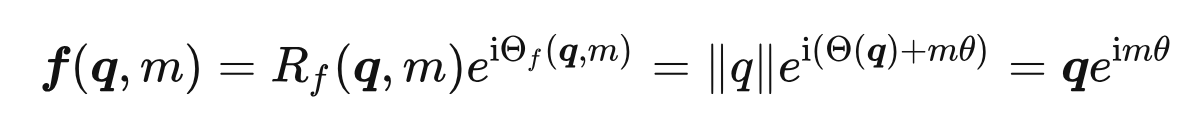
根据复数乘法的几何意义,该变换实际上对应着向量的旋转,所以我们称之为“旋转式位置编码” - RoPE通过绝对位置编码的方式实现相对位置编码,综合了绝对位置编码和相对位置编码的优点
- 绝对位置编码:最原始的正余弦位置编码(即sinusoidal位置编码)是一种绝对位置编码,但从其原理中的正余弦的和差化积公式来看,引入的其实也是相对位置编码。
- 优势: 实现简单,可预先计算好,不用参与训练,速度快
- 劣势: 没有外推性,即如果预训练最大长度为512的话,那么最多就只能处理长度为512的句子,再长就处理不了了。当然,也可以将超过512的位置向量随机初始化,然后继续微调
- 相对位置编码:经典相对位置编码RPR式
- 直接地体现了相对位置信号,效果更好。具有外推性,处理长文本能力更强
- 绝对位置编码:最原始的正余弦位置编码(即sinusoidal位置编码)是一种绝对位置编码,但从其原理中的正余弦的和差化积公式来看,引入的其实也是相对位置编码。
- 主要就是对attention中的q, k向量注入了绝对位置信息,然后用更新的q,k向量做attention中的内积就会引入相对位置信息了
- 二维情况下用复数表示的 RoPE
Alibi 位置编码
- ALiBi (Attention with Linear Biases,22年ICLR),是一种 position embedding 方法,允许 Transformer 语言模型在推理时处理比其训练时更长的序列。
- ALiBi 在不使用实际位置嵌入的情况下实现这一目标。相反,ALiBi计算某个键和查询之间的注意力时,会根据键和查询的距离来对查询可以分配给键的注意力值进行惩罚。因此,当键和查询靠近时,惩罚非常低,而当它们相距较远时,惩罚非常高。这个方法的动机很简单,即靠近的单词比远离的单词更重要。
- 不添加position embedding,然后添加一个静态的不学习的 bias
s o f t m a x ( q i K T + m ⋅ [ − ( i − 1 , . . . , − 2 , − 1 , 0 ) ] ) softmax(q_{i}K^{T} + m \cdot [-(i-1,...,-2,-1,0)]) softmax(qiKT+m⋅[−(i−1,...,−2,−1,0)])
- 不添加position embedding,然后添加一个静态的不学习的 bias
- ALiBi方法的速度与正弦函数嵌入或绝对嵌入方法相当(这是最快的位置编码方法之一)。在评估超出模型训练序列长度的序列时,ALiBi优于这些方法和Rotary嵌入(这称为外推)方法(ALiBi的方式,训练快了11%,并且会减少11%的内存消耗)。
- position embedding 并没有加在 work embedding 上,而是加在了 Q*K^T 上面
- ALiBi 在不使用实际位置嵌入的情况下实现这一目标。相反,ALiBi计算某个键和查询之间的注意力时,会根据键和查询的距离来对查询可以分配给键的注意力值进行惩罚。因此,当键和查询靠近时,惩罚非常低,而当它们相距较远时,惩罚非常高。这个方法的动机很简单,即靠近的单词比远离的单词更重要。
PI 位置插值支持长度外推
- PI位置插值
- 论文名称:EXTENDING CONTEXT WINDOW OF LARGE LANGUAGE MODELS VIA POSITION INTERPOLATION
- 论文链接:https://arxiv.org/pdf/2306.1559
- 方法:位置插值线性向下缩放了输入位置索引以匹配原始的上下文窗口大小,而不是外推超过训练时所用的上下文长度,因为这可能会导致灾难性的较高的注意力分数,从而完全破坏了自注意力机制。

- 左半部分为预训练阶段的位置向量范围[0,2048]
- 右上角为长度外推的部分(2048,4096]
- 左下角为位置插值法,将[0,4096]的值降采样到[0,2048]预训练阶段支持的范围
- 论文的实现很简单,只需要将对应位置缩放到原先支持的区间([0,2048])内:计算公式如下,
L
L
L 为原先支持的长度(如2048),
L
′
L^{'}
L′ 为需要扩展的长度(如4096):
f ′ ( x , m ) = f ( x , m L L ′ ) f^{'}(x, m)=f(x, \frac{mL}{L^{'}}) f′(x,m)=f(x,L′mL)
NTK-Aware Scaled RoPE 支持长度外推
- 在这项工作中,作者针对当前RoPE插值方法的不足,提出了一种改进方案。通过应用神经切线核(NTK)理论,作者发现现有的线性插值方法在处理距离接近的 token 时存在局限性。因此,作者设计了一种非线性插值方案,以改变 RoPE 的基数。这种方法在保持位置信息完整的同时,有效地提高了上下文大小。实验证明,该方法在没有进行模型微调的情况下就能显著减小困惑度,成为一种非常有效的优化策略。作者相信,通过进一步的微调,这个方法的效果将得到更好的提升。
Pre Norm与Post Norm的区别?
- 定义:
- Pre Norm(Norm and add): x t + 1 = x t + F t ( N o r m ( x t ) ) x_{t+1} = x_{t} + F_{t}(Norm(x_{t})) xt+1=xt+Ft(Norm(xt))
- Post Norm(Add and Norm): x t + 1 = N o r m ( x t + F t ( x t ) x_{t+1} = Norm(x_{t} + F_{t}(x_{t}) xt+1=Norm(xt+Ft(xt)
- 在同一训练设置下,同一设置之下,Pre Norm结构往往更容易训练,但最终效果通常不如Post Norm:
- Pre Norm更容易训练好理解,因为它的恒等路径更突出
- Pre Norm的深度有“水分”!也就是说,一个L层的Pre Norm模型,其实际等效层数不如L层的Post Norm模型,而层数少了导致效果变差了。Post Norm每Norm一次就削弱一次恒等分支的权重,所以Post Norm反而是更突出残差分支的,因此Post Norm中的层数更加“足秤”,一旦训练好之后效果更优。
- Post Norm的结构迁移性能更加好,也就是说在Pretraining中,Pre Norm和Post Norm都能做到大致相同的结果,但是Post Norm的Finetune效果明显更好
Bert 预训练过程
- Bert的预训练主要包含两个任务,MLM和NSP,Masked Language Model任务可以理解为完形填空,随机mask每一个句子中15%的词,用其上下文来做预测;Next Sentence Prediction任务选择一些句子对A与B,其中50%的数据B是A的下一条句子,剩余50%的数据B是语料库中随机选择的,学习其中的相关性。BERT 预训练阶段实际上是将上述两个任务结合起来,同时进行,然后将所有的 Loss 相加
深度学习基础
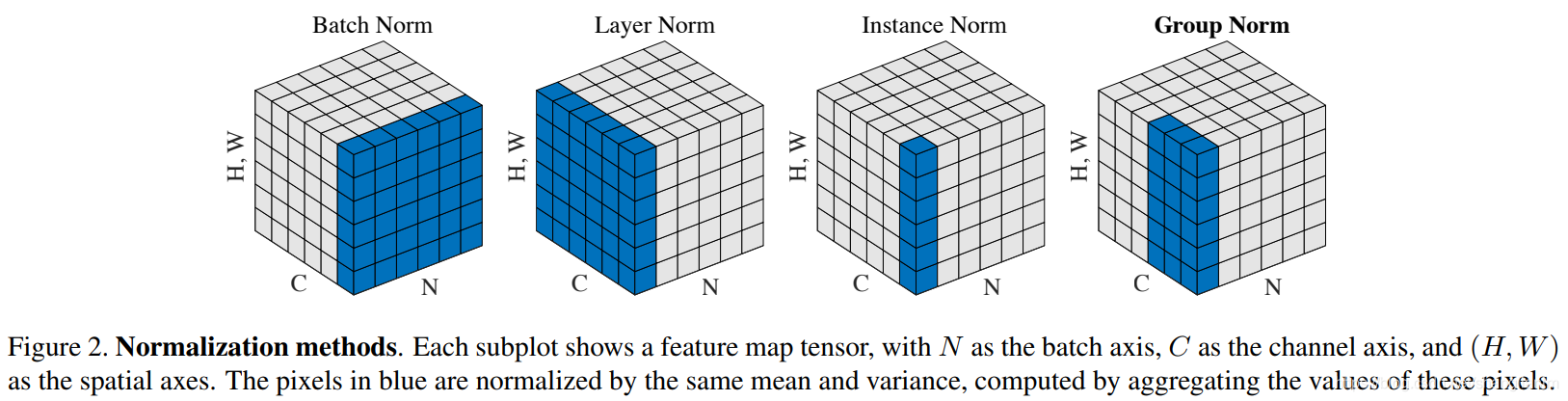
BN 和 LN 的区别
- BN 与 LN 定义:Batch Normalization 是对这批样本的同一维度特征做规范化处理, Layer Normalization 是对这单个样本的所有维度特征做规范化处理
- 区别:
- LN中同层神经元输入拥有相同的均值和方差,不同的输入样本有不同的均值和方差;BN中则针对不同神经元输入计算均值和方差,同一个batch中的输入拥有相同的均值和方差
- 为什么 NLP 使用 LN 而不是 BN?
- LN 不依赖于 batch 的大小和输入 sequence 的长度,因此可以用于 batchsize 为 1 和 RNN 中 sequence 的 normalize 操作
- BN 不适用于 batch 中 sequence 长度不一样的情况,有的靠后面的特征的均值和方差不能估算;另外 BN 在 MLP 中的应用对每个特征在 batch 维度求均值方差,比如身高、体重等特征,但是在 NLP 中对应的是每一个单词,但是每个单词表达的特征是不一样的
- 如果特征依赖于不同样本间的统计参数(比如 CV 领域),那么 BN 更有效(它抹杀了不同特征之间的大小关系,但是保留了不同样本间的大小关系);NLP 领域 LN 更合适(抹杀了不同样本间的大小关系,但是保留了一个样本内不同特征之间的大小关系),因为对于 NLP 或序列任务来说,一条样本的不同特征其实就是时序上字符取值的变化,样本内的特征关系是非常紧密的
- 相同点:标准化技术目的是让每一层的分布稳定下来,让后面的层可以在前面层的基础上安心学习,加快模型收敛
- 区别:
大模型基础知识
训练框架
- megatron-lm、deepspeed 介绍
开源大语言模型介绍
Llama
- causal LM: 严格遵守只有后面的token才能看到前面的token的规则
- 使用 RoPE 位置编码
ChatGLM and ChatGLM2
- ChatGLM
- 使用 prefix LM:prefix部分的token互相能看到
- 使用 RoPE 位置编码
- ChatGLM2
- 回归 decoder-only 结构,使用 Causal LM
- 使用 RoPE 位置编码
Bloom
- BLOOM 使用 Alibi 位置编码
Tokenizer
分词(Tokenize) 介绍
-
语言模型是对文本进行推理。由于文本是字符串,但对模型来说,输入只能是数字,所以就需要将文本转成用数字来表达。最直接的想法,就是类似查字典,构造一个字典,包含文本中所有出现的词汇,比如中文,可以每个字作为词典的一个元素,构成一个列表;一个句子就可以转换成由每个词的编号(词在词典中的序号)组成的数字表达。分词就是将连续的字序列按照一定的规范重新组合成语义独立词序列的过程,一个分词示例流程如下:
- Hello Geeks how are you 的一句话分开为每个单词为一个 token: [Hello, Geeks, how, are, you]
- 执行分词的算法模型称为分词器(Tokenizer) ,划分好的一个个词称为 Token,这个过程称为 Tokenization
- 由于一篇文本的词往往太多了,为了方便算法模型训练,我们会选取出频率 (也可能是其它的权重)最高的若干个词组成一个词表(Vocabulary)
-
古典分词方法
- 具体分词方式示例
- 直接把词与词直接加一个空格
- 按标点符号分词
- 语法规则分词
- 缺点
- 对于未在词表中出现的词(Out Of Vocabulary, OOV ),模型将无法处理(未知符号标记为 [UNK])。
- 词表中的低频词/稀疏词在模型训无法得到训练(因为词表大小有限,太大的话会影响效率)
- 很多语言难以用空格进行分词,例如英语单词的多形态,“look"衍生出的"looks”, “looking”, “looked”,其实都是一个意思,但是在词表中却被当作不同的词处理,模型也无法通过 old, older, oldest 之间的关系学到 smart, smarter, smartest 之间的关系。这一方面增加了训练冗余,另一方面也造成了大词汇量问题。
- 具体分词方式示例
-
拆分为单个字符(Character embedding)
- 是一种更为极端的分词方法,直接把一个词分成一个一个的字母和特殊符号。虽然能解决 OOV 问题,也避免了大词汇量问题,但缺点也太明显了,粒度太细,训练花费的成本太高
-
基于子词的分词方法(Subword Tokenization)
- 把一个词切成更小的一块一块的子词,基于子词的分词方法是目前主流的分词方案,有点类似英语中的词根词缀拼词法,其中的这些小片段又可以用来构造其他词。可见这样做,既可以降低词表的大小,同时对相近词也能更好地处理
- 例如:“unfortunately ” = “un ” + “for ” + “tun ” + “ate ” + “ly ”
- 三种主流的 Subword 算法,它们分别是:Byte Pair Encoding (BPE)、WordPiece 和 Unigram Language Model
- 把一个词切成更小的一块一块的子词,基于子词的分词方法是目前主流的分词方案,有点类似英语中的词根词缀拼词法,其中的这些小片段又可以用来构造其他词。可见这样做,既可以降低词表的大小,同时对相近词也能更好地处理
字节对编码 Byte Pair Encoding (BPE)、WordPiece、Unigram Language Model 介绍
-
字节对编码(BPE, Byte Pair Encoder),又称 digram coding 双字母组合编码,是一种数据压缩 算法,用来在固定大小的词表中实现可变⻓度的子词。该算法简单有效,因而目前它是最流行的方法。
- BPE 首先将词分成单个字符,然后依次用另一个字符替换频率最高的一对字符 ,直到循环次数结束。
- 算法过程
- 准备语料库,确定期望的 subword 词表大小等参数
- 通常在每个单词末尾添加后缀 ,统计每个单词出现的频率,例如,low 的频率为 5,那么我们将其改写为 "l o w </ w>”:5
注:停止符 的意义在于标明 subword 是词后缀。举例来说:st 不加 可以出现在词首,如 st ar;加了 表明该子词位于词尾,如 we st,二者意义截然不同 - 将语料库中所有单词拆分为单个字符,用所有单个字符建立最初的词典,并统计每个字符的频率,本阶段的 subword 的粒度是字符
- 挑出频次最高的符号对 ,比如说 t 和 h 组成的 th,将新字符加入词表,然后将语料中所有该字符对融合(merge),即所有 t 和 h 都变为 th。
注:新字符依然可以参与后续的 merge,有点类似哈夫曼树,BPE 实际上就是一种贪心算法 。 - 重复遍历 2 和 3 操作,直到词表中单词数达到设定量 或下一个最高频数为 1 ,如果已经打到设定量,其余的词汇直接丢弃
- BPE 一般适用在欧美语言拉丁语系中,因为欧美语言大多是字符形式,涉及前缀、后缀的单词比较多。而中文的汉字一般不用 BPE 进行编码,因为中文是字无法进行拆分。对中文的处理通常只有分词和分字两种。理论上分词效果更好,更好的区别语义。分字效率高、简洁,因为常用的字不过 3000 字,词表更加简短。
-
WordPiece:WordPiece算法和BPE类似,区别在于WordPiece是基于概率生成新的subword而不是下一最高频字节对。- Unigram:它和 BPE 等一个不同就是,bpe是初始化一个小词表,然后一个个增加到限定的词汇量,而 Unigram 是先初始一个大词表,接着通过语言模型评估不断减少词表,直到限定词汇量。
ChatGPT 的 tokenizer 用于中文分词的问题
-
在 Openai Tokenizer demo 中,中文分词后的 token 数量远大于原始中文字符数目
-
原因剖析:OpenAI 为了支持多种语言的 Tokenizer,采用了文本的一种通用表示:UTF-8 的编码方式,这是一种针对 Unicode 的可变长度字符编码方式,它将一个 Unicode 字符编码为1到4个字节的序列。
为什么 llama 的 tokenizer 需要单独针对中文语料进行词表扩充
- 百川2的技术报告中提到过 tokenizer 的设计需要考虑两个重要因素:
- 高压缩率:以实现高效的推理
- 适当大小的词汇表:以确保每个词嵌入的充分训练
- 因为原生LLaMA对中文的支持很弱,tokenizer 中的中文字符和词汇较少,导致一个中文汉字往往被切分为多个 token,不满足上面所提到的高压缩率原则,所以需要进行词表扩充
position embedding
为什么要引入 position embedding
-
对于任何一门语言,单词在句子中的位置以及排列顺序是非常重要的,它们不仅是一个句子的语法结构的组成部分,更是表达语义的重要概念。一个单词在句子的位置或排列顺序不同,可能整个句子的意思就发生了偏差。
I do not like the story of the movie, but I do like the cast.
I do like the story of the movie, but I do not like the cast.
上面两句话所使用的的单词完全一样,但是所表达的句意却截然相反。那么,引入词序信息有助于区别这两句话的意思。 -
Transformer模型抛弃了RNN、CNN作为序列学习的基本模型。我们知道,循环神经网络本身就是一种顺序结构,天生就包含了词在序列中的位置信息。当抛弃循环神经网络结构,完全采用Attention取而代之,这些词序信息就会丢失,模型就没有办法知道每个词在句子中的相对和绝对的位置信息。因此,有必要把词序信号加到词向量上帮助模型学习这些信息,位置编码(Positional Encoding)就是用来解决这种问题的方法。
RoPE
- RoPE
- 二维情况下用复数表示的RoPE
根据复数乘法的几何意义,该变换实际上对应着向量的旋转,所以我们称之为“旋转式位置编码” - RoPE通过绝对位置编码的方式实现相对位置编码,综合了绝对位置编码和相对位置编码的优点
- 绝对位置编码:最原始的正余弦位置编码(即sinusoidal位置编码)是一种绝对位置编码,但从其原理中的正余弦的和差化积公式来看,引入的其实也是相对位置编码。
- 优势: 实现简单,可预先计算好,不用参与训练,速度快
- 劣势: 没有外推性,即如果预训练最大长度为512的话,那么最多就只能处理长度为512的句子,再长就处理不了了。当然,也可以将超过512的位置向量随机初始化,然后继续微调
- 相对位置编码:经典相对位置编码RPR式
- 直接地体现了相对位置信号,效果更好。具有外推性,处理长文本能力更强
- 绝对位置编码:最原始的正余弦位置编码(即sinusoidal位置编码)是一种绝对位置编码,但从其原理中的正余弦的和差化积公式来看,引入的其实也是相对位置编码。
- 主要就是对attention中的q, k向量注入了绝对位置信息,然后用更新的q,k向量做attention中的内积就会引入相对位置信息了
- 二维情况下用复数表示的RoPE
Alibi
- ALiBi (Attention with Linear Biases,22年ICLR),是一种 position embedding 方法,允许Transformer 语言模型在推理时处理比其训练时更长的序列。
- ALiBi在不使用实际位置嵌入的情况下实现这一目标。相反,ALiBi计算某个键和查询之间的注意力时,会根据键和查询的距离来对查询可以分配给键的注意力值进行惩罚。因此,当键和查询靠近时,惩罚非常低,而当它们相距较远时,惩罚非常高。这个方法的动机很简单,即靠近的单词比远离的单词更重要。
- ALiBi方法的速度与正弦函数嵌入或绝对嵌入方法相当(这是最快的定位方法之一)。在评估超出模型训练序列长度的序列时,ALiBi优于这些方法和Rotary嵌入(这称为外推)方法(ALiBi的方式,训练快了11%,并且会减少11%的内存消耗)。
- position embedding并没有加在work embedding上,而是加在了Q*K^T上面
PEFT
Pattern-Exploiting Training(PET)
- 它通过人工构建的模版与 BERT 的 MLM 模型结合,能够起到非常好的零样本、小样本乃至半监督学习效果,而且该思路比较优雅漂亮,因为它将预训练任务和下游任务统一起来了
P-tuning and P-tuningv2
- P-tuning(GPT Understands, Too)(参考)
- P-tuning 重新审视了关于模版的定义,放弃了“模版由自然语言构成”这一常规要求,从而将模版的构建转化为连续参数优化问题,虽然简单,但却有效
- P-tuning直接使用[unused*]的token来构建模版,不关心模版的自然语言性
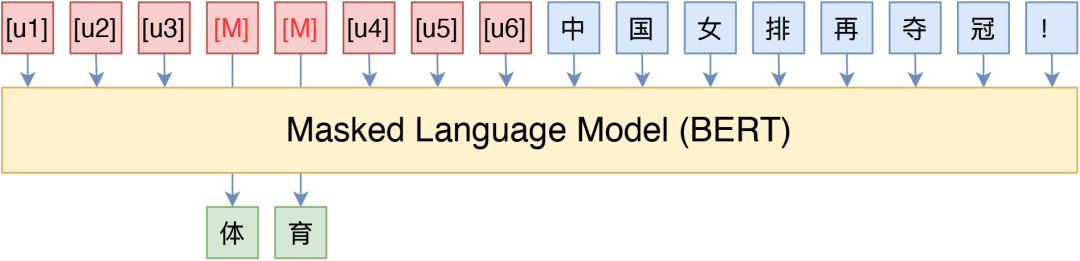
- 借助 P-tuning,GPT 在 SuperGLUE 上的成绩首次超过了同等级别的 BERT 模型,这颠覆了一直以来“GPT 不擅长 NLU”的结论
LoRA
- 低秩自适应 (Low-Rank Adaptation, LoRA):冻结了预训练的模型权重,并将可训练的秩分解矩阵注入到 Transformer 架构的每一层,极大地减少了下游任务的可训练参数的数量,有效提升预训练模型在下游任务上的 finetune 效率
- 【背景】之前的 PEFT 方法是 adapter/prefix/promp/P-tuning,但是Adapter会引入很强的推理延迟(只能串行),prefix/prompt/P-tuning很难练,而且要占用context length,变相的降低模型能力
- 【详解】具体来说,就是考虑到语言模型(LLM 尤其如此)的参数的低秩属性(low intrinsic dimension),或者说过参数化,在做 finetune 的时候不做 full-finetune,而是用一个降维矩阵A和一个升维矩阵B去做finetune。如果我们认为原来的模型的某个参数矩阵为
W
0
W_{0}
W0,那么可以认为原来经过全微调的参数矩阵为
W
0
+
Δ
(
W
)
W_{0} + \Delta(W)
W0+Δ(W) ,但考虑到前面的低秩属性,在 lora 中我们可以简单认为
Δ
(
W
)
=
B
A
\Delta(W)=BA
Δ(W)=BA (B 是降维矩阵,A是升维矩阵,其中 A 正常随机数初始化,B 全 0 初始化,从而保证训练初期的稳定性),其中 BA 的秩相当于是你认为的模型实际的秩。这样的话在做推理的时候,
h
=
W
0
x
+
B
A
x
h=W_{0}x + BAx
h=W0x+BAx ,根本不会引入推理延迟,因为你只需要把训好的 lora 参数
A
B
AB
AB 加进模型初始权重
W
0
W_{0}
W0 中就可以了。在 Transformer 中 self-attention 和 mlp 模块都有对应的 params 矩阵,对应加上 lora 即可。
- llama 为了节省参数量一般只加在 q、v 上 (参考),原论文实验是不会掉点
- bloom 一般加在 q、k、v 上
大语言模型推理
温度系数(Temperature)对大模型推理结果的影响
参考:What is Temperature in NLP / LLMs?
Huggingface generate 函数中的 top_p sampling、top_k sampling、greedy_search、beam_search 参数解释
参考:Huggingface 的 generate 方法介绍:top_p sampling、top_k sampling、greedy_search、beam_search
- Greedy search 每次都选择概率最大的词作为单词序列中的下一个词
- beam search(束搜索):通过在每个时间步骤保留最有可能的 num_beams 个假设,最终选择具有最高概率的假设,从而降低错过隐藏的高概率词序列的风险
- top-k sampling:在Top-K采样中,选择最有可能的 K 个下一个词,并将概率质量重新分配给这 K 个下一个词
- Top-p (nucleus) sampling:与仅从最可能的 K 个单词中进行采样不同,Top-p 采样从概率累积超过概率 p 的可能性最小的单词集中进行选择
大语言模型应用
LangChain 介绍
- LangChain 通过可组合性使用大型语言模型构建应用程序
- 【背景】大型语言模型 (LLM) 正在成为一种变革性技术,使开发人员能够构建他们以前无法构建的应用程序,但是单独使用这些 LLM 往往不足以创建一个真正强大的应用程序,当可以将它们与其他计算或知识来源相结合时,就有真的价值了。LangChain 旨在协助开发这些类型的应用程序
- LangChain 主要功能:
- 实现统一接口,支持不同大语言模型的统一化调用
- 支持引入 google 搜索、python 解释器等外部工具
- 支持便捷 prompt 模板设置(并提供一些教科书 prompt 模板供参考)
- 支持智能体 (Agent) 等高阶应用
推荐精读的博客/演讲
- State of GPT (OpenAI Karpathy 介绍 ChatGPT 原理及现状)
- Andrej Karpathy 介绍如何训练 ChatGPT 以及如何将 ChatGPT 用于定制化应用程序
- A Stage Review of Instruction Tuning
- 符尧讲解 SFT 现状及可以关注的问题
- C-Eval: 构造中文大模型的知识评估基准
- 介绍构造 C-Eval 的过程,同时介绍了提升模型排名的方法
大语言模型前沿研究
大模型涌现分析
- 大模型涌现能力探讨:大型语言模型的涌现能力是幻象吗?
- 探索大语言模型表现出涌现能力的原因,初步结论是涌现能力主要是由研究人员选择一个非线性或不连续的评价指标导致的,另外探索了如何诱导涌现能力的出现,本文在视觉任务上通过对评价指标的修改复现了涌现现象。
大语言模型知识蒸馏
- Fine-tune-CoT: 旨在利用非常大的语言模型 (LMs) 的CoT推理能力来教导小模型如何解决复杂任务,蒸馏出来的小模型在某些数据集上精度甚至能超过 teacher 大模型

