
- 1Unity shader Reflect 取反问题_shader取相反
- 2vue脚手架在vue.config.js文件中配置scss全局变量_vue.config.js scss
- 3狂神说Docker进阶版_k8s 狂神
- 4ScheduledThreadPoolExecutor源码解读(二)——ScheduledFutureTask时间调度执行任务(延迟执行、周期性执行)_delayedexecute
- 5linux terminal 命令--chown&chgrp&chmod_terminal chmod
- 6后端开发实践:Spring Boot项目模板_springboot项目模板
- 7解读大模型的微调
- 8素数距离问题--以为存储素数表会更快,结果sqrt更快
- 9【Linux从入门到精通】Linux常用基础指令(上)
- 10为 Ubuntu22.04 系统添加中文输入法_ubuntu22.04中文输入法
python基础语法:数据类型_2、python的数据类型
赞
踩
数据来源参考:(135条消息) 数据类型-基础语法-CSDNPython入门技能树
python的数据类型分为基本数据类型和复合数据类型
基本数据类型包含:数字,字符串
复合数据类型包含:列表,元组,字典,集合
一,数字类型
数字类型就是用数字或数值表示的苏剧类型。
数字类型有:整型(int),浮点型(float),复数类型(complex)和布尔类型(bool)
tips:python可以用type()函数来查看变量的类型。
1.1 整数
整数一般使用二进制,八进制,十进制和十六进制表示。
整型不同形式的转换
- bin():十进制转换为二进制,输出形式是字符串
- oct():十进制转换为八进制,输出形式是字符串
- hex():十进制转换为十六进制,输出形式是字符串
- int() :接收一个符合整型规范的字符串,并将字符串转换为整型
tips1:Python中当多个变量的值相同时,这个值在内存中并没有被保存多次,只是多个变量都指向了同一内存
例如:
- a = 6
- b = 6
- c = a
- print(id(a),id(b),id(c))
-
- # 输出
- 1643146464 1643146464 1643146464
id()可以取出变量的内存地址,从结果可以看出,a,b,c三个变量都指向了同一内存。但如果修改了a的值,那a的内存地址和b,c的内存地址及值有什么变化呢?举例如下:
- a = 6
- b = 6
- c = a
- print(id(a), id(b), id(c))
- a = 8
- print(id(a), id(b), id(c))
结果:
- 1643146464 1643146464 1643146464
- 1643146528 1643146464 1643146464
从上面可以看出,a的地址变了,b,c的地址没有变。
数字时Python中的不可变对象,当改变它的值时,并不是真的修改内存中变量的值,而是把新的值放入内存中,然后修改变量,使得变量指向新值的内存地址。浮点数、复数等其他数字类型及其他类型的变量具有同样的特点。
tips: Python具有自动内存管理功能,如果一个值没有任何变量指向,则Python自动将其删除,因此,一般Python程序员不需要太多考虑内存管理的问题(这就是Python与C语言最大的区别,自动内存回收机制!),但显式使用del命令删除不再使用的值,仍然是一个优秀程序员需要具备的基本素养!
1.2,浮点数
浮点数就是小数
可以使用flaot()函数将其他类型转换为浮点型。
- a = 1.2
- print(type(a))
- b = 1e-2
- print(type(b))
- c = 2e3
- print(c)
-
输出:
- <class 'float'>
- <class 'float'>
- 2000.0
1.3 复数
- 复数由“实部”和“虚部”两部分组成;
- 实数部分和虚数部分都是浮点型;
- 虚数部分后面必须有j或J
Python中表示复数的两种方法:
- a+bj
- complex(a,b)
其中a表示实部,b表示虚部
举例:
- a = 2 + 6j
- print(type(a))
- b = complex(2, 6)
- print(type(b))
- print(id(a), id(b))
结果:
- <class 'complex'>
- <class 'complex'>
- 2718471372752 2718437554352
获取复数的实部、虚部、共轭复数等
- a = 2 + 6j
- print(a.imag) # .imag可以获取复数的虚部
- print(a.real) # .real可以获取复数的虚部
- print(a.conjugate()) # .conjugate()方法可以获取复数的共轭复数
结果:
- 6.0
- 2.0
- (2-6j)
1.4 布尔类型
- Python中的布尔类型只有True和False两个取值;
- True对应整数1,False对应整数0。
- 常用的布尔运算包括 and、or、not 三种
等同于False的值:
- None;
- False;
- 任何为0的数字类型,如0、0.0、0j;
- 任何空序列,如’‘’'、()、[];
- 空字典,如{};
- 用户定义的类实例,如类中定义了__bool__()或者__len__()方法,并且该方法返回0或者布尔值False。
等同于True的值:
- 非零数值
- 非空字符串
and和or运算有一条重要的法则:短路法则
and举例:
a and b ,如果a是False,则整个结果必定为False,因此返回a的值,如果a是True,则表达式的结果取决于b,因此返回b (只有两个同为True是才为True,其它都是False)
- a = 0
- b = 2
- print(a and b)
-
- a = 1
- b = 0
- print(a and b)
-
- a = 1
- b = 3
- print(a and b)
结果:
- 0
- 0
- 3
or举例:
a or b ,如果a是True,则整个结果必定为True,因此返回a的值,如果a是False,则表达式的结果取决于b,因此返回b (or是只有一个为True结果就为True)
- a = 0
- b = 2
- print(a or b)
-
- a = 1
- b = 0
- print(a or b)
-
- a = True
- print(a and 'z=T' or 'z=F')
- 2
- 1
- z=T
1.5 数值运算
常见的数值运算有:加、减、乘、除、取余、指数运算等
例如:a=2 ,b=8
例如:
- a=3
- b=6
- a+b #加法
- # 输出
- 9
-
- a-b #减法
- # 输出
- -3
-
- a*b #乘法
- # 输出
- 18
- a**2 # 指数运算 a的2次方
- # 输出
- 9
-
- a%b #取余
- # 输出
- 3

Python有两种除法:/ 和 ///:真除法//:整除法,向下取整
例如:
- a = 6
- b = 4
- print(a/b) # 浮点数的结果
- print(a//b) # 向下取整 只保留浮点数整数结果
-
- b = -4
- print(a/b)
- print(a//b)
-
结果:
- 1.5
- 1
- -1.5
- -2
1.6 数值计算函数库
Python内置了很多实用的数值函数,例如: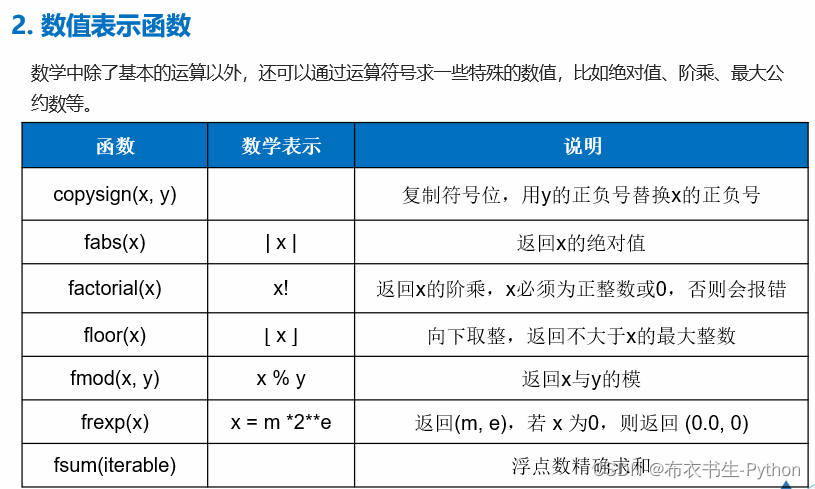
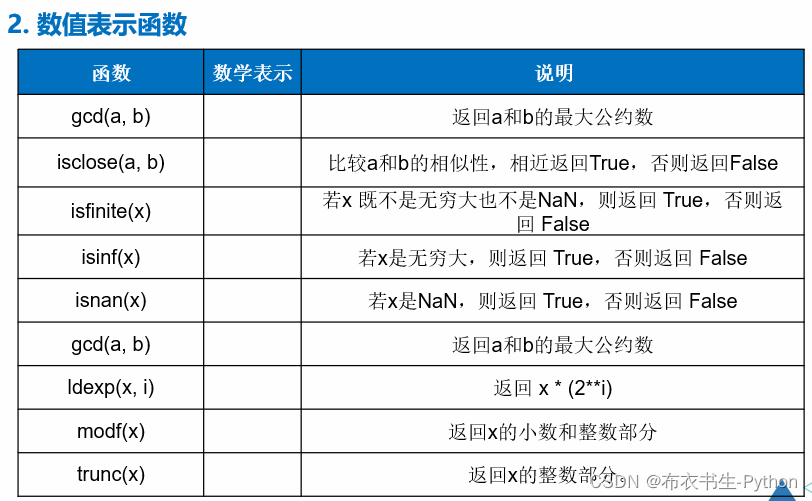
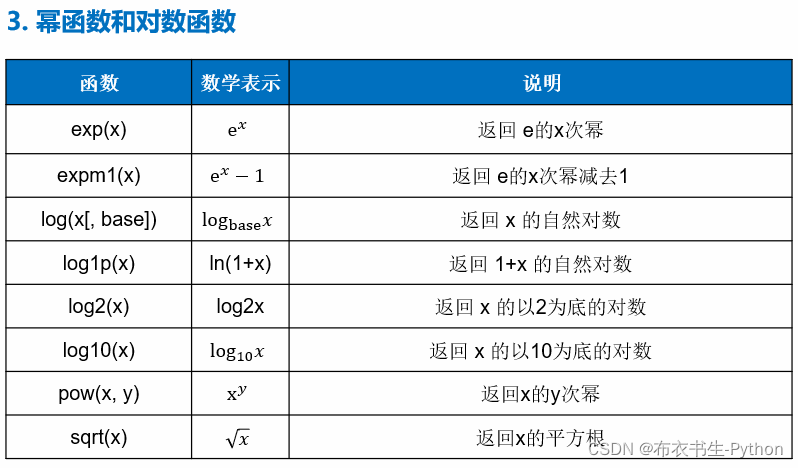
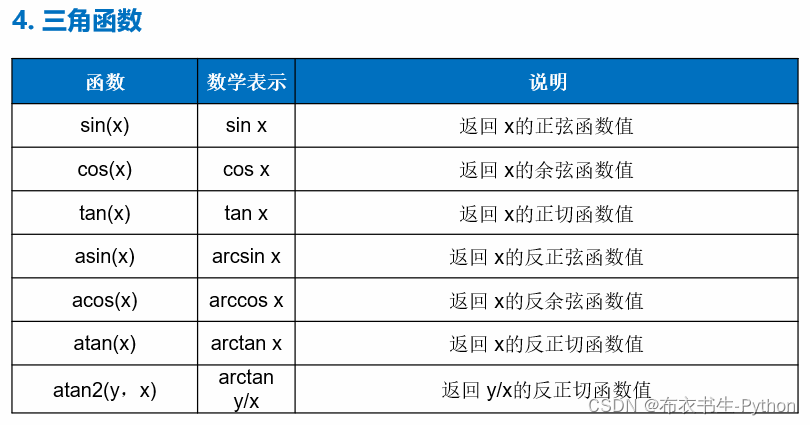
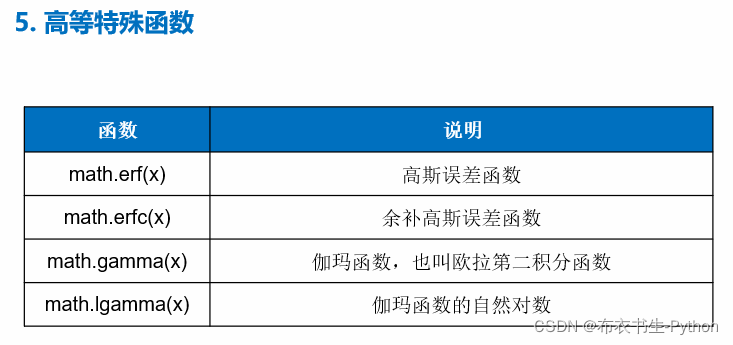
另外,还有随机数函数用途也是有很多的:random模块
- import random
-
- print(random.random()) # random.random()作用是生成一个[0-1]范围内的随机数
- print(random.randint(1, 2000)) # random.randint(a,b)作用是生成一个[a-b]范围内的随机整数
- 0.48771584654043476
- 58
1.7 type函数
type的用途是,当你不知道变量的数据类型时,可通过它来查询,type时内置函数,可以直接使用,不需要导包。
- a = 2
- b = -1.1
- c = "abc"
- d = ['a', 'b']
- print(type(a))
- print(type(b))
- print(type(c))
- print(type(d))
- <class 'int'>
- <class 'float'>
- <class 'str'>
- <class 'list'>
2 字符串类型
2.1 字符串表示
在python语言中,字符串的表示有以下三种:
- 单引号 ’
- 双引号 "
- 三重引号 """
2.1.1 单引号、双引号
在Python语言中,使用单引号(’ ')和双引号(" ")表示字符串是最常见的两种方式。
两种方式表示的字符串是等价的,且返回相同类型的对象,如下代码所示:

单引号和双引号表示字符串没有本质的区别,可以在一种引号中嵌套另一种引号。
单引号和双引号表示的字符串是等价的,要配对出现,不能混用。否则将引发语法错误。
2.1.2 三重引号
三重引号可以是三个单引号,也可以是三个双引号。这种方式表示的字符串也叫做块字符串。
三重引号是以三个同一种类型的引号开始,并以三个相同引号结束的字符串表示方式。
从上述代码中可以看出:
字符串变量spring的内容包含三行,以三个双引号开始和结束。从输出结果可以看到,字符串中出现了“\n”换行符。这是因为在每行结束时,都使用了回车并且换行到下一行
2.1.3 转义字符
Python语言使用反斜杠("\")表示转义字符。
转义字符是为了对其后紧接的字符进行转义,屏蔽其特殊含义,并将其作为普通字符来输出。

从代码中可以看出,需要在句子中显示一个特殊字符“ ’ ”,要用到转义字符\,才能正确输出。
下表中列出了一些常用的转义字符及其含义: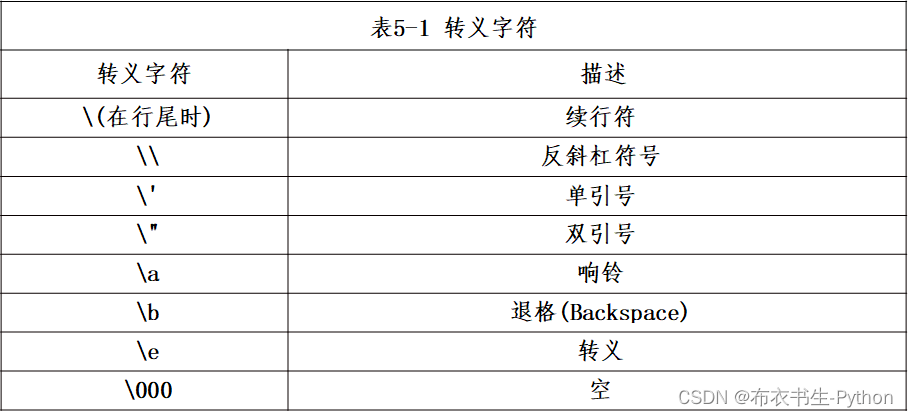
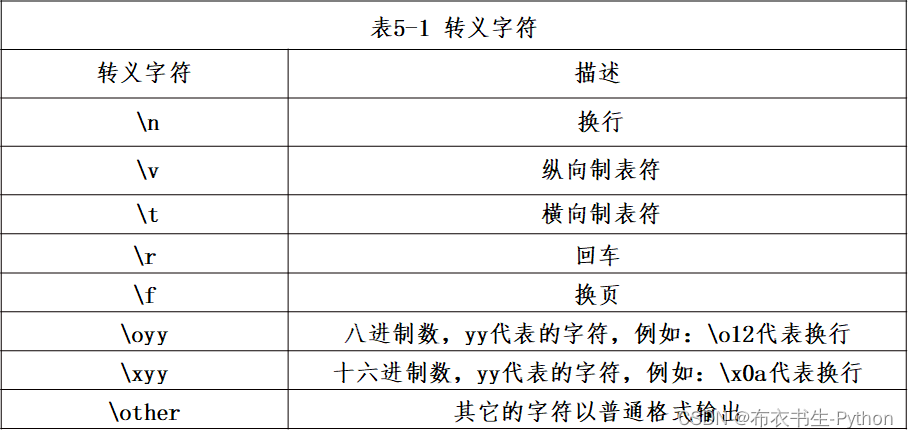
2.1.4 raw字符串
raw字符串的格式是r’…’。
在raw字符串中,所有的字符都是直接按照字面意思来解释,没有转义字符或者不能打印的字符。
看下面的例子:
- 第一种方式的语句打开一个文件时,字符“\n”会被当作回车键的转义字符,从而使文件打开失败。
- 第二种方式对反斜杠“\”进行转义,虽然正确,但是代码看起来会令人感到费解。
- 第三种就是pthon语言中的raw字符串。
2.2 字符串操作
Python语言中包含字符串的以下几个基本操作:
- 字符串的索引
- 字符串的分片
- 字符串的合并
- 重复字符串
- 其他操作
2.2.1 索引和分片
-
索引
在Python语言中,字符串是一个有序字符的集合。
在一个字符串被创建之后,其中字符的相对位置就固定了。第一个字符的索引编号定义为0,第二个字符索引编号为1,以此类推。在Python语言中,对字符串可以进行正向索引和反向索引。
下表直观表示了字符串中字符和其索引编号的对应关系:

上表中,中间行表示的是字符串中的每个字符内容,上面行表示该字符串正向索引时的索引编号,下面行表示该字符串反向索引时的索引编号。索引是对单个元素进行的操作,Python语言中字符串的索引是通过元素下标进行索引的。
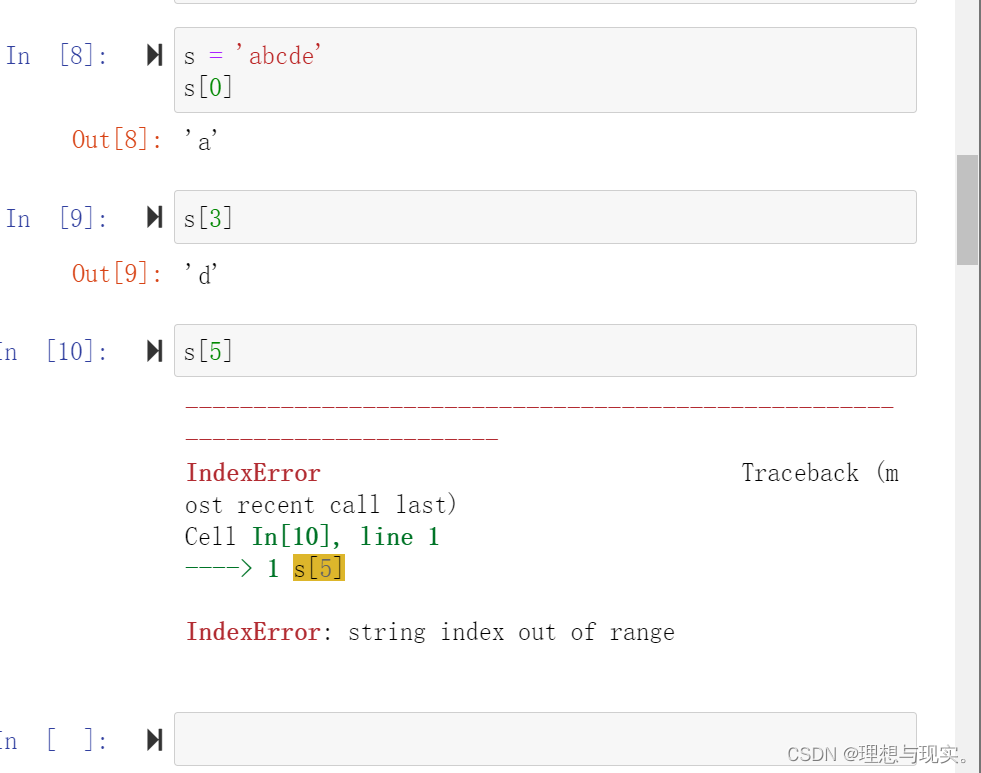
上述代码中,当通过下标5索引元素时,出现了下标越界的错误。因为字符串s的下标最大是4(从0开始)。 -
切片
使用Python语言的分片(slice)操作,来提取字符串中的子序列。
代码中:s[1:3]获取s中下标从1到3的子字符串;s[1:] 获取从下标为1到字符串末尾的元素;s[:-1]获取从开始开始到字符串末尾的元素。s[::2]下标从0开始,每隔一个字符取一个元素;s[::-1]实现对字符串的逆序操作。
2.2.2 连接字符串
字符串的连接就是把两个或多个字符串连接成一个字符串。
在连接字符串时,Python语言会为每个连接的字符串及新产生的字符串分配内存,增大不必要的内存开销。
- 操作符(“+”) 方法:

- Python语言使用符串格式化操作符(%)和join()方法这两种方式连接字符串。
操作符(%) 方法:
join()方法:
2.2.3 修改字符串
在Python语言中,字符串属于不可变类型,不能修改或删除原字符串中的字符。
通过加号的连接方式:
通过对原字符串切片再连接方式:
replace()函数来修改字符串:
replace()函数的功能是字符替换,如果要替换的源字符或字符串存在,且和待替换的目标字符或字符串不同,则返回值为重新创建的一个字符串对象;否则,返回原字符串对象。
代码中用replace()函数把字符串s中的’p’替换为’C’。

2.2.4 其他操作
通过帮助函数可以查看字符串对象的操作方法。这些方法可以通过object.attribute的方式调用。
上述列表中的方法都是可以直接调用的字符串操作方法,其中包含了上节提到的replace()方法。
2.3 字符串格式化
字符串格式化是对字符串的输出形式进行控制,使其按照开发者期望的方式输出。
进行字符串格式化的方法主要分为三种:
- 符号格式化
- 函数格式化
- 字典格式化
2.3.1 符号格式化
符号格式化主要是使用“%+格式化符号”,及相应的格式化辅助符号的方式对字符串进行格式化。
常用的字符串格式化符号如下表所示: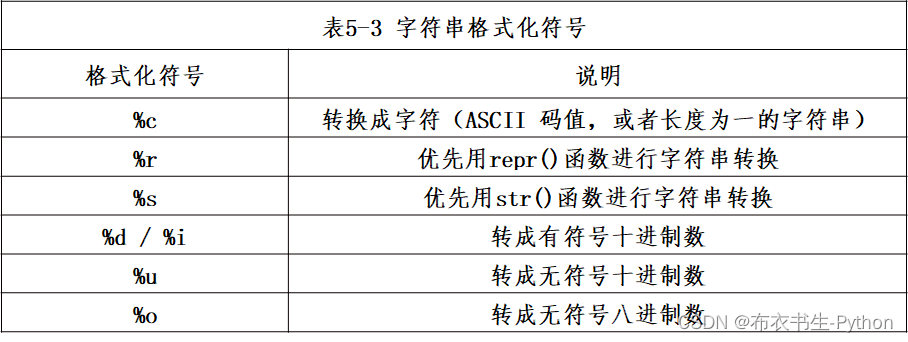
举例:
- print("%c,%c" % (65, 97))
- s = 'podjsd'
- print("%s" % (s))
- print('%r'%42)
- print('%e'%200.21)
- print('%g'%200.21)
- print('%%'%())
结果:
- A,a
- podjsd
- 42
- 2.002100e+02
- 200.21
- %
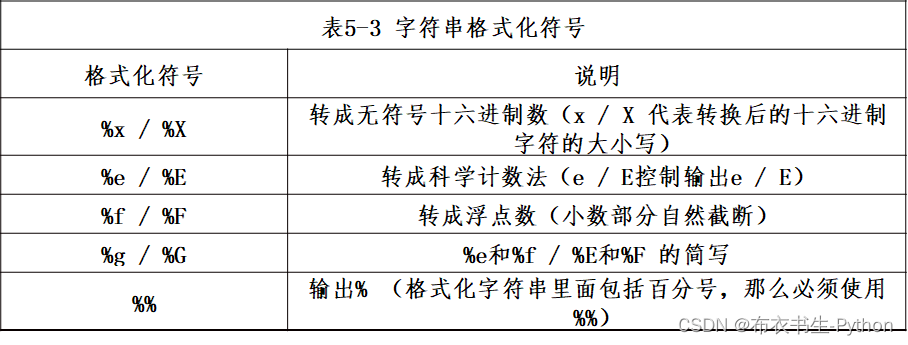
常用格式化辅助符号如表5-4所示: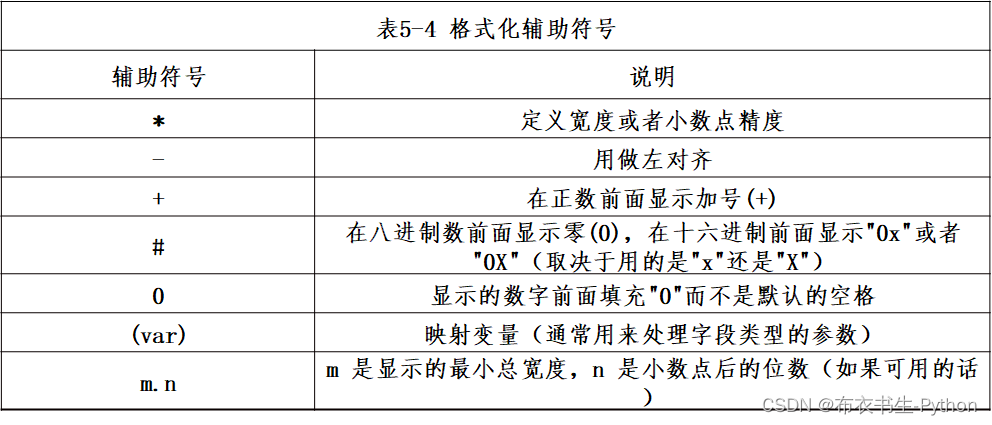
- print('%5.2f'%(3.4))
- print('%+d'%(4))
结果:
- 3.40
- +4
2.3.2 函数格式化
format()方法对字符串进行格式化操作,format()方法常用的匹配方法有三种:
- 不带编号,即“{}”;
- 带数字编号,可调换顺序,如“{0}”、“{1}”等;
- 带关键字,如“{name}”、“{age}”等。
例如:
- print("a={},b={}".format(2, 4))
- print("a={0},b={1}".format(2, 4))
- print("a={1},b={0}".format(2, 4))
- print("a={num2},b={num3}".format(num2=2, num3=4))
- print("a={num3},b={num2}".format(num2=2, num3=4))
结果:
- a=2,b=4
- a=2,b=4
- a=4,b=2
- a=2,b=4
- a=4,b=2
以下表格对常用的格式化输出形式予以介绍: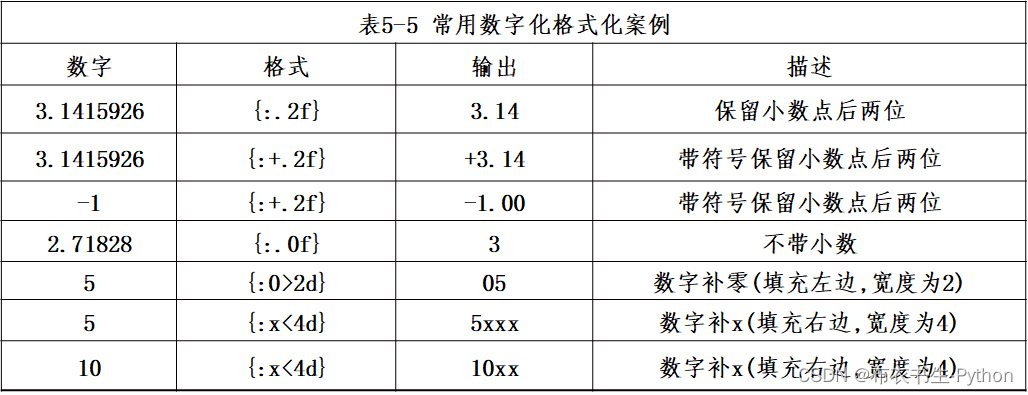
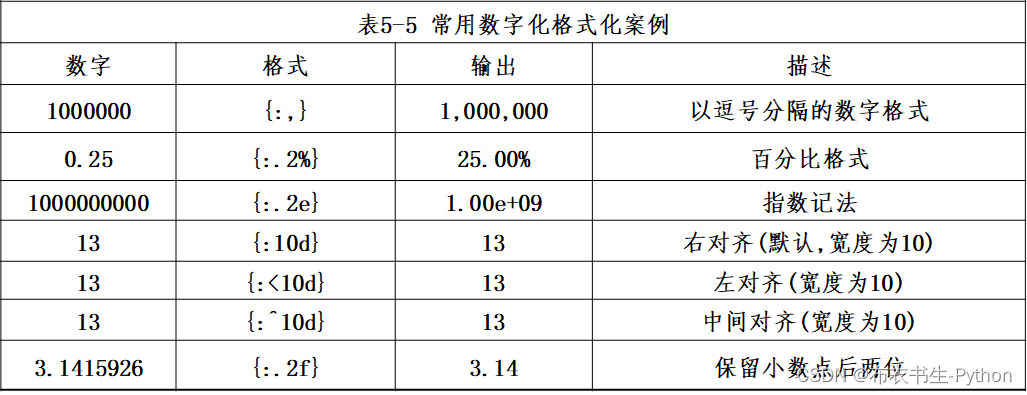
2.3.3 字典格式化
在Python语言中,字典格式化是在左边的格式化字符串通过引用右边字典中的键来提取对应的值,实现格式化输出。
print("%(name)s,%(age)s" % {"name": "hupo", "age": 18})
结果:
hupo,18
需要注意的是括号外的s别忘了:“%(name)s,%(age)s”
3 复合数据类型
3.1 List(列表)
3.1.1 列表的创建
创建列表:变量名 = [元素1,元素2,…,元素n]
list类型中区分元素的顺序,且允许包含重复的元素。
3.1.2 基本操作
1. 索引
列表每一个元素都对应一个整数型的索引值,可以通过索引值来得到相应的元素值。同时支持列表元素的正向索引和反向索引。
正向索引即索引值为正,从0开始;
反向索引即索引值为负,从-1开始。若是反向索引,则-1为末尾元素对应的索引编号。
2. 切片
切片操作可以截取列表变量中的部分元素,并返回一个子列表变量。
切片操作中,生成子列表的元素包含起始索引对应的元素,但是不包含终止索引对应的元素。
3. 加法和乘法
- 加法操作使用加号(+)完成,表示把加号两端的列表变量连接形成一个新列表;
- 乘法操作使用星号(*)完成,表示对当前列表对象进行复制并连接,并形成一个新列表。
4. 修改和删除
- 通过索引值对相应元素进行修改或删除。
- 删除整个列表或列表中的部分元素,使用del命令。删除整个列表后,不可再次引用。
5. 追加插入和扩展
- append:在当前列表对象尾部追加元素;
- insert:在当前列表的指定索引位置插入元素;
- extend:对当前列表元素进行批量增加。
3.1.3 多维列表
创建三个列表类型的变量a、n和x。其中,变量a和n中元素都是基本类型,变量x中的元素都是列表类型。
- >>> a = ['a',1]
- >>> n = ['b',2]
- >>> x = [a,n]
- >>> x
- [['a',1],['b',2]]
- >>> x[0] # 显示第一个元素
- ['a', 1]
- >>> x[0][1] # 显示第一个元素中的第二个元素
- 1
直接输入列表的数据,系统会根据输入生成相应的列表维度。
- >>>l = [[1,2,3],[4,5,6]]
- >>>print(l)
- 输出结果:
- [
- [1,2,3],
- [4,5,6]
- ]
也可以使用列表解析方式生成了二维矩阵
- cols = 7
- rows = 9
- list_2d = [[col + 1 for col in range(cols)] for row in range(rows)]
- print(list_2d)
-
3.1.4 迭代器
首先创建了一个列表类型变量lst,然后创建了该列表的迭代器对象lstiter,并且通过该迭代器对象的__next__()方法遍历列表中的元素。__next__()方法,返回下一个值。iter方法访问列表。
3.1.5 列表解析
- >>>list=[1,2,3,4,5,6,7,8,9,10] #方法1:直接指定
- >>>list=[]#方法2:先创建一个空列表,然后通过for循环实现
- for n in range(1,11):
- list.append(n);
- >>>list(range(1,11)) #方法3:列表解析
- [1,2,3,4,5,6,7,8,9,10]
for循环在这里可以很好的生成list
首先针对数值运算,使用列表解析生成了1到10的平方值;
其次,针对字符运算,使用列表解析生成了指定范围的字母组合列表。
- >>> [x * x for x in range(1, 11)]
- [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
-
- # 或者字母所进行的两层循环
- >>> [m + n for m in 'ABC' for n in 'XYZ']
- ['AX', 'AY', 'AZ', 'BX', 'BY', 'BZ', 'CX', 'CY', 'CZ']
3.1.6 列表函数和方法

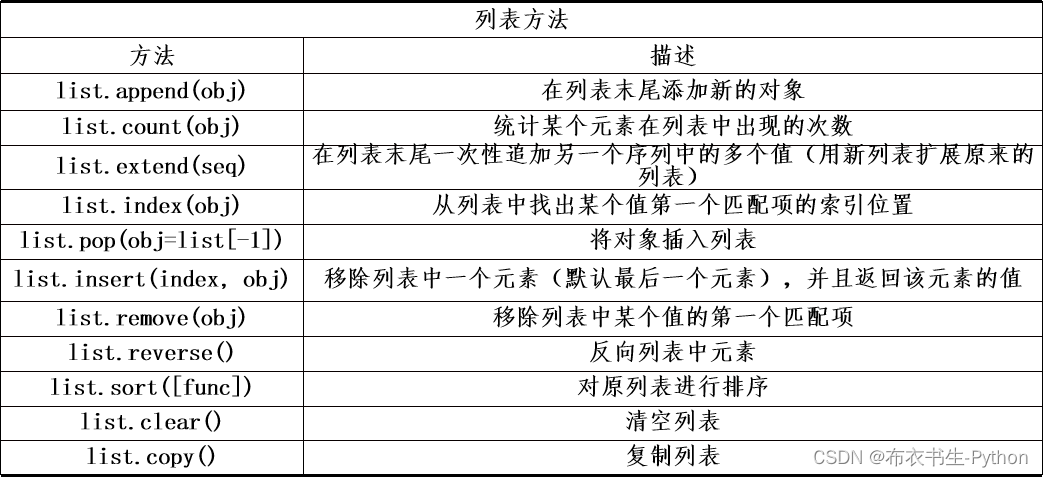
3.2 tuple(元组)
3.2.1 元组的创建
创建元组:变量名 = (元素1,元素2,…,元素n)
注意:
当元组中只包含一个元素时,需要在元素后面添加逗号,否则括号会被当作运算符使用。
3.2.2 基本操作
1. 访问
使用下标索引来访问相应的元素值。也可采用正向索引和反向索引两种方式,并支持切片操作。
2. 修改
元组中的元素值是不允许修改的,可以对元组进行连接生成新的元组。
3. 删除
元素值不允许删除的,但可使用del语句删除整个元组。
需要注意的是,删除后的元组对象不可再次引用。
4. 统计
通过内置的count方法统计某个元素出现的次数。
5. 查找
通过内置的index方法查找某个元素首次出现的索引位置。
3.2.3 元组函数和方法
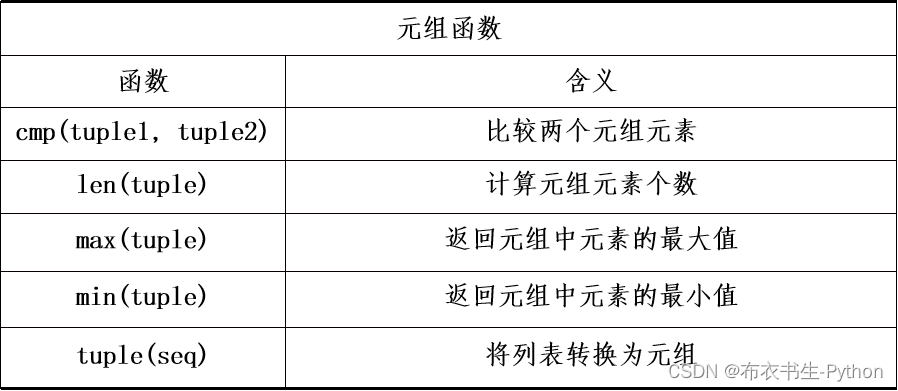
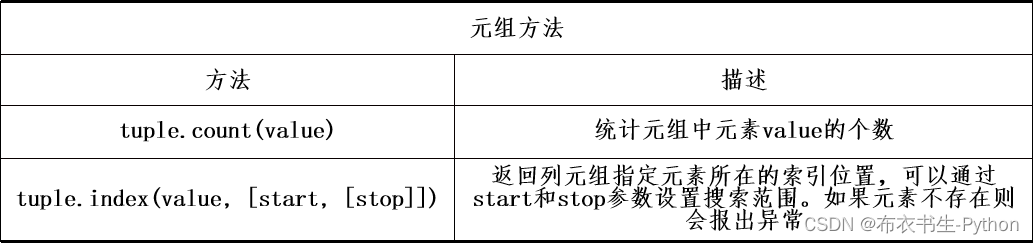
表中的count方法和index方法,实际是元组类型和列表类型所共有的方法,其使用方法和列表完全相同。
3.2.4 元组的优势
- 可以使函数返回多个值
- 可以使程序运行性能提升
- 一般来说,创建元组类型tuple的变量比列表类型list要快,而且占用更小的存储空间。
- 使用元组是线程安全的
- 元组类型变量的元素不可更改性,可保证多线程读写时的安全问题。
3.3 dict(字典)
3.3.1 字典的创建
创建字典对象:变量名=(key1:value1, key2:value2,…, keyn:valuen)
- 字典的元素是可变的,可以是列表、元组、字典等任意数据类型,但键(key)值必须使用不可变类型。
- 在同一个字典变量中,键(key) 值必须是唯一的。
3.3.2 基本操作
1. 访问
字典是无序的,没有索引,不能通过下标索引。通过对key值的索引进行访问。
2. 修改
通过对key值的引用对value值的修改操作。
3. 删除
字典的删除操作中,可以删除某个元素或删除整个字典,也可以清空字典元素。.
3.3.3 字典的嵌套
- >>>Va1 = {a:{b:1,c:2},d:{e:3,f:4}} #字典的value值是字典
- >>>Va2 = {a:[1,2,3],b:[4,5,6]} #字典的value值是序列
- >>>n1={'surname':'wang','name':'gang'}
- >>>n2={'surname':'zhang','name':'san'}
- >>>n3={'surname':'liu','name':'wen'}
- >>>n4=[n1,n2,n3] #序列的元素是字典
n1、n2、n3是字典类型的变量,n4是列表类型变量,且n4中的元素即为n1、n2、n3。
3.3.4 字典的遍历
- username={'full_name':'ZhangWei', 'surname':'Zhang', 'name':'Wei' }
- #遍历所有的键-值对
- for k,v in username.items():
- print('key:'+k)
- print('value:'+v+'\n')
- #遍历所有键
- for k in username.keys():
- print(k)
- print('key:'+k+'-value:'+username[k])
- #遍历所有的值
- for v in username.values():
- print(v)
3.3.5 字典函数和方法

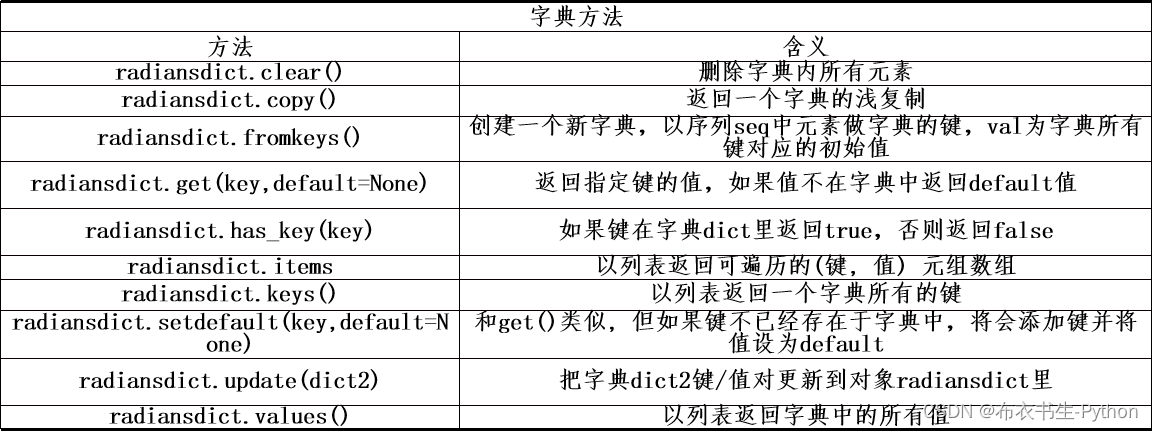
3.4 set(集合)
3.4.1 集合的创建
创建集合对象:变量名 = {元素1,元素2,…,元素n}
集合特性:
- 无序性:元素之间没有确定的顺序。
- 互异性:不会出现重复的元素。
- 确定性:元素和集合只有属于或不属于的关系。
注意:
创建空集合用set();
{}创建一个空字典。
3.4.2 集合的数学运算
数学运算后依然保持集合的特性,没有重复的元素
3.4.3 基本操作
1. 更改
- add():添加一个元素
- update():同时添加多个元素。
2. 删除
- discard() 和 remove() 方法删除集合中特定的元素。
- 若删除的对象不存在,remove()方法会引起错误,discard()方法不会。
3.4.4 不可变集合

3.4.5 集合函数和方法

提交参考资料,P



