
- 1软件项目开发工程组织管理总结_软件开发组织管理
- 2Tita绩效宝:更频繁的绩效考核周期的好处_考核周期优点
- 3剑指offer 面试题11 旋转数组的最小数字_剑指offer 11旋转数组的最小值 超出时间限制
- 4Windows server——部署DHCP服务(2)_windows server dhcp
- 5arm集群服务器_Coolpy7消息服务器简介
- 6知识图谱可解释推理研究综述_amie+
- 7详细教程:Stegsolve的下载,jdk的下载、安装以及环境的配置_stegsolve下载
- 8GoLang封装redigo_golang redigo封装方法
- 9论文项目总结02-前端模块总结_前端项目模块汇报
- 10微信小程序连接云数据库基本使用_微信小程序云数据库怎么用
决策树 随机森林_随机森林决策树数量的选择
赞
踩
用比较官方的话说,随机森林是一种集成算法,但实际上,可以种简单的语言描述。以随机森林分类为例
随机森林的基分类器是决策树,决策树分支的方法是在所有重要特征中随机选择一个进行分支,这样随着random_state的不同,就会生长出不同的决策树,对这些决策树,随机森林采取的方法是,如果一半以上的决策树(二分类)将该向量预测为1,则随机森林预测为1,反之亦然,所以可以认为随机森林是决策树长出的一片森林
只有一个医生(单一决策树)诊断病人可能发生误诊(过拟合),让多个医生(随机森林)一起进行诊断(集成),然后进行投票选出最合适的诊断结果(拟合)。由于有的医生,如外科主任/专家(分类或者回归效果好的算法)他们的诊断结果可信度更高一些(权重更高)。
决策树
要理解随机森林,我们首先要理解什么是决策树。决策树是一个树形结构。一个决策树在构建时,通过将数据划分为具有相似值的子集来构建出一个完整的树。决策树上每一个非叶节点都是一个特征属性的测试,经过每个特征属性的测试,会产生多个分支,而每个分支就是对于特征属性测试中某个值域的输出子集。决策树上每个叶子节点就是表达输出结果的连续或者离散的数据。
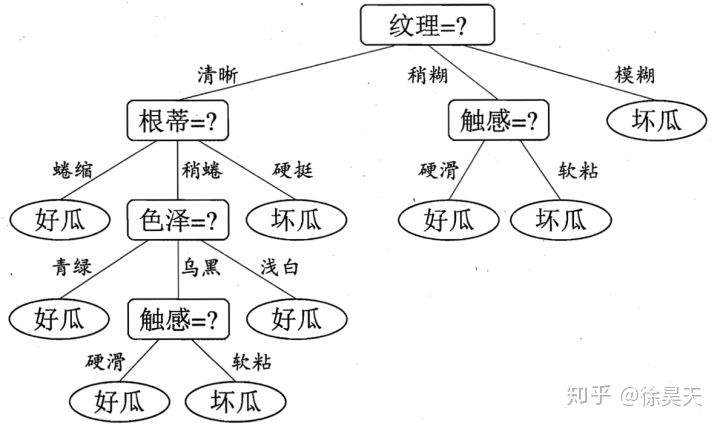
举个例子,下图来自于周志华老师的书《机器学习》,这个决策树是用来判断一个西瓜是不是好瓜的。在挑西瓜时,我们首先要判断一个西瓜的纹理,如果纹理很模糊,那么这个挂一定是坏瓜,赶紧扔掉。如果这个瓜的纹理稍微模糊,就去判断这个西瓜的触感怎么样。如果这个瓜的纹理比较清晰,那么接下来我们可以通过观察这个瓜的各个部分比如根蒂、色泽以及触感去一步一步判断一个瓜的好坏。这个就是决策树在分类问题中非常典型的例子。当决策树用于回归问题的时候,每个叶子节点就是一个一个实数值。
随机森林
随机森林是以决策树为基础的一种更高级的算法。像决策树一样,随机森林即可以用于回归也可以用于分类。从名字中可以看出,随机森林是用随机的方式构建的一个森林,而这个森林是由很多的相互不关联的决策树组成。实时上随机森林从本质上属于机器学习的一个很重要的分支叫做集成学习。集成学习通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成单预测,因此优于任何一个单分类的做出预测。
所以理论上,随机森林的表现一般要优于单一的决策树,因为随机森林的结果是通过多个决策树结果投票来决定最后的结果。简单来说,随机森林中每个决策树都有一个自己的结果,随机森林通过统计每个决策树的结果,选择投票数最多的结果作为其最终结果。我觉得中国一句谚语很形象的表达了随机森林的运作模式,就是“三个臭皮匠,顶个诸葛亮”。

