
热门标签
热门文章
- 1校园网免认证登录的方法-利用udp53端口_校园网可以实现不用验证登录吗
- 2【微服务】Ribbon负载均衡_修改ribbon负载均衡的规则
- 3LeetCode 114. 二叉树展开为链表(一题三吃)
- 4【愚公系列】2023年12月 HarmonyOS教学课程 043-Stage模型(ExtensionAbility组件)
- 5HarmonyOS 应用开发配置—Stage模型以及应用/组件级配置详解【鸿蒙专栏-18】
- 6【愚公系列】2023年12月 HarmonyOS应用开发者基础认证(完美答案)
- 7Java开发 - Elasticsearch初体验_java 写 es
- 8C/C++程序设计课程设计[2023-02-15]_c++网吧管理系统课程设计
- 9亚马逊云科技中国峰会:Amazon DeepRacer——载着 AI 梦想向前奔跑
- 10【ERROR】chaincode install failed with status: 500 - failed to invoke backing implementation xxx
当前位置: article > 正文
flask+echarts+mysql_实战|Python爬虫并用Flask框架搭建可视化网站
作者:编程探险家 | 2024-01-31 18:57:22
赞
踩
flask+python+echarts url:'/query
 大家好,我是J哥,也可以叫我菜J,专注原创,致力于用浅显易懂的语言分享网络爬虫、数据分析、可视化等干货,希望人人都能学到新知识。
项目背景
事情是这样的,最近呢,一直有朋友问我有没有什么办法将每天获得的最新数据进行可视化,并且实现可视化图表自动更新,解放双手。
大家好,我是J哥,也可以叫我菜J,专注原创,致力于用浅显易懂的语言分享网络爬虫、数据分析、可视化等干货,希望人人都能学到新知识。
项目背景
事情是这样的,最近呢,一直有朋友问我有没有什么办法将每天获得的最新数据进行可视化,并且实现可视化图表自动更新,解放双手。
 尤其对于金融行业,如果可以将每天获得的关键行情指标数据自建模型,然后将结果可视化至私有平台,实现每日更新,那确实是一件挺有意思的事情。
尤其对于金融行业,如果可以将每天获得的关键行情指标数据自建模型,然后将结果可视化至私有平台,实现每日更新,那确实是一件挺有意思的事情。
 这不,这位金融大佬就找到了我:
这不,这位金融大佬就找到了我:


OK,分析完优缺点,那咱就开始实操吧。本文以爬取豆瓣电影数据并搭建可视化网站为例进行讲解,考虑到很多朋友是结果导向心理,那就先看下最终实现的效果吧。
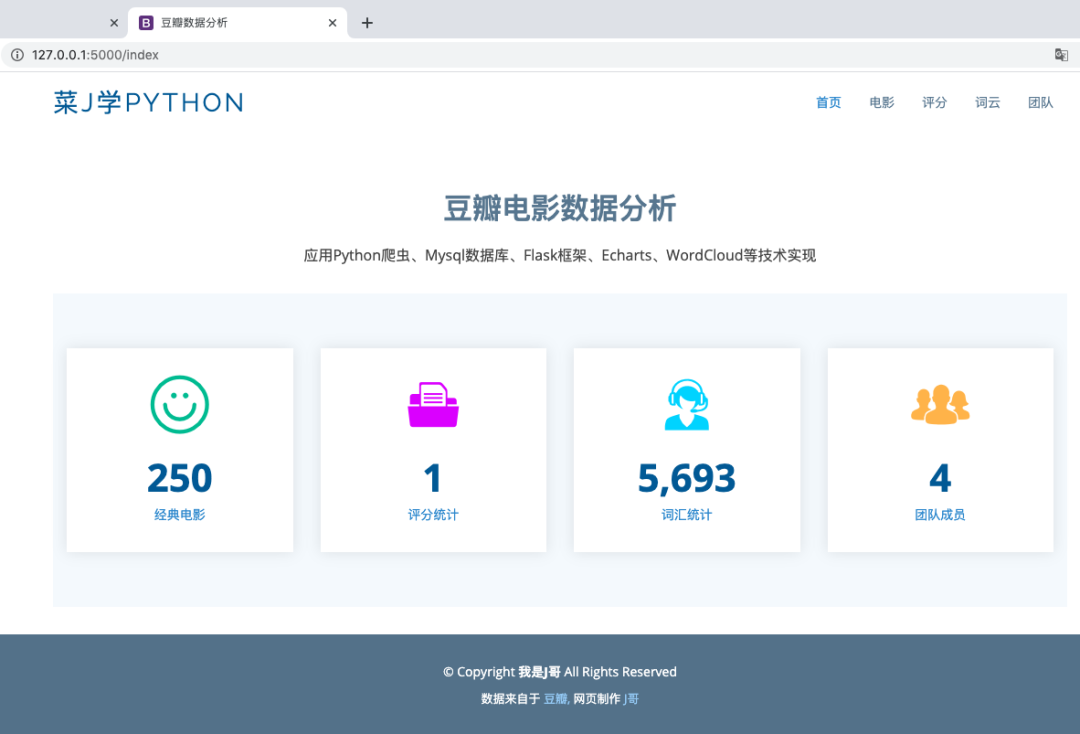
首先,看下可视化网站首页,长这样:
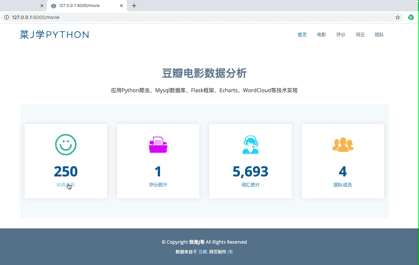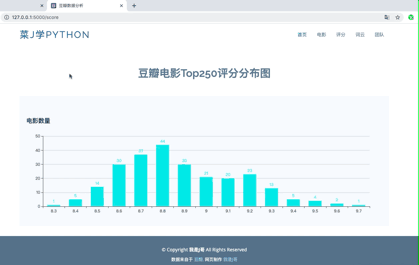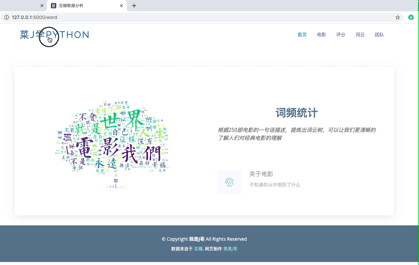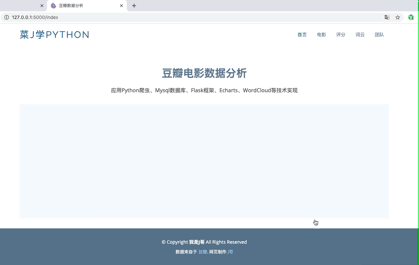
其次,简单用动画演示下可视化网站:

 理论部分讲完了,还是作图舒服,简单,直接。既然原理搞明白了,接下来就是一步步去实现了。
一
获取数据
获取数据的方法很多,J哥更喜欢自己动手,写写爬虫脚本。本次项目数据来源为以下网站。
理论部分讲完了,还是作图舒服,简单,直接。既然原理搞明白了,接下来就是一步步去实现了。
一
获取数据
获取数据的方法很多,J哥更喜欢自己动手,写写爬虫脚本。本次项目数据来源为以下网站。
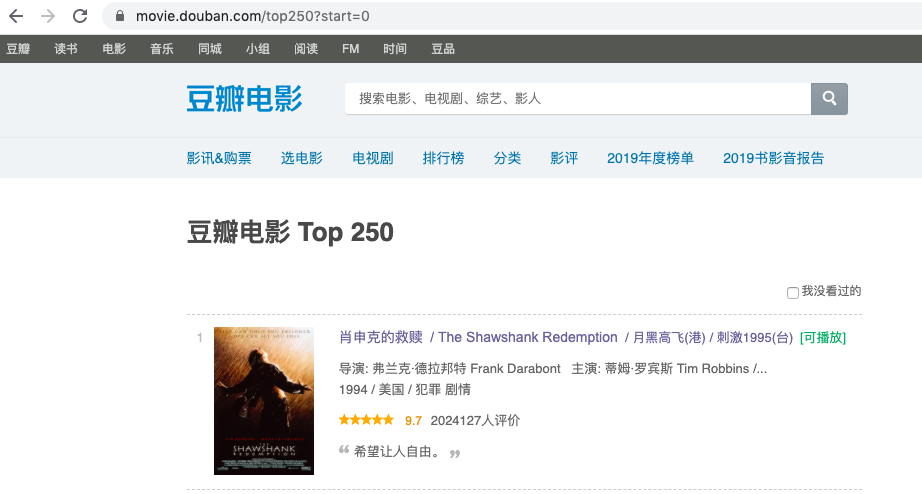
 不过考虑到有些朋友还没入门,J哥还是啰嗦一句。由于url中的start参数表示每增加25翻页一次,而翻10次就可以获取到豆瓣电影TOP250数据,所以,你要这样构建url:
不过考虑到有些朋友还没入门,J哥还是啰嗦一句。由于url中的start参数表示每增加25翻页一次,而翻10次就可以获取到豆瓣电影TOP250数据,所以,你要这样构建url:
1#爬取网页2baseurl = "https://movie.douban.com/top250?start="3def getData(baseurl):4 datalist = []5 for i in range(0,10): #调用获取页面信息的函数,10次6 url = baseurl + str(i*25)1import pymysql #进行Mysql数据库操作 1def mysql_create(): 2 conn = pymysql.connect(host="localhost", user="你的", passwd="你的", db="test", port=3306, charset="utf8") 3 4 # 获取游标 5 cur = conn.cursor() 6 7 # 创建表sql语句 8 sql_create = """ 9 create table movie10 (11 id INTEGER PRIMARY KEY AUTO_INCREMENT, #自增、主键注意字段属性必须大写12 info_link TEXT,13 pic_link TEXT,14 cname VARCHAR(100),15 ename VARCHAR(100),16 score DECIMAL(10,2),17 rated INTEGER,18 instroduction TEXT,19 info TEXT20 ) 21 """22 # 执行创建表sql语句23 cur.execute(sql_create)24 conn.commit()25 cur.close()26 conn.close() 1#3、保存数据 2def saveData2DB(datalist): 3 mysql_create() 4 conn = pymysql.connect(host="localhost", user="你的", passwd="你的", db="test", port=3306, charset="utf8") 5 cur = conn.cursor() 6 for data in datalist: 7 for index in range(len(data)): 8 data[index] = '"'+data[index]+'"' #每个数据加上双引号 9 sql = ''' #注意空格,这个sql要在for data in datalist:下遍历10 insert into movie(11 info_link,pic_link,cname,ename,score,rated,instroduction,info)12 values(%s)'''%",".join(data) #",".join表示把数据连接并以逗号分隔13 print(sql) #先打印下sql看下有没有问题14 cur.execute(sql)15 conn.commit()16 cur.close()17 conn.close()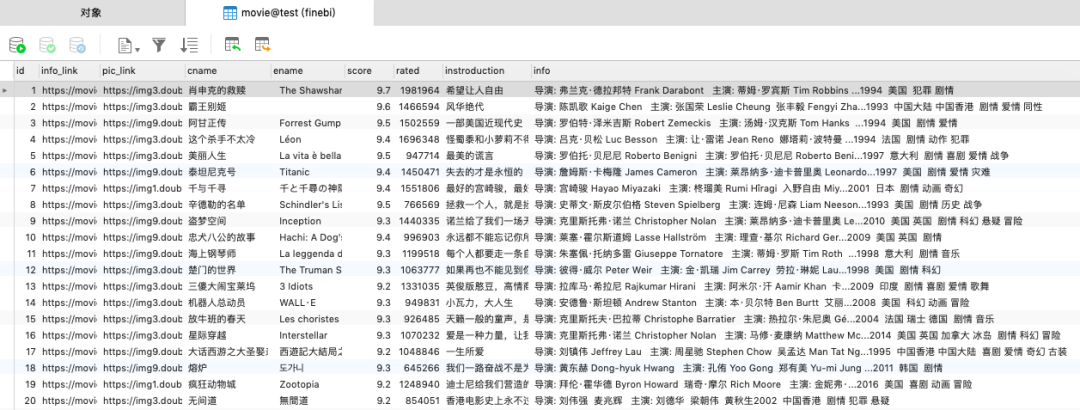
 不过问题也不大,咱自己创建Flask框架中的app.py文件、static文件以及templates文件也行呀。templates是前端网页模板,static是对templates的样式设置,app.py控制用户的请求和数据的返还。
不过问题也不大,咱自己创建Flask框架中的app.py文件、static文件以及templates文件也行呀。templates是前端网页模板,static是对templates的样式设置,app.py控制用户的请求和数据的返还。
 那J哥就举个可能不太恰当的栗子,templates是素颜,static是美颜,而app.py是朋友圈。
那J哥就举个可能不太恰当的栗子,templates是素颜,static是美颜,而app.py是朋友圈。

我们来看看app.py长啥样:
1#-*- coding = uft-8 -*- 2#@Time : 2020/5/24 11:57 上午 3#@Author : 菜J学Python 4#@File : app.py 5 6from flask import Flask,render_template 7 8app = Flask(__name__) 910@app.route("/index")11def index():12 return render_template("index.html")1314if __name__ == '__main__':15 app.run(debug=True)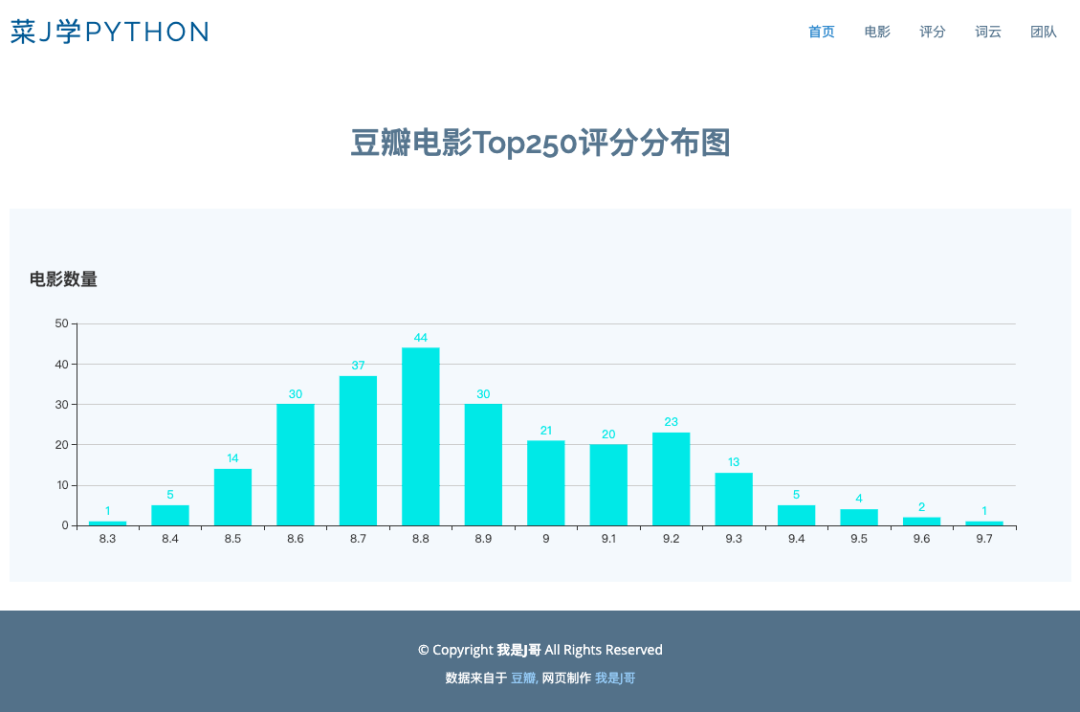
我从网上download了一个免费的Bootstrap前端模板,这样网页的结构、颜色等就不用自己搞了,当然前端大佬可以考虑自己写。在模板中找了个html,把没用的内容全删掉,留下可以放图表的位置。
接着,在score.html中加入图表,我这里采用的是Echarts的模板。
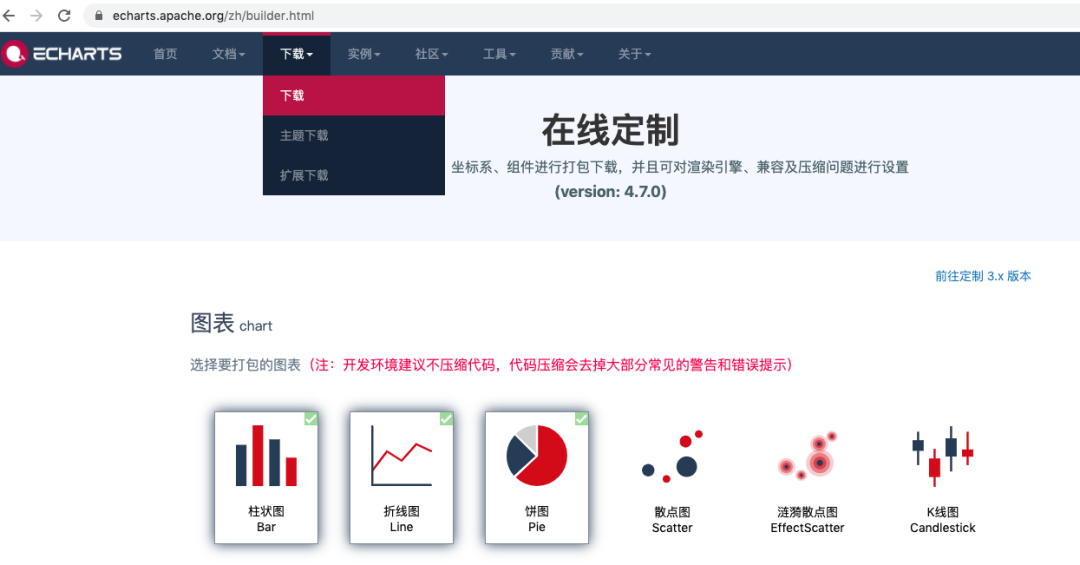
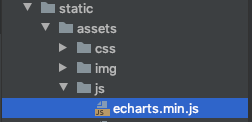
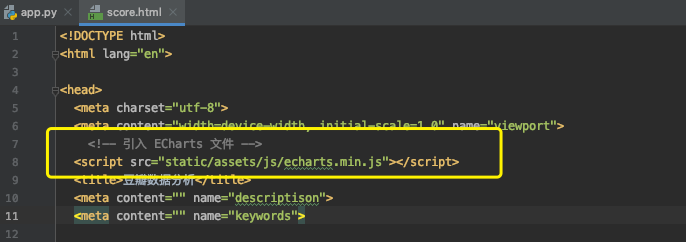
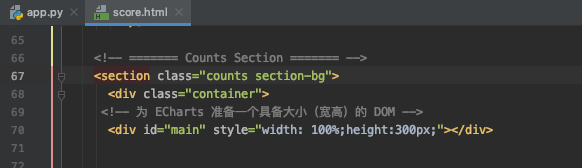
眼尖的朋友可能已经发现我那柱状图stript里的两个data就是横纵坐标的数据,数据类型为list。Echarts官网默认给的数据我用注释掉了。而data里的score和num正是通过app.py调用的Mysql里的movie表数据。
@app.route("/score")def score(): score = [] #评分 num = [] #每个评分所统计出的电影数量 conn = pymysql.connect(host="localhost", user="你的", passwd="你的", db="test", port=3306, charset="utf8") cur = conn.cursor() sql = "select score,count(score) from movie group by score;" cur.execute(sql) data = cur.fetchall() #mysql必须 for item in data: score.append(item[0]) num.append(item[1]) cur.close() conn.close() return render_template("/score.html",score=score,num=num)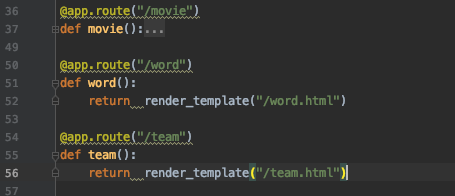
通过以上方法制作的网站你可以在自己的电脑里查看,只要每天运行下爬虫代码,你的网站内容就会实现自动更新啦。但如果你想要发布到互联网,随时随地让自己和别人查看,你还得把项目部署到服务器上,并给爬虫设置定时。你才可以实现每天躺着吃瓜,开心地看着你的网站自动更新。

往期回顾
实战|Python轻松实现动态网页爬虫(附详细源码)
实战|Python轻松实现地图可视化(附详细源码)
实战|Python轻松实现PDF格式转换(附详细源码)
实战|Python轻松实现批量图片文字识别(附详细源码)
实战|手把手教你用Python爬虫(附详细源码)
实战|Python轻松实现绘制词云图(附详细源码)

声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
推荐阅读

相关标签

