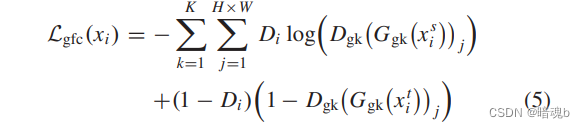- 1rasterio介绍以及代码
- 2篇三:让OAuth2 server支持密码模式_oauth2authorizationgrantauthenticationtoken
- 3Django 自定义权限管理系统(通过中间件认证)_中间件对指定的文件配置权限认证
- 4Confluent kafka rest实战
- 5关于Gitee的安装与概述_gitee安装
- 6SF相关1111
- 7补: Codeforces Round #698 (Div. 2)_codeforces round #698 (div. 2) c
- 8基于微信小程序+SpringBoot的私家车位共享系统小程序(源码+文档+部署+讲解)
- 9Codeforces Round #828 (Div. 3) 题解(A-E2)_828 codeforces
- 10Mac 系统安装 PyCharm 并使用_mac安装pycharm
R-YOLO
赞
踩
Abstract
提出了一个框架,名为R-YOLO,不需要在恶劣天气下进行注释。考虑到正常天气图像和不利天气图像之间的分布差距,我们的框架由图像翻译网络(QTNet)和特征校准网络(FCNet)组成,用于逐步使正常天气域适应不利天气域。具体来说,我们使用简单而有效的QTNet来生成图像,这些图像继承了正常天气域中的注释,并对两个域之间的间隙进行插值。然后,在FCNet中,我们提出了两种基于对抗性学习的特征校准模块,以局部到全局的方式有效地对其两个领域中的特征表示。
Introduction
基于UDA的方法将知识从源域转移到目标域,以弥补域差距,提高泛化能力。用于对象检测器的最先进的(SOTA)UDA方法主要依赖于对抗性学习来在全局级别和实例级别对齐源图像和目标图像的表示。然而,在一级物体探测器上使用上述方法的问题有两个:
- 全局级别的特征对齐容易发生负迁移,使得UDA模型甚至表现得比模型在源域上更差
- 其次,主要针对受益于区域建议网络的两级检测器设计了实例级特征自适应方法。
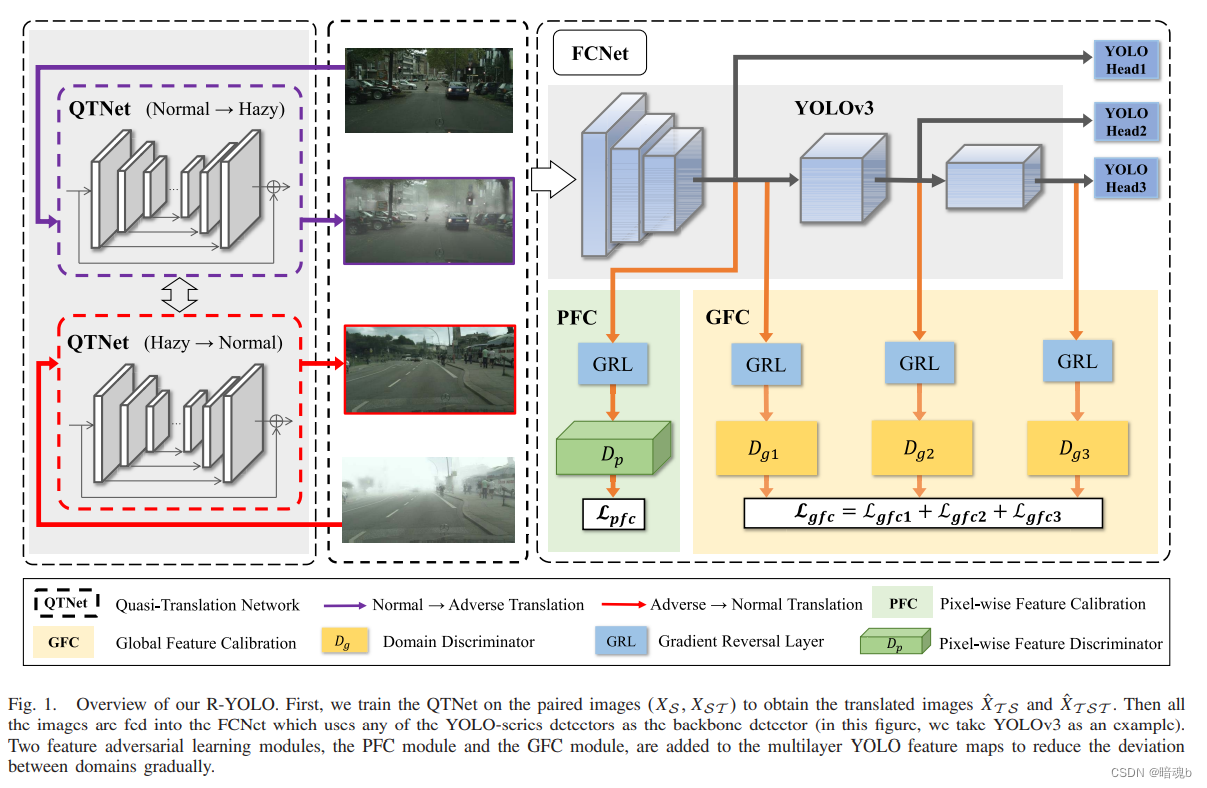
提出了一个R-YOLO网络,包含QTNet(图像翻译网络)和FCNet(特征对齐网络)来逐步减少两个域之间的差异。我们声称,作为预处理步骤,不需要在源域和目标域之间进行严格的翻译,我们只能将图像生成为两个域之间的插值,以指导对抗性学习。因此,我们设计了一个简单而有效的网络来学习残差图像,以在源域和目标域之间进行相互图像翻译。与现有的图像翻译/恢复方法相比,我们的QTNet有三个主要优势: - 它生成具有相同场景但位于不同域的跨域图像,有利于以下基于对抗性学习的特征对齐
- 它不需要对朦胧和雨天图像的先验知识,因此可以统一用于不利图像的翻译任务;
- 易于训练以避免基于GAN的方法的训练问题。
在FCNet中提出了两种对抗性学习模块: - 逐像素特征对齐模块(PFC)
- 全局特征对其模块(GFC)
PFC模块以像素方式对齐低级别特征,以增强前景对象和背景的跨域,这对于降低后续全局特征对齐中的负迁移风险非常重要。
GFC模块使用多尺度特征对抗性训练来全局消除不同域之间特征图上的多样性,并增强对象类别对齐。
主要贡献如下:
- 我们提出了一个统一的一阶段目标检测器训练框架,即R-YOLO,在恶劣天气下,不使用不利领域注释。R-YOLO包含QTNet和FCNet适用于所有YOLO系列检测器,且有着相同的推理速度。
- 设计了一种简单且有效的网络来相互转化正常图像和不利图像以生成两个域之间的插值。我们还建议使用两种对抗性学习模块来逐步减少特征水平上的领域差异。
Method
我们有两个主要目标来提高YOLO在恶劣环境下的性能:
- 在不引入基于GAN的方法的训练问题的情况下,设计一个简单而有效的图像翻译网络来进行数据扩充
- 提出一种为一级检测器量身定制的特征对准网络,避免触发负转移
QTNet
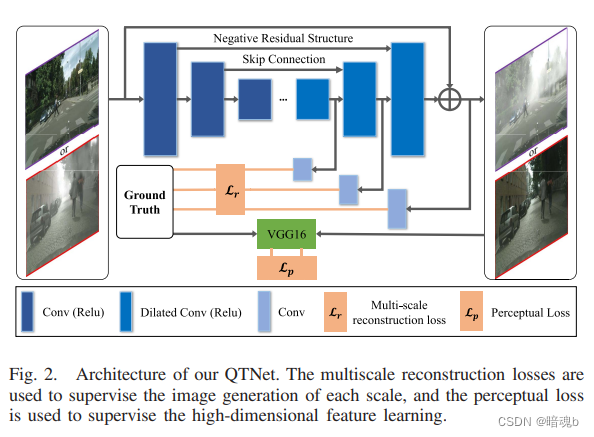
我们的QTNet的目的是设计一个适用于朦胧和雨天图像的统一网络,因此在图像翻译过程中无法探索任何特定于天气的信息或先验信息。受残差图像最近在图像恢复和增强任务中的成功启发,如图像去噪[45]、[46]、[47]和图像阴影去除[48]、[49]、[50],我们设计了带有残差模块的QTNet,以直接缩小从输入到输出的映射范围,使学习过程更容易。我们使用简单的自动编码器作为主干,并添加跳过连接路径,将多层编码器特征融合到解码器特征中。为了改进网络训练过程,我们在自动编码器的输入和输出之间添加了跳跃连接,使其能够学习负残差映射。
具体来说,使用源域和目标域图像XS、XT,我们可以获得合成目标图像,XST。然后,QTNet可以训练成对的XS、XST图像,如果XS被用作输入图像,则XST被用作GT图像,反之亦然。
我们使用多尺度重建损失来监督图像翻译后的语义保存网络训练,可以定义如下:
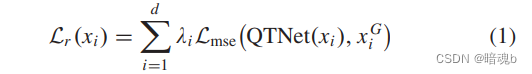
xi是输入图像,QTNet(xi)是输出图像,xiG是xi对应的GT图像。d是损失强制执行的总层数,λi是对应每层的权重参数。注意QTNet训练的都是合成图像,一旦经过训练,就可以被用来翻译图像。我们还使用感知损失来生成逼真图像。具体来说,给定QTNet的输出图像及其相应的GT图像,我们使用预训练的网络,例如在ImageNet上预训练的VGG,来提取上述两幅图像的特征。然后,我们使用这两个特征之间的MSE损失来评估生成图像的真实性,从而感知损失Lp可以指导高真实性图像生成的QTNet训练,可以定义如下:
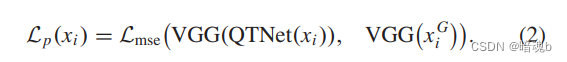
训练QTNet的损失如下:
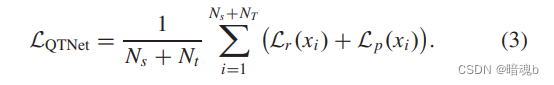
生成的图像的重要性有三个方面,这有利于以下特征自适应步骤:
- 我们可以在目标域中获得大量的注释样本
- 生成的图像可以看作是源域和目标域之间的插值样本,它驱动源域决策边界适应目标域
- 对于大量的跨域图像(具有相同场景但在不同域中的图像),我们可以在不考虑语义不一致问题的情况下对齐两个域中的特征,从而避免负迁移。
FCNet(特征对齐网络)
得益于生成的跨域图像,我们在FCNet中进行了基于对抗性学习的特征对齐,其关键是学习鉴别器无法识别的常见特征分布。为此,我们提出了两种特征校准模块,PFC模块和GFC模块,以消除两个领域在特征水平上的差异。FCNet建立在YOLO主干上,而不改变YOLO网络结构。我们唯一做的事就是添加两种鉴别器和对应损失函数来限制特征学习。
PFC
我们发现,与正常天气相比,恶劣天气下的物体细节和背景之间存在巨大差异。具体来说,悬浮的微小颗粒或快速下落的雨滴首先影响前景对象和背景的颜色、边缘和纹理等低级特征,然后导致对象的草图和语义等高级特征的差异。因此,有必要且相对容易地将每个像素的低水平特征校准为对不利天气具有鲁棒性的共同分布。
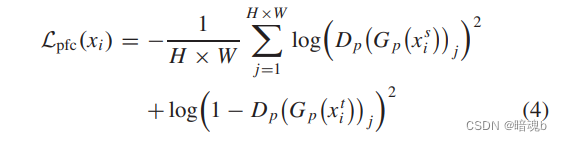
Dp是像素特征鉴别器,在本文中是简单的Conv+sigmoid。Gp(xi)j表示从Gp(xi)获得的特征图中的第j个位置的特征向量,H和W是Gp(xi)的高度和宽度。对于QTNet生成的跨域图像,可以严格保证源图像和目标图像之间的语义一致性。然后,在低级别特征图上实施PFC损失可以以像素方式对齐低级别特征,以有效地增强关于前景对象和背景细节的跨域特征。然后,在低级别特征图上实施PFC损失可以以像素方式对齐低级别特征,以有效地增强关于前景对象和背景细节的跨域特征。
GFC Module
一旦像素级低级别特征被校准,就更容易通过多尺度GFC模块学习图像级对齐的特征表示,例如图像风格、全局亮度和暗度。根据YOLO结构(以YOLOv3为例),其中多尺度特征图被提取并发送到用于收集不同尺度特征图的颈部结构,我们在多尺度特征上强制执行GFC模块。多尺度GFC损失定义如下: