
热门标签
热门文章
- 1springboot3.0的新特性_springboot3.0新特性
- 2解决 three.js 模型颜色偏差问题_three 模型加载墙面颜色变了
- 3L1-036 A乘以B-java
- 4http://与www.开头的网站有什么区别
- 5C++ 指针与作用域_c++ 指针定义的作用域
- 6获取机器内存的三种方法_asmwbinvd
- 7win服务器系统2019和2016区别,Windows Server 2019和Windows Server, Version 1909的区别是什么?...
- 8Python中time模块详解[转]
- 9props与state的区别_state和props的区别
- 10JAVA获取当前进程的内存占用数和CPU利用率以及读写字节数并计算统计信息_java获取cpu使用率
当前位置: article > 正文
微博json文件_爬虫:新浪微博爬虫的最简单办法
作者:数据灵魂2 | 2024-02-03 15:18:06
赞
踩
微博怎么得到json文件
前言:本文主要内容是介绍如何用最简单的办法去采集新浪微博的数据,主要是采集指定微博用户发布的微博以及微博收到的回复等内容,可以通过配置项来调整爬取的微博用户列表以及其他属性。
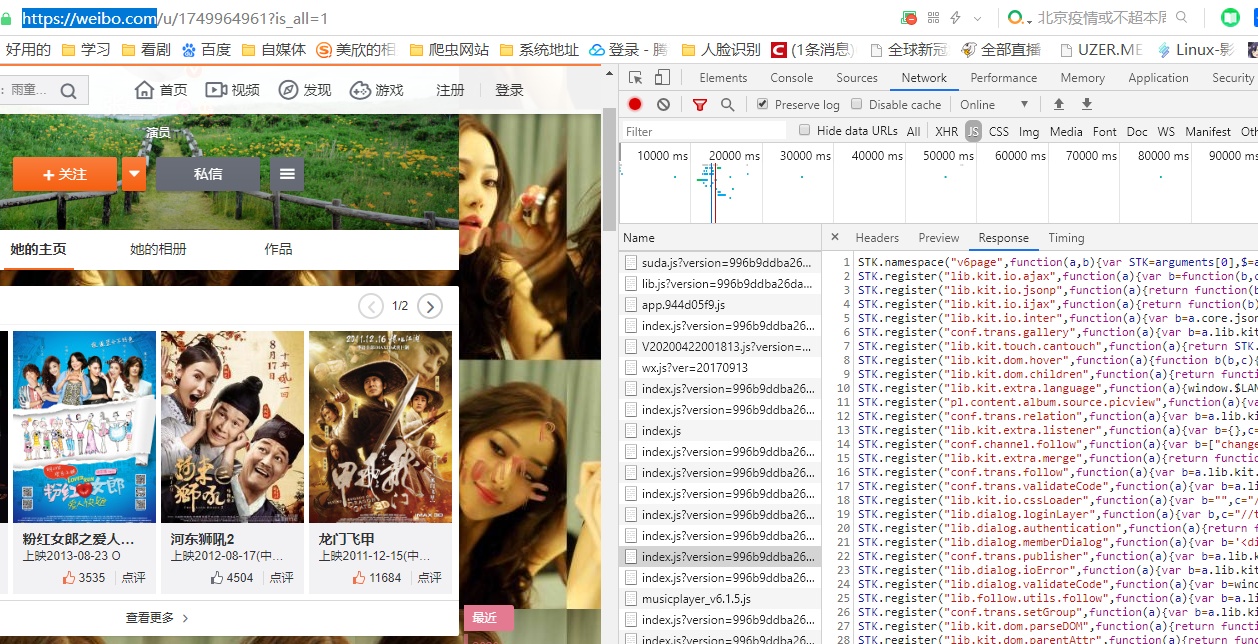
既然说是最简单的办法,那么我们就得先分析微博爬虫可能选择的几个目标网址,首先肯定是最常见的web网站了
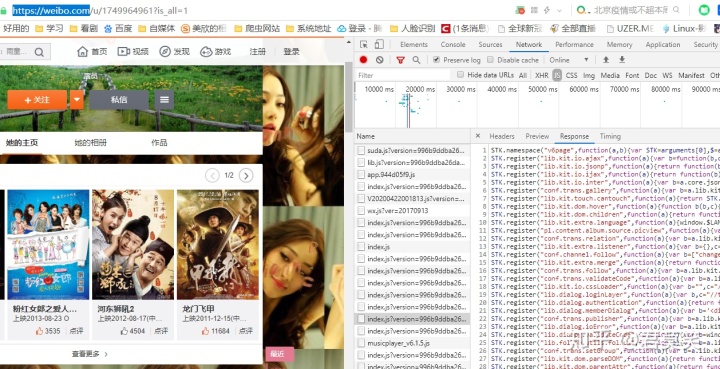
还有就是m站,也就是移动端网页
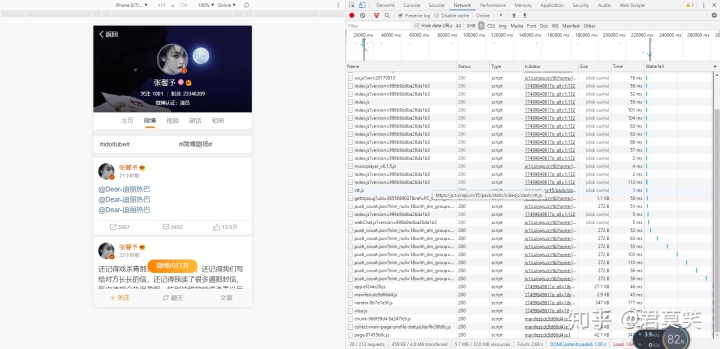
以及一个无法旧版本的访问入口了,首先可以排除web站了,这个是最麻烦的,它的请求是被js加密过,处理起来很麻烦
那我们为何不退而求其次呢,我们观察下这个m站的请求
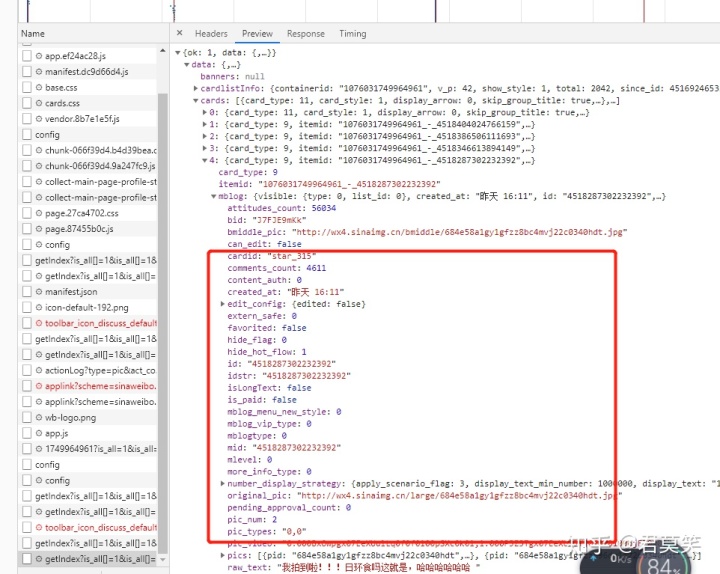
可以发现在某个请求里可以发现我们需要的微博信息,既然这样就好办了,我们就可以着手我们的代码了
首先是获取用户信息,通过用户信息获取用户的微博总数,这样就可以知道总共多少页的数据了,代码如下所示
- def get_json(self, params):
- """获取网页中json数据"""
- url = 'https://m.weibo.cn/api/container/getIndex?'
- r = requests.get(url, params=params, cookies=self.cookie)
- return r.json()
- def get_page_count(self):
- """获取微博页数"""
- try:
- weibo_count = self.user['statuses_count']
- page_count = int(math.ceil(weibo_count / 10.0))
- return page_count
- except KeyError:
- sys.exit(u'程序出错')
- def get_user_info(self):
- """获取用户信息"""
- params = {'containerid': '100505' + str(weibo_config['user_id'])}
- js = self.get_json(params)
- if js['ok']:
- info = js['data']['userInfo']
- user_info = {}
- user_info['id'] = weibo_config['user_id']
- user_info['screen_name'] = info.get('screen_name', '')
- user_info['gender'] = info.get('gender', '')
- user_info['statuses_count'] = info.get('statuses_count', 0)
- user_info['followers_count'] = info.get('followers_count', 0)
- user_info['follow_count'] = info.get('follow_count', 0)
- user_info['description'] = info.get('description', '')
- user_info['profile_url'] = info.get('profile_url', '')
- user_info['profile_image_url'] = info.get('profile_image_url', '')
- user_info['avatar_hd'] = info.get('avatar_hd', '')
- user_info['urank'] = info.get('urank', 0)
- user_in

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/article/detail/57143
推荐阅读

相关标签

