- 1AtCoder Beginner Contest 157 F Yakiniku Optimization Problem 难点 计算几何 求解两圆相交的交点坐标 二分
- 2C/C++程序设计课程设计[2023-02-15]_c++网吧管理系统课程设计
- 3java 1.7 linux rpm_linux 下面 jdk1.7 rpm 包的安装
- 4JDK8常见的函数式接口详解_jdk函数式接口
- 5STM32F103RCT6 实验代码之舵机+超声波避障小车(二)舵机+超声波_stm32f103rct6超声波模块
- 6k8s集群部署springboot项目_k8s部署springboot项目
- 7【Vue3+Vite】Vue生命周期与组件 快速学习 第三期
- 8QrCodeUtil--二维码工具类
- 9springboot banner在线生成_江帅帅:精通 Spring Boot 系列 03
- 10基于Spring Security2与 Ext 的权限管理设计与兑现
人体姿态估计-SimplePoseNet(二)_行人姿态估计小模型
赞
踩
资源链接
论文出处:微软亚洲研究院(MSRA)、2018EECV
论文
代码
论文个人解读
这篇文章开发的单人姿态估计模型SimplePoseNet简单高效,是2018年COCO人体关键点挑战赛的亚军,使用top-down策略,在COCO测试集上取得mAP=73.7。
模型结构
模型结构非常简单:
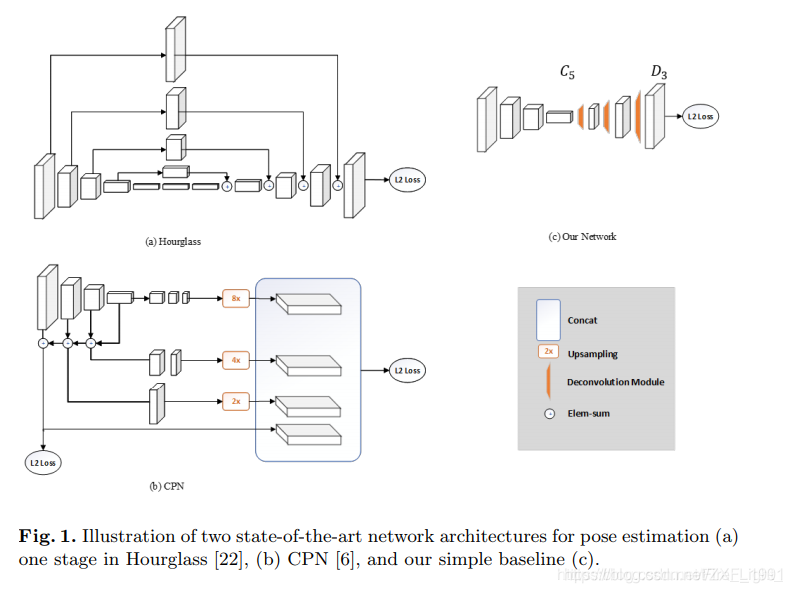
网络特点
1) 网络直接在基础网络后面接反卷积作为上采样,没有构建金字塔特征结构
2) 使用反卷积作为上采样,添加可训练参数,增加网络的非线性,使得网络能够更好的表达特征。在上采样upsampling目前主要存在三种常用方式:
双线性插值(bilinear)---在语义分割中用的比较多的一种方式,例如FCN和一些带金字塔结构的网络,在不增加网络复杂性的情况下,实现特征的扩张,近似还原高层特征,既含有位置信息又有语义信息,具体实现源码不记录。
反池化(unpooling)---原理:记录下max-pooling在对应kernel中的坐标,在反池化过程中,将一个元素根据kernel进行放大,根据之前的坐标将元素填写进去,其他位置补0. 感觉没啥用,在segNet中有源码。
反卷积(deconvolution)---反卷积的具体实现源码,不做讨论,但是要会用。记录下卷积以及反卷积的输出out与输入in在caffe和tensorflow中的不同关系:
卷积:
caffe:
caffe架构中conv和pooling层输出尺寸的计算方法
tensorflow:
valid(不进行补0):
o
u
t
=
f
l
o
o
r
(
(
i
n
−
k
)
/
s
)
+
1
out=floor((in-k)/s)+1
out=floor((in−k)/s)+1
same(进行补0):
o
u
t
=
c
e
i
l
(
i
n
/
s
)
out=ceil(in/s)
out=ceil(in/s)
反卷积:
caffe:
o
u
t
=
(
i
n
−
1
)
∗
s
+
k
−
2
∗
p
out=(in-1)*s+k-2*p
out=(in−1)∗s+k−2∗p
tensorflow:
valid(不进行补0):
o
u
t
=
i
n
∗
s
+
m
a
x
(
k
−
s
,
0
)
out=in*s+max(k-s,0)
out=in∗s+max(k−s,0)
same(进行补0):
o
u
t
=
i
n
∗
s
out=in*s
out=in∗s
3) 具体结构:
第一部分:基础特征提取器---Resnet(进行5次下采样)
第二部分: 连续3个反卷积,每个反卷积参数设置相同
第三部分: 1个1*1卷积层,使得输出热图个数为关键点个数
4) 损失函数:
MSE均方误差--L2loss
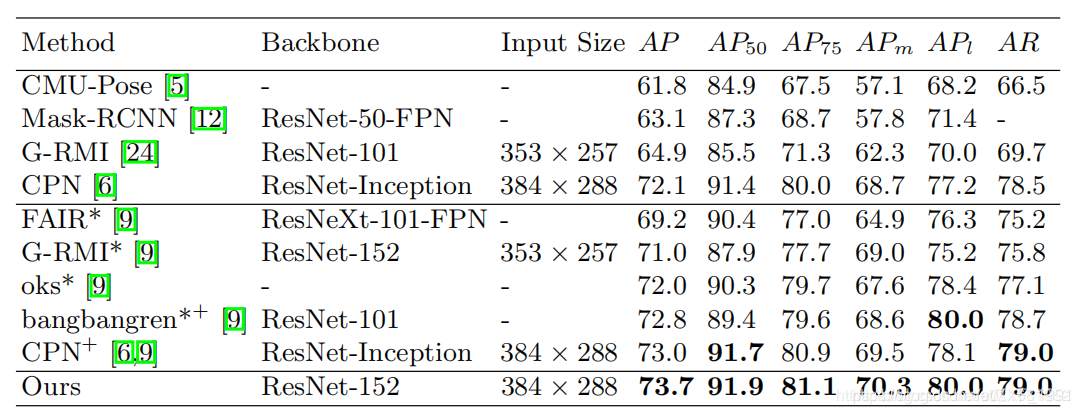
算法效果
在coco数据集上关键点检测取得了不错的效果:
1)参数设置实验:
 2) Hourglass、CPN、SimplePoseNet 对比
2) Hourglass、CPN、SimplePoseNet 对比
 3) 多种方法综合对比
3) 多种方法综合对比
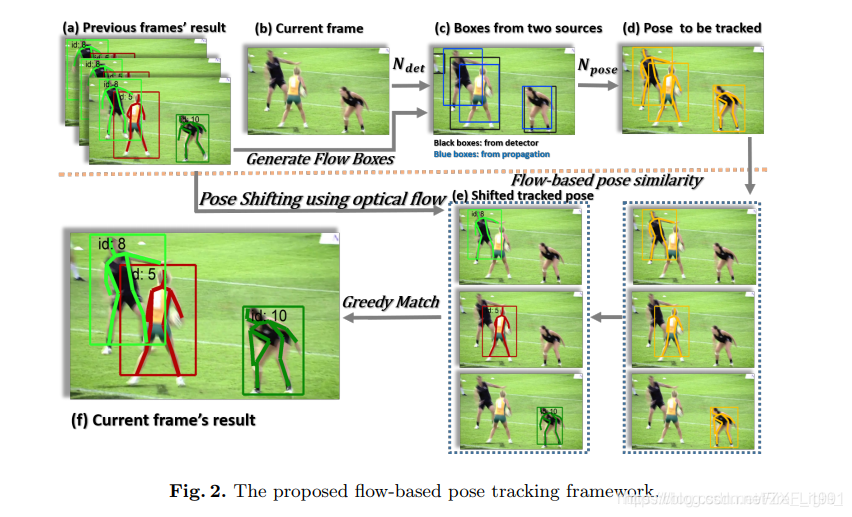
视频轨迹追踪
文中还介绍了使用SimplePoseNet进行轨迹跟踪的一套流程。流程中主要的方法依赖于ICCV 17PoseTrack Challenge 提出的算法,首先使用MaskRcnn来进行多行人检测,在视频第一帧中每个检测到的人给一个id,然后之后的每一帧检测到的人都和上一帧检测到的人通过某种度量方式(文中提到的是计算检测框的IOU)计算一个相似度,将相似度大的作为同一个id,没有匹配到的分配一个新的id。
创新的改进点:
1) 使用光流法对检测框进行补充,目的避免有些行人没有被检测到,文中给出例子,如下图c
2) 使用OKS代替代替检测框的IOU来计算相似度,具体是使用光流法计算某一帧的关键点会出现在的另外一帧的位置,然后用这个计算出来的位置和这一帧检测出来的关键点之间计算OKS,以此作为两帧之间的不同人的相似度值。
跟踪示意图: