
- 1【简记】virt-manager查看虚拟机详情出现报错:启动详情报错:‘NoneType’ object has no attribute ‘change_run_text‘_qemu/kvm未连接
- 2学习rtthread个人感觉_rtt 系统用的人多吗
- 3简单好玩的编程代码python,python好玩又简单的代码_简单编程代码
- 4Qt For Android 开发环境配置
- 5《WEB应用开发》复习题(二)_a、web窗体页的程序的逻辑由代码组成,这些代码的创建用于与窗体交互。编程逻
- 6基于docker-compose搭建Elasticsearch集群_ulimits: memlock: soft: -1 hard: -1
- 7永兴的笔记-OpenCV-11模版匹配 (python)_min_val max_val
- 8Pycharm中配置环境变量(包含Django Server和 celery)_pycharm django celery
- 9Codeforces Rating计算规则
- 10Pycharm的设置和基本使用1_pycharm 管理ide设置
基于SMO的支持向量机的Python实现并用于新闻文本分类_smo python
赞
踩
一、SMO算法


二、支持向量机的实现
- # SVM的实现
- import numpy as np
- import random
- import copy
- import math
- import time
-
- """
- 函数说明: 计算核函数的值
- Parameters:
- train_x - 训练集数据
- sample_x - 训练集中的样本
- kernelOpt - 选择的核函数(可选linear(线性核函数)或rbf(径向核函数))以及rbf核函数的参数(linear时该参数为0)
- Returns:
- kernelValue - 核函数的值
- """
- def calcuKernelValue(train_x, sample_x, kernelOpt = ("linear", 0)):
- kernelType = kernelOpt[0]
- kernelPara = kernelOpt[1]
- numSamples = np.shape(train_x)[0]
- kernelValue = np.mat(np.zeros((numSamples, 1)))
- if kernelType == "linear":
- kernelValue = train_x * sample_x.T
- elif kernelOpt[0] == "rbf":
- sigma = kernelPara
- for i in range(numSamples):
- diff = train_x[i, :] - sample_x
- kernelValue[i] = math.exp(diff * diff.T / (-2 * sigma ** 2))
- else:
- print("The kernel is not supported")
- return kernelValue
-
-
- """
- 函数说明: 核函数求内积
- Parameters:
- train_x - 训练集数据
- kernelOpt - 选择的核函数(可选linear(线性核函数)或rbf(径向核函数))以及rbf核函数的参数(linear时该参数为0)
- Returns:
- kernealMat - 核函数的内积
- """
- def calcKernelMat(train_x, kernelOpt):
- numSamples = np.shape(train_x)[0]
- kernealMat = np.mat(np.zeros((numSamples, numSamples)))
- for i in range(numSamples):
- kernealMat[:, i] = calcuKernelValue(train_x, train_x[i], kernelOpt)
- return kernealMat
-
-
- """
- 函数说明: 定义存储SVM参数和数据的结构体
- Parameters:
- trainX - 训练集数据
- trainY - 训练集标签
- c - 惩罚参数
- tolerance - 容错率
- maxIteration - 最大迭代次数
- kernelOption - 选择的核函数(可选linear(线性核函数)或rbf(径向核函数))以及rbf核函数的参数(linear时该参数为0)
- """
- class svmSruct(object):
- def __init__(self, trainX, trainY, c, tolerance, maxIteration, kernelOption):
- self.train_x = trainX
- self.train_y = trainY
- self.C = c
- self.toler = tolerance
- self.maxIter = maxIteration
- self.numSamples = np.shape(trainX)[0] #数据集的行数(样本数)
- self.alphas = np.mat(np.zeros((self.numSamples, 1))) # alpha系数,numSamples*1矩阵
- self.b = 0 #偏置项
- self.errorCache = np.mat(np.zeros((self.numSamples, 2))) # 保存原始数据每行的预测误差
- self.kernelOpt = kernelOption
- self.kernelMat = calcKernelMat(self.train_x, self.kernelOpt)
-
- """
- 函数说明: 计算原始数据第alpha_i项对应的预测误差
- Parameters:
- svm - SVM参数的结构体
- alpha_i - 原始数据行索引
- Returns:
- erro_i - 原始数据第alpha_i项对应的预测误差
- """
- def calcError(svm, alpha_i):
- func_i = np.multiply(svm.alphas, svm.train_y).T * svm.kernelMat[:, alpha_i] + svm.b
- erro_i = func_i - svm.train_y[alpha_i]
- return erro_i
-
- """
- 函数说明: 计算原始数据第alpha_j项对应的预测误差并更新结构体中的缓存
- Parameters:
- svm - SVM参数的结构体
- alpha_j - 原始数据行索引
- """
- def updateError(svm, alpha_j):
- error = calcError(svm, alpha_j)
- svm.errorCache[alpha_j] = [1, error]
-
- """
- 函数说明: 选取一对 alpha_i 和 alpha_j,使用启发式方法
- Parameters:
- svm - SVM参数的结构体
- alpha_i - 原始数据行索引
- error_i - 原始数据第alpha_i项对应的预测误差
- Returns:
- alpha_i 和 alpha_j
- """
- def selectAlpha_j(svm, alpha_i, error_i):
- svm.errorCache[alpha_i] = [1, error_i]
- alpha_index = np.nonzero(svm.errorCache[:, 0])[0]
- maxstep = float("-inf")
- alpha_j, error_j = 0, 0
- if len(alpha_index) > 1:
- # 遍历选择最大化 |error_i - error_j| 的 alpha_j
- for alpha_k in alpha_index:
- if alpha_k == alpha_i:
- continue
- error_k = calcError(svm, alpha_k)
- if abs(error_i - error_k) > maxstep:
- maxstep = abs(error_i - error_k)
- alpha_j = alpha_k
- error_j = error_k
- else:
- # 最后一个样本,与之配对的 alpha_j采用随机选择
- alpha_j = alpha_i
- random.seed(38)
- while alpha_j == alpha_i:
- alpha_j = random.randint(0, svm.numSamples - 1)
- error_j = calcError(svm, alpha_j)
- return alpha_j, error_j
-
-
- """
- 函数说明: 内循环,优化 alpha_i 和 alpha_j
- Parameters:
- svm - SVM参数的结构体
- alpha_i - 原始数据行索引
- """
- def innerLoop(svm, alpha_i):
- #计算误差error_i
- error_i = calcError(svm, alpha_i)
- error_i_ago = copy.deepcopy(error_i)
- #优化alpha,设定一定的容错率。
- if (svm.train_y[alpha_i] * error_i < -svm.toler and svm.alphas[alpha_i] < svm.C) or \
- (svm.train_y[alpha_i] * error_i > svm.toler and svm.alphas[alpha_i] > 0):
- # 步骤1:使用内循环启发方式选择aplha_j,并计算alpha_j
- alpha_j, error_j = selectAlpha_j(svm, alpha_i, error_i)
- alpha_i_ago = copy.deepcopy(svm.alphas[alpha_i])
- alpha_j_ago = copy.deepcopy(svm.alphas[alpha_j])
- error_j_ago = copy.deepcopy(error_j)
- #步骤2:计算上下界L和H
- if svm.train_y[alpha_i] != svm.train_y[alpha_j]:
- L = max(0, svm.alphas[alpha_j] - svm.alphas[alpha_i])
- H = min(svm.C, svm.C + svm.alphas[alpha_j] - svm.alphas[alpha_i])
- else:
- L = max(0, svm.alphas[alpha_j] + svm.alphas[alpha_i] - svm.C)
- H = min(svm.C, svm.alphas[alpha_j] + svm.alphas[alpha_i])
- if L == H:
- return 0
- #步骤3:计算eta(i和j的相似性)
- eta = 2.0 * svm.kernelMat[alpha_i, alpha_j] - svm.kernelMat[alpha_i, alpha_i] - \
- svm.kernelMat[alpha_j, alpha_j]
-
- # 步骤4:更新aplha_j
- svm.alphas[alpha_j] = alpha_j_ago - svm.train_y[alpha_j] * (error_i - error_j) / eta
-
- #步骤5:修剪aplha_j
- if svm.alphas[alpha_j] > H:
- svm.alphas[alpha_j] = H
- elif svm.alphas[alpha_j] < L:
- svm.alphas[alpha_j] = L
-
- #步骤6:优化alpha_j后更新alpha_i
- svm.alphas[alpha_i] = alpha_i_ago + svm.train_y[alpha_i] * svm.train_y[alpha_j] * \
- (alpha_j_ago - svm.alphas[alpha_j])
- #步骤7:如果alpha_j不再变化,就返回
- if abs(alpha_j_ago - svm.alphas[alpha_j]) < 10 ** (-5):
- return 0
-
- # 步骤8:更新 b
- b1 = svm.b - error_i_ago - svm.train_y[alpha_i] * (svm.alphas[alpha_i] - alpha_i_ago) * \
- svm.kernelMat[alpha_i, alpha_i] - svm.train_y[alpha_j] * (svm.alphas[alpha_j] - alpha_j_ago) * \
- svm.kernelMat[alpha_i, alpha_j]
- b2 = svm.b - error_j_ago - svm.train_y[alpha_i] * (svm.alphas[alpha_i] - alpha_i_ago) * \
- svm.kernelMat[alpha_i, alpha_j] - svm.train_y[alpha_j] * (svm.alphas[alpha_j] - alpha_j_ago) * \
- svm.kernelMat[alpha_j, alpha_j]
- if (svm.alphas[alpha_i] > 0) and (svm.alphas[alpha_i] < svm.C):
- svm.b = b1
- elif (svm.alphas[alpha_j] > 0) and (svm.alphas[alpha_j] < svm.C):
- svm.b = b2
- else:
- svm.b = (b1 + b2) / 2
-
- # 步骤9:优化alpha_i、alpha_j、b 之后再更新误差
- updateError(svm, alpha_j)
- updateError(svm, alpha_i)
-
- return 1
- else:
- return 0
-
- """
- 函数说明: 训练SVM
- Parameters:
- train_x - 训练集数据
- train_y - 训练集标签
- c - 惩罚参数
- toler - 容错率
- maxIter - 最大迭代次数
- kernelOpt - 选择的核函数(可选linear(线性核函数)或rbf(径向核函数))以及rbf核函数的参数(linear时该参数为0)
- Returns:
- svm - 训练好的SVM参数的结构体
- """
- def trainSVM(train_x, train_y, c, toler, maxIter, kernelOpt):
- train_start = time.time()
- svm = svmSruct(train_x, train_y, c, toler, maxIter, kernelOpt)
- entire = True
- alphaPairsChanged = 0
- iter = 0
- while (iter < svm.maxIter) and ((alphaPairsChanged > 0) or entire):
- alphaPairsChanged = 0
- if entire:
- for i in range(svm.numSamples):
- alphaPairsChanged += innerLoop(svm, i)
- print("\tIter = %d, entire set, alpha2 changed = %d" % (iter, alphaPairsChanged))
- iter += 1
- else:
- nonBound_index = np.nonzero((svm.alphas.A > 0) * (svm.alphas.A < svm.C))[0]
- for i in nonBound_index:
- alphaPairsChanged += innerLoop(svm, i)
- print("\tIter = %d, non boundary, alpha2 changed = %d" % (iter, alphaPairsChanged))
- iter += 1
- if entire:
- entire = False
- elif alphaPairsChanged == 0:
- entire = True
- train_end = time.time()
- print("\tnumVector VS numSamples == %d -- %d" % (len(np.nonzero(svm.alphas.A > 0)[0]), svm.numSamples))
- print("\tTraining complete! ---------------- %.3fs" % (train_end - train_start))
- return svm
-
- """
- 函数说明: 测试样本
- Parameters:
- svm - 训练好的SVM参数的结构体
- test_x - 测试集数据
- test_y - 测试集标签
- Returns:
- accuracy - 预测准确率
- labelpredict - 预测的标签
- numright - 预测为负类正确的个数
- """
- def testSVM(svm, test_x, test_y):
- numTest = np.shape(test_x)[0]
- supportVect_index = np.nonzero(svm.alphas.A > 0)[0]
- supportVect = svm.train_x[supportVect_index]
- supportLabels = svm.train_y[supportVect_index]
- supportAlphas = svm.alphas[supportVect_index]
- num = 0
- numright = 0
- labelpredict = []
- for i in range(numTest):
- kernelValue = calcuKernelValue(supportVect, test_x[i, :], svm.kernelOpt)
- predict = kernelValue.T * np.multiply(supportLabels, supportAlphas) + svm.b
- labelpredict.append(int(np.sign(predict)))
- if np.sign(predict) == np.sign(test_y[i]):
- num += 1
- if np.sign(test_y[i]) == -1:
- numright += 1
- print("\tnumRight VS numTest == %d -- %d" % (num, numTest))
- accuracy = num / numTest
- return accuracy, labelpredict, numright

三、新闻文本数据集fetch_20newsgroups介绍
fetch_20newsgroups(20类新闻文本)数据集是用于文本分类、文本挖据和信息检索研究的国际标准数据集之一。该数据集中含有18846篇新闻文章,均匀分为20种不同主题类别的新闻组集合,每个类别包含将近1000篇新闻文章。该数据集是典型的单标签、平衡文本数据集。
该数据集分为训练集和测试集两部分。其中训练集含有11314条新闻文本数据,测试集含有7532条新闻文本数据。
该数据集的20类标签如下图所示。

四、基于支持向量机的新闻文本分类
1.数据预处理
本文仅导入数据集中的三类数据。
通过调用Python中的sklearn库的TfidfVectorizer模型来将数据集中的文本数据转化成TF-IDF特征向量并去除停用词。
TF-IDF ( term frequency–inverse document frequency ) 又称词频-逆文本频率,是衡量一个词语重要程度的统计指标。相比于词频方法, TF-IDF 还综合考虑词语的稀有程度。在TF-IDF 算法中,一个词语的重要程度除了正比于在文本中的频次,还反比于有多少文本包含它。
- # 导入数据并数据预处理
- from sklearn.feature_extraction.text import TfidfVectorizer # TF-IDF模型提取特征向量
- from sklearn.datasets import fetch_20newsgroups # 导入数据集
-
- categories = ['alt.atheism', 'soc.religion.christian', 'comp.graphics']
-
- news_train = fetch_20newsgroups(subset='train', categories=categories, random_state=12) # 训练集数据
- news_test = fetch_20newsgroups(subset='test', categories=categories, random_state=12) # 测试集数据
-
- # 提取TF-IDF特征并去除停用词
- vectorizer = TfidfVectorizer(analyzer='word', stop_words='english')
- vectors = vectorizer.fit_transform(news_train.data)
- vectors_test = vectorizer.transform(news_test.data)
-
- traindataMat = vectors.todense() # 处理后的训练集数据
- testdataMat = vectors_test.todense() # 处理后的测试集数据
-
- trainlabelMat = np.mat(news_train.target).T # 训练集原始标签
- testlabelMat = np.mat(news_test.target).T # 测试集原始标签
2.新闻文本二分类
(1)数据导入与预处理
- # 导入数据并数据预处理
- from sklearn.feature_extraction.text import TfidfVectorizer # TF-IDF模型提取特征向量
- from sklearn.datasets import fetch_20newsgroups # 导入数据集
-
- categories = ['alt.atheism', 'soc.religion.christian']
-
- news = fetch_20newsgroups(subset='all') # 所有文本数据
- news_train = fetch_20newsgroups(subset='train', categories=categories, random_state=12) # 训练集数据
- news_test = fetch_20newsgroups(subset='test', categories=categories, random_state=12) # 测试集数据
-
- # 提取TF-IDF特征并去除停用词
- vectorizer = TfidfVectorizer(analyzer='word', stop_words='english')
- vectors = vectorizer.fit_transform(news_train.data)
- vectors_test = vectorizer.transform(news_test.data)
-
- traindataMat = vectors.todense() # 处理后的训练集数据
- testdataMat = vectors_test.todense() # 处理后的测试集数据
-
- trainlabel = []
- for i in range(len(news_train.target)):
- if news_train.target[i] == 0: # 标签分为-1和1
- trainlabel.append(-1)
- else:
- trainlabel.append(1)
- trainlabelMat = np.mat(trainlabel).T # 训练集标签
-
- testlabel = []
- for i in range(len(news_test.target)):
- if news_test.target[i] == 0: # 标签分为-1和1
- testlabel.append(-1)
- else:
- testlabel.append(1)
- testlabelMat = np.mat(testlabel).T # 测试集标签
(2)SVM模型的训练与测试
径向核函数的情形:
- # SVM参数
- C = 200 # 惩罚参数
- toler = 0.0001 # 容错率
- maxIter = 100 # 最大迭代次数
- kernelOption = ("rbf", 10) #核函数
-
- # 训练SVM
- svmClassifier = trainSVM(traindataMat, trainlabelMat, C, toler, maxIter, kernelOption)
-
- # 测试SVM
- accuracy, labelpredict, numright = testSVM(svmClassifier, testdataMat, testlabelMat)
- print(accuracy)
运行结果:在测试集上的分类准确率约为95.40%

线性核函数的情形:
- # SVM参数
- C = 200 # 惩罚参数
- toler = 0.0001 # 容错率
- maxIter = 100 # 最大迭代次数
- kernelOption = ("linear", 0) # 核函数
-
- # 训练SVM
- svmClassifier = trainSVM(traindataMat, trainlabelMat, C, toler, maxIter, kernelOption)
-
- # 测试SVM
- accuracy, labelpredict, numright = testSVM(svmClassifier, testdataMat, testlabelMat)
- print(accuracy)
运行结果:在测试集上的分类准确率约为94.98%

3.新闻文本三分类
(1)数据导入与预处理
- # 导入数据并数据预处理
- from sklearn.feature_extraction.text import TfidfVectorizer # TF-IDF模型提取特征向量
- from sklearn.datasets import fetch_20newsgroups # 导入数据集
-
- categories = ['alt.atheism', 'soc.religion.christian', 'comp.graphics']
-
- news_train = fetch_20newsgroups(subset='train', categories=categories, random_state=12) # 训练集数据
- news_test = fetch_20newsgroups(subset='test', categories=categories, random_state=12) # 测试集数据
-
- # 提取TF-IDF特征并去除停用词
- vectorizer = TfidfVectorizer(analyzer='word', stop_words='english')
- vectors = vectorizer.fit_transform(news_train.data)
- vectors_test = vectorizer.transform(news_test.data)
-
- traindataMat = vectors.todense() # 处理后的训练集数据
- testdataMat = vectors_test.todense() # 处理后的测试集数据
-
- trainlabelMat = np.mat(news_train.target).T # 训练集原始标签
- testlabelMat = np.mat(news_test.target).T # 测试集原始标签
(2)SVM模型的训练与测试
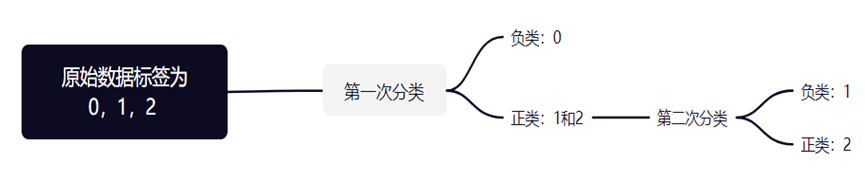
原始数据集的标签为0,1,2,由于一个支持向量机仅支持二分类,因此需要构造两个支持向量机,一个用于分类0和12合并的两类,另一个在分好的12合并类的基础下对1和2两类进行分类。然后需要分别对两个支持向量机构造相应的数据集标签,对于第一个支持向量机,将原标签为0的和原标签为1或2的分别标记为-1和1;对于第二个支持向量机,将原标签为1的和原标签为2的分别标记为-1和1。其思维导图如下图所示。
径向核函数的情形:
- # 模型的训练和预测
- C = 200
- toler = 0.0001
- maxIter = 100
- kernelOption = ("rbf", 1)
-
- # 第一个分类器:0 / 12
- trainlabel_0_12 = []
- for i in range(len(news_train.target)):
- if news_train.target[i] == 0:
- trainlabel_0_12.append(-1)
- else:
- trainlabel_0_12.append(1)
- trainlabel_0_12Mat = np.mat(trainlabel_0_12).T # 第一个分类器处理好的训练集标签
- traindata_0_12Mat = traindataMat[::]
- svmClassifier_0_12 = trainSVM(traindata_0_12Mat, trainlabel_0_12Mat, C, toler, maxIter, kernelOption)
-
- C = 100
- toler = 0.0001
- maxIter = 100
- kernelOption = ("rbf", 1)
-
- # 第二个分类器:1 / 2
- trainlabel_1_2 = []
- traindata_1_2index=[]
- for i in range(len(news_train.target)):
- if news_train.target[i] == 1:
- trainlabel_1_2.append(-1)
- traindata_1_2index.append(i)
- elif news_train.target[i] == 2:
- trainlabel_1_2.append(1)
- traindata_1_2index.append(i)
- trainlabel_1_2Mat = np.mat(trainlabel_1_2).T # 第二个分类器处理好的训练集标签
- traindata_1_2Mat = traindataMat[traindata_1_2index] # 第二个分类器处理好的训练集数据
- svmClassifier_1_2 = trainSVM(traindata_1_2Mat, trainlabel_1_2Mat, C, toler, maxIter, kernelOption)
-
- # 测试样本 0 / 12
- testlabel_0_12 = []
- for i in range(len(news_test.target)):
- if news_test.target[i] == 0:
- testlabel_0_12.append(-1)
- else:
- testlabel_0_12.append(1)
- testlabel_0_12Mat = np.mat(testlabel_0_12).T
- testdata_0_12Mat = testdataMat[::]
- accuracy_0_12, labelpredict_0_12, numright_0_12 = testSVM(svmClassifier_0_12, testdata_0_12Mat, testlabel_0_12Mat)
- print("accuracy_0_12:",accuracy_0_12)
-
- # 测试样本 1 / 2
- testlabel_1_2index = [] # 存储第一个分类器对12合并类分类正确的索引
- for i in range(len(labelpredict_0_12)):
- if labelpredict_0_12[i] == 1 and testlabel_0_12Mat[i] == 1:
- testlabel_1_2index.append(i)
- num12 = len(testlabel_1_2index)
- testlabel_1_2raw = testlabelMat[testlabel_1_2index] # 提取第一个分类器对12合并类分类正确的标签
- testlabel_1_2 = [0 for i in range(num12)]
- for i in range(num12): # 对标签进行重新标记为-1和1
- if testlabel_1_2raw[i] == 1:
- testlabel_1_2[i] = -1
- else:
- testlabel_1_2[i] = 1
- testlabel_1_2Mat = np.mat(testlabel_1_2).T # 第二个分类器处理好的测试集标签
- testdata_1_2Mat = testdataMat[testlabel_1_2index] # 第二个分类器处理好的测试集数据
- accuracy_1_2, labelpredict_1_2, numright_1_2 = testSVM(svmClassifier_1_2, testdata_1_2Mat, testlabel_1_2Mat)
- print("accuracy_1_2:",accuracy_1_2)
-
- """
- 统计被正确分类的样本数量,包括:
- 1、第一轮分类 -> 本来是-1结果被正确分类为-1的个数。
- 第一轮分类结束后,本来是1结果被正确分类为1的样本进入第二轮分类;
- 本来是-1结果本分类为1的样本已经分类错误,不参与第二轮分类
- 2、第二轮分类 -> -1、1被正确分类的个数。
- """
- total_accuracy = (numright_0_12 + num12 * accuracy_1_2) / len(testlabelMat)
- print("\tFinal accuracy = %.3f%%" % (total_accuracy * 100))
运行结果:在测试集上的分类准确率约为92.495%

线性核函数的情形:
- # 模型的训练和预测
- C = 200
- toler = 0.0001
- maxIter = 100
- kernelOption = ("linear", 0)
-
- # 第一个分类器:0 / 12
- trainlabel_0_12 = []
- for i in range(len(news_train.target)):
- if news_train.target[i] == 0:
- trainlabel_0_12.append(-1)
- else:
- trainlabel_0_12.append(1)
- trainlabel_0_12Mat = np.mat(trainlabel_0_12).T # 第一个分类器处理好的训练集标签
- traindata_0_12Mat = traindataMat[::]
- svmClassifier_0_12 = trainSVM(traindata_0_12Mat, trainlabel_0_12Mat, C, toler, maxIter, kernelOption)
-
- C = 100
- toler = 0.0001
- maxIter = 100
- kernelOption = ("linear", 0)
-
- # 第二个分类器:1 / 2
- trainlabel_1_2 = []
- traindata_1_2index=[]
- for i in range(len(news_train.target)):
- if news_train.target[i] == 1:
- trainlabel_1_2.append(-1)
- traindata_1_2index.append(i)
- elif news_train.target[i] == 2:
- trainlabel_1_2.append(1)
- traindata_1_2index.append(i)
- trainlabel_1_2Mat = np.mat(trainlabel_1_2).T # 第二个分类器处理好的训练集标签
- traindata_1_2Mat = traindataMat[traindata_1_2index] # 第二个分类器处理好的训练集数据
- svmClassifier_1_2 = trainSVM(traindata_1_2Mat, trainlabel_1_2Mat, C, toler, maxIter, kernelOption)
-
- # 测试样本 0 / 12
- testlabel_0_12 = []
- for i in range(len(news_test.target)):
- if news_test.target[i] == 0:
- testlabel_0_12.append(-1)
- else:
- testlabel_0_12.append(1)
- testlabel_0_12Mat = np.mat(testlabel_0_12).T
- testdata_0_12Mat = testdataMat[::]
- accuracy_0_12, labelpredict_0_12, numright_0_12 = testSVM(svmClassifier_0_12, testdata_0_12Mat, testlabel_0_12Mat)
- print("accuracy_0_12:",accuracy_0_12)
-
- # 测试样本 1 / 2
- testlabel_1_2index = [] # 存储第一个分类器对12合并类分类正确的索引
- for i in range(len(labelpredict_0_12)):
- if labelpredict_0_12[i] == 1 and testlabel_0_12Mat[i] == 1:
- testlabel_1_2index.append(i)
- num12 = len(testlabel_1_2index)
- testlabel_1_2raw = testlabelMat[testlabel_1_2index] # 提取第一个分类器对12合并类分类正确的标签
- testlabel_1_2 = [0 for i in range(num12)]
- for i in range(num12): # 对标签进行重新标记为-1和1
- if testlabel_1_2raw[i] == 1:
- testlabel_1_2[i] = -1
- else:
- testlabel_1_2[i] = 1
- testlabel_1_2Mat = np.mat(testlabel_1_2).T # 第二个分类器处理好的测试集标签
- testdata_1_2Mat = testdataMat[testlabel_1_2index] # 第二个分类器处理好的测试集数据
- accuracy_1_2, labelpredict_1_2, numright_1_2 = testSVM(svmClassifier_1_2, testdata_1_2Mat, testlabel_1_2Mat)
- print("accuracy_1_2:",accuracy_1_2)
-
- """
- 统计被正确分类的样本数量,包括:
- 1、第一轮分类 -> 本来是-1结果被正确分类为-1的个数。
- 第一轮分类结束后,本来是1结果被正确分类为1的样本进入第二轮分类;
- 本来是-1结果本分类为1的样本已经分类错误,不参与第二轮分类
- 2、第二轮分类 -> -1、1被正确分类的个数。
- """
- total_accuracy = (numright_0_12 + num12 * accuracy_1_2) / len(testlabelMat)
- print("\tFinal accuracy = %.3f%%" % (total_accuracy * 100))
运行结果:在测试集上的分类准确率约为91.682%

五、实验结果分析
| 二分类 | 三分类 | ||
核函数 | 线性核函数 | 径向核函数 | 线性核函数 | 径向核函数 |
预测准确率 | 94.98% | 95.40% | 91.68% | 92.50% |
程序运行时间 | 57s | 2m13s | 4m24s | 11m17s |
对于新闻文本二分类和三分类的情形,该支持向量机的分类预测效果较好,准确率都达到了90%以上。
对于不同的分类问题,二分类的分类准确率高于三分类。原因在于在三分类中,第一轮分类结束后,本来是正类结果被正确分类为正类的样本进入第二轮分类,本来是负类结果被分类为正类的样本已经分类错误,不参与第二轮分类。因此三分类的第一轮分类的准确率对第二轮分类以及总体的准确率有很大的影响。
而对于相同的分类情形,在合适的参数下,选取核函数为径向核函数的预测准确率高于线性核函数的情形,但程序运行时间也长于线性核函数的情形。原因在于径向核函数的处理过程比线性核函数繁琐,且文本数据的特征一般具有高维且稀疏的特点,需要的训练时间较长,导致模型效率较低。
六、支持向量机的优缺点
优点:
可以解决高维问题,即大型特征空间;
解决小样本下机器学习问题;
能够处理非线性特征的相互作用;
无局部极小值问题;(相对于神经网络等算法)
无需依赖整个数据;
泛化能力比较强;
缺点:
当观测样本很多时,效率并不是很高;
对非线性问题没有通用解决方案,有时候很难找到一个合适的核函数;
对于核函数的高维映射解释力不强,尤其是径向基函数;
常规SVM只支持二分类;
对缺失数据敏感;



