
热门标签
热门文章
- 1maven的pom.xml中repositories的作用_pom repositories
- 2实验—UML正向工程和反向工程应用_uml 顺序图 正向工程
- 3Java常用类库之String_java string库
- 4基于代码一步一步教你深度学习中循环神经网络(RNN)的原理
- 5通过阿里云ECS服务器公网ip访问tomcat,nginx
- 6我的1827创作纪念日
- 7Class类的继承_class继承
- 8【Java程序设计】【C00254】基于Springboot的java学习平台(有论文)
- 9Excel数据可视化—波士顿矩阵图【四象限图】_波斯顿矩阵图excel怎么做
- 10100个go语言面试问答合集_golangde_SQL_go语言mysql的面试题
当前位置: article > 正文
向量与矩阵、矩阵与矩阵的余弦相似度_numpy向量和矩阵计算相似度
作者:代码创新者 | 2024-02-03 16:49:24
赞
踩
numpy向量和矩阵计算相似度
向量与矩阵、矩阵与矩阵的余弦相似度
很简单,将公式套上就行了。
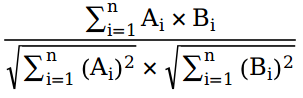
python 代码
import numpy as np a = np.array([[1, 2, 1, 2, 3, 5, 6, 2]]) b = np.array([ [1, 2, 1, 2, 3, 5, 6, 2], [1, 2, 1, 2, 3, 5, 6, 2], [2, 3, 3, 2, 1, 2, 1, 1], [2, 2, 1, 1, 1, 2, 4, 4] ]) c = np.array([ [1, 2, 1, 2, 3, 5, 6, 2], [2, 1, 1, 2, 1, 2, 3, 3], [2, 3, 3, 2, 1, 2, 1, 1], [2, 2, 1, 1, 1, 2, 4, 4] ]) # 向量与向量的余弦相似度 def vector_vector(arr, brr): # return arr.dot(brr.T) / (np.sqrt(np.sum(arr*arr)) * np.sqrt(np.sum(brr*brr))) return np.sum(arr*brr) / (np.sqrt(np.sum(arr*arr)) * np.sqrt(np.sum(brr*brr))) # 向量与矩阵的余弦相似度 def vector_matrix(arr, brr): return arr.dot(brr.T) / (np.sqrt(np.sum(arr*arr)) * np.sqrt(np.sum(brr*brr, axis=1))) # 矩阵与矩阵的余弦相似度 def matrix_matrix(arr, brr): # return arr.dot(brr.T).diagonal() / ((np.sqrt(np.sum(arr * arr, axis=1))) * np.sqrt(np.sum(brr * brr, axis=1))) return np.sum(arr*brr, axis=1) / (np.sqrt(np.sum(arr**2, axis=1)) * np.sqrt(np.sum(brr**2, axis=1))) print(vector_vector(a, a)) print(vector_matrix(a, b)) print(matrix_matrix(b, c))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
输出结果
1.0
[[1. 1. 0.68376346 0.85941947]]
[1. 0.87369775 1. 1. ]
- 1
- 2
- 3
另外,在像人脸识别这类底库巨大的情况下,可以先将底库的 L2 范式事先计算好,这样可以节省大量的时间,示例:
# -*- coding: utf-8 -*- import numpy as np import time def vector_matrix(arr, brr): return arr.dot(brr.T) / (np.sqrt(np.sum(arr*arr)) * np.sqrt(np.sum(brr*brr, axis=1))) def vector_matrix_T(arr, brr, brr_l2): return arr.dot(brr) / (np.sqrt(np.sum(arr*arr)) * brr_l2) """ 测试条件 不使用 cuda,没有 cuda,只有 cpu 假设需要识别100个人,只统计相似度的时间,单个人脸特征长度为128,底库为100W """ # 当前检测到的人脸特征 faceFeat = np.random.random((128, )) # 人脸底库特征 FeatDB = np.random.random((1000000, 128)) t1 = time.time() for i in range(100): sim = vector_matrix(faceFeat, FeatDB) print("直接计算相似度耗时:", time.time() - t1) t2 = time.time() FeatDB_T = FeatDB.T FeatDB_L2 = np.sqrt(np.sum(FeatDB*FeatDB, axis=1)) for i in range(100): sim = vector_matrix_T(faceFeat, FeatDB_T, FeatDB_L2) print("先计算L2,再计算相似度耗时:", time.time() - t2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
运行结果:
直接计算相似度耗时: 63.002615213394165
先计算L2,再计算相似度耗时: 5.581569194793701
- 1
- 2
这差距还是挺大的。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/article/detail/57309?site
推荐阅读
相关标签

