
热门标签
热门文章
- 1STM32 通过HAL库实现双机SPI程序烧录之一SPI双机通信_hal_spi_receive_it
- 2如何用文心一言开发前端代码_文心一言上下文长度
- 3自动化防DDoS脚本
- 4mitmdump命令下无法导入python第三方包(requests)的问题解决_mitmdump -s 没包怎么办
- 5R语言实现机器学习_r语言对adult数据集进行机器学习
- 6大模型+自动驾驶
- 7SpringBoot添加自定义消息转换器
- 8SpringBoot实现多线程处理任务_springboot多线程并发处理
- 9作用域运算符的用途
- 10vue3 根据点击位置,实现一个用户头像弹框定位_前端vue怎么根据图片的点位定位元素的位置
当前位置: article > 正文
【经典题目】正则表达式匹配,通配符匹配——字符串的dp匹配问题_字符串 相似度 dp 通配符
作者:程序代码艺术家2 | 2024-01-31 14:22:57
赞
踩
字符串 相似度 dp 通配符
引言
核心的dp状态设计还是老方法,但是给出了通配符这个新东西。因此要对这类操作有新的思考。
其中涉及到了一个状态压缩的方法比较巧妙。
题目
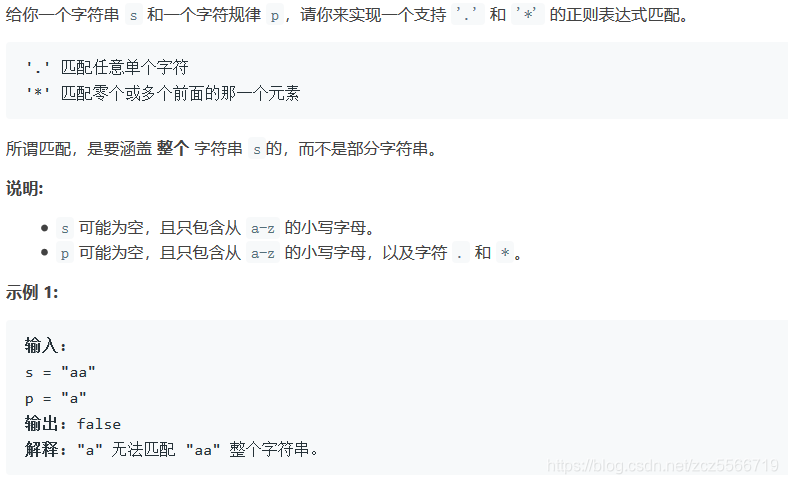
思考,状态还是自然定义为dp[i][j],表示s[:i]和p[:j]匹配的情况。对于状态的转移我们考虑两种大的情况:
p[j+1] == '*'这是一个特殊的情况,我们需要整体处理a*这种形式s[i] == p[j] or '.'此时是匹配的,可以化为dp[i][j] = dp[i-1][j-1]- 当
p = '*',需要看前一个字符的匹配情况,
(1)能匹配正确,此时枚举能需要重复几次,1次:dp[i-1][j-2] and s[i] == p[j-1], 两次:dp[i-2][j-2] and s[i-1] == p[j-2] and s[i] == p[j-2]…
(2)无法匹配上,此时让前一个字符消失dp[i][j-2] - 当
p = '*'有情况dp[i][j] = dp[i][j-2] or (dp[i-1][j-2] and p[j-1]==s[i]) or (dp[i-2][j-2] and p[j-1]==s[i] and p[j-1] == s[i-1].....一次是重复0次,重复一次,重复两次。。。
状态压缩:
对比前后两个状态
6. dp[i][j] = dp[i][j-2] or (dp[i-1][j-2] and p[j-1]==s[i]) or (dp[i-2][j-2] and p[j-1]==s[i] and p[j-1] == s[i-1].....
7. dp[i-1][j] = dp[i-1][j-2] or (dp[i-2][j-2] and p[j-1]==s[i-1]) ....
可以很明显的看出 dp[i][j] = (dp[i-1][j] and p[j-1]==s[i]) or dp[i][j-2]
还需要特别处理,边界的代码,保证保证"a"可以匹配""空*
因此得到代码:
class Solution: def isMatch(self, s: str, p: str) -> bool: n = len(s) m = len(p) dp = [[False]*(m+1) for _ in range(n+1)] # 为了在索引上进行匹配 s = ' '+s p = ' '+p dp[0][0] = True # 预处理,保证"a*"可以匹配""空 for j in range(2, m + 1): dp[0][j] = dp[0][j - 2] and p[j] == '*' for i in range(1, n + 1): for j in range(1, m + 1): if p[j] == '*': if s[i] == p[j - 1] or p[j - 1] == '.': dp[i][j] = dp[i][j - 2] or dp[i - 1][j] else: dp[i][j] = dp[i][j - 2] elif s[i] == p[j] or p[j] == '.': dp[i][j] = dp[i - 1][j - 1] return dp[n][m]

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
例题2:通配符匹配

与正则表达式匹配类似的题目,需要考虑如何处理两个特殊的匹配符号。
- 对于
?很容易处理,可以当成替换操作,只需要dp[i][j] = dp[i-1][j-1] - 对于
*就需要特殊处理,我们可以视为一个删除(匹配空)操作dp[i][j-1]或者添加(表示当前星号匹配了当前的位置的字符)操作dp[i][j] = dp[i-1][j],dp[i][j] = dp[i][j-1] or dp[i-1][j]
另外需要注意边界的处理,***也是可以匹配空字符串的。
class Solution: def isMatch(self, s: str, p: str) -> bool: n = len(s) m = len(p) dp = [[False]*(m+1) for _ in range(n+1)] dp[0][0] = True # 考虑边界的特殊情况,"*"是可以匹配空的 for i in range(1, m+1): if p[i-1] == '*': dp[0][i] = True else: break for i in range(1,n+1): for j in range(1,m+1): if p[j-1] == '*': # 匹配当前,或空匹配 dp[i][j] = dp[i-1][j] | dp[i][j-1] elif p[j-1] == '?' or p[j-1] == s[i-1]: dp[i][j] = dp[i-1][j-1] return dp[n][m]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/article/detail/50753?site
推荐阅读
相关标签

