
- 12022 年全国职业院校技能大赛高职组云计算赛项试卷
- 2Eclipse使用配置tomcat服务:Server配置_eclipse server locations
- 3手把手教你使用Python调用 ChatGPT!支持http代理_chatgpt python 代理
- 4SpringBoot使用多线程_springboot 多线程
- 5JDK产品的发展史_jdk历史版本
- 6四次挥手详解
- 7200.【2023年华为OD机试真题(C卷)】求最多可以派出多少支团队(贪心算法-Java&Python&C++&JS实现)
- 8基于云原生的边缘计算在大麦现场的探索应用_基于云原生技术、适配工业场景的边缘云平台设计
- 9Macs Fan Control Pro v1.5.16_macs fan control 1.5.16
- 10Spring Boot(四):Thymeleaf 使用详解_spring thymeleaf
pytorch_小土堆听课笔记_小土堆pytorch 是谁
赞
踩
官网教程:https://pytorch.org/docs/stable/index.html
Pytorch安装
https://zhuanlan.zhihu.com/p/629463313
[[01-study note/Python/安装Anaconda]]
安装目录:D:\ProgramData\anaconda3
安装Pytorch
https://pytorch.org/
安装cuda
cuda安装目录:D:CUDA_install

pytorch部署到jupyter notebook当中使用
https://blog.csdn.net/weixin_45775136/article/details/125800300
切换到Pytorch环境
检查Pytorch是否可用
import torch
torch
-
torch
-
utils
-
data
-
class Dataset():
“”"
数据集本身,并获取label
“” -
class Dataloader():
“”"
加载数据
“”"
-
-
tensorboard
- class SummaryWriter(存放日志的文件夹):
“”"
创建日志
“”"
- class SummaryWriter(存放日志的文件夹):
-
-
-
torchvision
- transforms
张量(一阶、二阶)
一阶张量=一维数组(向量vector)
arr = [1, 2, 3, 4, 5]
二阶张量=二维数组(矩阵matrix)
matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
三阶张量=三维数组
arr = np.array([[[1, 2], [3, 4], [5, 6], [7, 8]]])
python中的库、包、class之间的关系是什么
模块就是一个.py文件
-
包
-
模块
-
函数
-
类呢
-
-
创建模块
模块的调用路径
Python的模块搜索顺序:当前目录——>shell变量下的pythonpath目录——>默认路径
导入模块的过程,就是将模块文件下的函数列举在了本文件中,因此函数可以直接调用。
主程序调用
# 主程序
if __name__=='__main__':
pass
该代码块的内容如果作为主函数,则执行
如果这个py文件被调用,则该代码块不会被调用执行
- 1
- 2
- 3
- 4
- 5
导入模块
import 模块名
import 模块名1,模块名2
from 模块名 import 功能1,功能2
from 模块名 import *(导入该模块的所有功能)
别名:as 别名
创建包
包 = 模块s+__init__.py文件+__pycache__(这个文件是自动生成的)
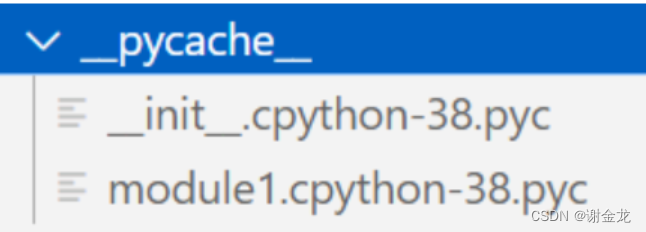
这个init文件的作用:__init__.py 文件的作用是将一个文件夹标记为 Python 包,使得该文件夹下的模块可以被导入和使用。同时,它还可以包含包的初始化代码,例如导入其他模块或者定义变量等。
导入包的方法和导入模块的方法一致
当调入的模块不在同一文件夹该如何处理?
创建子模块
先创建子包,然后在子包里面添加模块
包 = 模块s+__init__.py文件+__pycache__(这个文件是自动生成的)
模块组成包(库)
torch的层级关系
nn """ 模型 """ torch.utils.data class Dataset(): """ 数据集本身,并获取label """ pass class Dataloader(): """ 加载数据 """ torch.utils.tensorboard class SummaryWriter(存放日志的文件夹): """ 创建日志 """ from torchvision import transforms

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
Dataset与Dataloader
以创建图片数据集为例,创建dataset的核心在于将图片文件夹转换为list类型,每个图片都是列表中的一个元素,因为转换为list类型,方便取值操作。同样的label文件夹也是如此
import os import torch from PIL import Image from torch.utils.data import Dataset from torch.utils.data import DataLoader from torchvision import transforms class My_data(Dataset): """ 需要干以下几件事 init:核心在与拿到image_list,label_list getitem:核心在与拿到每个图片对应的label,需要创建索引 len:核心在于计算image_list的长度 """ def __init__(self,root_dir,img_dir,label_dir): self.root_dir=root_dir self.image_path=os.path.join(root_dir,img_dir) self.label_path=os.path.join(root_dir,label_dir) self.image_list=os.listdir(self.image_path) self.label_list=os.listdir(self.label_path) # 对image list与label list排序,才能对应 self.image_list.sort() self.label_list.sort() def __getitem__(self, index): # 创建索引 img_name=self.image_list[index] label_name=self.label_list[index] # 打开图片和她对应的label img_name_path=os.path.join(self.image_path,img_name) label_name_path=os.path.join(self.label_path,label_name) with open(img_name_path,'r') as f: label=f.readline() img = self.transform(img) sample = {'img': img, 'label': label} return sample def __len__(self): return len(self.image_list) if __name__=='__main__': transform = transforms.Compose([transforms.Resize((256, 256)), transforms.ToTensor()]) # compose 将这两个操作变成一个,totensor,变成tensor张量的形式 ant_datasets=My_data('C:\\Users\\x1352\\Desktop\\tudui_data\\练手数据集\\train','ants_image','ants_label') my_dataloader=Dataloader(ant_datasets,batch_size=1,num_workers=2) # ant_datasets是数据集,batch_size是批次(也就是说将一个数据集分为几批),num_workers:用于并行加载数据的工作线程数。设置为0表示在主进程中加载数据,设置为大于0的值表示在后台使用多个线程加载数据。默认值为0。多线程可以并行执行任务,提高速度 for i,j in enumerate(my_dataloader): print(i, j['img'].shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
Tensorboard
add_scalar:
from torch.utils.tensorboard import SummaryWriter
my_writer=SummaryWriter('my_log3')
for a in range(100):
my_writer.add_scalar('title',6*a+5,a)
my_writer.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
运行my_logk日志文件夹:tensorboard --logdir=my_log --port=6007
add_image:
import numpy as np
import torch
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
my_writer=SummaryWriter(log_dir='my_logs_dir')
imag_PIL=Image.open('20230815170426.jpg')
# img_PIL.show()
# 将img_PIL转换为tensor格式
imag_tensor=torch.tensor(np.array(imag_PIL))
print(imag_tensor.shape)
my_writer.add_image('tagtitle4',imag_tensor,global_step=4,dataformats='HWC')
my_writer.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
torchvision
transform
from PIL import Image from torch.utils.tensorboard import SummaryWriter from torchvision import transforms import torch import numpy as np # 创建一个writer实例 writer=SummaryWriter('loggg') img=Image.open('20230815170426.jpg') print(type(img)) # 创建to tensor工具(实例化) tensor_trans=transforms.ToTensor() img_tensor1=tensor_trans(img) writer.add_image('source_img',img_tensor1) # print(type(img_tensor1)) # print(img_tensor1) # 其实也可以直接torch.tensor(np array)也能实现同样的效果 # img_tensor2=torch.tensor(np.array(img)) # print(type(img_tensor2)) norm_tool=transforms.Normalize([0.5,0.6,0.7],[0.8,0.8,0.8]) img_tensor1_norm=norm_tool.forward(img_tensor1) writer.add_image('source_img_norm',img_tensor1_norm) # print(img_tensor1_norm) writer.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
下载CIFAR10数据集
# 下载CIFAR10数据集
import torchvision.datasets as datasets
train_data=datasets.CIFAR10('CIFAR_train',train=True,download=True)
test_data=datasets.CIFAR10('CIFAR_test',train=False,download=True)
# print(train_data[0])
# print(train_data.classes)
img,target=train_data[0]
print(target)
print(train_data.classes[target])
print(img)
img.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
model
import torch from torch import nn class my_Model(nn.Module): def __init__(self,name): super().__init__() self.name=name def forward(self,input): output=3*input+2 return output model1=my_Model('Tom') print(model1.name) result=model1.forward(1) print(f'前向传播的结果是:{result}')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
forward函数的调用
直接:对象(传入forward函数的参数)==对象.forward(传入forward函数的参数)
为什么x = self.conv1(x)可以省略.forward?
- 在Python编程语言中,
x = self.conv1(x)可以省略.forward()方法,因为在定义类时,如果继承了torch.nn.Module,那么该类就会自动拥有__call__()方法。__call__()方法会将self.conv1(x)的计算过程封装起来,当调用该类的实例时,就会执行__call__()方法。因此,x = self.conv1(x)相当于调用了__call__()方法,从而实现了前向传播的过程。
class Tudui(nn.Module): def __init__(self): super(Tudui, self).__init__() self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0) def forward(self, x): x = self.conv1(x) return x 这段代码是不是和以下代码等效?x传递给self.conv1,我们实际上是在调用该层的前向传播方法,以便对输入数据进行处理并生成输出结果。这个输出结果将作为下一层或最终的预测结果使用。 class Tudui(nn.Module): def __init__(self): super(Tudui, self).__init__() self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0) def forward(self, x): x = self.conv1.forward(x) return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
卷积操作实例
import torch import torchvision from torch import nn from torch.nn import Conv2d from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter from PIL import Image # 定义模型 class my_model(nn.Module): def __init__(self): super(my_model, self).__init__() # 卷积层实例,输入channel=3,输出channel=6,卷积核:3x3,step=1,padding=0 # 这段代码中,卷积核的9个元素没有明确定义。在PyTorch中,卷积层的权重是通过nn.Parameter类自动初始化的。默认情况下,这些权重是随机初始化的,范围在-1到1之间。如果你想自定义权重,可以在__init__方法中使用nn.init模块进行初始化。所以这段代码的img3的张量输出结果是不一致的 self.conv_1=Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=1) def forward(self,input): x=self.conv_1(input) return x my_CNN=my_model() # 准备数据 img=Image.open('6aa3baf260a16ee94c11dab0d498a0c0.jpg') trans_tensor=torchvision.transforms.ToTensor() img2=trans_tensor(img) print(img2.shape) # torch.Size([3, 1280, 2048]) # 传入模型 img3=my_CNN(img2) # 输出结果 print(img3.shape) # torch.Size([6, 1280, 2048]) print(img3)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
图片相关操作
from PIL import Image
img=Image.open('6aa3baf260a16ee94c11dab0d498a0c0.jpg')
img.show()
也可以将图片转换为tensor方便后续操作
- 1
- 2
- 3
- 4
卷积函数
F是面向过程的写法,class是面向过程的写法
需要自定义卷积核
F.conv2d(input,weight,bias…)
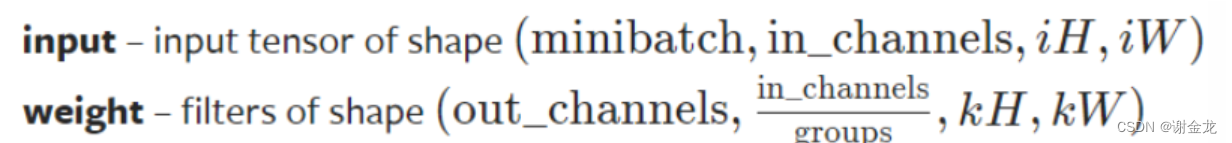
import torch import torch.nn.functional as F from PIL import Image from torchvision import transforms img = torch.tensor([[1, 2, 0, 3, 1], [0, 1, 2, 3, 1], [1, 2, 1, 0, 0], [5, 2, 3, 1, 1], [2, 1, 0, 1, 1]]) my_kernel=torch.tensor([[1,2,1],[0,1,0],[2,1,0]]) img=torch.reshape(img,(1,1,5,5)) my_kernel=torch.reshape(my_kernel,(1,1,3,3)) output=F.conv2d(img,my_kernel) print(output)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
关于class的传参问题
class lei(a):
def __init__(self,c,d):
super(lei,self).__init__()
def forward(e,f)
pass
a不是参数,而是继承的类
c,d的参数,会在创建对象的时候,调用这个方法.同时也调用了父类a的init方法,所以父类a 的init方法中参数也要传递
dog=lei(c=1,d=2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
池化层
import torch from torch import nn class my_model(nn.Module): def __init__(self): super(my_model, self).__init__() self.pooling1=nn.MaxPool2d(kernel_size=3,stride=1,padding=0) def forward(self,input): # 或者output=self.pooling1.forward(input) output=self.pooling1(input) return output polpol=my_model() x=torch.tensor([[[10, 12, 12], [18, 16, 16], [13, 9, 3]]]).float() result=polpol.forward(input=x) print(result)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
线性层
import torch
from torch import nn
class my_model(nn.Module):
def __init__(self):
super().__init__()
self.def_linar=nn.Linear(20,30)
def forward(self,x):
out=self.def_linar(x)
return out
x = torch.randn(128, 20)
model1=my_model()
my_out=model1.forward(x=x)
print(my_out.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
非线性层(激活函数层)
激活函数理论汇总
Multi-Head-Attention层
初始化
def __init__(self):
super().__init__()
再iniit中用class创造工具,使得对象创建后可以直接调用函数,而无需重新创造工具
但事实上,真正的对象其实用到比较少,往往再forward里面的对象直接用这个def工具的情况较多
- 1
- 2
- 3
- 4
Sequential

对比
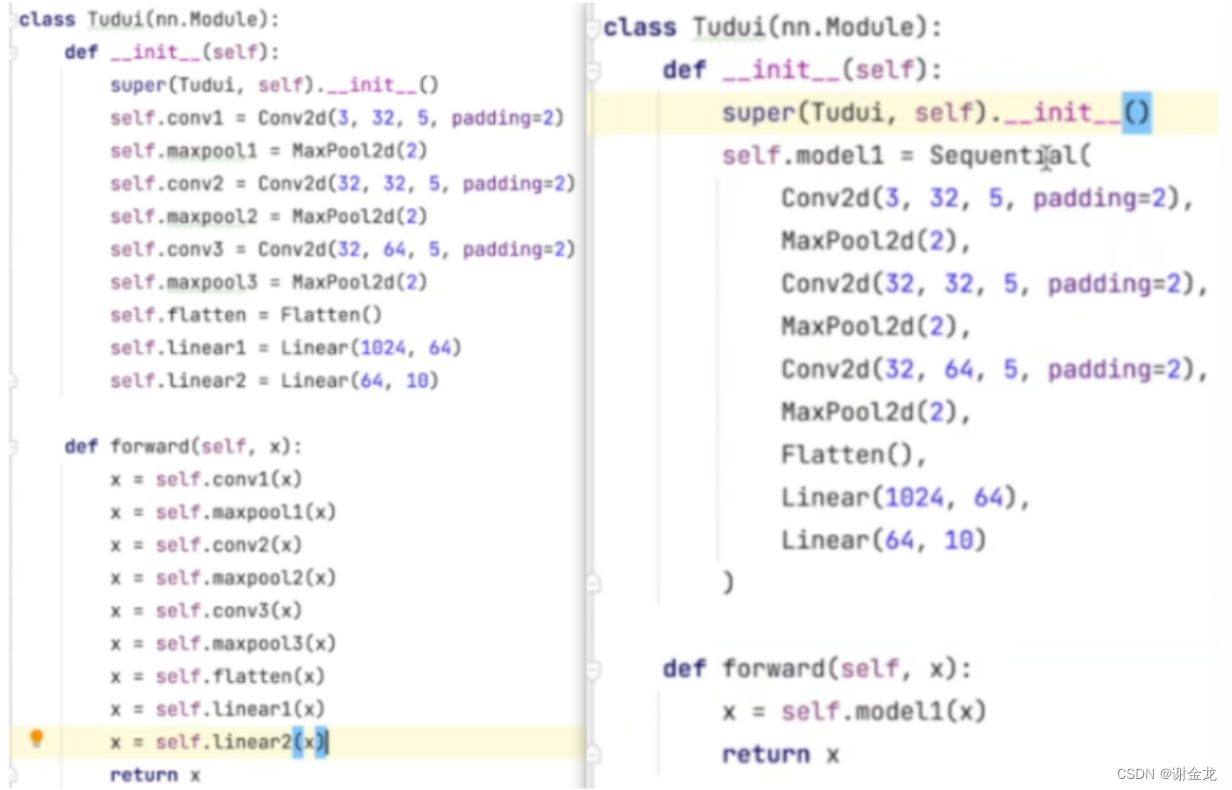
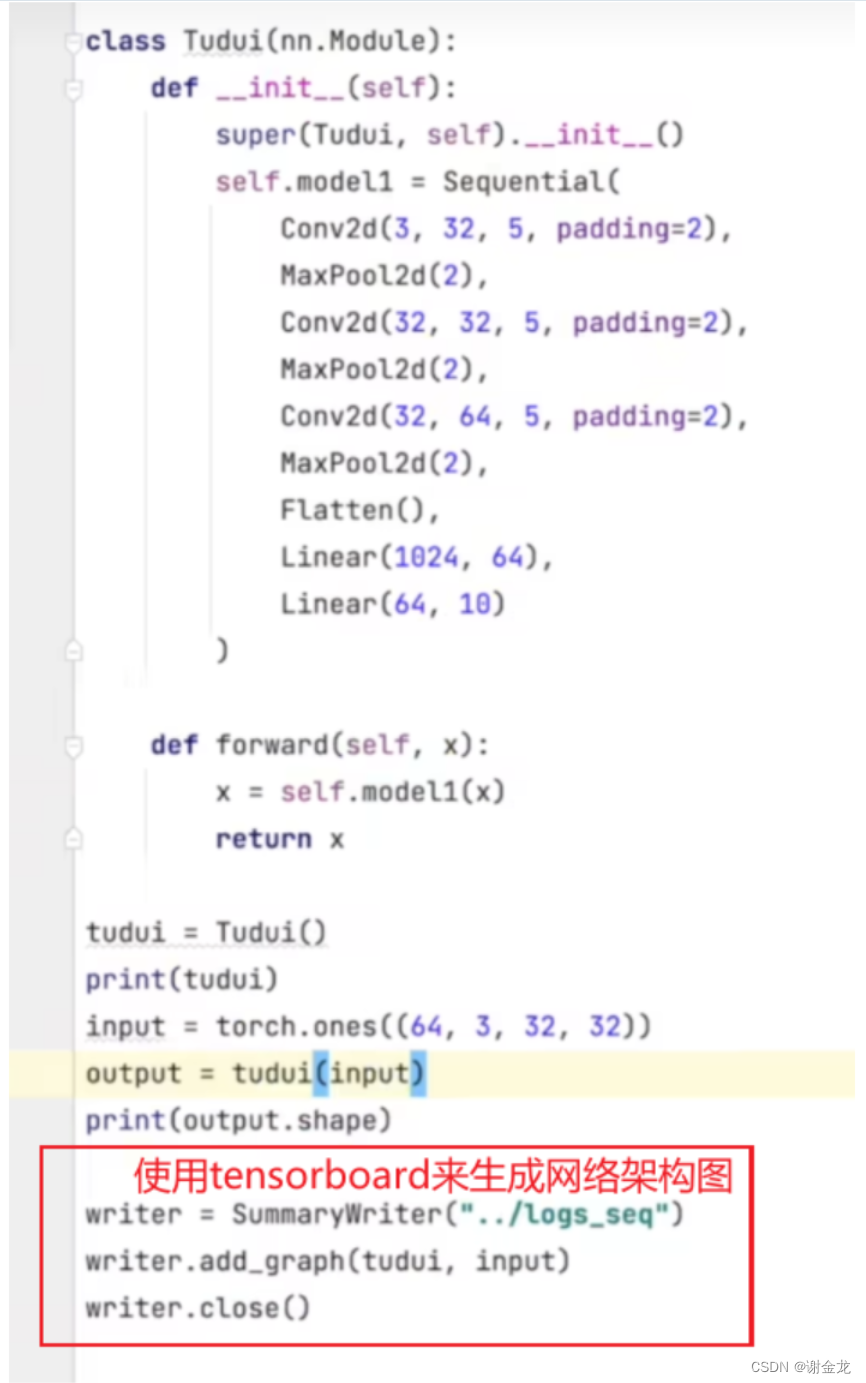
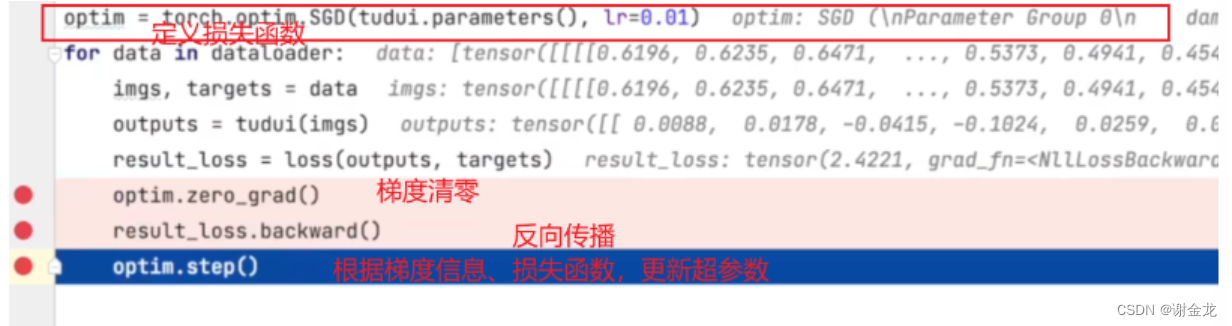
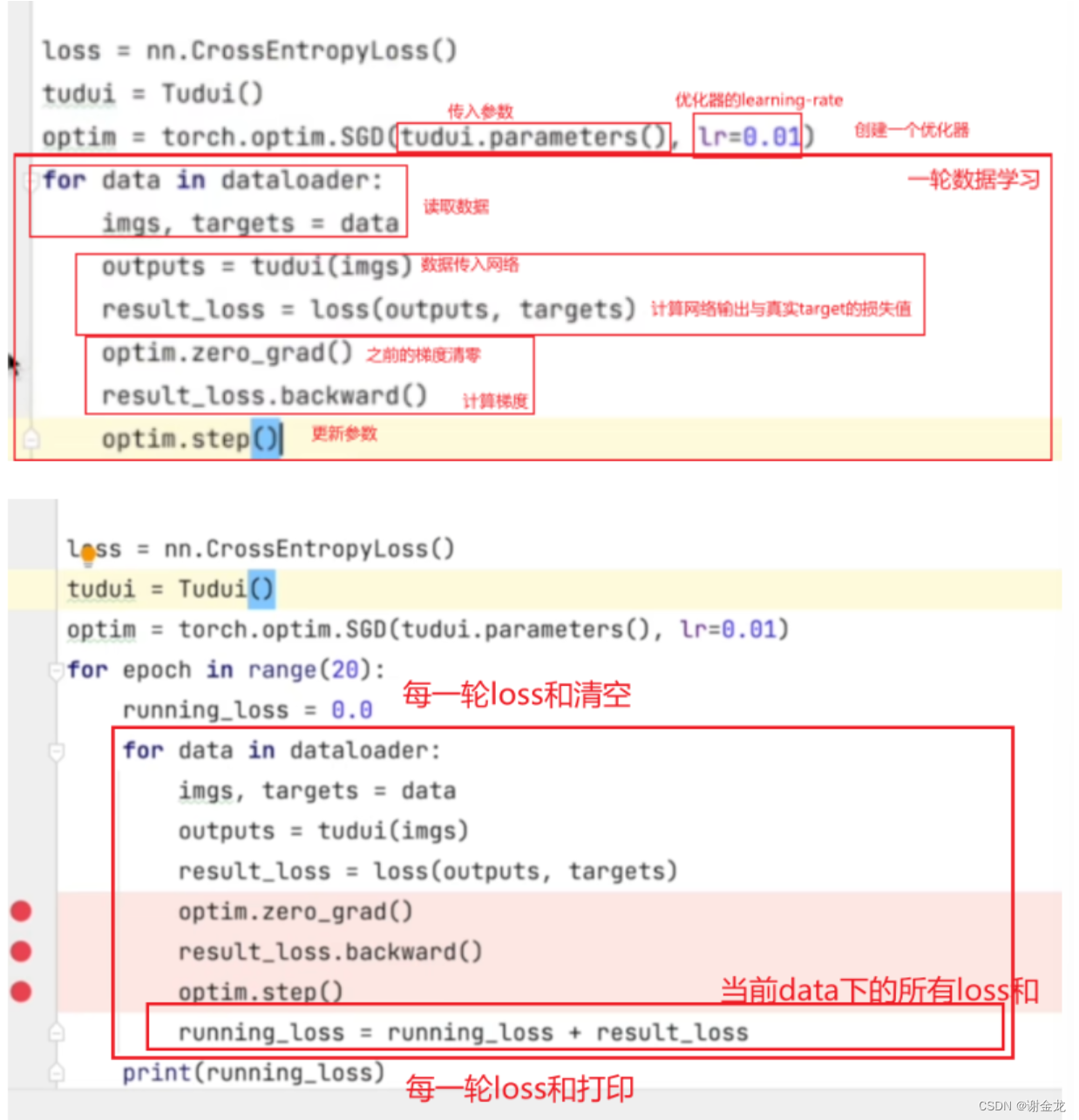
优化器
优化器的作用是根据梯度信息与损失函数,来更新参数
class(参数1,参数2)
参数指的是init传递的参数
__init__表示在创建对象时候传递的参数
损失函数
L1Loss
import torch import torch.nn as nn # 创建L1Loss实例 l1_loss_mean = nn.L1Loss(reduction='mean') l1_loss_sum = nn.L1Loss(reduction='sum') l1_loss_none = nn.L1Loss(reduction='none') # 准备输入数据 input = torch.tensor([1.0, 2.0, 3.0]) target = torch.tensor([2.0, 2.0, 2.0]) # 计算损失值 loss_mean = l1_loss_mean(input, target) loss_sum = l1_loss_sum(input, target) loss_none = l1_loss_none(input, target) print("Mean reduction:", loss_mean) print("Sum reduction:", loss_sum) print("None reduction:", loss_none) """ Mean reduction: tensor(0.6667) Sum reduction: tensor(2.) None reduction: tensor([1., 0., 1.]) """
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
MSELoss
import torch import torch.nn as nn # 创建L1Loss实例 l1_loss_mean = nn.L1Loss(reduction='mean') l1_loss_sum = nn.L1Loss(reduction='sum') l1_loss_none = nn.L1Loss(reduction='none') # 准备输入数据 x = torch.tensor([1.0, 2.0, 3.0]) y = torch.tensor([2.0, 2.0, 2.0]) # 计算损失值 my_loss=nn.MSELoss(reduction='mean') output=my_loss(input=x,target=y) print(output)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
CrossEntropyLoss
import torch import torch.nn as nn # 创建L1Loss实例 l1_loss_mean = nn.L1Loss(reduction='mean') l1_loss_sum = nn.L1Loss(reduction='sum') l1_loss_none = nn.L1Loss(reduction='none') # 准备输入数据 x = torch.tensor([1.0, 2.0, 3.0]) y = torch.tensor([2.0, 2.0, 2.0]) # 计算损失值 my_loss=nn.CrossEntropyLoss(reduction='mean') output=my_loss(input=x,target=y) print(output)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
loss与优化器训练
现有模型的使用和修改
模型的保存
保存方式一
torch.save(vgg16,"vgg16_method1.pth")
vgg16是模型,vgg16_method1.pth是保存的模型文件(一般常见的是以.pth结尾的)
模型加载一
model=torch.load("vgg16_method1.pth")
保存方式二
torch.save(vgg16.state_dict(),"vgg16_method2.pth")
这种是只保存了模型参数,而且是官方推荐的
模型加载二
model=torch.load("vgg16_method2.pth") # 只加载了参数
vgg16=torchvision.models.vgg16(pretrained=False) # 载入了没有训练参数的vgg16模型
vgg16_load_state_dict(torch.load("vgg16"))
- 1
- 2
- 3
- 4
import torch import torchvision from torch import nn # 陷阱 class Tudui(nn.Module): def __init__(self): super(Tudui, self).__init__() self.conv1 = nn.Conv2d(3, 64, kernel_size=3) def forward(self, x): x = self.conv1(x) return x tudui = Tudui() # torch.save(tudui, "tudui_method1.pth") # 10kb模型 torch.save(tudui.state_dict(), "tudui_method2.pth") # 9kb模型,只保存参数,字典类型 # 大小可能与导包有关系,少import,或者多使用from import,使用啥,导入啥
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
不管使用的保存模型的方式是方式一还是方式二,我们通常都会将模型架构class(不需要实例化)单独放在一个文件中,然后在训练时,from import
相对路径
根目录是项目根目录,而不是当前文件所在的目录
模型的创建、保存、加载实例
model.py
from torch import nn
class my_model(nn.Module):
def __init__(self):
super(my_model, self).__init__()
def forward(self, x):
y = 2*x+3
return y
duixiang=my_model()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
my_save.py
import torch
from torch import nn
from model import *
# 保存模型方式一,不用实例化,直接保存class
torch.save(my_model,"./save_and_load_example/my_model_v1.pth")
# 保存模型方式二,必须实例化
torch.save(duixiang.state_dict(),"./save_and_load_example/my_model_v2.pth")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
my_load.py
import torch
from model import *
# 加载方式一保存
moxing1=torch.load('my_model_v1.pth')
# 加载方式二保存
# moxing2=torch.load('C:\\Users\\x1352\\Desktop\\tudui\\save_and_load_example\\my_model_v2.pth') # 加载参数(好像这一行也可以不要)
duixiang.load_state_dict(torch.load('C:\\Users\\x1352\\Desktop\\tudui\\save_and_load_example\\my_model_v2.pth'))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
在实际的使用中,是用到别人的class模型还是pth模型
测试时间
start_time=time.time()
代码块
end_time=time.time()
print(end_time-start_time)
GPU训练
- 实例化模型、损失函数
if torch.cuda.is_available():
duixiang=duixiang.cuda()
loss_func=loss_func.cuda()
- 1
- 2
- 3
- 数据(输入、标注):两个for循环下的(训练+测试,imgs,label)
for data in train_loader:
imgs,label=data
if torch.cuda.is_available():
imgs=imgs.cuda()
label=label.cuda()
for data in test_loader:
imgs,label=data
if torch.cuda.is_available():
imgs=imgs.cuda()
label=label.cuda()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
完整的项目流程
model.py
import torch from torch import nn class my_model(nn.Module): def __init__(self): super(my_model, self).__init__() self.model=nn.Sequential( nn.Conv2d(3,32,5,1,2), nn.MaxPool2d(2), nn.Conv2d(32,32,5,1,2), nn.MaxPool2d(2), nn.Conv2d(32,64,5,1,2), nn.MaxPool2d(2), nn.Flatten(), nn.Linear(64*4*4,64), nn.Linear(64,10) ) def forward(self,x): x=self.model(x) return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
train-test.py
import torch import torchvision from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter from model import * import time start_time=time.time() # ==================01、准备数据==================================== train_data=torchvision.datasets.CIFAR10(root="my_dataset", train=True, transform=torchvision.transforms.ToTensor(), download=True) test_data=torchvision.datasets.CIFAR10(root="my_dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True) print(f'训练集的长度:{len(train_data)},测试集的长度:{len(test_data)}') # 训练集的长度50000,测试集的长度10000 train_loader=DataLoader(dataset=train_data,batch_size=64) #一共有64批,每批长度len=782;782x64=50048 test_loader=DataLoader(dataset=test_data,batch_size=64) #一共有64批,每批长度len=157;157x64=10048 # ===============02、创建实例模型,损失函数,优化器================================== duixiang=my_model() loss_func=nn.CrossEntropyLoss() # if torch.cuda.is_available(): # duixiang=duixiang.cuda() # loss_func=loss_func.cuda() optimizer=torch.optim.SGD(params=duixiang.parameters(),lr=0.01) # 优化器传入实例模型的所有参数,学习率 # ===============03、设置训练初始参数================================================ epoch=10 # 训练的轮数 sum_train_step=0 # 训练集训练的总次数 sum_test_step=0 # 测试集训练的总次数 # ===============04、开始训练======================================================== for i in range(epoch): # 训练步骤包括训练和测试,分别用训练集和测试集 duixiang.train() # 训练======================================================== for data in train_loader: imgs,label=data # if torch.cuda.is_available(): # imgs=imgs.cuda() # label=label.cuda() output=duixiang(imgs) loss=loss_func(output,label) # 优化器设置 optimizer.zero_grad() # 梯度清零 loss.backward() # 反向传播 optimizer.step() # 更新参数 sum_train_step=sum_train_step+1 # 记录训练次数 if sum_train_step % 100 ==0: print(f'已训练{sum_train_step}次') print(f'这是第{i+1}轮训练,此时训练集loss值为:{loss}') duixiang.eval() # 测试(每执行一轮测试一次)============================================= with torch.no_grad(): sum_test_loss=0 for data in test_loader: imgs,label=data # if torch.cuda.is_available(): # imgs=imgs.cuda() # label=label.cuda() output=duixiang(imgs) loss=loss_func(output,label) sum_test_step=sum_test_step+1 if sum_test_step % 10 ==0: print(f'已测试{sum_test_step}次,此时的loss值为:{loss}') sum_test_loss=sum_test_loss+loss # 计算这一轮次的总loss值 print(f'这是第{i+1}轮测试,此时测试集loss值之和为:{sum_test_loss}') # ========================保存模型================================================== torch.save(duixiang,"moxing") end_time=time.time() print(end_time-start_time)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
声明
本笔记是根据b站up“小土堆”的pytorch教程所作,笔记是根据自身的理解做的,并没有完全照搬教程内容,因此可能会与原教程有所出入。

