
- 1天鹰优化器算法(AO)优化的BP神经网络预测,AO-BP回归预测
- 2蓝桥杯之平方拆分_c++蓝桥杯 平方拆分
- 32024最新版IntelliJ IDEA安装使用指南
- 4IT运维服务体系的总体架构是什么?_运维架构
- 5SpringBoot配置druid数据源_spring.datasource.type=druid
- 6安装docker_查看docker安装路径
- 7区块链技术与应用 【全国职业院校技能大赛国赛题目解析】第二套区块链系统部署与运维_区块链系统部署与运维1.1 搭建区块链系统并验证1.2 搭建区块链系统管理平台并
- 8Unity PlayerSetting Android打包设置介绍_unity 设置 mute other audio sources相关android权限问题
- 9python开机自动运行_python脚本开机自启的实现方法
- 10【Flink-Kafka-To-Mongo】使用 Flink 实现 Kafka 数据写入 Mongo(根据对应操作类型进行增、删、改操作,写入时对时间类型字段进行单独处理)_kafka数据存入mongo
Hive实战UDF 外部依赖文件找不到的问题_primitiveobjectinspectorfactory.writablestringobje
赞
踩
关注公众号:
大数据技术派,回复:资料,领取1024G资料。
目录
-
关于外部依赖文件找不到的问题
-
为什么要使用外部依赖
-
为什么idea 里面可以运行上线之后不行
-
依赖文件直接打包在jar 包里面不香吗
-
学会独立思考并且解决问题
-
-
总结
其实这篇文章的起源是,我司有数据清洗时将ip转化为类似中国-湖北-武汉地区这种需求。由于ip服务商提供的Demo,只能在本地读取,我需要将ip库上传到HDFS分布式存储,每个计算节点再从HDFS下载到本地。
那么到底能不能直接从HDFS读取呢?跟我强哥讲了这件事后,不服输的他把肝儿都熬黑了,终于给出了解决方案。
关于外部依赖文件找不到的问题
其实我在上一篇的总结中也说过了你需要确定的上传的db 文件在那里,也就是你在hive 中调用add file之后 会出现添加后的文件路径或者使用list 命令来看一下
今天我们不讨论这个问题我们讨论另外一个问题,外部依赖的问题,当然这个问题的引入本来就很有意思,其实是一个很简单的事情。
为什么要使用外部依赖
重点强调一下我们的外部依赖并不是单单指的是jar包依赖,我们的程序或者是UDF 依赖的一切外部文件都可以算作是外部依赖。
使用外部依赖的的原因是我们的程序可能需要一些外部的文件,或者是其他的一些信息,例如我们这里的UDF 中的IP 解析库(DB 文件),或者是你需要在UDF 访问一些网络信息等等。
为什么idea 里面可以运行上线之后不行
我们很多如人的一个误区就是明明我在IDEA 里面都可以运行为什么上线或者是打成jar 包之后就不行,其实你在idea 可以运行之后不应该直接上线的,或者说是不应该直接创建UDF 的,而是先应该测试一下jar 是否可以正常运行,如果jar 都不能正常运行那UDF 坑定就运行报错啊。
接下来我们就看一下为什么idea 可以运行,但是jar 就不行,代码我们就不全部粘贴了,只粘贴必要的,完整代码可以看前面一篇文章
- @Override
- public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
- converter = ObjectInspectorConverters.getConverter(arguments[0], PrimitiveObjectInspectorFactory.writableStringObjectInspector);
-
- String dbPath = Ip2Region.class.getResource("/ip2region.db").getPath();
- File file = new File(dbPath);
- if (file.exists() == false) {
- System.out.println("Error: Invalid ip2region.db file");
- return null;
- }
- DbConfig config = null;
- try {
- config = new DbConfig();
- searcher = new DbSearcher(config, dbPath);
- } catch (DbMakerConfigException | FileNotFoundException e) {
- e.printStackTrace();
- }
-
-
- return PrimitiveObjectInspectorFactory.writableStringObjectInspector;
-
- }

这就是我们读取外部配置文件的方法,我们接下来写一个测试
- @Test
- public void ip2Region() throws HiveException {
- Ip2Region udf = new Ip2Region();
- ObjectInspector valueOI0 = PrimitiveObjectInspectorFactory.javaStringObjectInspector;
- ObjectInspector[] init_args = {valueOI0};
- udf.initialize(init_args);
- String ip = "220.248.12.158";
-
- GenericUDF.DeferredObject valueObj0 = new GenericUDF.DeferredJavaObject(ip);
-
- GenericUDF.DeferredObject[] args = {valueObj0};
- Text res = (Text) udf.evaluate(args);
- System.out.println(res.toString());
- }
我们发现是可以正常运行的,这里我们把它打成jar 包再运行一下,为了方便测试我们将这个测试方法改成main 方法,我们还是先在idea 里面运行一下
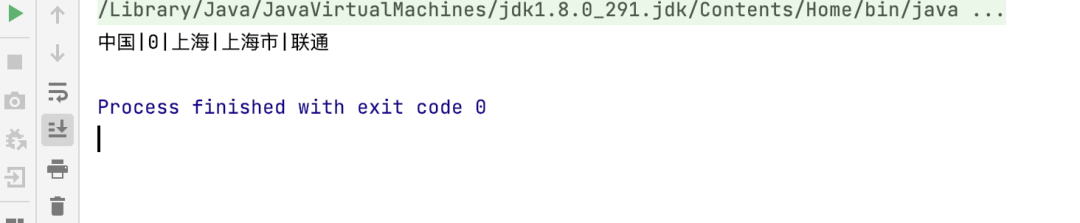
我们发现还是可以正常运行,我们接下来打个jar包试一下
- Error: Invalid ip2region.db file
- java.io.FileNotFoundException: file: /Users/liuwenqiang/workspace/code/idea/HiveUDF/target/HiveUDF-0.0.4.jar!/ip2region.db (No such file or directory)
- at java.io.RandomAccessFile.open0(Native Method)
- at java.io.RandomAccessFile.open(RandomAccessFile.java:316)
- at java.io.RandomAccessFile.<init>(RandomAccessFile.java:243)
- at java.io.RandomAccessFile.<init>(RandomAccessFile.java:124)
- at org.lionsoul.ip2region.DbSearcher.<init>(DbSearcher.java:58)
- at com.kingcall.bigdata.HiveUDF.Ip2Region.main((Ip2Region.java:42)
- Exception in thread "main" java.lang.NullPointerException
- at com.kingcall.bigdata.HiveUDF.Ip2Region.main(Ip2Region.java:48)
我们发现jar 包已经报错了,那你的UDF 肯定运行不了了啊,其实如果你仔细看的话就知道为什么报错了/Users/liuwenqiang/workspace/code/idea/HiveUDF/target/HiveUDF-0.0.4.jar!/ip2region.db 其实就是这个路径,我们很明显看到这个路径是不对的,所以这就是我们UDF报错的原因
依赖文件直接打包在jar 包里面不香吗
上面找到了这个问题,现在我们就看一下如何解决这个问题,出现这个问题的原因就是打包后的路径不对,导致我们的不能找到这个依赖文件,那我们为什要这个路径呢。这个主要是因为我们使用的API 的原因
- DbConfig config = new DbConfig();
- DbSearcher searcher = new DbSearcher(config, dbPath);
也就是说我们的new DbSearcher(config, dbPath) 第二个参数传的是DB 的路径,所以我们很自然的想到看一下源码是怎么使用这个路径的,能不能传一个其他特定的路径进去,其实我们从idea 里面可以运行就知道,我们是可以传入一个本地路径的。
这里我们以memorySearch 方法作为入口
- // 构造方法
- public DbSearcher(DbConfig dbConfig, String dbFile) throws FileNotFoundException {
- this.dbConfig = dbConfig;
- this.raf = new RandomAccessFile(dbFile, "r");
- }
- // 构造方法
- public DbSearcher(DbConfig dbConfig, byte[] dbBinStr) {
- this.dbConfig = dbConfig;
- this.dbBinStr = dbBinStr;
- this.firstIndexPtr = Util.getIntLong(dbBinStr, 0);
- this.lastIndexPtr = Util.getIntLong(dbBinStr, 4);
- this.totalIndexBlocks = (int)((this.lastIndexPtr - this.firstIndexPtr) / (long)IndexBlock.getIndexBlockLength()) + 1;
- }
- // memorySearch 方法
- public DataBlock memorySearch(long ip) throws IOException {
- int blen = IndexBlock.getIndexBlockLength();
- // 读取文件到内存数组
- if (this.dbBinStr == null) {
- this.dbBinStr = new byte[(int)this.raf.length()];
- this.raf.seek(0L);
- this.raf.readFully(this.dbBinStr, 0, this.dbBinStr.length);
- this.firstIndexPtr = Util.getIntLong(this.dbBinStr, 0);
- this.lastIndexPtr = Util.getIntLong(this.dbBinStr, 4);
- this.totalIndexBlocks = (int)((this.lastIndexPtr - this.firstIndexPtr) / (long)blen) + 1;
- }
-
- int l = 0;
- int h = this.totalIndexBlocks;
- long dataptr = 0L;
-
- int m;
- int p;
- while(l <= h) {
- m = l + h >> 1;
- p = (int)(this.firstIndexPtr + (long)(m * blen));
- long sip = Util.getIntLong(this.dbBinStr, p);
- if (ip < sip) {
- h = m - 1;
- } else {
- long eip = Util.getIntLong(this.dbBinStr, p + 4);
- if (ip <= eip) {
- dataptr = Util.getIntLong(this.dbBinStr, p + 8);
- break;
- }
-
- l = m + 1;
- }
- }
-
- if (dataptr == 0L) {
- return null;
- } else {
- m = (int)(dataptr >> 24 & 255L);
- p = (int)(dataptr & 16777215L);
- int city_id = (int)Util.getIntLong(this.dbBinStr, p);
- String region = new String(this.dbBinStr, p + 4, m - 4, "UTF-8");
- return new DataBlock(city_id, region, p);
- }
- }
其实我们看到memorySearch 方法首先是读取DB 文件到内存的字节数组然后使用,而且我们看到有这样一个字节数组的构造方法DbSearcher(DbConfig dbConfig, byte[] dbBinStr)
既然读取文件不行,那我们能不能直接传入字节数组呢?其实可以的
- DbSearcher searcher=null;
- DbConfig config = new DbConfig();
- try {
- config = new DbConfig();
- } catch (DbMakerConfigException e) {
- e.printStackTrace();
- }
- InputStream inputStream = Ip2Region.class.getResourceAsStream("/ip2region.db");
- ByteArrayOutputStream output = new ByteArrayOutputStream();
- byte[] buffer = new byte[4096];
- int n = 0;
- while (-1 != (n = inputStream.read(buffer))) {
- output.write(buffer, 0, n);
- }
- byte[] bytes = output.toByteArray();
- searcher = new DbSearcher(config, bytes);
- // 只能使用memorySearch 方法
- DataBlock block = searcher.memorySearch(ip);
-
- //打印位置信息(格式:国家|大区|省份|城市|运营商)
- System.out.println(block.getRegion());
我们还是先在Idea 里面测试,我们发现是可以运行的,然后我们还是打成jar包进行测试,这次我们发现还是可以运行中国|0|上海|上海市|联通
也就是说我们已经把这个问题解决了,有没有什么问题呢?有那就是DB 文件在jar 包里面,不能单独更新,前面我们将分词的时候也水果,停用词库是随着公司的业务发展需要更新的 DB库也是一样的。
也就是说可以这样解决但是不完美,我看到有的人是这样做的他使用getResourceAsStream 把数据读取到内存,然后再写出成本地临时文件,然后再使用,我只想说这个解决方式也太不友好了吧
-
文件不能更新
-
需要写临时文件(权限问题,如果被删除了还得重写)
只能使用memorySearch 方法
这个原因值得说明一下,因为你使用其他两个search 方法的时候都会抛出异常Exception in thread "main" java.lang.NullPointerException
这主要是因为其他两个方法都是涉及到从文件读取数据进来,但是我们的raf 是null
学会独立思考并且解决问题
上面我们的UDF 其实已经可以正常使用了,但是有不足之处,这里我们就处理一下这个问题,前面我们说过了其实在IDEA 里的路径参数可以使用,那就说明传入本地文件是可以的,但是有一个问题就是我们的UDF 是可能在所有节点上运行的,所以传入本地路径的前提是需要保证所有节点上这个本地路径都可用,但是这样维护成本也很高,还不如直接将依赖放在jar 包里面。
继承DbSearcher
其实我们是可以将这个依赖放在OSS或者是HDFS 上的,但是这个时候你传入路径之后,还是有问题,因为构造方法里面读取文件的时候默认的是本地方法,其实这个时候你可以继承DbSearcher 方法,然后添加新的构造方法,完成从HDFS 上读取文件。
- // 构造方法
- public DbSearcher(DbConfig dbConfig, byte[] dbBinStr) {
- this.dbConfig = dbConfig;
- this.dbBinStr = dbBinStr;
- this.firstIndexPtr = Util.getIntLong(dbBinStr, 0);
- this.lastIndexPtr = Util.getIntLong(dbBinStr, 4);
- this.totalIndexBlocks = (int)((this.lastIndexPtr - this.firstIndexPtr) / (long)IndexBlock.getIndexBlockLength()) + 1;
- }
读取文件传入字节数组
还有一个方法就是我们直接使用第二个构造方法,dbBinStr 就是我们读取进来的字节数组,这个时候不论这个依赖是在HDFS 还是OSS 上你只要调用相关的API 就可以了,其实这个方法我们在读取jar包里面的文件的时候已经使用过了
下面的ctx就是OSS的上下问,用来从OSS上读取数据,同理你可以从任何你需要的地方读取数据。
- DbConfig config = null;
- try {
- config = new DbConfig();
- } catch (DbMakerConfigException e) {
- e.printStackTrace();
- }
- InputStream inputStream = ctx.readResourceFileAsStream("ip2region.db");
- ByteArrayOutputStream output = new ByteArrayOutputStream();
- byte[] buffer = new byte[4096];
- int n = 0;
- while (-1 != (n = inputStream.read(buffer))) {
- output.write(buffer, 0, n);
- }
- byte[] bytes = output.toByteArray();
- searcher = new DbSearcher(config, bytes);
总结
-
Idea里面使用文件路径是可以的,但是jar里面不行,要使用也是本地文件或者是使用getResourceAsStream获取InputStream; -
存储在
HDFS或者OSS上的文件也不能使用路径,因为默认是读取本地文件的; -
多思考,为什么,看看源码,最后请你思考一下怎么在外部依赖的情况下使用
binarySearch或者是btreeSearch方法;
猜你喜欢
数仓建模—宽表的设计
Spark SQL知识点与实战
Hive计算最大连续登陆天数
Hadoop 数据迁移用法详解
数仓建模分层理论

