
热门标签
热门文章
- 1我就不信这些 npm 指令你全知道_npm 如何kill
- 2Spring Boot笔记-拦截器相关(用户权限方面)_interceptor拦截器初步赋子不同类型用户权限
- 3ONLYOFFICE:兼顾协作与安全的开源办公套件
- 41.2 金融数据处理_qstock get_data
- 5【qstock量化】动态交互数据可视化_qstock.data.trade
- 6Spring Boot Thymeleaf 中文乱码_spring boot thymleaf 中文 显示 \u
- 7convertToWorldSpace convertToNodeSpace_converttoworldspace converttonodespace
- 8日志处理--Logo4Net与文件的并发处理_log4net 多线程
- 9mysqldump介绍及使用_mysqldump 表
- 10DoTween全解析(入门篇)
当前位置: article > 正文
【pytorch】从入门到入门 小土堆_小土堆torch安装
作者:数据挖掘灵魂 | 2024-01-31 19:52:52
赞
踩
小土堆torch安装
一、起步
- anacondar的安装
- 虚拟环境的创建
conda create -n pytorch python=3.7.0 - pytorch的安装,上pytorch官网复制命令即可
本人是使用conda安装 cpu环境的
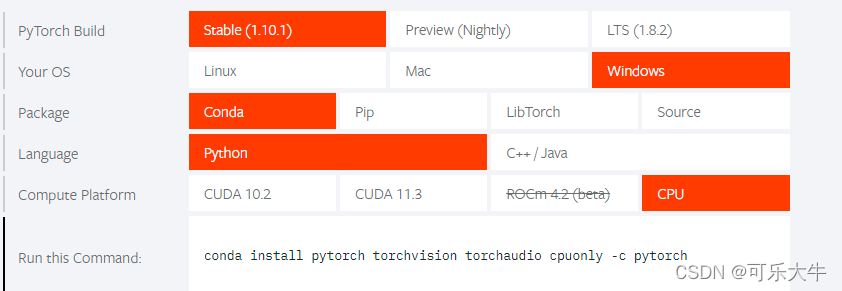
- opencv的安装
conda install -c https://conda.anaconda.org/menpo opencv - 编码环境:pycharm、jupyternotebook、和pycharm内置的python控制台
- 学习法宝:dir()函数和help()函数
pycharm快捷键:
- ctrl+p 显示参数
二、学习
加载数据集:
- Dataset ->提供一种方式去获取数据及其label
- Dataloader->为后面的网络提供不同的数据形式
练习DataSet的使用,创建自己的数据集类别
数据集没有对应的label标签 直接使用文件夹名作为标签
数据集形式为:

学习代码为:
from torch.utils.data import Dataset import os from PIL import Image # 数据集类 必须继承Dataset 实现__getitem__(获取每一个数据及其label)和__len__方法(一共有多少数据) class MyData(Dataset): # root_dir是训练集 label_dir是本来应该是label文件夹 但是由于这个文件夹的label就是文件夹名称 就更方便了 def __init__(self,root_dir,label_dir): # self相当于创建类的成员变量 self.root_dir=root_dir self.label_dir=label_dir # 图片集合的路径 self.path=os.path.join(self.root_dir,self.label_dir) # 存放所有图片名称的集合 self.img_path_list=os.listdir(self.path) def __getitem__(self, idx): img_name=self.img_path_list[idx] img_item_path=os.path.join(self.path,img_name) img=Image.open(img_item_path) # 因为label就是文件夹的名字 label=self.label_dir return img,label def __len__(self): return len(self.img_path_list) root_dir="dataset/train" ants_label_dir="ants" bees_label_dir="bees" ants_dataset=MyData(root_dir,ants_label_dir) bees_dataset=MyData(root_dir,bees_label_dir) train_dataset=ants_dataset+bees_dataset

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
标准的数据集 两个文件夹下的jpg文件和txt文件一一对应
数据集形式为:

学习代码为:
from torch.utils.data import Dataset from PIL import Image import os class MyData(Dataset): def __init__(self,root_dir,data_dir,label_dir): self.root_dir=root_dir self.data_dir=data_dir self.label_dir=label_dir self.img_path=os.path.join(self.root_dir,self.data_dir) self.img_path_list=os.listdir(self.img_path) def __getitem__(self, idx): img_name=self.img_path_list[idx] img_item_path=os.path.join(self.img_path,img_name) img=Image.open(img_item_path) label_item_path = os.path.join(self.img_path, img_name) with open(label_item_path, "r") as f: label = f.read() return img,label def __len__(self): return len(self.img_path_list) root_dir="dataset2\\train" ants_data_dir="ants_image" ants_label_dir="ants_label" bees_data_dir="bees_image" bees_label_dir="bees_label" ants_dataset=MyData(root_dir,ants_data_dir,ants_label_dir) bees_dataset=MyData(root_dir,bees_data_dir,bees_label_dir) train_dataset=ants_dataset+bees_dataset
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
tensorboard相关
安装 tensorboard:
pip install tensorboard
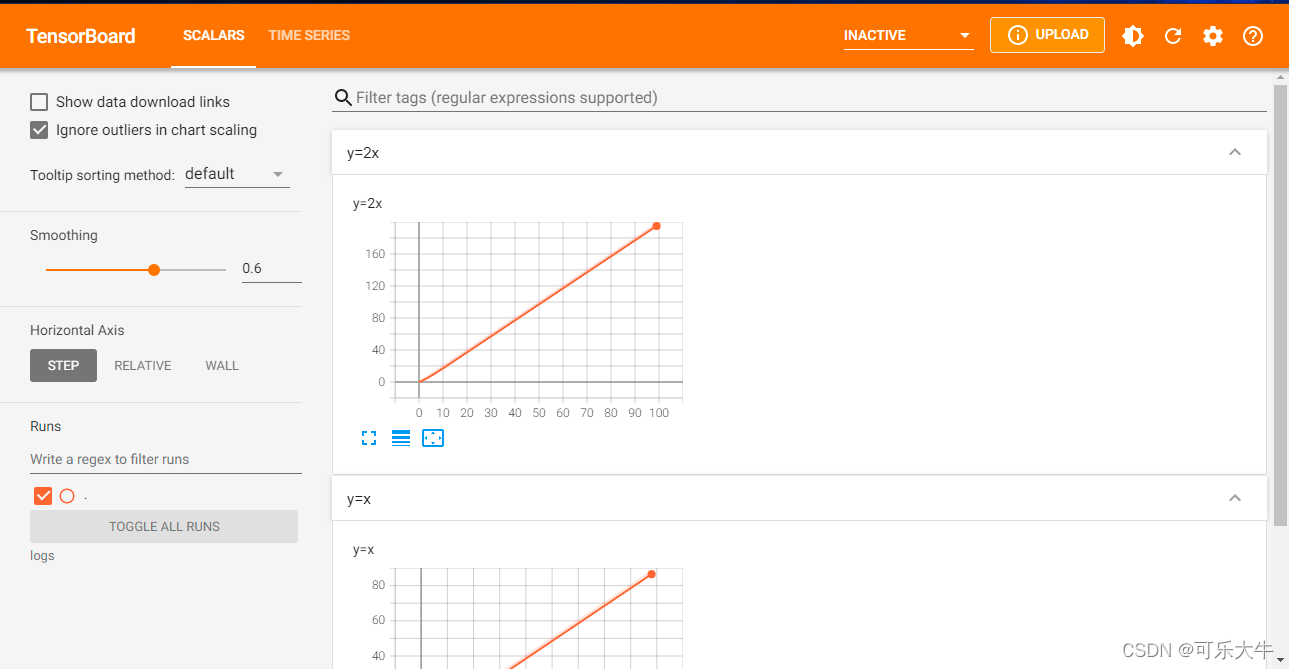
write.add_scalar
使用:
from torch.utils.tensorboard import SummaryWriter
write =SummaryWriter("logs")
for i in range(100):
# 常用参数 前三个 标题 y轴 x轴
write.add_scalar("y=x",i,i)
write.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
打开生成的文件,当前目录下:tensorboard --logdir=logs --port=6007 这个logs就是创建SummaryWriter实例时候传入的文件名

write.add_image()
使用:
from torch.utils.tensorboard import SummaryWriter
import cv2
import numpy as np
write =SummaryWriter("logs")
# 我们之前使用PIL.image读图片 读出来是PLT巴拉巴拉类型的 但是这里的图片要numpy型的 只能用opencv读了
img_path="dataset/train/bees/16838648_415acd9e3f.jpg"
img=cv2.imread(img_path)
# img.shape ->(512, 768, 3)分别是高度 宽度 通道 按照函数的要求 添加参数dataformats='HWC'
write.add_image("test",img,1,dataformats='HWC')
write.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
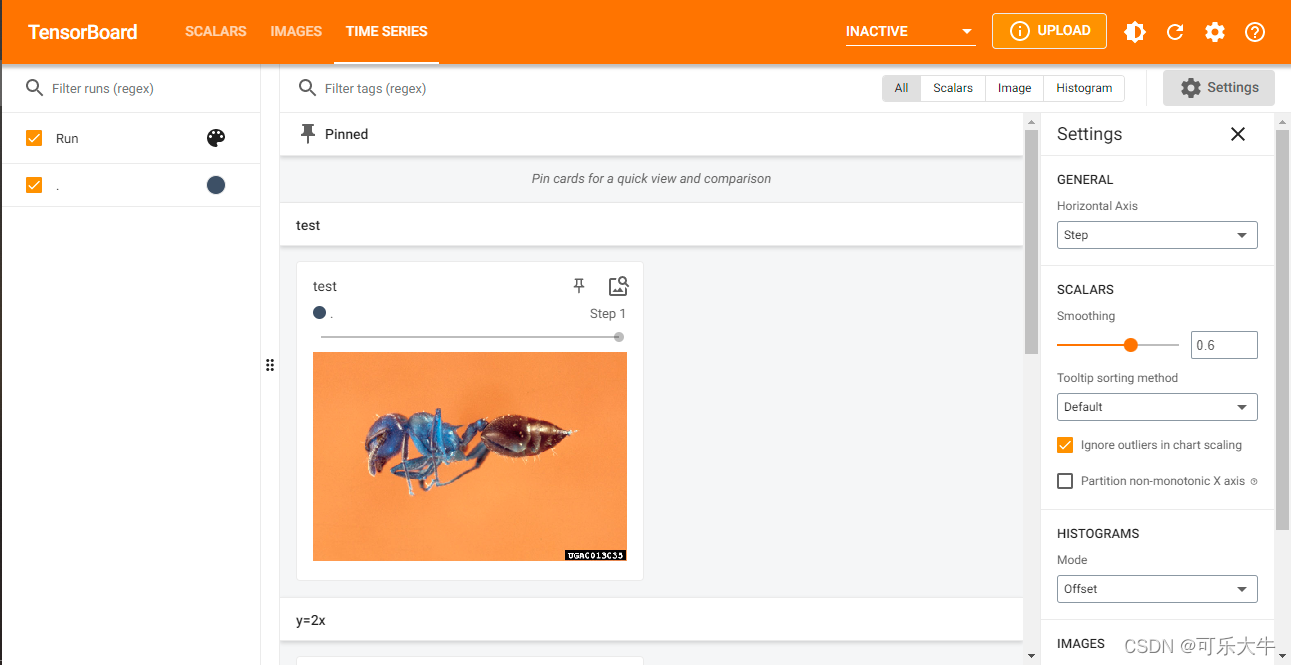
效果:
Transforms相关
核心作用:将一些图片进行特定的图片变换
常用类:
ToTensor 作用:Convert a
PIL Imageornumpy.ndarrayto tensor
ToPILImage作用:Convert a tensor or an ndarray to PIL Image
Resize:Resize the input image to the given size
小案例:
import cv2
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
img_path="dataset/train/ants/0013035.jpg"
img=cv2.imread(img_path)
# 1、使用ToTensor类
to_tensor=transforms.ToTensor()
# tensor_img=to_tensor(img) 也行 因为是call
tensor_img=to_tensor.__call__(img)
# 2、tensor作用:包装了神经网络理论基础的一些参数
write = SummaryWriter("logs")
write.add_image("tensor_img",tensor_img)
write.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
效果:


使用torch自带的数据集
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_set =torchvision.datasets.CIFAR10("./dataset",train=True,transform=dataset_transform,download=True)
test_set =torchvision.datasets.CIFAR10("./dataset",train=False,transform=dataset_transform,download=True)
write=SummaryWriter("logs")
for i in range(10):
img,target = test_set[i];
write.add_image("test_set",img,i)
write.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
DataLoader
常见参数:dataset是我们准备的数据集,batch_size是一次取几个数据,shuffle:每次数据顺序是否相同,num_workers:几个进程(默认值为0 多个进行在windows下可能会有问题),drop_last是否舍去最后的余数
import torchvision from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter test_set =torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True) test_loader=DataLoader(dataset=test_set,batch_size=4,shuffle=True,num_workers=0,drop_last=False) write=SummaryWriter("logs") step=0 for data in test_loader: imgs,targets = data write.add_images("test_loader",imgs,step) step+=1 write.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
Module
超级无敌简单的神经网络:
import torch
import torch.nn as nn
class MyModule(nn.Module):
def __init__(self) -> None:
super().__init__()
def forward(self, x):
return x+1
myModule=MyModule()
x=torch.tensor(1.0)
output = myModule(x)
print(output)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
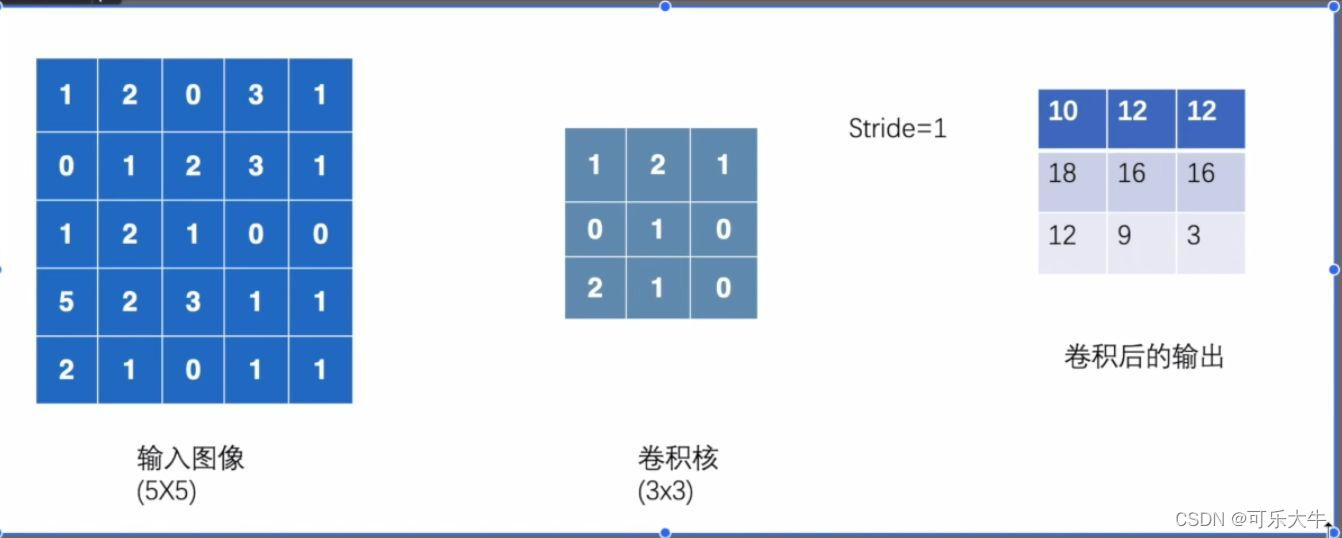
卷积小解释:
卷积就是卷积核在输入图像中移动,每一次卷积核覆盖的位置值和卷积核的值相乘 作为输出,如图像是55的矩阵,卷积核是33的矩阵,他们不断相乘再相加作为输出,输出完之后卷积核移动到下一个位置,继续相乘再相加作为输出
这个移动的步数就是CONV2D中的参数stride ,一个值就是横向和纵向的步数,一个元组就是两个值分别对应横向移动和纵向移动
import torch import torch.nn.functional as F input=torch.tensor([ [1,2,0,3,1], [0,1,2,3,1], [1,2,1,0,0], [5,2,3,1,1], [2,1,0,1,1] ]) kernel=torch.tensor([ [1,2,1], [0,1,0], [2,1,0] ]) # 因为CONV2D要求输入的tensor 是4维的 而我们创建的是二维的所以需要用变换一下 # (1,1,5,5)表示一个通道、batch_size=1、数据是5*5 input=torch.reshape(input,(1,1,5,5)) kernel=torch.reshape(kernel,(1,1,3,3)) output=F.conv2d(input,kernel,stride=1) print(output)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
三、最后总结
模型训练套路
模型结构:
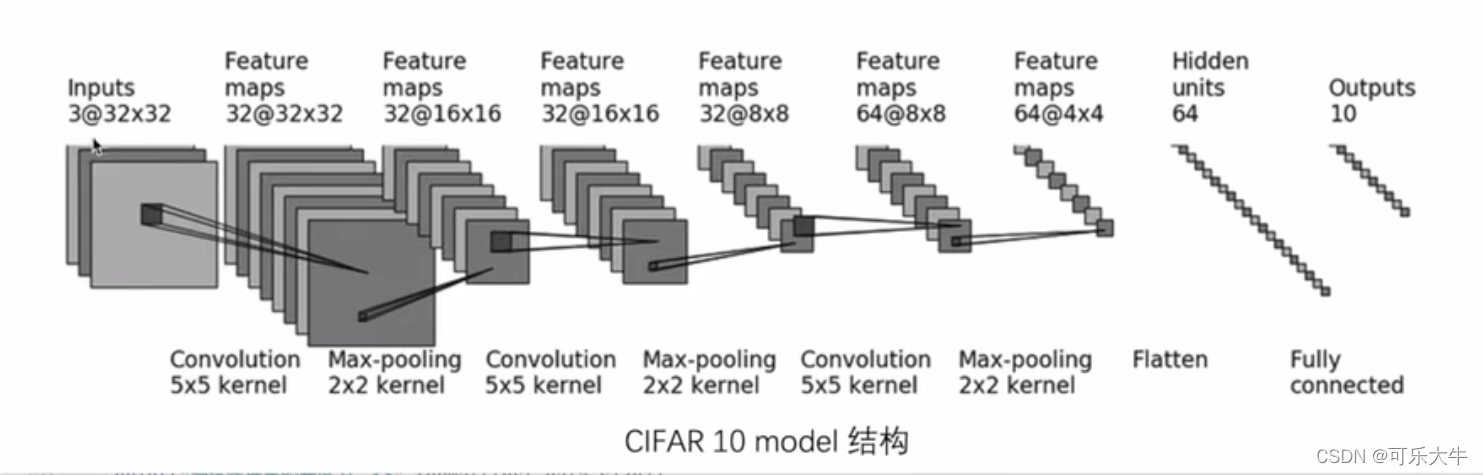
模型:
import torch from torch import nn class CNN(nn.Module): def __init__(self) -> None: super().__init__() self.model = nn.Sequential( # 目标从3通道32*32经过卷积得到32通道32*32 带入公式N=(W-F+2P)/S+1 即(32-5+2padding)/1+1=32 得padding=2 nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2), # 最大池化 得到32通道16*16 nn.MaxPool2d(2), # 目标从32通道16*16经过卷积得到32通道16*16 带入公式N=(W-F+2P)/S+1 即(16-5+2padding)/1+1=16 得padding=2 nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2), # 最大池化 得到32通道8*8 nn.MaxPool2d(2), # 目标从32通道8*8经过卷积得到64通道8*8 带入公式N=(W-F+2P)/S+1 即(8-5+2padding)/1+1=8 得padding=2 nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2), # 最大池化 得到64通道4*4 nn.MaxPool2d(2), # 展平为64*4*4的一维向量 nn.Flatten(), # 全连接 nn.Linear(64 * 4 * 4, 64), nn.Linear(64, 10) ) def forward(self, x): x=self.model(x) return x if __name__ == '__main__': cnn = CNN() # 输出是一组64张图片 三通道 尺寸是32*32 input=torch.ones((64,3,32,32)) # 返回为torch.Size([64, 10]) 即64张图片 每张图片在10个类别中的概率 output=cnn(input)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
训练:
import torch.optim import torchvision from torch import nn from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter from model import CNN # 准备数据集 train_data=torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True) test_data=torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True) train_loader=DataLoader(dataset=train_data,batch_size=64,shuffle=True) test_loader=DataLoader(dataset=test_data,batch_size=64,shuffle=True) # 搭建网络模型 cnn=CNN() # 损失函数 选择交叉熵 loss_fun=nn.CrossEntropyLoss() #优化器选择 随机梯度下降 learning_rate=0.01 optimizer=torch.optim.SGD(cnn.parameters(),lr=learning_rate) # 训练网络的一些参数 total_train_step=0 # 训练的次数 total_test_step=0 # 测试的次数 epoch=10 # 训练的轮数 # 添加tensboard writer=SummaryWriter("./logs") for i in range(epoch): print("第{}轮训练开始".format(i+1)) # 标志开始训练只对某些层管用 torch.train() for data in train_loader: imgs,targets=data outputs=cnn(imgs) loss=loss_fun(outputs,targets) # 梯度清零 损失反向传播 然后优化参数 optimizer.zero_grad() loss.backward() optimizer.step() total_train_step+=1 # loss是一个tensor 使用item方法得到真实的值 如 loss是tensor(5),loss.item()就是5 if total_train_step%100==0: print("训练次数为{}时,损失为{}".format(total_train_step, loss.item())) writer.add_scalar("train_loss",loss.item(),total_train_step) # 测试每一轮训练之后 在测试集上的损失 因为只是测试 不需要对梯度进行调整 torch.eval() # 标志开始测试 只对某些层管用 total_test_loss=0 with torch.no_grad(): for data in test_loader: imgs, targets = data outputs = cnn(imgs) loss = loss_fun(outputs, targets) total_test_loss+=loss.item() print("第{}轮训练结束之后 测试集上的整体损失为{}".format(i+1,total_test_loss)) total_test_step+=1 writer.add_scalar("test_loss", total_test_loss, total_test_step) # 保存每一轮训练的模型 torch.save(cnn,"./path/cnn_{}_path".format(i)) print("模型已经保存") writer.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
结果
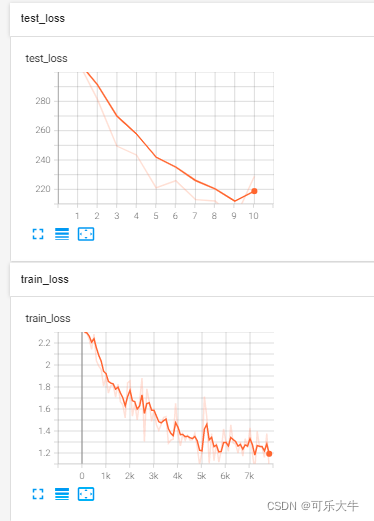
模型验证
import torch import torchvision from PIL import Image from model import CNN image = Image.open("./imgs/002.png") image=image.convert("RGB") transform =torchvision.transforms.Compose([ torchvision.transforms.Resize((32,32)), torchvision.transforms.ToTensor() ]) image=transform(image) # 这个image是3通道的32*32没有batch_size 给他加上 image=torch.reshape(image,(1,3,32,32)) cnn=torch.load("path/cnn_9_path") cnn.eval() with torch.no_grad(): output=cnn(image) print(output.argmax(1)) # 输出是tensor([3]) 而第三个类别是猫 没有预测准确 害
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/article/detail/51871
推荐阅读
相关标签

