
热门标签
热门文章
- 1Git: commit 中的 hash 是什么_commit hash
- 2[附源码]Java计算机毕业设计SSM航空订票系统
- 3EXML的使用
- 4python实现四位随机验证码生成_制作随机验证码4位(验证码由0-9,大小写字母a-z,小写a-z构成),不区分大小写。用pyt
- 5【Unity3D】UI Toolkit简介_uitoolkit
- 6【Linux-Ubuntu】定时任务 cron 详解
- 7【AI_Design】Midjourney技巧进阶
- 8在众多的材质中选择灰口铸铁铸造划线平台、铸铁平台等的原因——河北北重
- 9基于粤嵌gec6818开发板嵌入式电子相册,智能家居,音乐播放,灯光控制,2048游戏_粤嵌开发板相册
- 10发生了快速异常检测失败,将不会调用异常处理程序
当前位置: article > 正文
随机森林算法及其实现(1)_随机森林算法伪代码
作者:算法设计者 | 2024-02-01 09:22:53
赞
踩
随机森林算法伪代码
随机森林算法及其实现
算法理解
随机森林就是通过集成学习的思想将多棵决策树集成的一种算法,它的基本单元是决策树,而它的本质属于机器学习的一大分支——集成学习(Ensemble Learning)方法。
这里随机的意思涉及到了另一个思想,也就是 Bagging 思想。
Bagging 是 bootstrap aggregating 的简写,又称为装袋算法,是一种有放回的抽样方法,目的是为了得到统计量的分布以及置信区间,该算法可与其它分类、回归算法结合,提高其准确率、稳定形的同时,通过降低结果的方差,避免过拟合的发生。具体的步骤如下:
- 采用重抽样方法(有放回抽样)从原始样本中抽取一定数量的样本
- 根据抽出的样本计算想要得到的统计量T
- 重复上述N次(一般大于1000),得到N个统计量T
- 根据这N个统计量,即可计算出统计量的置信区间
随即森林就属于 Bagging。 通过随机的方式去构造不同的决策树形成一个森林,这些决策树之间相互没有关联,最后的结果便是通过这些决策树的预测结果统计得到。
算法实现
首先实现决策树,这里具体的代码就不贴出来了,可以贴贴结果。一是有点长,而是还有点小问题有待完善,用西瓜书上的伪代码表示一下决策树的算法步骤:

测试代码:
void RandomForestClassifier::unitTest() { std::string fileName = ".\\data\\testRandomForest.txt"; char* testFile = (char*)fileName.c_str(); DataReader testReader(testFile, ","); testReader.train_test_split(0.3); IntArray* availableInstances = new IntArray(testReader.getTrainLabels()->getLength()); IntArray* availableAttributes = new IntArray(testReader.getTrainData()->getColumns()); DoubleMatrix* trainData = testReader.getTrainData(); IntArray* trainLabels = testReader.getTrainLabels(); DoubleMatrix* testData = testReader.getTestData(); IntArray* testLabels = testReader.getTestLabels(); Tree* tree = new Tree(trainData, testReader.getTrainLabels(), availableInstances, availableAttributes, testReader.getNumClasses(), 3); /*std::cout << "The Data:" << std::endl << testReader.getAllData()->toString() << std::endl; std::cout << "The tree:" << std::endl << tree->toString() << std::endl;*/ tree->train(); IntArray* predictLabels = new IntArray(testLabels->getLength()); DoubleMatrix* oneLineData = new DoubleMatrix(1, testData->getColumns()); for (int i = 0; i < testData->getRows(); i++) { oneLineData = oneLineData->getOneLine(testData, i); predictLabels->setValue(i, tree->predict(oneLineData)); } /*std::cout << "trainData:" << std::endl << trainData->toString() << std::endl; std::cout << "trainLabels:" << std::endl << trainLabels->toString() << std::endl;*/ std::cout << "testData:" << std::endl << testData->toString() << std::endl; std::cout << "testLabels:" << std::endl << testLabels->toString() << std::endl; std::cout << "predictLabels:" << std::endl << predictLabels->toString() << std::endl; double accuracy = 0; for (int i = 0; i < testData->getRows(); i++) { if (testLabels->getValue(i) == predictLabels->getValue(i)) { accuracy++; } } accuracy /= testData->getRows(); std::cout << "accuracy:" << accuracy << std::endl; /*for (int i = 0; i < trainData->getColumns(); i++) { std::cout << tree->getNumValues(i) << std::endl; }*/ }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
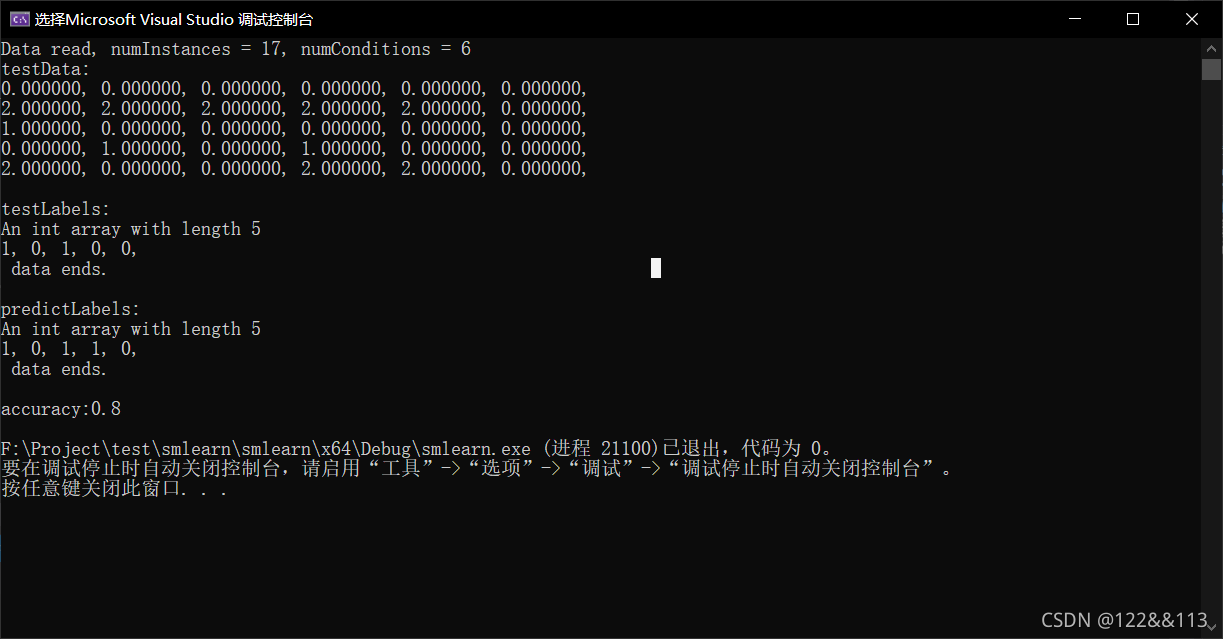
随机森林的实现步骤就和上面 Bagging 的步骤差不多,通过多个决策树分类得到的结果来投票获得最终的预测值。
实现过程出现的问题以及解决方式
实现方式是利用C++去实现,目前实现了ID3决策树算法的大部分代码,不过测试还有点小问题,正在更改,同时需要考虑数据的特性,目前只实现了基于离散属性的决策树,在这个过程中需要结合该框架下的基础类进行编码,因此需要添加很多未存在的方法,感觉会使代码比较臃肿,比如 DoubleMatrix 类,因此有些方法还是放在了当前实现的类中以单独使用。
下周目标以及待完善的工作
继续完善随机森林的代码,实现基于连续属性的决策树,比如 C4.5决策树。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/article/detail/52888
推荐阅读
相关标签

