
- 1UNet 系列:做医学图像分割的任何人,都必须要会使用 nnU-Net_nnunet和unet区别
- 2Unity-ROS与激光雷达小车搭建(五)_gazebo-unity
- 3confluence 编辑器这次没有加载_【PyCharm】 配置Python环境 加载Pandas包
- 4ST发布M33内核新品STM32U5,首款40nm工艺超低功耗系列,160MHz全速运行19uA/MHz_stm32u5发售日期
- 5HTML5作品展示摄影网站网页模板源码下载_图片展示页面源代码
- 6Index_js setproperty
- 72023年美赛获奖结果分析(附中英文版赛题)_2023美赛
- 8HTML常用标签之标题、段落、换行和水平线标签_写出 标题标记、段落标记
- 9支付宝原生小程序封装组件_支付宝小程序封装公共的js
- 10pyqt写个元旦快乐代码
小土堆Pytorch快速入门-ch01_小土堆 pytorch
赞
踩
1.Pytorch加载数据初步认识
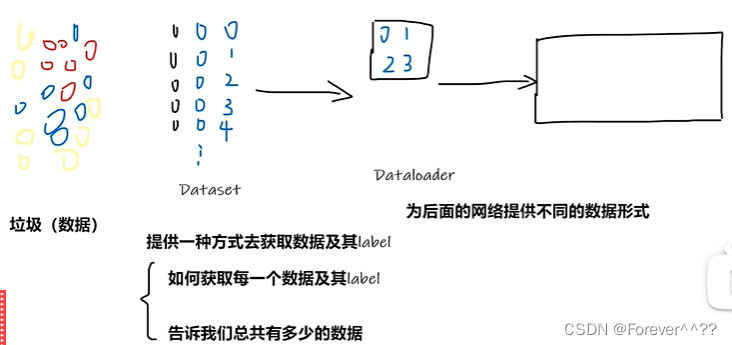
对于一个数据集来说,在使用之前需要把这些数据加载成我们需要的格式。
这地方就需要了Dataset和Dataloader:
1.dateset是告诉我们数据集在什么位置,数据集什么位置是什么东西,
给出一个索引index=0,能够给出哪一个数据
2.dataloader加载器,是从dataset里面取数据,
然后加载到另一个地方(如加载到神经网络)。加载的过程是通过dataloader控制的
from torch.utils.data import Dataset from PIL import Image #通过PIL来导入图片 import os #先继承Dataset类 class MyData(Dataset): #重写里面的三个函数 def __init__(self,root_dir,label_dir): self.root_dir = root_dir self.label_dir=label_dir self.path=os.path.join(self.root_dir,self.label_dir) self.img_path = os.listdir(self.path) def __getitem__(self, idx): img_name = self.img_path[idx] img_item_path = os.path.join(self.root_dir,self.label_dir,img_name) img = Image.open(img_item_path) label=self.label_dir return img,label def __len__(self): return len(self.img_path)#图片列表长度 root_dir = "dataset/train" ants_label_dir = "ants_image" bees_label_dir = "bees_image" ants_dataset = MyData(root_dir,ants_label_dir)#通过输入数据集存放路径和相应的label来创建数据集 bees_dataset = MyData(root_dir,bees_label_dir) train_dataset = ants_dataset+bees_dataset

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
利用Dataset来对自己初始数据进行处理,由原来的ant和bee数据图片,来获得train_dataset和相应的label(例如某条数据图片,label是ant还是bee)。
2.TensorBoard的使用
这里主要使用TensorBoard来展示代码中对图片的处理的过程的展示
np.array
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer = SummaryWriter("logs")#步骤1:初始化,对日志的存放路径
image_path = "dataset/train/ants_image/0013035.jpg"
img_PIL = Image.open(image_path)
img_array = np.array(img_PIL)#需要将图片类型转化为np.array或者下一个代码的tensor类型
writer.add_image("test", img_array, 1, dataformats='HWC')#步骤2:添加,注意添加类型
for i in range(100):
writer.add_scalar("y=2x", i,2*i)
writer.close()#步骤3,关闭
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
tensor类型
这地方涉及transforms,以下会进行讲解
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision.transforms import transforms
writer = SummaryWriter("logs")
img_path = "dataset/train/ants_image/0013035.jpg"
img = Image.open(img_path)
tensor_trans = transforms.ToTensor()#转化为tensor类型
tensor_img = tensor_trans(img)
#使用tensor类型时,是因为add_image时需要曼珠troch.tensor和np.array型。目的是在这地方
#可以科Tensorboard对比,这里用到的是tensor类型,而另一个是np类型
writer.add_image("Tensor_img",tensor_img)
writer.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
对于tensorboard的使用方法:
在终端中输入
tensorboard --logdir=日志存放文件夹
会给出一个链接,打开即可。
3.torchvision中的transforms
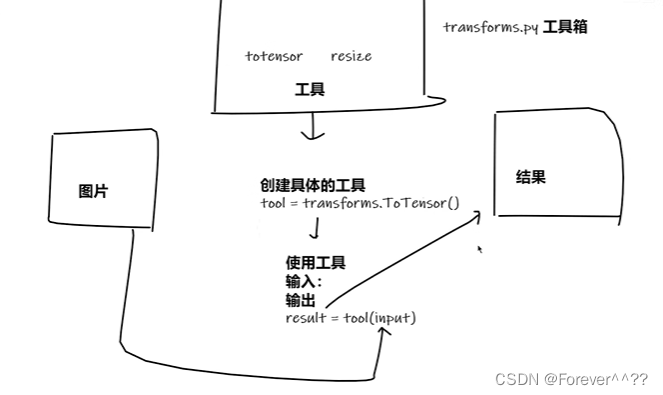
transforms为我们提供了一个强大的工具箱,我们可以通过对transforms的一些函数进行输入一些参数,来构造成我们自身模型的功能函数。以下先举一个例子:
import cv2 from PIL import Image from torchvision import transforms #通过transforms.Totensor去看两个问题 #1.transforms该如何使用 #2.为什么我们需要Tensor数据类型 img_path ="dataset/train/ants_image/0013035.jpg" #导入方法1 img = Image.open(img_path) #print(img) #导入方法2 img2 = cv2.imread(img_path) #可以将transforms看作一个工具箱 #利用transforms的Totensor来创建一个工具 tensor_trans = transforms.ToTensor() #使用工具 tensor_img = tensor_trans(img) print(tensor_img)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
代码中,我们的tensor_trans功能函数,是通过transforms的ToTensor函数创建来的,创建成功后,我们可以直接使用我们自身创建的tensor_trans功能函数来完成相应功能。
以下为几个常用的transform函数:
from PIL import Image from torch.utils.tensorboard import SummaryWriter from torchvision import transforms img_path= "dataset/train/ants_image/0013035.jpg" img = Image.open("dataset/train/ants_image/0013035.jpg") writer = SummaryWriter("logs") '''1.ToTensor的使用,转化为tensor数据类型''' trans_tensor = transforms.ToTensor() img_tensor = trans_tensor(img) writer.add_image("Tensor",img_tensor) '''2.Normalize归一化''' print(img_tensor[0][0][0]) trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) img_norm = trans_norm(img_tensor) print(img_norm[0][0][0]) writer.add_image("Normalize",img_norm,1)#将结果放在第一步 trans_norm = transforms.Normalize([1, 3, 5], [0.5, 0.5, 0.5]) img_norm = trans_norm(img_tensor) writer.add_image("Normalize",img_norm,2)#将结果放在第2步 trans_norm = transforms.Normalize([0.5, 6, 1], [0.5, 0.5, 0.5]) img_norm = trans_norm(img_tensor) writer.add_image("Normalize",img_norm,3)#将结果放在第3步 #注意观察图片的变化 '''3.Resize''' print(img.size) trans_resize = transforms.Resize(512) #数据类型变化 img PIL ->(resize)-> image_resize PIL img_resize = trans_resize(img) # img_resize PIL ->(totensor)-> image_resize tensor img_resize = trans_tensor(img_resize) writer.add_image("Reisze",img_resize,1) '''4.Compose - resize -2''' trans_resize_2 = transforms.Resize(512) #compose就是将多个操作级联起来,本例中compose将trans_resize_2和trans_tensor两个操作级联使用 #相当于多个操作对一个数据时进行顺序使用,必须保证前一个输出是后一个输入,类型保持一致 trans_compose = transforms.Compose([trans_resize_2,trans_tensor]) img_resize_2 = trans_compose(img)#此处输入是img writer.add_image("Resize",img_resize_2,2) '''5.RandomCrop随机裁剪''' trans_random = transforms.RandomCrop(256) trans_compose_2 = transforms.Compose([trans_random,trans_tensor]) for i in range(10): img_crop = trans_compose_2(img) writer.add_image("RandomCrop",img_crop,i) writer.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
4.torchvision中的数据集使用
本例使用的是torchvision提供的CIFAR10数据集
对于数据集的下载
对于torchvision自带的数据集,在进行使用时,直接在dataset时,将download=True即可,因为dataset中的数据集会提供相应的链接。另外也可以自己手动下载,可以使用该链接复制到迅雷加速下载。
对于数据集的dataset
#如何使用torchvision提供的数据集 import torchvision from torch.utils.tensorboard import SummaryWriter dataset_transform = torchvision.transforms.Compose([ torchvision.transforms.ToTensor() ])#此处对transforms的多个操作进行组合,需要注意每个操作的输出和下一个操作输入类型一致。 #获得dataset_transform操作,可以用在对数据集的一个操作dataset.CIFAR10中 train_set = torchvision.datasets.CIFAR10(root="./dataset/CIFAR10",train=True,transform=dataset_transform,download=True)#(数据集路径,是否是训练数据集,对数据集所进行的操作,是否开启下载) test_set = torchvision.datasets.CIFAR10(root="./dataset/CIFAR10",train=False,transform=dataset_transform,download=True) writer = SummaryWriter("logs") for i in range(10): img,label = test_set[i] writer.add_image("test_set",img,i) writer.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
5.Dataloader使用
import torchvision #准备好的测试集合 from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter test_data = torchvision.datasets.CIFAR10(root="./dataset/CIFAR10", train=False, transform=torchvision.transforms.ToTensor()) test_loader = DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=True) ''' dataset=test_data, 从哪个数据集进行加载 batch_size=4, 一批打包总有多少个 shuffle=True, 是否重新”洗牌“,打乱顺序 num_workers=0, 一起运行的进程数,0默认只有一个主进程 drop_last=False 数据集最后一组batch不能达到batch_size,是否舍去 ''' #测试数据集中第一张图片和target img, target = test_data[0] print(img.shape) print(target) writer = SummaryWriter("logs") for epoch in range(2): step = 0 for data in test_loader: imgs, targets = data#这地方的imgs将是用在以后的模型输入 #print(imgs.shape)#打包之后变成,多了一个4维torch.Size([4, 3, 32, 32]) #print(targets) #打包之后变成batch_size长度的tensor([3, 4, 8, 6]) writer.add_images("Epoch:{}".format(epoch),imgs,step) step = step + 1 writer.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
完成Dataloader操作获得的imgs才是后续操作模型的输入
6.神经网络的框架和卷积理解
在构建自己的神经网络过程中,主要是使用torch.nn.Module类,来进行重写里面的函数来构建自己的神经网络。
import torch
from torch import nn
class Tudui(nn.Module):
def __init__(self):
super().__init__()
def forward(self, input):
output = input + 1
return output
tudui = Tudui()#自己构造的Tudui()神经网络类,进行实例化
x = torch.tensor(1.0)
output = tudui(x)#直接进行输入x,由于继承了nn.Module类,Tudui类会自动执行forward函数,得到输出
print(output)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
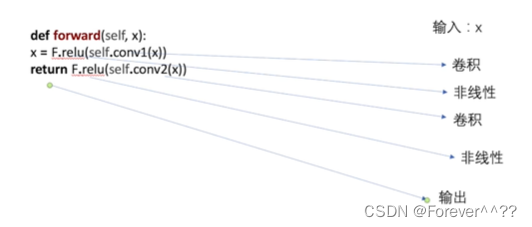
卷积的概述
通过使用torch.nn.functional.conv2d()函数来进行大致介绍:
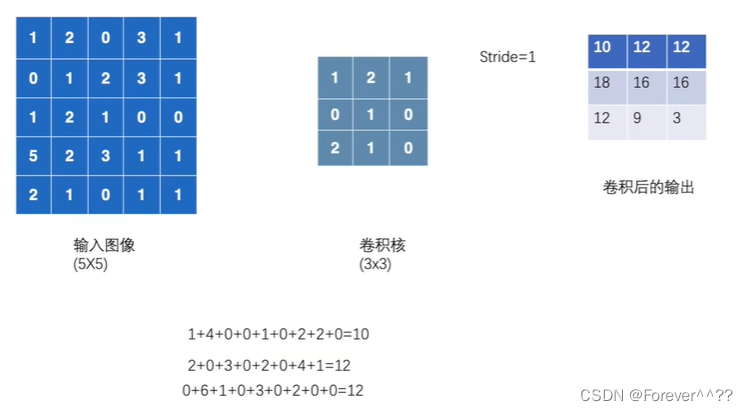
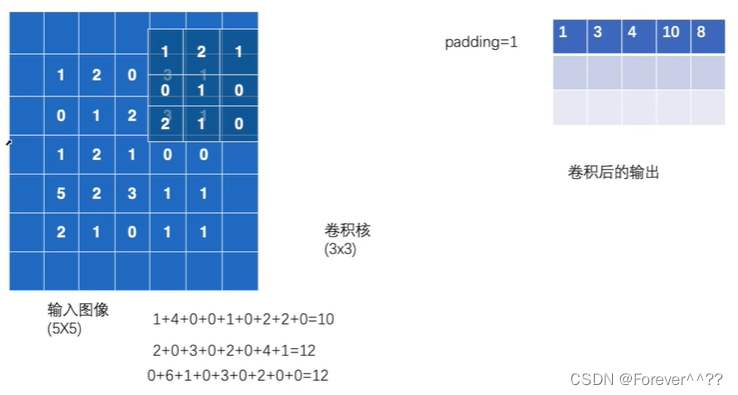
卷积的过程:
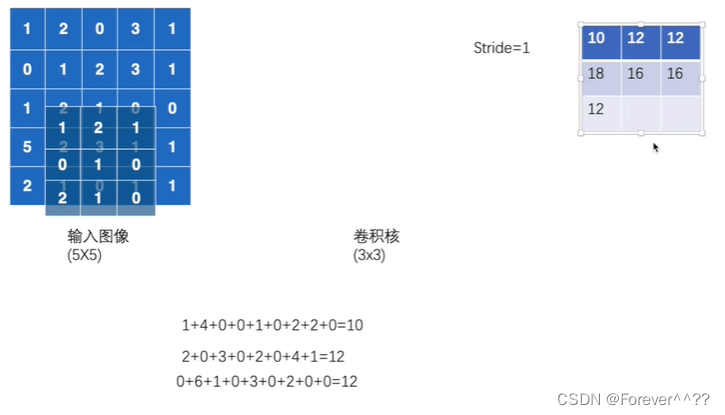
进行填充卷积
''' torch.nn.functional.conv2d() 为卷积函数 一些输入参数: 1.input输入 2.weight权重,即卷积核,对于二维来说,卷积核是2维的,则weight也是二维的 3.bias偏移量 4.stride是步长,卷积核运动的长度,可以为一个列表 5.padding是填充,对input周围进行填充行和列,一般填充默认为0 ''' import torch import torch.nn.functional as F input = torch.tensor([[1,2,0,3,1], [0,1,2,3,1], [1,2,1,0,0], [5,2,3,1,1], [2,1,0,1,1]]) kernal = torch.tensor([[1,2,1], [0,1,0], [2,1,0]])#weight #由于输入时需要input必须满足一个尺寸,input为(minibatch,in_channels,iH,iW) #weight(out_channels, in_channels/groups,kH,kW) #则需要改变input input = torch.reshape(input,(1,1,5,5)) kernal = torch.reshape(kernal,(1,1,3,3)) print(input.shape) print(kernal.shape) output = F.conv2d(input, kernal,stride=1)#卷积 print(output) output2 = F.conv2d(input, kernal,stride=2) print(output2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35

