
- 1OpenHarmony/HarmonyOS中如何进行Http请求
- 2kubernetes--pod的生命周期管理(PostStart,PreStop)
- 3波折的2023年_联通数科面试通过一直不谈薪
- 4Android移动开发基础第二版-课后习题_android程序中,log.e()用于输出
- 5Python反编译exe获取封装源代码
- 6【保姆级教学】抓包工具Wireshark使用教程_抓包和视图怎么配合
- 7Android 开发从入门到实战_android入门实战
- 8【整理总结】VSCode常用插件和好用配置(小白必看)_vscode 插件
- 9【Linux】套接字编程
- 10记一次服务器被挖矿的排查过程:xmrig挖矿病毒
Python每日一练(9)-批量爬取B站小视频_class myspider(object):
赞
踩
目录
1. 批量爬取B站小视频
哔哩哔哩网站(英文名称: bilibili),是年轻人的文化社区,被粉丝们亲切的称为B站。该网站中拥有动画、番剧、国创、音乐、舞蹈、游戏、科技、生活、鬼畜、娱乐、时尚等多个内容分区。那么我们能不能爬取一些视频以后离线观看呢?答案是肯定的。本任务要求使用Python语言中的爬虫技术,实现批量爬取B站小视频的爬虫程序。爬取后的效果下图所示。
分析过程如下: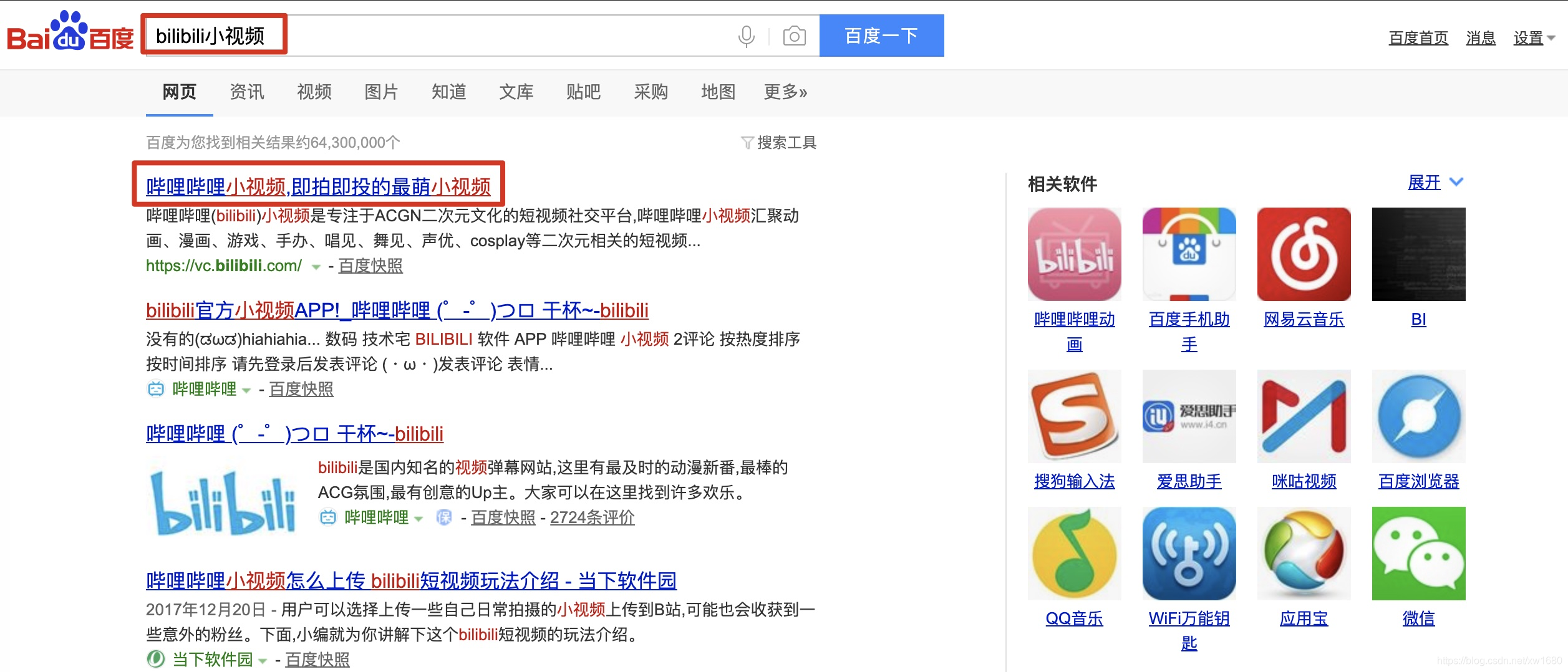
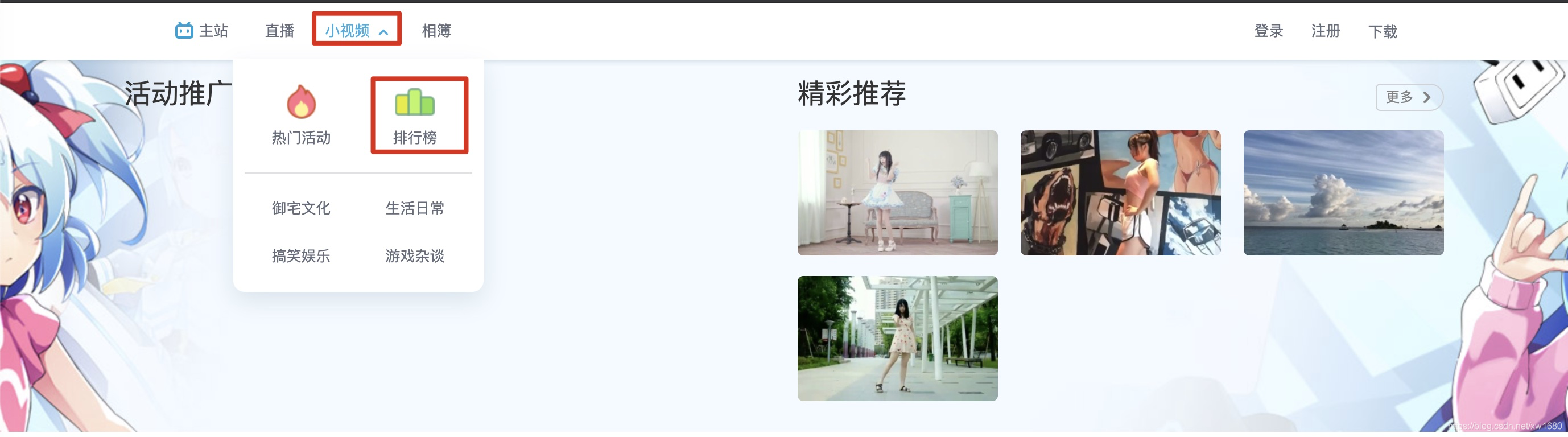
点击上面的排行榜之后,按F12调出浏览器控制台调试界面,点击Network,第一次进入Network可能是空的,按F5或者点击浏览器左上角刷新一下即可,最后如图所示。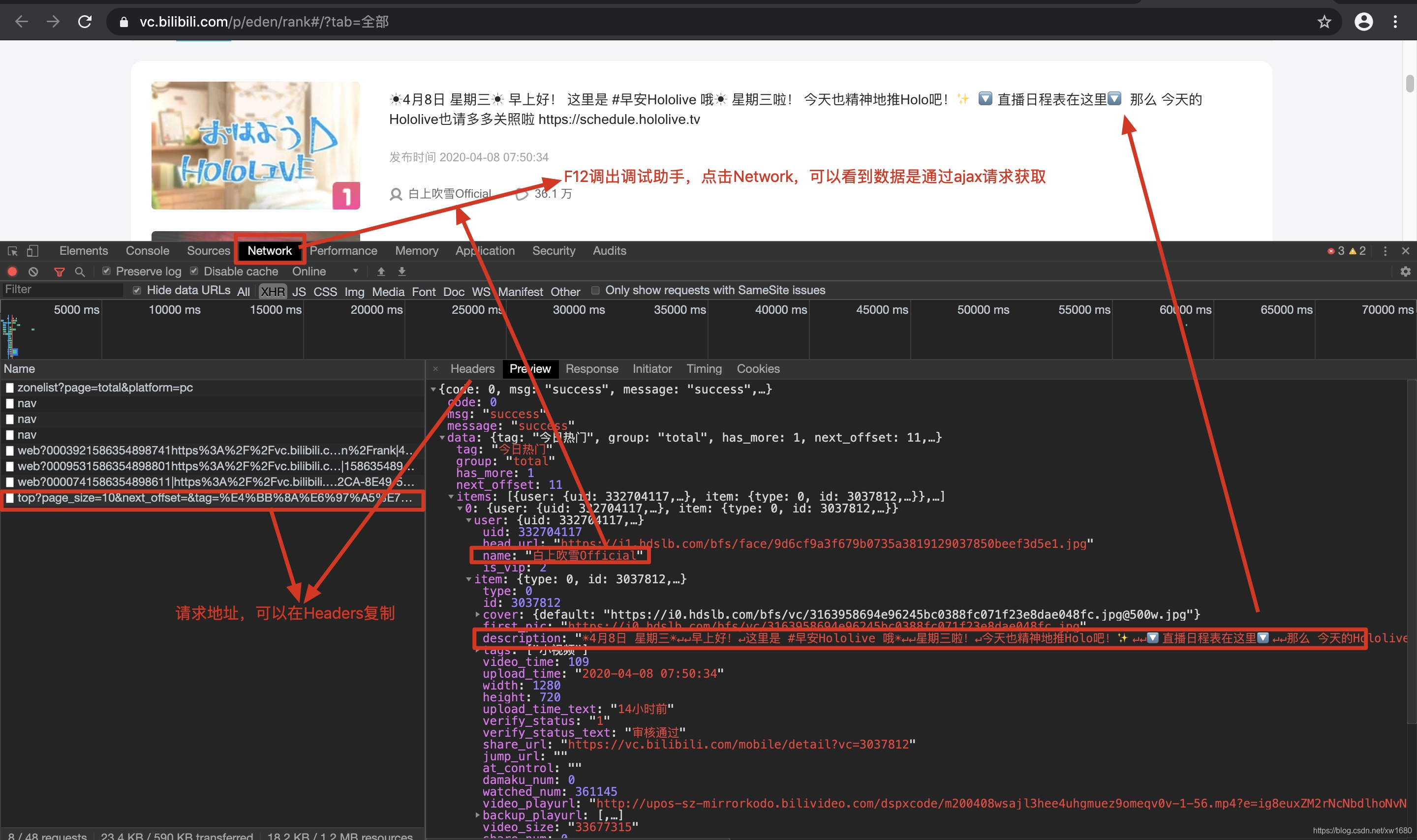
但是需要注意的是,不是所有的数据都是根据一个固定的url返回的,如图所示。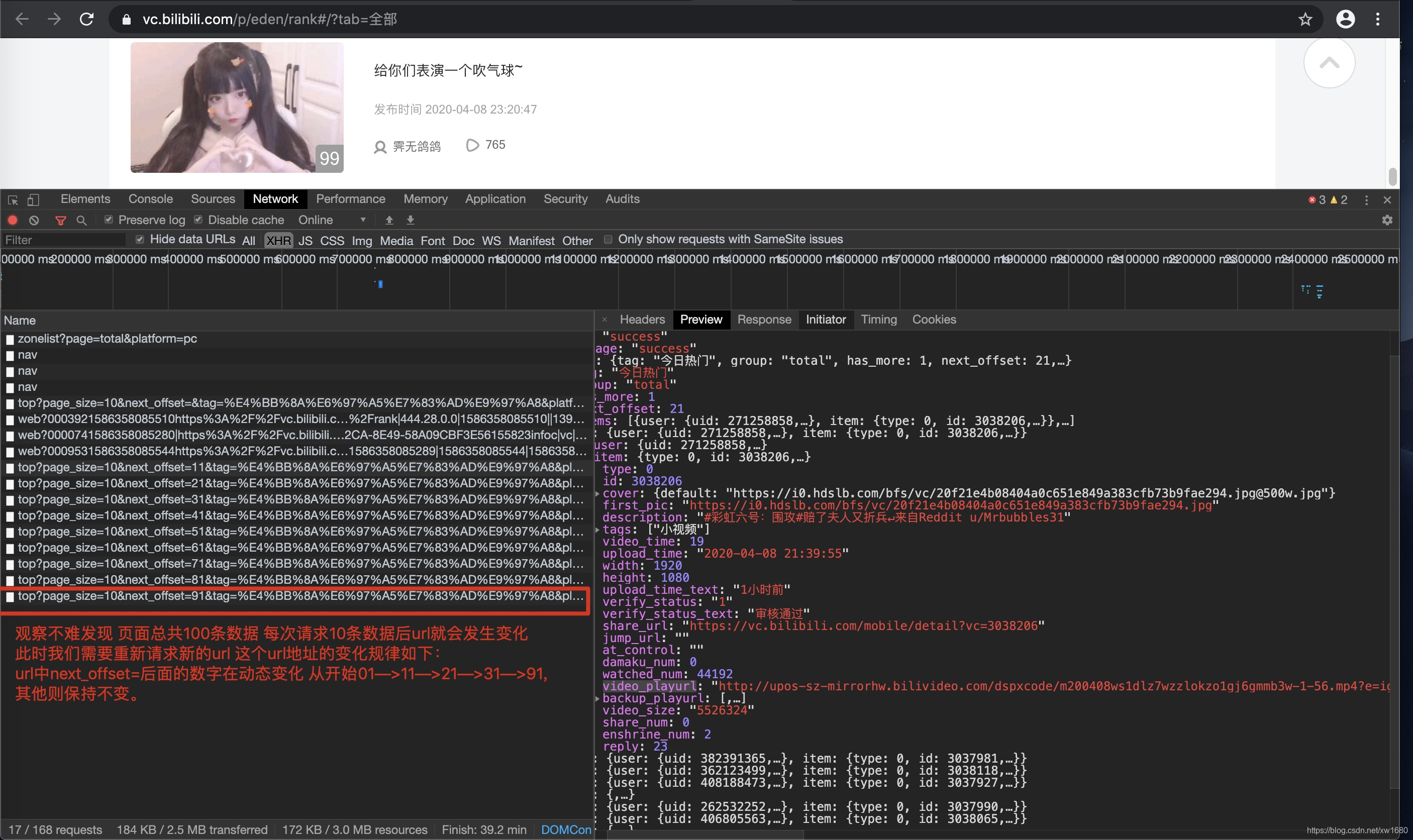
接下来就可以去完成代码了,注意,因为爬虫需要使用第三方模块requests,所以读者需要使用如下命令进行安装。
pip install --user -i http://pypi.douban.com/simple --trusted-host pypi.douban.com requests
如图所示: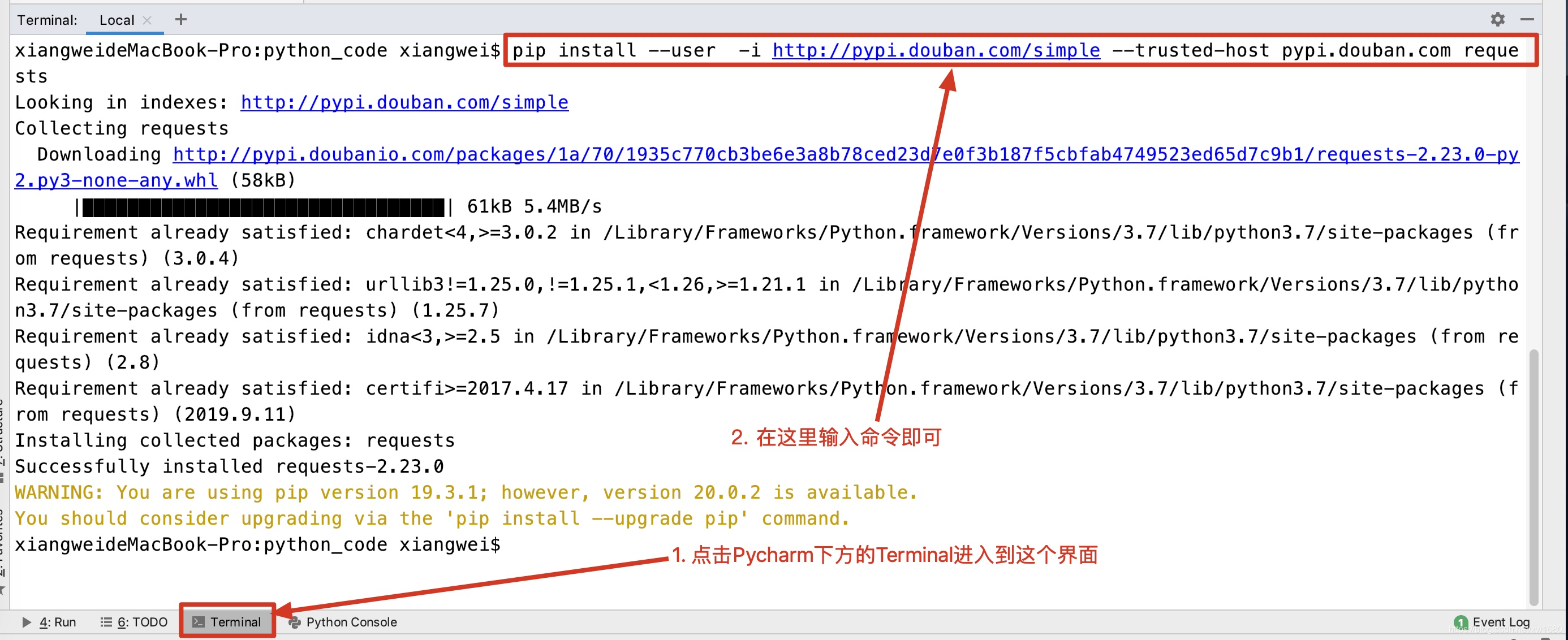
示例代码如下:
- import requests # 网络请求模块
- import os # 系统模块
- import time # 时间模块
- import re # 正则模块
- import random # 随机模块
-
- json_url = "https://api.vc.bilibili.com/board/v1/ranking/top?page_size=10&next_offset={}1&tag=%E4%BB%8A%E6%97%A5%E7%83%AD%E9%97%A8&platform=pc" # 哔哩哔哩小视频json地址
-
-
- class MySpider(object): # 定义一个spider类
- # 初始化
- def __init__(self):
- # 构造请求头
- self.headers = {
- "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit" "/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36"}
-
- # 请求json数据
- def get_json(self, url):
- response = requests.get(url, headers=self.headers)
- # 根据返回的状态码判断是否请求成功
- if response.status_code == 200:
- return response.json() # 返回json信息
- else:
- print("获取json信息的请求没有成功~")
-
- # 下载视频
- def download_video(self, url, video_name):
- # 下载视频的网络请求
- response = requests.get(url, headers=self.headers, stream=True)
- if not os.path.exists("video"): # 判断本地是否存在video文件夹 不存在则创建
- os.mkdir("video")
- # 根据返回的状态码判断是否请求成功
- if response.status_code == 200:
- with open("video/" + video_name + ".mp4", "wb") as file: # 非纯文本都以字节的方式写入
- for data in response.iter_content(chunk_size=1024): # 循环写入file.write(data) # 写入视频文件file.flush() # 刷新缓存
- print("视频下载完成~")
- else:
- print("视频下载失败~")
-
-
- if __name__ == '__main__': # 程序的入口
- spider = MySpider()
- for i in range(10): # 100条数据 需要发送10次循环 所以需要循环10次
- json = spider.get_json(json_url.format(i))
- video_infos = json["data"]["items"] # 信息集 一个列表
- # 遍历 获取每一个video的信息
- for video_info in video_infos:
- # 视频的名字只保留标题中英文、数字与汉字 便于写入文件
- title = video_info["item"]["description"]
- comp = re.compile("[^A-Z^a-z^0-9^\u4e00-\u9fa5]")
- title = comp.sub("", title) # 其他字符一律替换为空
- video_url = video_info["item"]["video_playurl"] # 视频地址
- print(title, video_url) # 打印提取的视频标题与视频地址
- spider.download_video(video_url, title) # 下载视频 视频标题作为视频的名字
- time.sleep(random.randint(3, 6)) # 避免频繁发送请求 ip被封

2. 获取动态请求的JSON数据
在上面的批量爬取B站小视频任务中,我们已经通过发送动态请求的方式,获取到视频的标题与视频地址。为了更好的掌握JSON数据的提取技术,此次任务要求获取JSON中视频发布时间、用户名称以及观看人数并打印。在PyCharm控制台输出的结果如图所示。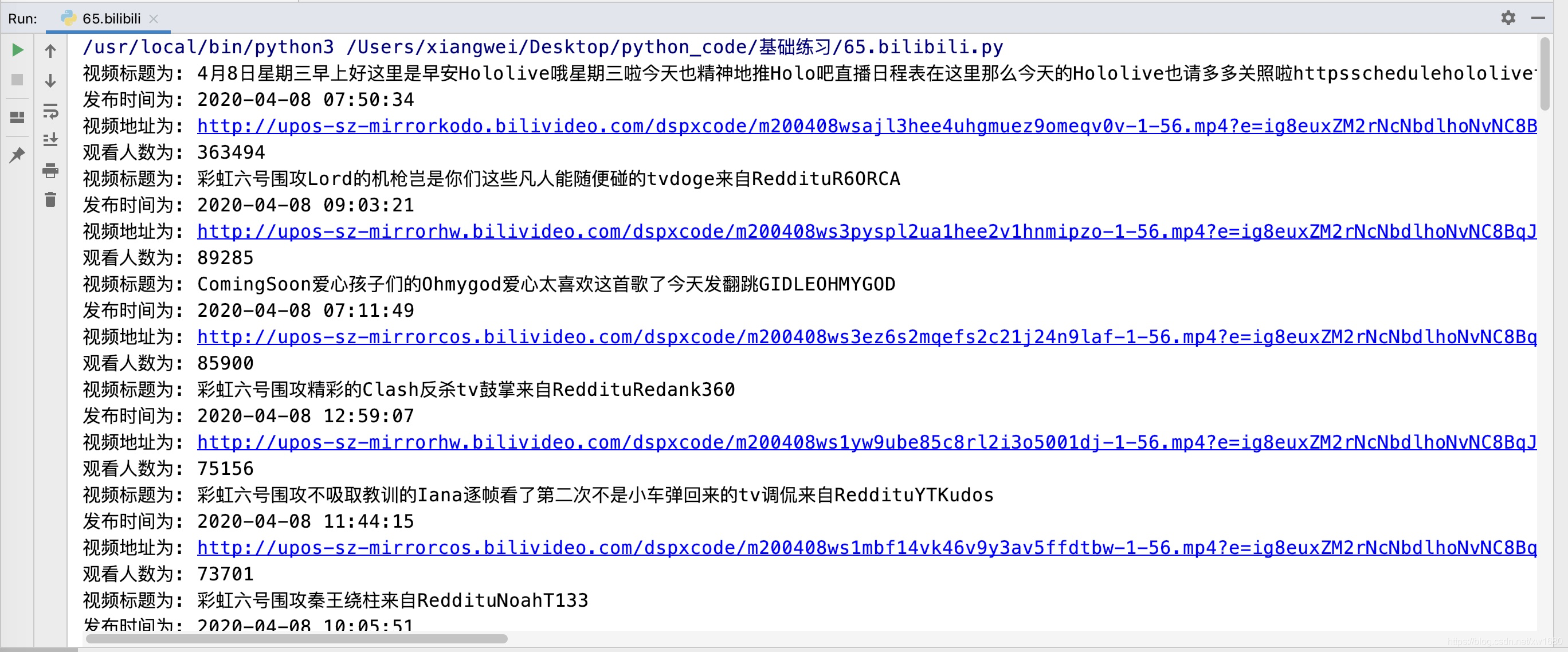
这个任务的话其实就是在之前代码的基础上修改了一小部分,如图所示: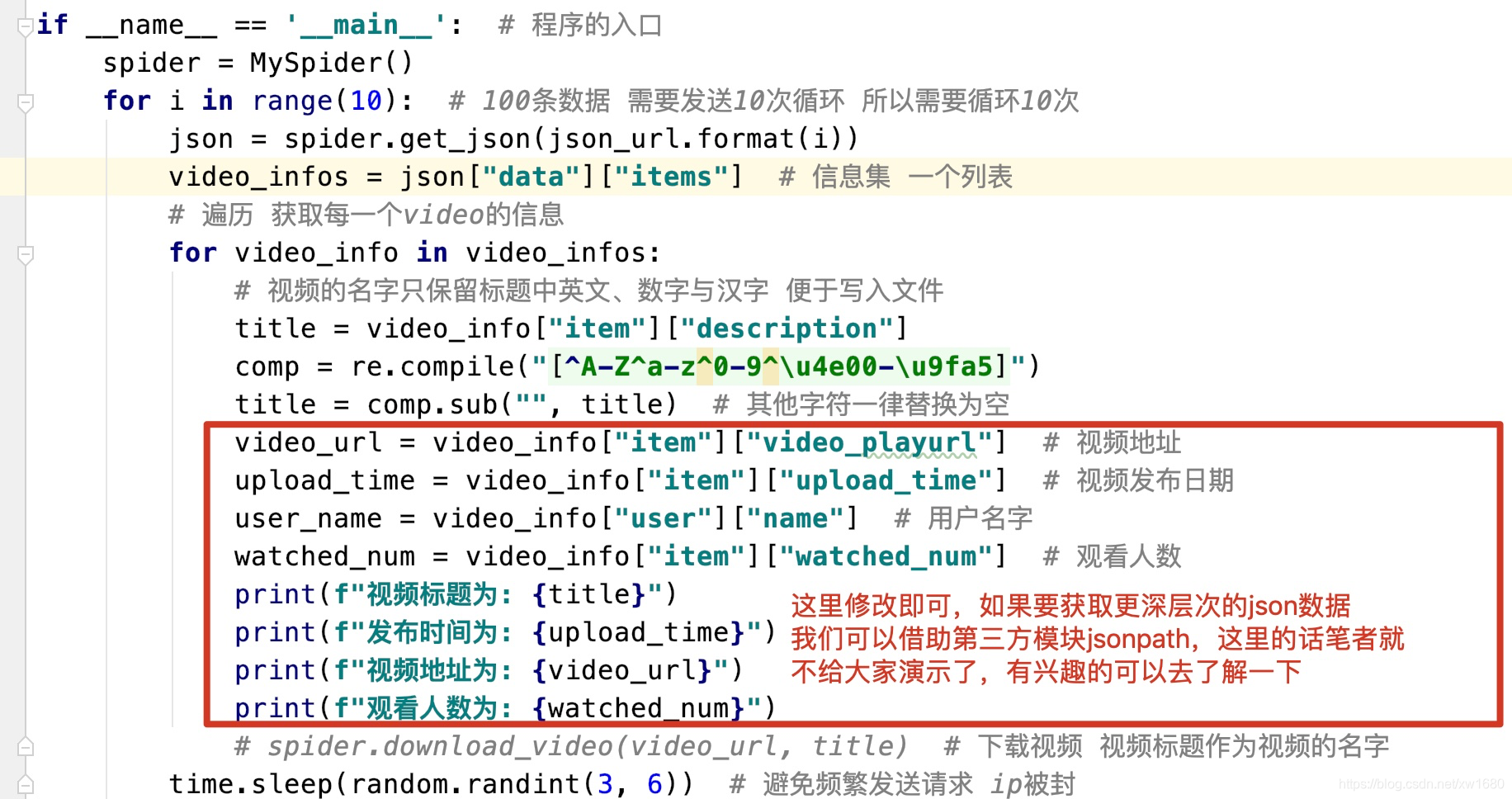
3. 随机生成浏览器的头部信息
有时在请求一个网页内容时,如果频繁地使用一个固定的浏览器头部信息发送网络请求时,可能会出现403错误。产生这种错误是由于该网页为了防止恶意采集信息而使用了反爬虫设置,从而拒绝了用户的访问。所以本任务要求实现每发送一个网络请求,就更换一个浏览器的头部信息,避免使用固定的浏览器头部信息。在PyCharm控制台输出的结果如图所示。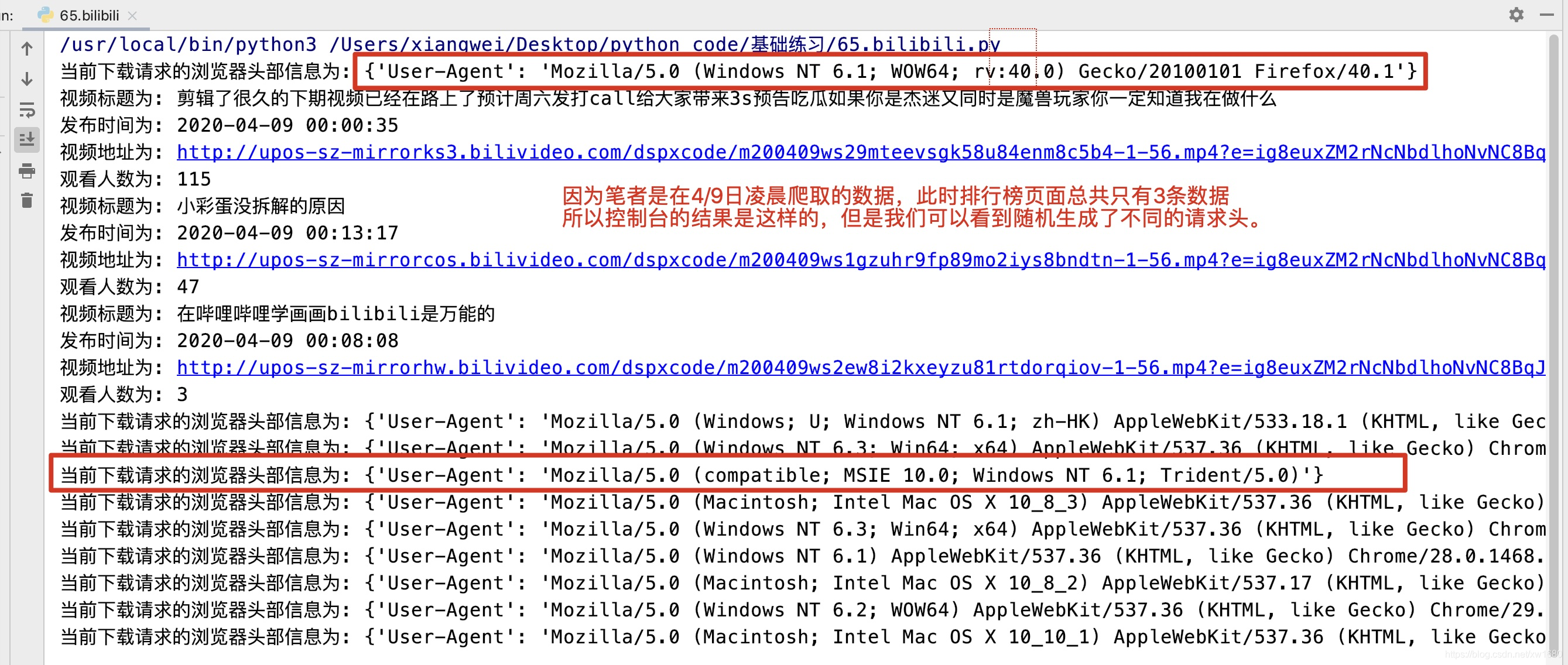
安装fake_useragent模块并初步了解其基本应用,使用pip命令安装fake_useragent模块的命令如下:
pip install --user -i http://pypi.douban.com/simple --trusted-host pypi.douban.com fake_useragent
如图所示: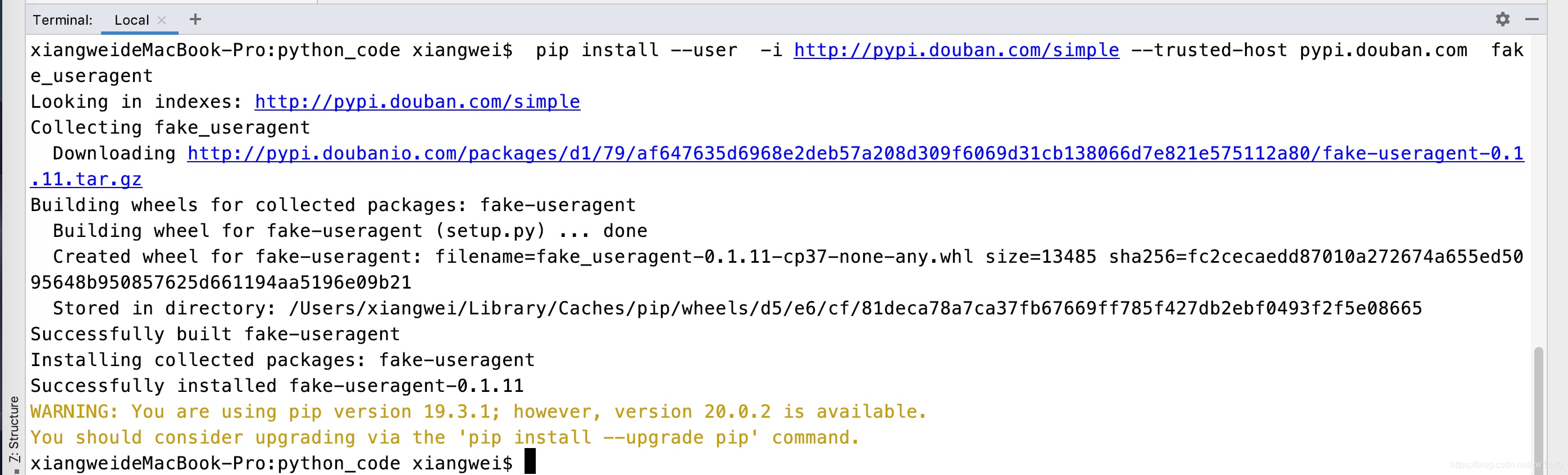
在这次的任务中,还需要一个json格式的文件,下载地址为:
链接:https://pan.baidu.com/s/1IeW70k6pd1HMZqOQ0jw1FQ 密码:t67s
示例代码如下:
- import requests # 网络请求模块
- import os # 系统模块
- import time # 时间模块
- import re # 正则模块
- import random # 随机模块
- from fake_useragent import UserAgent # 导入伪造头部信息的模块
-
- json_url = "https://api.vc.bilibili.com/board/v1/ranking/top?page_size=10&ne" \
- "xt_offset={}1&tag=%E4%BB%8A%E6%97%A5%E7%83%AD%E9%97%A8&platform=pc" # 哔哩哔哩小视频json地址
-
-
- class MySpider(object): # 定义一个spider类
- def get_json(self, url): # 请求json数据
- headers = {"User-Agent": UserAgent(path="fake_useragent.json").random} # 创建随机生成的头部信息
- print(f"当前下载请求的浏览器头部信息为: {headers}")
- response = requests.get(url, headers=headers)
- # 根据返回的状态码判断是否请求成功
- if response.status_code == 200:
- return response.json() # 返回json信息
- else:
- print("获取json信息的请求没有成功~")
-
- # 下载视频
- def download_video(self, url, video_name):
- headers = {"User-Agent": UserAgent(path="fake_useragent.json").random} # 创建随机生成的头部信息
- # 下载视频的网络请求
- response = requests.get(url, headers, stream=True)
- if not os.path.exists("video"): # 判断本地是否存在video文件夹 不存在则创建
- os.mkdir("video")
- # 根据返回的状态码判断是否请求成功
- if response.status_code == 200:
- with open("video/" + video_name + ".mp4", "wb") as file: # 非纯文本都以字节的方式写入
- for data in response.iter_content(chunk_size=1024): # 循环写入file.write(data) # 写入视频文件file.flush() # 刷新缓存
- print("视频下载完成~")
- else:
- print("视频下载失败~")
-
-
- if __name__ == '__main__': # 程序的入口
- spider = MySpider()
- for i in range(10): # 100条数据 需要发送10次循环 所以需要循环10次
- json = spider.get_json(json_url.format(i))
- video_infos = json["data"]["items"] # 信息集 一个列表
- # 遍历 获取每一个video的信息
- for video_info in video_infos:
- # 视频的名字只保留标题中英文、数字与汉字 便于写入文件
- title = video_info["item"]["description"]
- comp = re.compile("[^A-Z^a-z^0-9^\u4e00-\u9fa5]")
- title = comp.sub("", title) # 其他字符一律替换为空
- video_url = video_info["item"]["video_playurl"] # 视频地址
- upload_time = video_info["item"]["upload_time"] # 视频发布日期
- user_name = video_info["user"]["name"] # 用户名字
- watched_num = video_info["item"]["watched_num"] # 观看人数
- print(f"视频标题为: {title}")
- print(f"发布时间为: {upload_time}")
- print(f"视频地址为: {video_url}")
- print(f"观看人数为: {watched_num}")
- # spider.download_video(video_url, title) # 下载视频 视频标题作为视频的名字
- time.sleep(random.randint(3, 6)) # 避免频繁发送请求 ip被封
4. 获取要下载视频的大小
在多数网站中下载视频、音乐以及文本文件时,都可以看见当前文件的大小,如下图所示。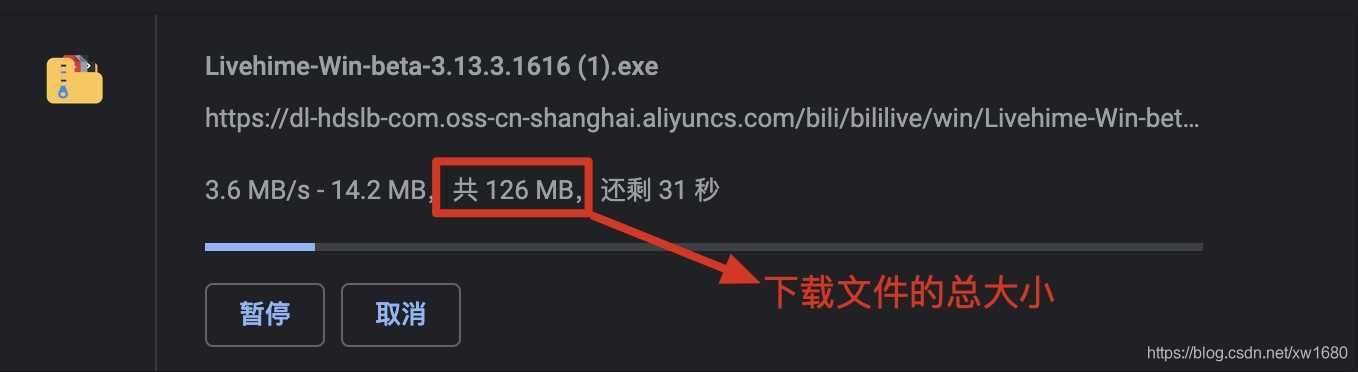
本任务要求通过requests模块下载指定视频内容时,获取其视频的文件大小。在PyCharm控制台输出的结果如下图所示。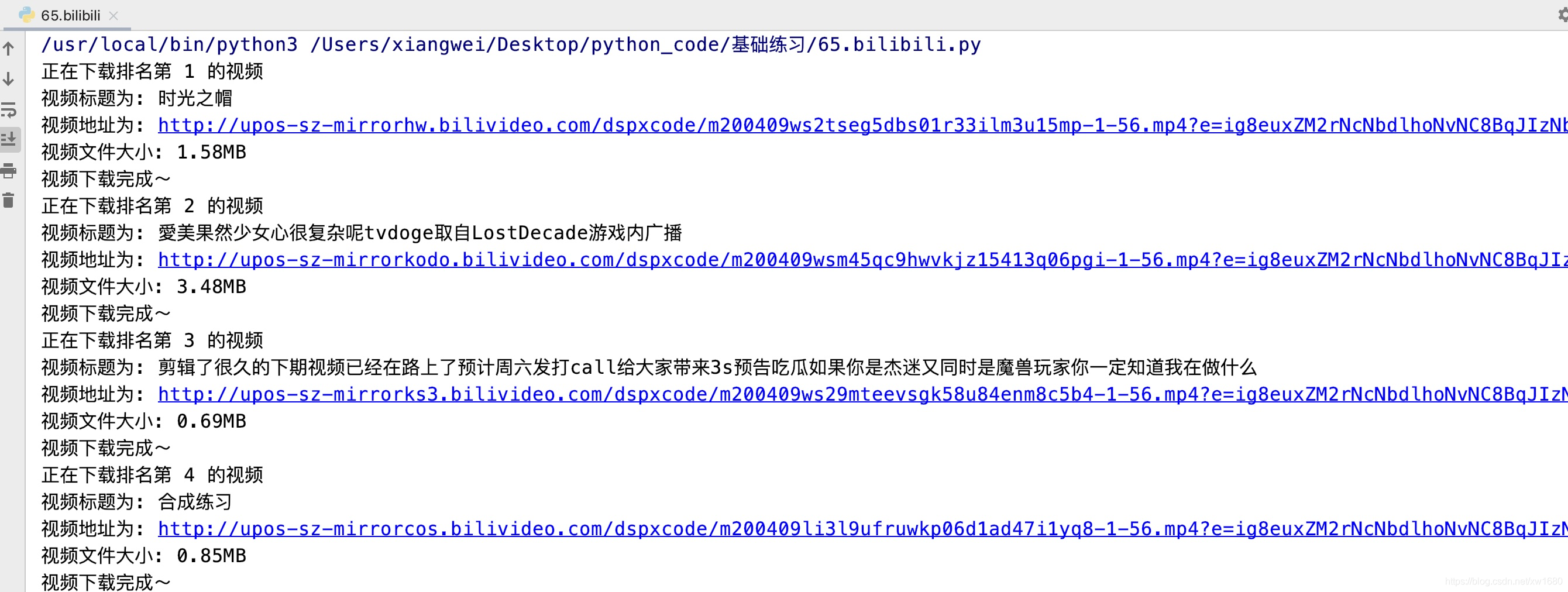
示例代码如下:
- import requests # 网络请求模块
- import os # 系统模块
- import time # 时间模块
- import re # 正则模块
- import random # 随机模块
- from fake_useragent import UserAgent # 导入伪造头部信息的模块
-
- json_url = "https://api.vc.bilibili.com/board/v1/ranking/top?page_size=10&ne" \
- "xt_offset={}1&tag=%E4%BB%8A%E6%97%A5%E7%83%AD%E9%97%A8&platform=pc" # 哔哩哔哩小视频json地址
-
-
- class MySpider(object): # 定义一个spider类
- def get_json(self, url): # 请求json数据
- headers = {"User-Agent": UserAgent(path="fake_useragent.json").random} # 创建随机生成的头部信息
- response = requests.get(url, headers=headers)
- # 根据返回的状态码判断是否请求成功
- if response.status_code == 200:
- return response.json() # 返回json信息
- else:
- print("获取json信息的请求没有成功~")
-
- # 下载视频
- def download_video(self, url, video_name):
- headers = {"User-Agent": UserAgent(path="fake_useragent.json").random} # 创建随机生成的头部信息
- # 下载视频的网络请求
- response = requests.get(url, headers=headers, stream=True)
- content_size = int(response.headers["content-length"]) # 视频内容的总大小
- if not os.path.exists("video"): # 判断本地是否存在video文件夹 不存在则创建
- os.mkdir("video")
- # 根据返回的状态码判断是否请求成功
- if response.status_code == 200:
- # 1MB=1024KB 1KB=1024B 我们返回的是多少B 推出==>KB==>MB
- print("视频文件大小: %0.2fMB" % (content_size / 1024 / 1024)) # 换算单位
- with open("video/" + video_name + ".mp4", "wb") as file: # 非纯文本都以字节的方式写入
- for data in response.iter_content(chunk_size=1024): # 循环写入file.write(data) # 写入视频文件file.flush() # 刷新缓存
- print("视频下载完成~")
- else:
- print("视频下载失败~")
-
-
- if __name__ == '__main__': # 程序的入口
- spider = MySpider()
- ranking = 0 # 排名
- for i in range(10): # 100条数据 需要发送10次循环 所以需要循环10次
- json = spider.get_json(json_url.format(i))
- video_infos = json["data"]["items"] # 信息集 一个列表
- # 遍历 获取每一个video的信息
- for video_info in video_infos:
- ranking += 1
- print(f"正在下载排名第 {ranking} 的视频")
- # 视频的名字只保留标题中英文、数字与汉字 便于写入文件
- title = video_info["item"]["description"]
- comp = re.compile("[^A-Z^a-z^0-9^\u4e00-\u9fa5]")
- title = comp.sub("", title) # 其他字符一律替换为空
- video_url = video_info["item"]["video_playurl"] # 视频地址
- print(f"视频标题为: {title}")
- print(f"视频地址为: {video_url}")
- spider.download_video(video_url, title) # 下载视频 视频标题作为视频的名字
- time.sleep(random.randint(3, 6)) # 避免频繁发送请求 ip被封
5. 实时打印文件下载进度
在多数网站中下载视频、音乐以及文本文件时,都可以看见当前文件的大小以及已经下载的大小,如下图所示。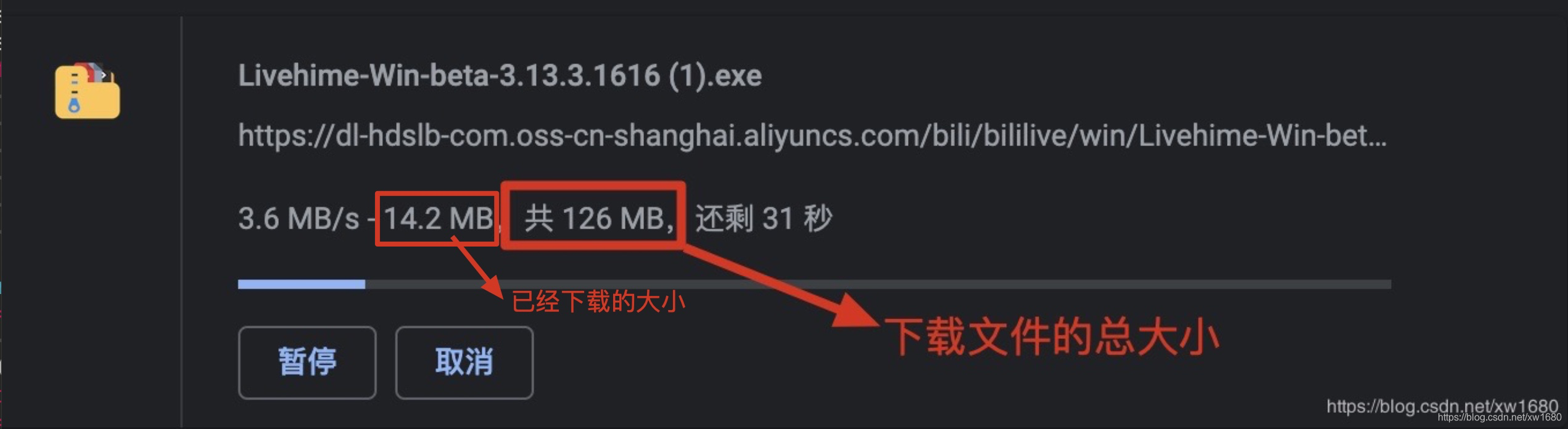
在之前的任务中,我们已经实现了显示当前文件的大小。本任务要求将下载文件的实时进度打印出来。在PyCharm控制台输出的结果如下图所示。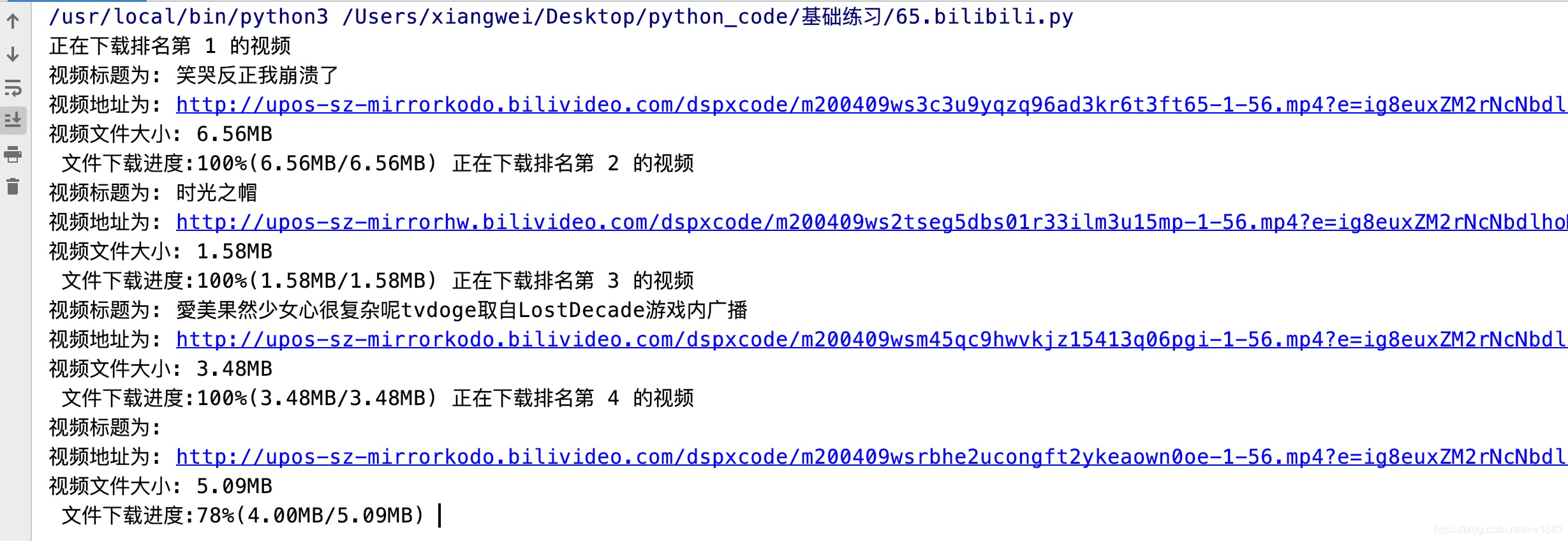
示例代码如下:
- import requests # 网络请求模块
- import os # 系统模块
- import time # 时间模块
- import re # 正则模块
- import random # 随机模块
- from fake_useragent import UserAgent # 导入伪造头部信息的模块
-
- json_url = "https://api.vc.bilibili.com/board/v1/ranking/top?page_size=10&ne" \
- "xt_offset={}1&tag=%E4%BB%8A%E6%97%A5%E7%83%AD%E9%97%A8&platform=pc" # 哔哩哔哩小视频json地址
-
-
- class MySpider(object): # 定义一个spider类
- def get_json(self, url): # 请求json数据
- headers = {"User-Agent": UserAgent(path="fake_useragent.json").random} # 创建随机生成的头部信息
- response = requests.get(url, headers=headers)
- # 根据返回的状态码判断是否请求成功
- if response.status_code == 200:
- return response.json() # 返回json信息
- else:
- print("获取json信息的请求没有成功~")
-
- # 下载视频
- def download_video(self, url, video_name):
- size = 0 # 记录叠加每次写入的大小
- headers = {"User-Agent": UserAgent(path="fake_useragent.json").random} # 创建随机生成的头部信息
- # 下载视频的网络请求
- response = requests.get(url, headers=headers, stream=True)
- content_size = int(response.headers["content-length"]) # 视频内容的总大小
- if not os.path.exists("video"): # 判断本地是否存在video文件夹 不存在则创建
- os.mkdir("video")
- # 根据返回的状态码判断是否请求成功
- if response.status_code == 200:
- # 1MB=1024KB 1KB=1024B 我们返回的是多少B 推出==>KB==>MB
- print("视频文件大小: %0.2fMB" % (content_size / 1024 / 1024)) # 换算单位
- with open("video/" + video_name + ".mp4", "wb") as file: # 非纯文本都以字节的方式写入
- for data in response.iter_content(chunk_size=1024): # 循环写入file.write(data) # 写入视频文件file.flush() # 刷新缓存size += len(data) # 叠加每次写入的大小# 打印下载进度print("\r 文件下载进度:%d%%(%0.2fMB/%0.2fMB)" % ( float(size / content_size * 100), (size / 1024 / 1024), (content_size / 1024 / 1024)), end=" ")
- else:
- print("视频下载失败~")
-
-
- if __name__ == '__main__': # 程序的入口
- spider = MySpider()
- ranking = 0 # 排名
- for i in range(10): # 100条数据 需要发送10次循环 所以需要循环10次
- json = spider.get_json(json_url.format(i))
- video_infos = json["data"]["items"] # 信息集 一个列表
- # 遍历 获取每一个video的信息
- for video_info in video_infos:
- ranking += 1
- print(f"正在下载排名第 {ranking} 的视频")
- # 视频的名字只保留标题中英文、数字与汉字 便于写入文件
- title = video_info["item"]["description"]
- comp = re.compile("[^A-Z^a-z^0-9^\u4e00-\u9fa5]")
- title = comp.sub("", title) # 其他字符一律替换为空
- video_url = video_info["item"]["video_playurl"] # 视频地址
- print(f"视频标题为: {title}")
- print(f"视频地址为: {video_url}")
- spider.download_video(video_url, title) # 下载视频 视频标题作为视频的名字
- time.sleep(random.randint(3, 6)) # 避免频繁发送请求 ip被封



