
热门标签
热门文章
- 1Cesium中常用的一些数学计算(矩阵、向量)用法——向量_cesium.cartesian3.subtract
- 2VMware或virtualbox虚拟机虚拟网卡缺失解决办法_vmware虚拟机网卡不见了
- 3MYSQL解决“plugin caching_sha2_password could not be loaded”
- 4【Cisco Packet Tracer】验证IP数据包的分组与转发流程
- 5感悟随想:还记得当初自己为什么选择计算机?
- 6毕业设计-基于 Matlab 的电力系统稳定性分析与仿真_现代电力系统分析matlab仿真
- 7千帆起航:探索百度智能云千帆AppBuilder在AI原生应用开发中的革新之路
- 8Vue + Element UI 实现文本超出长度显示省略号,鼠标移上悬浮展示全部内容的方法_element超过的字符省略
- 93D Gaussian Splatting:用于实时的辐射场渲染
- 10Python zip函数 详解(全)
当前位置: article > 正文
假期听书友福利-(lian)(ting)(网)有声小说下载脚本_朗读引擎url地址大全
作者:lpred | 2024-02-02 13:31:21
赞
踩
朗读引擎url地址大全
两个星期的考试周副本结束,今天放假。寝室就我一个人,闲来没事,写篇博客混混时间。好像现在csdn上爬虫主题比较火,我也来个听书网站的下载脚本吧。
(前两次投竟然审核没通过)
下载脚本
(本脚本仅限爬取该网站免费内容)
网站选取和网页元素踩点
我挺喜欢听小说的,某雅,某人听书都充过会员,但爬他们网站的资源是可能有被禁的风险,思来想去还是爬个没有版权保护的听书网站,找了一会儿,发现有个叫(lian)(ting)网的还不错。网站底下有免责声明,资源来自网络比较丰富。
并且有电脑端和手机端两个网站,非常nice
可以看一下网站的爬虫声明:
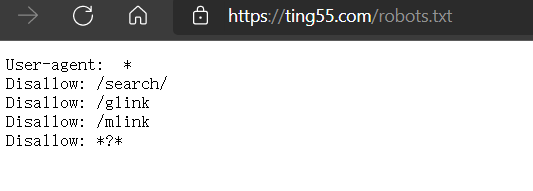
只要不爬取上图所写的目录,应该就不用担心。
首先观察网页整体布局
点击项对应的标签和属性
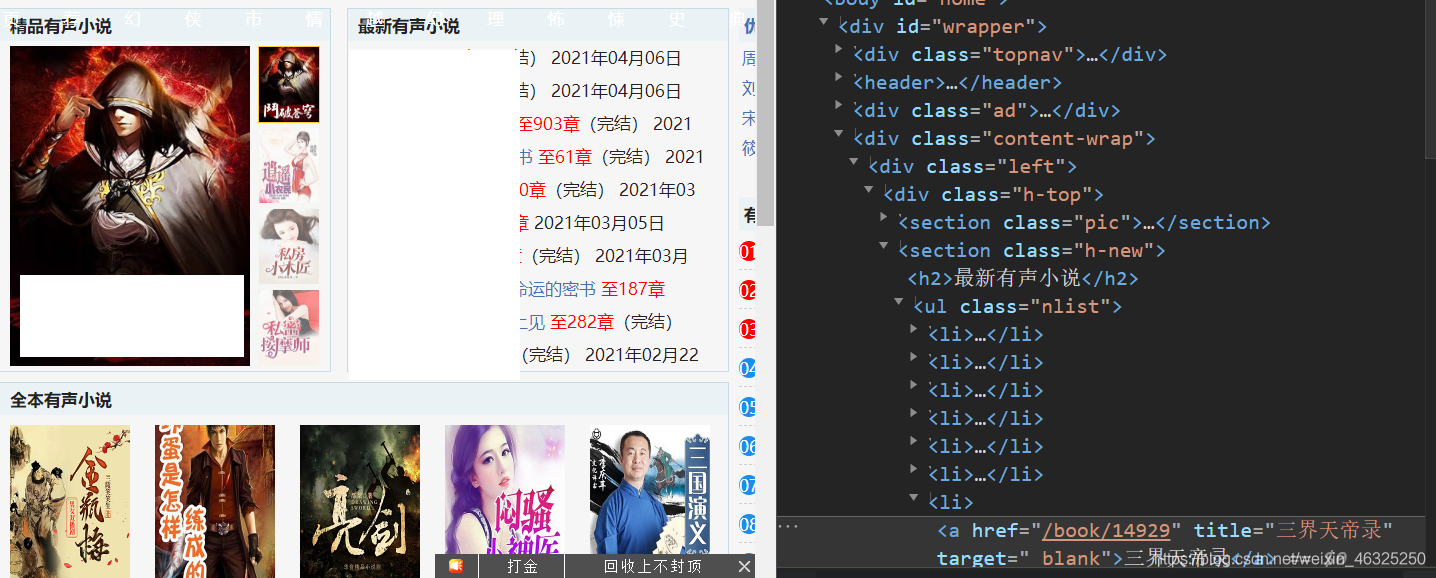
每本书对应链接应该是“https://m.ting55.com/”+href
进入选中的书籍页面,我们可以看到对应的每一集目录
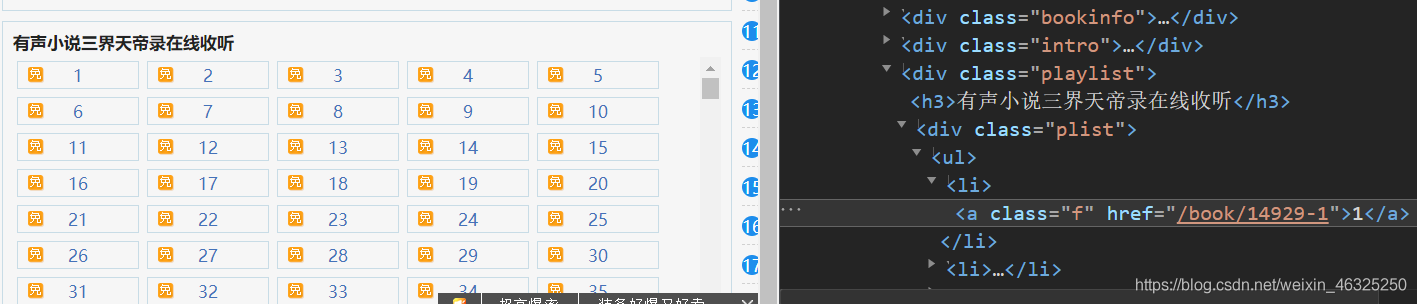
每一集目录应该是“https://m.ting55.com/”+href
进入每一集后查看音频元素,大多为m4a和mp3格式,我们最终要找到每一集对应的音频文件地址
在类似的爬取音频视频网站时,最重要的就是找到音频视频对应的地址
选取合适的库工具
这里我使用的是Microsoft edge(浏览器)+selenium+requests+lxml(代码里面有一些库是优化使用的)
这个网站比较贼,如果单纯用requests库时在返回每一集的响应时会将音频资源标签去掉,所以我们需要使用selenium来将标签完整的爬取。
selenium配置资料:可以在csdn中搜索Microsoft edge+selenium,或者选择chrome+selenium来进行配置。
其他的库就正常的pip下载
开始代码部分
我们首先获取想听的书的网页信息(响应+书名)
def get_url_response(url):#传入的参数url即你想听的书的url地址
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'}
Proxy={'http':'121.230.133.214:9999'}
a=requests.get(url,proxies=Proxy,headers=header)
return a
def get_bookname(a):
html=etree.HTML(a.text)
name=html.xpath('//*[@id="wrapper"]/div[3]/div/div/div[2]/div/div[2]/h1/text()')
return name
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
然后获取小说每一章的url地址
def get_page_url(reponse,start_page,stop_page):
html=etree.HTML(reponse.text)
page_url=[]
for i in range(start_page,stop_page+1):
page_url.append('https://m.ting55.com/'+html.xpath(f'/html/body/div[1]/div[3]/div/div/div[4]/div/ul/li[{i}]/a/@href')[0])
return page_url #获取的每个章节的url地址
- 1
- 2
- 3
- 4
- 5
- 6
- 7
获取每一章的音频地址并爬取保存
@retry(stop_max_attempt_number=6) #假如该函数断开,重复尝试的次数 def get_audio_url(driver,page_url,name): # #声明代理 global num num=num+1 if (num==4): return print(page_url,"---第{}次".format(num)) driver.get(page_url) sleep(120) page_all=driver.find_element_by_xpath('/html/body/div[1]/section/h1').text audio_url=driver.find_element_by_xpath('//*[@id="player"]').get_attribute("src") print("开始爬取{}".format(name)) save(name,page_all,audio_url) num=0 def save(name,page,audio_url): path = f'D:/有声小说/{name}//' if not os.path.exists(path): os.makedirs(path) audio_content = requests.get(audio_url).content #audio_content=request.get(audio_url).content with open(path +page+ '.mp3', mode='wb') as f: f.write(audio_content) print('正在保存:', page) print("等待一会开始爬取下一章") # sleep(100)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
主进程
if __name__ == '__main__': url='https://www.ting55.com/book/13864' # start=int(input("起始集:")) start=10 # stop=int(input("中止集:")) stop=100 proxy = Proxy({ 'proxyType': ProxyType.MANUAL, # #代理 ip 和端口 'httpProxy': '223.215.118.145:9999'}) # #配置对象 DesiredCapabilities dc=DesiredCapabilities.EDGE.copy() # #把代理 ip 加入配置对象 proxy.add_to_capabilities(dc) option=EdgeOptions() option.add_argument('headless') option.add_argument( 'user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36') option.add_experimental_option('excludeSwitches', ['enable-automation']) # driver=webdriver.Edge("D:/edgedriver_win64/9.1/msedgedriver.exe",capabilities=dc,options=option) driver = Edge("D:/edgedriver_win64/9.1/msedgedriver.exe",options = option) re=get_url_response(url) try: get_medio(driver,get_page_url(re,start,stop),get_bookname(re)) except Exception as e: print(e,"5小时后还在被封") driver.close() print("第{}到第{}已经爬取完成".format(start,stop)) driver.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
完整代码
import requests import os from lxml import etree # from selenium import webdriver from time import sleep from selenium.webdriver.common.proxy import Proxy from selenium.webdriver.common.proxy import ProxyType from selenium.webdriver.common.desired_capabilities import DesiredCapabilities from retrying import retry from msedge.selenium_tools import EdgeOptions from msedge.selenium_tools import Edge num = 0 def get_url_response(url): header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'} Proxy={'http':'121.230.133.214:9999'} a=requests.get(url,proxies=Proxy,headers=header) return a def get_page_url(reponse,start_page,stop_page): html=etree.HTML(reponse.text) page_url=[] for i in range(start_page,stop_page+1): page_url.append('https://m.ting55.com/'+html.xpath(f'/html/body/div[1]/div[3]/div/div/div[4]/div/ul/li[{i}]/a/@href')[0]) return page_url def get_bookname(a): html=etree.HTML(a.text) name=html.xpath('//*[@id="wrapper"]/div[3]/div/div/div[2]/div/div[2]/h1/text()') return name @retry(stop_max_attempt_number=6)#假如该函数断开,重复尝试的次数 def get_audio_url(driver,page_url,name): # #声明代理 global num num=num+1 if (num==4): return print(page_url,"---第{}次".format(num)) driver.get(page_url) sleep(120)#每一集之间的爬取设置暂停2分钟 page_all=driver.find_element_by_xpath('/html/body/div[1]/section/h1').text audio_url=driver.find_element_by_xpath('//*[@id="player"]').get_attribute("src") print("开始爬取{}".format(name)) save(name,page_all,audio_url) num=0 def get_medio(driver,page,name): global num try_num=0 stop=0 for i in page: get_audio_url(driver,i,name) stop+=1 if(stop%4 == 0 and stop!=0): print("为防止爬取过快被限制,暂停10分钟") sleep(600) stop=0 #这个网站有访问限制,如果一定时间内访问过于频繁就会被封一个小时,所以我设置了上面的for循环每爬取四集就停十分钟 while (num>=4 and try_num<=2): print("开始等待一小时")# sleep(3600) print("等待时间结束,开始爬取") try_num=try_num+1 print("get_medio中{}的第{}次尝试".format(i,try_num)) num=0 get_audio_url(driver,i,name) #假如被封禁一个小时,这个while语句会自动等待一小时后再试着爬取,一直被禁则重复五次后异常退出 try_num=0 def save(name,page,audio_url): path = f'D:/有声小说/{name}//' if not os.path.exists(path): os.makedirs(path) audio_content = get_url_response(audio_url).content #audio_content=request.get(audio_url).content with open(path +page+ '.m4a', mode='wb') as f: f.write(audio_content) print('正在保存:', page) print("等待一会开始爬取下一章") # sleep(100) if __name__ == '__main__': url=input("恋听网中书籍url地址:") start=int(input("起始集:")) stop=int(input("中止集:")) proxy = Proxy({ 'proxyType': ProxyType.MANUAL, # #代理 ip 和端口 'httpProxy': '223.215.118.145:9999'}) # #配置对象 DesiredCapabilities dc=DesiredCapabilities.EDGE.copy() # #把代理 ip 加入配置对象 proxy.add_to_capabilities(dc) option=EdgeOptions() option.add_argument('headless') option.add_argument( 'user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36') option.add_experimental_option('excludeSwitches', ['enable-automation']) # driver=webdriver.Edge("D:/edgedriver_win64/9.1/msedgedriver.exe",capabilities=dc,options=option) driver = Edge("D:/edgedriver_win64/9.1/msedgedriver.exe",options = option) re=get_url_response(url) try: get_medio(driver,get_page_url(re,start,stop),get_bookname(re)) except Exception as e: print(e,"5小时后还在被封") driver.close() print("第{}到第{}已经爬取完成".format(start,stop)) driver.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
注意:
这个脚本写的时间比较短,可能会有一些东西无法兼顾,比如防止被封禁的方法(我选择以降低速度来防止访问频繁被禁),其实可以做个代理ip池切换ip爬取。如果只是自己听小说我觉得应该够用了,建议晚上运行脚本,白天听。
觉得有帮助的朋友,能给个赞吗?求求了
本人原创,若要转载请私信通知即可
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/article/detail/55449
推荐阅读
相关标签

