
- 1python实现随机森林_随机森林 python
- 2人工智能之Python基础(一)控制语句|循环|常用数据类型
- 3Spring Cloud Alibaba 最新版本(基于Spring Boot 3.1.0)整合完整使用及与各中间件集成_springcloudalibaba集成spring security
- 4【Linux】Linux基本指令
- 5图解LeetCode——24. 两两交换链表中的节点
- 6Python爬虫学习之requests库
- 7好无聊啊~ 来试试用Python采集下载漫画【附原码哟~】
- 8cc2530 Zstack NV操作类似EEPROM 掉电不丢失(flash)_cc2530 eeprom
- 9系统开发常用需求收集_系统开发怎么去找需求
- 10驱动程序无法通过使用安全套接字层(SSL)加密与 SQL Server 建立安全连接。_encrypt=false
hardfault问题分析解决及记一次ucosIII环境下的hardfault解决_ucosiii 出现hardfault
赞
踩
背景
hardfault嵌入式开发中算是比较常见的问题了,前几天正好遇到了一次,虽然比较简单,网上资料也很多,不过自己还是做个review分析总结下方法吧。
环境
板子103+ucosIII,多任务环境,跑着跑着进hardfault。
分析
hardfault主要有两方面的原因:
1、内存溢出或者访问越界,或者直接使用未分配空间的指针。(代码逻辑)
2、堆栈溢出。(调整堆栈大小)
如何排查则可根据hardfalut函数打断点查看寄存器及call stack。这样可以基本了解hardfalut产生的环境
查看调用堆栈
寄存器主要看LR寄存器及MSP(Main_Stack_Pointer )及PSP(Process_Stack_Pointer)两个堆栈指针。
直接说结论,hardfault时,LR寄存器0xFFFF_FFF9使用的是MSP,LR寄存器0xFFFF_FFFD使用的是PSP.
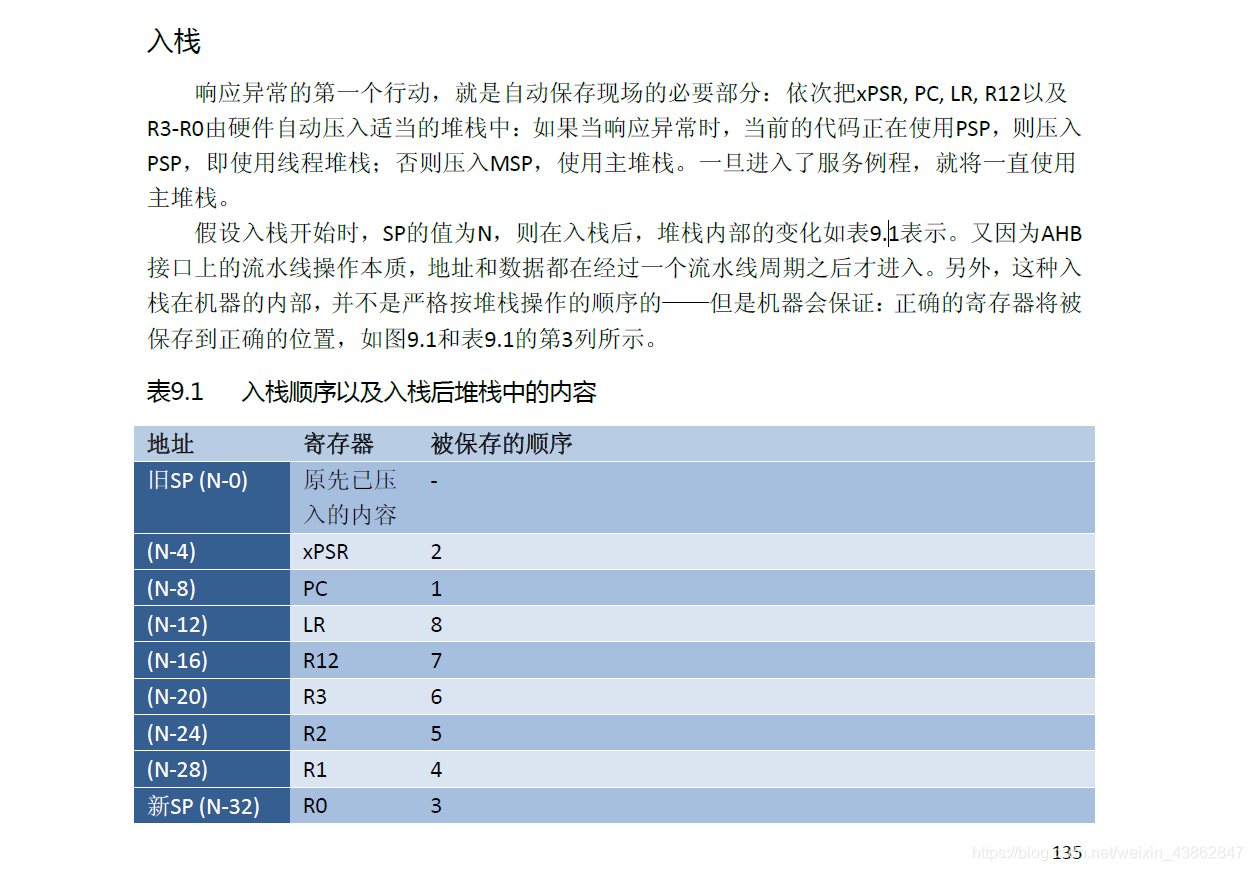
MSP和PSP存储着程序未发生hardfalut时的现场环境,根据堆栈中的PC指针可得发生hardfault的代码位置。堆栈先入后出,所以是堆栈之中的第七个寄存器为pc。

举例
例程,对空指针直接赋值。
int main(void){ OS_ERR err; OSInit(&err); BSP_Init(); OSTaskCreate((OS_TCB *)&AppTaskStartTCB, // ÈÎÎñ¿ØÖÆ¿éÖ¸Õë (CPU_CHAR *)"App Task Start", // ÈÎÎñÃû³Æ (OS_TASK_PTR )Task_Start, // ÈÎÎñ´úÂëÖ¸Õë (void *)0, // ´«µÝ¸øÈÎÎñµÄ²ÎÊýparg (OS_PRIO )STARTUP_TASK_PRIO, // ÈÎÎñÓÅÏȼ¶ (CPU_STK *)&AppTaskStartStk[0], // ÈÎÎñ¶ÑÕ»»ùµØÖ· (CPU_STK_SIZE)STARTUP_TASK_STK_SIZE/10, // ¶ÑջʣÓྯ½äÏß (CPU_STK_SIZE)STARTUP_TASK_STK_SIZE, // ¶ÑÕ»´óС (OS_MSG_QTY )0, // ¿É½ÓÊÕµÄ×î´óÏûÏ¢¶ÓÁÐÊý (OS_TICK )0, // ʱ¼äƬÂÖתʱ¼ä (void *)0, // ÈÎÎñ¿ØÖÆ¿éÀ©Õ¹ÐÅÏ¢ (OS_OPT )(OS_OPT_TASK_STK_CHK | OS_OPT_TASK_STK_CLR), // ÈÎÎñÑ¡Ïî (OS_ERR *)&err); // ·µ»ØÖµ OSStart(&err); } void Task_Start(void *p_arg) { OS_ERR err; u8 *p; IWDG_Init(); *p = 10; //对未指定地址的指针赋值会hardfalut while(DEF_ON) { IWDG_ReloadCounter(); // printf("喂狗1\r\n"); OSTimeDlyHMSM(0, 0,1,0,OS_OPT_TIME_HMSM_STRICT,&err); //ÑÓʱ×èÈû1000ms IWDG_ReloadCounter(); OSTimeDlyHMSM(0, 0,1,0,OS_OPT_TIME_HMSM_STRICT,&err); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
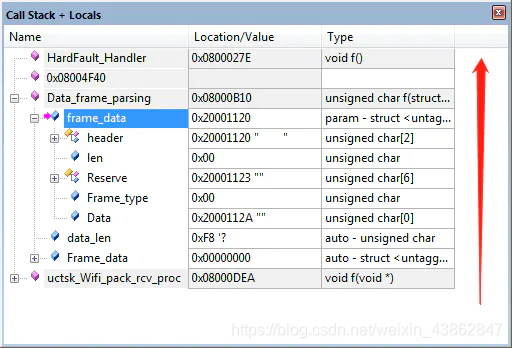
进入hardfault,call stack显示如下
因为我们是任务内的局部指针赋值问题,所以查看call stack及参数传参没有什么太多有用的信息。
寄存器信息如下
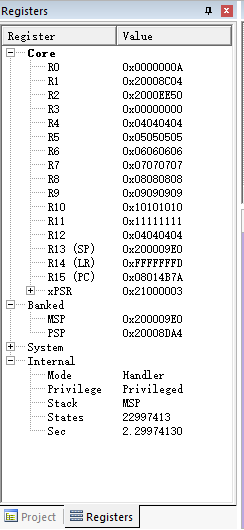
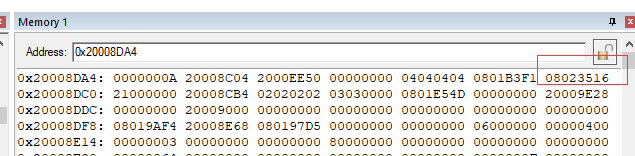
LR 0XFFFFFFFD,说明使用的是PSP寄存器存储现场环境,查看PSP栈顶指针0X20008DA4,找到栈顶7个寄存器PC为0x8023516,说明如果未发生异常下一步将执行0x8023516处的代码。
然后至Disassembly Windows跳转0x8023516,根据下图可知道将执行IWDG_ReloadCounter(); 时发生hardfault,即 执行*P =10;导致hardfault。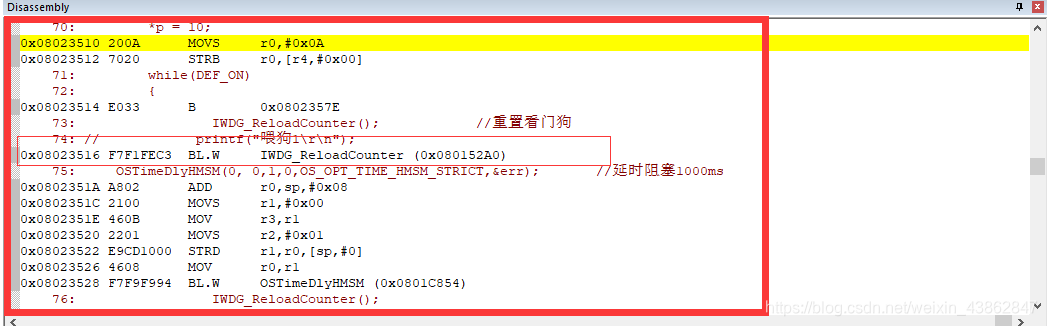
分析
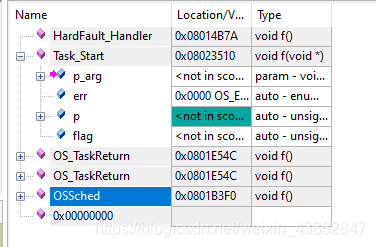
回到我生产环境的程序,按分析过程,打断点,查看发生hardfault的现场环境。
call stack
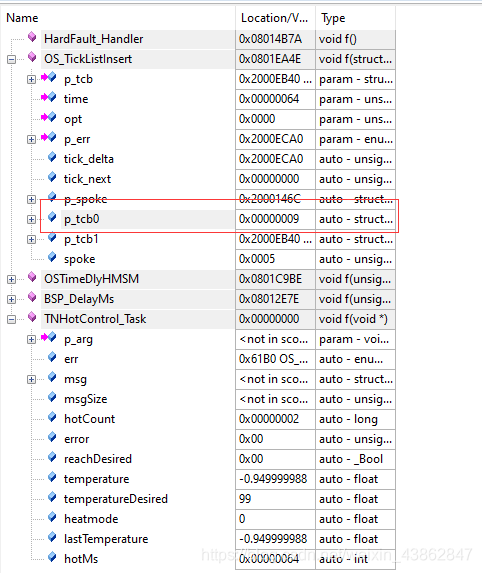
可以看到一个局部变量 任务控制块指针异常了,正常ram范围0x20000000起,这种一般来说基本可以考虑任务堆栈大小是否合适了,基本可以就不是代码逻辑问题。调大堆栈后使用ucos自带的堆栈检测函数。
//打开宏定义开关
#define OS_CFG_STAT_TASK_STK_CHK_EN 1u /* Check task stacks from statistic task */
{
CPU_STK_SIZE free,used;
OSTaskStkChk (&CTRL_TCB,&free,&used,&err);
printf("use/free:%d/%d,%%%d\r\n",used,free,(used*100)/(used+free));
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
将任务堆栈由80改为160后,正常无hardfault,并且堆栈占用也显示,之前堆栈确实太小了,本身该任务功能很简单,所以之前也设的比较小,但功能一直增加,堆栈需求也在逐渐增加,对于这种问题建议另开一个任务监控自己的其他任务的堆栈使用情况。

小结
就此,问题解决。
另外附带一句与文无关的牢骚:写博客真是比较费心的事,特别在自己心情十分糟糕的情况,心烦意乱言之无物。


