
- 1c语言 龟兔赛跑_.设计一个龟兔赛跑的程序,兔子和乌龟两个分别跑步,当谁先跑够1000步时,谁就获胜.
- 2自动写代码的AI工具,已经支持 VsCode 插件安装使用_vscode ai插件
- 3100多个经典常用的PHP功能插件大全实例演示和下载_php 常用案例
- 4CentOS 7通过yum安装Docker和docker-compose_yum能创建dockers-compose么?
- 5SASS 官方文档速通
- 6Mac系统编辑hosts文件_mac 复制了hosts文件如何删除
- 7本地部署Stable Diffusion教程,详细教学,已安装成功,无科学上网版_stable diffusion pc版
- 8MATLAB概率密度函数估计_matlab中概率密度函数
- 9【最经典的79个】软件测试面试题(内含答案)提前备战“金九银十”_软件运维面试题目100及最佳答案
- 10Pycharm的安装以及如何配置Pytorch环境(Win11)_pycharm安装torch
支持向量机SVM及python实现_python代码实现svm支持向量机的多输入单输出预测模型
赞
踩
0. 介绍
支持向量机,support vector machines,SVM,是一种二分类模型。
- 策略:
间隔最大化。这等价于正则化的合页损失函数最小化问题。 - 学习算法:
序列最小最优化算法SMO - 分类
线性可分支持向量机,线性支持向量机、非线性支持向量机。
1、线性可分支持向量机
- 特点:
训练数据线性可分;策略为硬间隔最大化;线性分类器。
模型
分类决策函数:
f
(
x
)
=
sign
(
w
∗
⋅
x
+
b
∗
)
f(x)=\operatorname{sign}\left(w^{*} \cdot x+b^{*}\right)
f(x)=sign(w∗⋅x+b∗)
分类超平面:
w
∗
⋅
x
+
b
∗
=
0
w^{*} \cdot x+b^{*} = 0
w∗⋅x+b∗=0
定义超平面关于样本点
(
x
i
,
y
i
)
(x_i, y_i)
(xi,yi)的函数间隔为:
γ
^
i
=
y
i
(
w
⋅
x
i
+
b
)
\hat{\gamma}_{i}=y_{i}\left(w \cdot x_{i}+b\right)
γ^i=yi(w⋅xi+b)
定义超平面关于样本点
(
x
i
,
y
i
)
(x_i, y_i)
(xi,yi)的几何间隔:
γ
i
=
y
i
(
w
∥
w
∥
⋅
x
i
+
b
∥
w
∥
)
\gamma_{i}=y_{i}\left(\frac{w}{\|{w}\|} \cdot x_{i}+\frac{b}{\|w\|}\right)
γi=yi(∥w∥w⋅xi+∥w∥b)
几何距离是真正的点到面的距离。
定义所有样本点到面的距离的最小值:
γ
=
min
i
=
1
,
…
,
N
γ
i
\gamma=\min _{i=1, \ldots, N} \gamma_{i}
γ=i=1,…,Nminγi
间隔最大化:对训练集找到几何间隔最大的超平面,也就是充分大的确信度对训练数据进行分类。
以下通过最大间隔法和对偶法进行实现:
最大间隔法:
1)构造约束最优化函数
max
w
,
b
γ
s.t.
y
i
(
w
∥
w
∥
⋅
x
i
+
b
∥
w
∥
)
⩾
γ
,
i
=
1
,
2
,
⋯
,
N
如果假设函数间隔
γ
^
=
∣
∣
w
∣
∣
γ
=
1
\hat\gamma = ||w||\gamma = 1
γ^=∣∣w∣∣γ=1,易得
上述等价于:
min
1
2
∥
ω
∥
s.t.
y
i
(
w
x
i
+
b
)
−
1
≥
0
2)解约束函数,即获得超平面
w
∗
⋅
x
+
b
∗
=
0
w^{*} \cdot x+b^{*} = 0
w∗⋅x+b∗=0
对偶法:
对偶算法可以使得问题更容易求解,并且能自然引入核函数,推广非线性分类。
1、定义拉格朗日函数
L
(
w
,
b
,
α
)
=
1
2
∥
w
∥
2
−
∑
i
=
1
N
α
i
y
i
(
w
⋅
x
i
+
b
)
+
∑
i
=
1
N
α
i
L(w, b, \alpha)=\frac{1}{2}\|w\|^{2}-\sum_{i=1}^{N} \alpha_{i} y_{i}\left(w \cdot x_{i}+b\right)+\sum_{i=1}^{N} \alpha_{i}
L(w,b,α)=21∥w∥2−i=1∑Nαiyi(w⋅xi+b)+i=1∑Nαi
优化目标:
max
α
min
w
,
b
L
(
w
,
b
,
α
)
\max _{\alpha} \min _{w,b} L(w, b, \alpha)
αmaxw,bminL(w,b,α)
2、求
min
w
,
b
L
(
w
,
b
,
α
)
\min _{w, b} L(w, b, \alpha)
minw,bL(w,b,α)
将
L
L
L 分别对
w
,
b
w,b
w,b求偏导数,并令其等于0。
∇
w
L
(
w
,
b
,
α
)
=
w
−
∑
i
=
1
N
α
i
y
i
x
i
=
0
∇
b
L
(
w
,
b
,
α
)
=
∑
i
=
1
N
α
i
y
i
=
0
得:
w
=
∑
i
=
1
N
α
i
y
i
x
i
∑
i
=
1
N
α
i
y
i
=
0
3、求
min
w
,
b
,
α
L
(
w
,
b
,
α
)
\min _{w, b,\alpha} L(w, b, \alpha)
minw,b,αL(w,b,α) 对
α
\alpha
α的极大。
根据2中的结果,
min
w
,
b
L
(
w
,
b
,
α
)
=
−
1
2
∑
i
=
1
N
∑
j
=
1
N
α
i
α
j
y
i
y
j
(
x
i
⋅
x
j
)
+
∑
i
=
1
N
α
i
\min _{w, b} L(w, b, \alpha)=-\frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_{i} \alpha_{j} y_{i} y_{j}\left(x_{i} \cdot x_{j}\right)+\sum_{i=1}^{N} \alpha_{i}
w,bminL(w,b,α)=−21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)+i=1∑Nαi
求
m
i
n
L
(
w
,
b
,
α
)
min L(w,b,\alpha)
minL(w,b,α)对
α
\alpha
α的极大的对偶问题是:
min
α
1
2
∑
i
=
1
N
∑
j
=
1
N
α
i
α
j
y
i
y
j
(
x
i
⋅
x
j
)
−
∑
i
=
1
N
α
i
s.t.
∑
i
=
1
N
α
i
y
i
=
0
α
i
⩾
0
,
i
=
1
,
2
,
⋯
,
N
求解出
α
∗
\alpha^*
α∗,即可得:
w
∗
=
∑
i
α
i
∗
y
i
x
i
w^{*}=\sum_{i} \alpha_{i}^{*} y_{i} x_{i}
w∗=i∑αi∗yixi
存在一个
α
j
∗
>
0
\alpha_j^*>0
αj∗>0,使得
y
j
(
w
∗
⋅
x
j
+
b
∗
)
−
1
=
0
y_{j}\left(w^{*} \cdot x_{j}+b^{*}\right)-1=0
yj(w∗⋅xj+b∗)−1=0
因此,分类决策函数为:
f
(
x
)
=
sign
(
∑
i
=
1
N
α
i
∗
y
i
(
x
⋅
x
i
)
+
b
∗
)
f(x)=\operatorname{sign}\left(\sum_{i=1}^{N} \alpha_{i}^{*} y_{i}\left(x \cdot x_{i}\right)+b^{*}\right)
f(x)=sign(i=1∑Nαi∗yi(x⋅xi)+b∗)
总结
感知机模型的定义和SVM一样,但是两者的学习策略不同,感知机是误分类驱动,最小化误分点到超平面距离;SVM是最大化所有样本点到超平面的几何距离,也就是SVM是由与超平面距离最近的点决定的,这些点也称为支持向量。
2、线性支持向量机与软间隔最大化
- 特点:
训练数据近似可分;策略为软间隔最大化;线性分类器。
线性不可分指,某些样本点不能满足函数间隔
γ
^
≥
1
\hat\gamma \geq1
γ^≥1的约束条件。
引入松弛因子
ξ
\xi
ξ 和惩罚参数
C
C
C,得
min
w
,
b
,
ξ
1
2
∥
w
∥
2
+
C
∑
i
=
1
N
ξ
i
s.t.
y
i
(
w
⋅
x
i
+
b
)
⩾
1
−
ξ
i
,
i
=
1
,
2
,
⋯
,
N
ξ
i
⩾
0
,
i
=
1
,
2
,
⋯
,
N
优化目标,一方面是使得间隔尽量大,另一方面使得误分点的个数尽量少。
当C趋于无穷大时,优化目标不允许误分点存在,从而过拟合;
当C趋于0时,只要求间隔越大越好,那么将无法得到有意义的解且算法不会收敛,即欠拟合。
学习算法:
1.构建凸二次规划问题:
min
α
1
2
∑
i
=
1
N
∑
j
=
1
N
α
i
α
j
y
i
y
j
(
x
i
⋅
x
j
)
−
∑
i
=
1
N
α
i
s.t.
∑
i
=
1
N
α
i
y
i
=
0
0
⩽
α
i
⩽
C
,
i
=
1
,
2
,
⋯
,
N
2.求得
w
∗
=
∑
i
=
1
N
α
i
∗
y
i
x
i
w^{*}=\sum_{i=1}^{N} \alpha_{i}^{*} y_{i} x_{i}
w∗=i=1∑Nαi∗yixi
存在
0
<
α
j
∗
<
C
0<\alpha_{j}^{*}<C
0<αj∗<C,则
b
∗
=
y
j
−
∑
i
=
1
N
y
i
α
i
∗
(
x
i
⋅
x
j
)
b^{*}=y_{j}-\sum_{i=1}^{N} y_{i} \alpha_{i}^{*}\left(x_{i} \cdot x_{j}\right)
b∗=yj−i=1∑Nyiαi∗(xi⋅xj)
分类决策函数:
f
(
x
)
=
sign
(
w
∗
⋅
x
+
b
∗
)
f(x)=\operatorname{sign}\left(w^{*} \cdot x+b^{*}\right)
f(x)=sign(w∗⋅x+b∗)
3、非线性支持向量机与核函数
- 特点:
训练数据线性不可分;学习策略为使用核技巧和软间隔最大化;非线性支持向量机。
思想:
使用非线性变换,把输入空间对应一个特征空间(希尔伯特空间),把非线性问题转换成线性问题;

核函数:
定义
ϕ
\phi
ϕ是一个输入空间到特征空间的映射,使得对于所有的输入空间的x, z满足条件:
K
(
x
,
z
)
=
ϕ
(
x
)
ϕ
(
z
)
K(x, z) = \phi(x) \phi(z)
K(x,z)=ϕ(x)ϕ(z)
其中,
K
(
x
,
z
)
K(x,z)
K(x,z)是核函数;
ϕ
(
x
)
\phi(x)
ϕ(x)是映射函数。
把原来目标函数的
x
i
,
x
j
x_i, x_j
xi,xj内积替换成
K
(
x
i
,
x
j
)
K(x_i,x_j)
K(xi,xj).
正定核:
K
(
x
,
z
)
K(x, z)
K(x,z) 是对称函数, 核对应的Gram矩阵半正定。
常用的核函数:
多项式核函数:
K
(
x
,
z
)
=
(
x
⋅
z
+
1
)
p
K(x, z)=(x \cdot z+1)^{p}
K(x,z)=(x⋅z+1)p
高斯核函数:
K
(
x
,
z
)
=
e
x
p
(
−
∣
∣
x
−
z
∣
∣
2
2
σ
2
)
K(x,z) = exp(-\frac{||x-z||^2}{2\sigma^2})
K(x,z)=exp(−2σ2∣∣x−z∣∣2)
非线性支持向量分类机学习算法:
(1)选取适当的核函数
K
(
x
,
z
)
K(x,z)
K(x,z)和适当的参数C,构造并求解最优化问题:
min
α
1
2
∑
i
=
1
N
∑
j
=
1
N
α
i
α
j
y
i
y
j
K
(
x
i
,
x
j
)
−
∑
i
=
1
N
α
i
s.t.
∑
i
=
1
N
α
i
y
i
=
0
0
⩽
α
i
⩽
C
,
i
=
1
,
2
,
⋯
,
N
求得最优解
α
∗
=
(
α
1
∗
,
α
2
∗
,
⋯
,
α
N
∗
)
T
\alpha^{*}=\left(\alpha_{1}^{*}, \alpha_{2}^{*}, \cdots, \alpha_{N}^{*}\right)^{\mathrm{T}}
α∗=(α1∗,α2∗,⋯,αN∗)T。
(2)选择
α
∗
\alpha^*
α∗的一个正分量
0
<
α
∗
<
C
0<\alpha^*<C
0<α∗<C,并计算
b
∗
=
y
j
−
∑
i
=
1
N
α
i
∗
y
i
K
(
x
i
⋅
x
j
)
b^{*}=y_{j}-\sum_{i=1}^{N} \alpha_{i}^{*} y_{i} K\left(x_{i} \cdot x_{j}\right)
b∗=yj−i=1∑Nαi∗yiK(xi⋅xj)
(3)构建决策函数:
f
(
x
)
=
sign
(
∑
i
=
1
N
α
i
∗
y
i
K
(
x
,
x
i
)
+
b
∗
)
f(x)=\operatorname{sign}\left(\sum_{i=1}^{N} \alpha_{i}^{*} y_{i} K\left(x, x_{i}\right)+b^{*}\right)
f(x)=sign(i=1∑Nαi∗yiK(x,xi)+b∗)
当 K ( x , z ) K(x,z) K(x,z)是正定核函数时,上述是凸二次规划问题,解是存在的。
4、学习算法:序列最小最优化算法SMO
4.1 原理
序列最小最优化SMO算法:
1、通过满足KKT条件,来求解;
2、如果没有满足KKT条件,选择两个变量,固定其他变量,构造二次规划问题。
算法包括,求解两个变量二次规划和选择变量的启发式方法。
优化目标:
min
α
1
2
∑
i
=
1
N
∑
j
=
1
N
α
i
α
j
y
i
y
j
K
(
x
i
,
x
j
)
−
∑
i
=
1
N
α
i
st
∑
i
=
1
n
α
i
=
0
0
⩽
α
i
⩽
C
,
i
=
1
,
2
,
⋯
,
N
变量是拉格朗日乘子,一个变量
α
i
\alpha_i
αi对应于一个样本点
(
x
i
,
y
i
)
(x_i, y_i)
(xi,yi); 变量的总数等于训练样本的容量N。
SMO是启发式算法,思路是:
固定其他变量,针对其中两个变量构建二次规划问题,通过子问题求解,提高算法计算速度。
这两个变量,一个是违反KKT条件最严重的那个,另一个是由约束条件自动确定。
两个变量二次规划的求解方法
min
α
1
,
α
2
W
(
α
1
,
α
2
)
=
1
2
K
11
α
1
2
+
1
2
K
22
α
2
2
+
y
1
y
2
K
12
α
1
α
2
−
(
α
1
+
α
2
)
+
y
1
α
1
∑
i
=
3
N
y
i
α
i
K
i
1
+
y
2
α
2
∑
i
=
3
N
y
i
α
i
K
i
2
s.t.
α
1
y
1
+
α
2
y
2
=
−
∑
i
=
3
N
y
i
α
i
=
ζ
0
⩽
α
i
⩽
C
,
i
=
1
,
2
其中, K i j = K ( x i , x j ) K_{ij} = K(x_i,x_j) Kij=K(xi,xj)
由于
y
i
y_i
yi要么是1,要么是-1;所以,
α
1
y
1
+
α
2
y
2
\alpha_{1} y_{1}+\alpha_{2} y_{2}
α1y1+α2y2是一个平行于以下正方形对角线的线段。
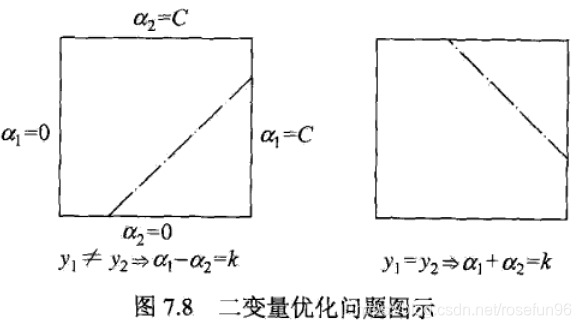
由于,
0
<
α
i
<
C
0<\alpha_i < C
0<αi<C,
α
1
y
1
+
α
2
y
2
=
c
o
n
s
t
\alpha_{1} y_{1}+\alpha_{2} y_{2} = const
α1y1+α2y2=const,那么容易知道
α
2
n
e
w
\alpha_2^{new}
α2new 的取值范围:
如果
y
1
≠
y
2
y_1 \neq y_2
y1=y2:
L
=
max
(
0
,
α
2
old
−
α
1
old
)
,
H
=
min
(
C
,
C
+
α
2
old
−
α
1
old
)
L=\max \left(0, \alpha_{2}^{\text {old }}-\alpha_{1}^{\text {old }}\right), \quad H=\min \left(C, C+\alpha_{2}^{\text {old }}-\alpha_{1}^{\text {old }}\right)
L=max(0,α2old −α1old ),H=min(C,C+α2old −α1old )
如果
y
1
=
y
2
y_1 = y_2
y1=y2:
L
=
max
(
0
,
α
2
old
+
α
1
old
−
C
)
,
H
=
min
(
C
,
α
2
old
+
α
1
old
)
L=\max \left(0, \alpha_{2}^{\text {old }}+\alpha_{1}^{\text {old }}-C\right), \quad H=\min \left(C, \alpha_{2}^{\text {old }}+\alpha_{1}^{\text {old }}\right)
L=max(0,α2old +α1old −C),H=min(C,α2old +α1old )
记未考虑 α 2 \alpha_2 α2不等式约束 0 ⩽ α i ⩽ C 0 \leqslant \alpha_{i} \leqslant C 0⩽αi⩽C,为 α 2 n e w , u n c \alpha_2^{new,unc} α2new,unc .
那么:
α
2
new, unc
=
α
2
old
+
y
2
(
E
1
−
E
2
)
η
\alpha_{2}^{\text {new, unc }}=\alpha_{2}^{\text {old }}+\frac{y_{2}\left(E_{1}-E_{2}\right)}{\eta}
α2new, unc =α2old +ηy2(E1−E2)
其中,
E
i
E_i
Ei 为函数
g
(
x
)
g(x)
g(x) 对输入
x
i
x_i
xi 的预测值与真实值
y
i
y_i
yi之差。
E
i
=
g
(
x
i
)
−
y
i
=
(
∑
j
=
1
N
α
j
y
j
K
(
x
j
,
x
i
)
+
b
)
−
y
i
,
i
=
1
,
2
E_{i}=g\left(x_{i}\right)-y_{i}=\left(\sum_{j=1}^{N} \alpha_{j} y_{j} K\left(x_{j}, x_{i}\right)+b\right)-y_{i}, \quad i=1,2
Ei=g(xi)−yi=(j=1∑NαjyjK(xj,xi)+b)−yi,i=1,2
η = K 11 + K 22 − 2 K 12 = ∥ Φ ( x 1 ) − Φ ( x 2 ) ∥ 2 \eta=K_{11}+K_{22}-2 K_{12}=\left\|\Phi\left(x_{1}\right)-\Phi\left(x_{2}\right)\right\|^{2} η=K11+K22−2K12=∥Φ(x1)−Φ(x2)∥2
于是:
α
2
new
=
{
H
,
α
2
new, unc
>
H
α
2
new,
,
unc
,
L
⩽
α
2
new,
,
unc
⩽
H
L
,
α
2
new, unc
<
L
\alpha_{2}^{\text {new }}=\left\{
其中,
H
H
H,
L
L
L是
α
2
n
e
w
\alpha_2^{new}
α2new取值范围的上下界.
α
1
new
=
α
1
old
+
y
1
y
2
(
α
2
old
−
α
2
new
)
\alpha_{1}^{\text {new }}=\alpha_{1}^{\text {old }}+y_{1} y_{2}\left(\alpha_{2}^{\text {old }}-\alpha_{2}^{\text {new }}\right)
α1new =α1old +y1y2(α2old −α2new )
4.2 算法步骤
SMO算法在每个子问题中选择两个变量优化,其中至少一个变量是违反KKT条件的。
(1)第一个变量选择
从间隔边界上的支持向量点(
0
<
α
<
C
0<\alpha<C
0<α<C),选取不满足KKT条件的点,如果没有,从剩下的点选择。
KKT条件为:
y
i
⋅
g
(
x
i
)
=
{
⩾
1
,
{
x
i
∣
α
i
=
0
}
=
1
,
{
x
i
∣
0
<
α
i
<
C
}
⩽
1
,
{
x
i
∣
α
i
=
C
}
(2)第二个变量的选择
第二个变量选择使得
∣
E
1
−
E
2
∣
|E_1 - E_2|
∣E1−E2∣最大。
其中,
E
i
E_i
Ei代表函数 g(x)对输入
x
i
x_i
xi的预测值与真实输出
y
i
y_i
yi 之差。
E
i
=
g
(
x
i
)
−
y
i
=
(
∑
j
=
1
N
α
j
y
j
K
(
x
j
,
x
i
)
+
b
)
−
y
i
,
i
=
1
,
2
E_{i}=g\left(x_{i}\right)-y_{i}=\left(\sum_{j=1}^{N} \alpha_{j} y_{j} K\left(x_{j}, x_{i}\right)+b\right)-y_{i}, \quad i=1,2
Ei=g(xi)−yi=(j=1∑NαjyjK(xj,xi)+b)−yi,i=1,2
(3)计算阈值b 和差值
E
i
E_i
Ei.
这里更新
α
1
n
e
w
\alpha_1^{new}
α1new参考上面4.1。
b 1 new = − E 1 − y 1 K 11 ( α 1 new − α 1 old ) − y 2 K 21 ( α 2 new − α 2 old ) + b old {b}_{1}^{\text {new }}=-E_{1}-y_{1} K_{11}\left(\alpha_{1}^{\text {new }}-\alpha_{1}^{\text {old }}\right)-y_{2} K_{21}\left(\alpha_{2}^{\text {new }}-\alpha_{2}^{\text {old }}\right)+b^{\text {old }} b1new =−E1−y1K11(α1new −α1old )−y2K21(α2new −α2old )+bold
b 2 new = − E 2 − y 1 K 12 ( α 1 new − α 1 old ) − y 2 K 22 ( α 2 new − α 2 old ) + b old b_{2}^{\text {new }}=-E_{2}-y_{1} K_{12}\left(\alpha_{1}^{\text {new }}-\alpha_{1}^{\text {old }}\right)-y_{2} K_{22}\left(\alpha_{2}^{\text {new }}-\alpha_{2}^{\text {old }}\right)+b^{\text {old }} b2new =−E2−y1K12(α1new −α1old )−y2K22(α2new −α2old )+bold
b n e w b^{new} bnew选择满足条件 0 < α i n e w < C 0<\alpha_{i}^{\mathrm{new}}<C 0<αinew<C下的 b i n e w b_i^{new} binew. 如果 α 1 \alpha_1 α1 和 α 2 \alpha_2 α2都不满足,那么选择 b 1 n e w b_1^{new} b1new和 b 2 n e w b_2^{new} b2new的中点。
E i new = ∑ S y j α j K ( x i , x j ) + b new − y i E_{i}^{\text {new }}=\sum_{S} y_{j} \alpha_{j} K\left(x_{i}, x_{j}\right)+b^{\text {new }}-y_{i} Einew =S∑yjαjK(xi,xj)+bnew −yi
(4)预测
根据决策函数:
f
(
x
)
=
sign
(
∑
i
=
1
N
α
i
∗
y
i
K
(
x
⋅
x
i
)
+
b
∗
)
f(x)=\operatorname{sign}\left(\sum_{i=1}^{N} \alpha_{i}^{*} y_{i} K\left(x \cdot x_{i}\right)+b^{*}\right)
f(x)=sign(i=1∑Nαi∗yiK(x⋅xi)+b∗)
可以获得预测样本的标签。
5、实践

下面代码实现有点问题,这里使用了 max_iter作为终止条件,实际上应该是,找到最不符合KKT条件的样本,然后,该样本和剩下样本中挑选一个符合|Ei - Ej|最大的样本,不断重复挑选第二个样本直到目标函数不下降。也就是说,这里是O(n^2)的复杂度。代码展示的是O(n*max_iter)的复杂度,不合理。
from sklearn import datasets import numpy as np class SVM: def __init__(self, max_iter=100, kernel='linear'): self.max_iter = max_iter self._kernel = kernel def init_args(self, features, labels): # 样本数,特征维度 self.m, self.n = features.shape self.X = features self.Y = labels self.b = 0.0 # 将Ei保存在一个列表里 self.alpha = np.ones(self.m) self.E = [self._E(i) for i in range(self.m)] # 松弛变量 self.C = 1.0 def _KKT(self, i): y_g = self._g(i) * self.Y[i] if self.alpha[i] == 0: return y_g >= 1 elif 0 < self.alpha[i] < self.C: return y_g == 1 else: return y_g <= 1 # g(x)预测值,输入xi(X[i]) # g(x) = \sum_{j=1}^N {\alpha_j*y_j*K(x_j,x)+b} def _g(self, i): r = self.b for j in range(self.m): r += self.alpha[j] * self.Y[j] * self.kernel(self.X[i], self.X[j]) return r # 核函数 def kernel(self, x1, x2): if self._kernel == 'linear': return sum([x1[k] * x2[k] for k in range(self.n)]) elif self._kernel == 'poly': return (sum([x1[k] * x2[k] for k in range(self.n)]) + 1)**2 return 0 # E(x)为g(x)对输入x的预测值和y的差 # E_i = g(x_i) - y_i def _E(self, i): return self._g(i) - self.Y[i] def _init_alpha(self): # 外层循环首先遍历所有满足0<a<C的样本点,检验是否满足KKT index_list = [i for i in range(self.m) if 0 < self.alpha[i] < self.C] # 否则遍历整个训练集 non_satisfy_list = [i for i in range(self.m) if i not in index_list] index_list.extend(non_satisfy_list) # 外层循环选择满足0<alpha_i<C,且不满足KKT的样本点。如果不存在遍历剩下训练集 for i in index_list: if self._KKT(i): continue # 内层循环,|E1-E2|最大化 E1 = self.E[i] # 如果E1是+,选择最小的E_i作为E2;如果E1是负的,选择最大的E_i作为E2 if E1 >= 0: j = min(range(self.m), key=lambda x: self.E[x]) else: j = max(range(self.m), key=lambda x: self.E[x]) return i, j def _compare(self, _alpha, L, H): if _alpha > H: return H elif _alpha < L: return L else: return _alpha def fit(self, features, labels): self.init_args(features, labels) for t in range(self.max_iter): # train, 时间复杂度O(n) i1, i2 = self._init_alpha() # 边界,计算阈值b和差值E_i if self.Y[i1] == self.Y[i2]: # L = max(0, alpha_2 + alpha_1 -C) # H = min(C, alpha_2 + alpha_1) L = max(0, self.alpha[i1] + self.alpha[i2] - self.C) H = min(self.C, self.alpha[i1] + self.alpha[i2]) else: # L = max(0, alpha_2 - alpha_1) # H = min(C, alpha_2 + alpha_1+C) L = max(0, self.alpha[i2] - self.alpha[i1]) H = min(self.C, self.C + self.alpha[i2] - self.alpha[i1]) E1 = self.E[i1] E2 = self.E[i2] # eta=K11+K22-2K12= ||phi(x_1) - phi(x_2)||^2 eta = self.kernel(self.X[i1], self.X[i1]) + self.kernel( self.X[i2], self.X[i2]) - 2 * self.kernel(self.X[i1], self.X[i2]) if eta <= 0: # print('eta <= 0') continue # 更新约束方向的解 alpha2_new_unc = self.alpha[i2] + self.Y[i2] * ( E1 - E2) / eta #此处有修改,根据书上应该是E1 - E2,书上130-131页 alpha2_new = self._compare(alpha2_new_unc, L, H) alpha1_new = self.alpha[i1] + self.Y[i1] * self.Y[i2] * ( self.alpha[i2] - alpha2_new) b1_new = -E1 - self.Y[i1] * self.kernel(self.X[i1], self.X[i1]) * ( alpha1_new - self.alpha[i1]) - self.Y[i2] * self.kernel( self.X[i2], self.X[i1]) * (alpha2_new - self.alpha[i2]) + self.b b2_new = -E2 - self.Y[i1] * self.kernel(self.X[i1], self.X[i2]) * ( alpha1_new - self.alpha[i1]) - self.Y[i2] * self.kernel( self.X[i2], self.X[i2]) * (alpha2_new - self.alpha[i2]) + self.b if 0 < alpha1_new < self.C: b_new = b1_new elif 0 < alpha2_new < self.C: b_new = b2_new else: # 选择中点 b_new = (b1_new + b2_new) / 2 # 更新参数 self.alpha[i1] = alpha1_new self.alpha[i2] = alpha2_new self.b = b_new self.E[i1] = self._E(i1) self.E[i2] = self._E(i2) return 'train done!' def predict(self, data): r = self.b for i in range(self.m): r += self.alpha[i] * self.Y[i] * self.kernel(data, self.X[i]) return 1 if r > 0 else -1 def score(self, X_test, y_test): right_count = 0 for i in range(len(X_test)): result = self.predict(X_test[i]) if result == y_test[i]: right_count += 1 return right_count / len(X_test) def _weight(self): # linear model yx = self.Y.reshape(-1, 1) * self.X self.w = np.dot(yx.T, self.alpha) return self.w def normalize(x): return (x - np.min(x))/(np.max(x) - np.min(x)) def get_datasets(): # breast cancer for classification(2 classes) X, y = datasets.load_breast_cancer(return_X_y=True) # 归一化 X_norm = normalize(X) X_train = X_norm[:int(len(X_norm)*0.8)] X_test = X_norm[int(len(X_norm)*0.8):] y_train = y[:int(len(X_norm)*0.8)] y_test = y[int(len(X_norm)*0.8):] return X_train,y_train,X_test,y_test if __name__ == '__main__': X_train,y_train,X_test,y_test = get_datasets() svm = SVM(max_iter=200) svm.fit(X_train, y_train) print("acccucy:{:.4f}".format(svm.score(X_test, y_test)))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
运行结果:
acccucy:0.6491
- 1
Q:为什么支持向量机不适合大规模数据?
这里,大规模数据指,样本数目和特征数目都很大。
A:个人理解:
Linear核的SVM迭代一次时间复杂度
O
(
n
2
k
)
O(n^2 k)
O(n2k), n 为样本数目,k为特征数目,因为计算每个符合KKT条件的样本时,都得遍历剩余的样本来更新参数,直到目标函数不下降。
像LR时间复杂度是
O
(
n
)
O(n)
O(n), LR的样本和权重矩阵相乘(矩阵运算快,我认为可以忽略特征数目)。
非线性核的SVM:使用非线性特征映射将低维特征映射到高维,使用核技巧计算高维特征之间的内积。

由于使用数据集的核矩阵K(K[i][j]代表两个样本的核函数值)描述样本之间的相似性,矩阵元素随着数据规模的增大成平方增长。
最近开通了个公众号,主要分享推荐系统,风控等算法相关的内容,感兴趣的伙伴可以关注下。

参考:



