
热门标签
热门文章
- 1Django 中间件详解_django中间件权限验证
- 2AI对决:文心一言 VS ChatGPT 全方面比拼_文心一言 chatgpt
- 3Zookeeper使用详解
- 4python多线程map_Python中利用Threadpool.map()多线程抓数据
- 5封装的页面分割控件_js 分隔窗体控件
- 6Automatic Lip-reading with Hierarchical Pyramidal Convolution and Self-Attention for Image Sequences_automatic lip reading
- 7复盘:图像有哪些基本属性?关于图像的知识你知道哪些?图像的参数有哪些_图片的属性哪些需要看
- 8python、C# 写企业微信机器人推送【图文消息】_python 企业微信机器人推送图文
- 9vue-cli3.0+ 全局使用 scss预处理器 scss的全局变量_vue-cli scss 全局变量
- 10Flask web表单_flaskform default
当前位置: article > 正文
提取数据_python pdf文件提取表格数据
作者:墨韵书生 | 2024-01-31 18:51:44
赞
踩
pdf表格数据提取 python csdn
pdf文件提取表格数据,写入excel或csv文件
昨天试了pdftoHtml、pdfMiner都不是特别理想,要么就是执行太慢,要么就是提取表格数据散乱,不好处理;pdfplumber使用了一下,提取出的都是空数据,最后采用tabula.
安装 pip install tabula
tabula方便的一点时,提取出的数据不需要转化处理,可以直接使用它,他提取的数据就是一个dataFrame列表数据,可直接使用pandas处理,或直接存入excel或csv.
效果代码如下:
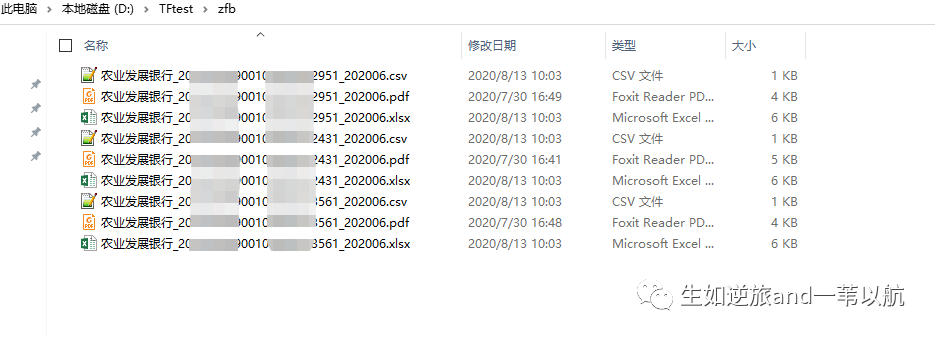
# -*- conding: utf-8 -*-import osimport tabulapath1 = r'D:\TFtest\zfb'fileList = os.listdir(path1)for file in fileList: if not file.endswith('.pdf'): # 剔除非pdf文件 continue file = os.path.join(path1, file) tableList = tabula.read_pdf(file, encoding='utf-8', pages='all') if len(tableList) < 2: # 转化结果小于两个表 continue print(tableList) 第一个表 = tableList[0] 第二个表 = tableList[1].fillna('') 第二个表['支出'] = 第二个表['支出'].str.replace('-', '0') 第二个表['收入'] = 第二个表['收入'].str.replace('-', '0') 第二个表.to_excel(file.replace('pdf', 'xlsx'), index=False) 第二个表.to_csv(file.replace('pdf', 'csv'), sep='|', index=False)数据处理结果:
声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读

相关标签

