
- 1【Unity入门计划】Unity2D动画(1)-动画系统的组成及功能的使用
- 2网络抓包分析【IP,ICMP,ARP】以及 IP数据报,MAC帧,ICMP报和ARP报的数据报格式_imcp udp arp报文格式
- 3数学建模学习笔记01——线性规划_objectivesense
- 4Java知识体系最强总结(2021版)
- 5多操作系统引导管理工具System Commander 2000 全面兼容Windows 9x/NT/2000、Linux、OS/2 Warp、 NetWare、Solaris_system command下载
- 6如何运行 Python 程序?_python小工具怎么运行
- 7Spring Boot服务监控(Prometheus)_springboot prometheus
- 8【面试题】当面试官让我回答React和Vue框架的区别......_vue与react的区别面试题
- 9Matlab遗传算法工具箱(Sheffield大学版)
- 10面向过程与面向对象编程的区别和优缺点
第四篇【传奇开心果短博文系列】Python的OpenCV库技术点案例示例:机器学习
赞
踩
传奇开心短博文系列
- 系列短博文目录
- Python的OpenCV库技术点案例示例系列短博文
- 短博文目录
- 一、项目目标
- 二、OpenCV机器学习介绍
- 三、OpenCV支持向量机示例代码
- 四、OpenCV支持向量机示例代码扩展
- 五、OpenCVK均值聚类示例代码
- 六、OpenCVK均值聚类示例代码扩展
- 七、OpenCV决策树示例代码
- 八、OpenCV决策树示例代码扩展
系列短博文目录
Python的OpenCV库技术点案例示例系列短博文
短博文目录
一、项目目标
 OpenCV机器学习示例:包括支持向量机、K均值聚类、决策树等机器学习算法的实现。
OpenCV机器学习示例:包括支持向量机、K均值聚类、决策树等机器学习算法的实现。
二、OpenCV机器学习介绍
 OpenCV是一个广泛使用的开源计算机视觉库,它提供了丰富的功能和算法来处理图像和视频数据。虽然OpenCV主要用于计算机视觉任务,但它也提供了一些机器学习算法的实现。
OpenCV是一个广泛使用的开源计算机视觉库,它提供了丰富的功能和算法来处理图像和视频数据。虽然OpenCV主要用于计算机视觉任务,但它也提供了一些机器学习算法的实现。
以下是OpenCV中一些常见的机器学习算法介绍:
-
支持向量机(SVM):OpenCV提供了对支持向量机的支持,可以用于二分类和多分类问题。您可以使用OpenCV的SVM类来训练和预测数据集。
-
K均值聚类:OpenCV的ml模块中包含了K均值聚类的实现。您可以使用KMeans类进行聚类分析,将数据集划分为指定数量的簇。
-
决策树:OpenCV中的ml模块还提供了决策树的实现。您可以使用DecisionTree类来构建和训练决策树模型,用于分类和回归任务。
除了上述算法,OpenCV还提供了其他一些机器学习相关的功能,如特征提取、降维、模型评估等。
请注意,虽然OpenCV提供了一些基本的机器学习算法实现,但它并不是一个全面的机器学习框架。如果您需要更高级的机器学习功能和算法,您可能需要使用其他专门的机器学习库,如scikit-learn、TensorFlow等。
三、OpenCV支持向量机示例代码
 以下是一个使用OpenCV进行支持向量机(SVM)训练和预测的示例代码:
以下是一个使用OpenCV进行支持向量机(SVM)训练和预测的示例代码:
import cv2 import numpy as np # 准备训练数据 trainData = np.random.randint(0, 100, (25, 2)).astype(np.float32) responses = np.random.randint(0, 2, (25, 1)).astype(np.float32) # 创建SVM对象 svm = cv2.ml.SVM_create() svm.setType(cv2.ml.SVM_C_SVC) svm.setKernel(cv2.ml.SVM_LINEAR) # 训练SVM模型 svm.train(trainData, cv2.ml.ROW_SAMPLE, responses) # 准备测试数据 newcomer = np.random.randint(0, 100, (1, 2)).astype(np.float32) # 使用训练好的SVM模型进行预测 response = svm.predict(newcomer) print("预测结果:", response[1].ravel()[0])

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
这个示例代码中,首先创建了一个随机的训练数据集trainData和对应的标签responses。然后通过cv2.ml.SVM_create()创建了一个SVM对象,并设置了SVM的类型为C_SVC,核函数为线性。
接下来,使用svm.train()方法训练SVM模型,传入训练数据和标签。然后,准备一个新的测试数据newcomer,并使用svm.predict()方法进行预测。最后打印出预测结果。
请注意,这只是一个简单的示例代码,实际应用中可能需要更多的数据预处理和参数调整。您可以根据自己的需求和数据特点进行相应的修改和优化。
四、OpenCV支持向量机示例代码扩展
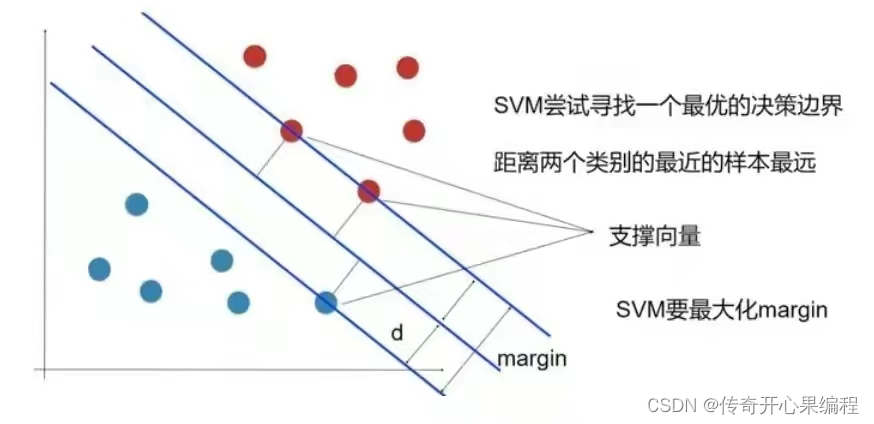 当使用OpenCV进行支持向量机(SVM)训练和预测时,还可以对数据进行更详细的处理和模型参数的调整。下面是一个扩展的示例代码:
当使用OpenCV进行支持向量机(SVM)训练和预测时,还可以对数据进行更详细的处理和模型参数的调整。下面是一个扩展的示例代码:
import cv2 import numpy as np # 准备训练数据 trainData = np.random.randint(0, 100, (25, 2)).astype(np.float32) responses = np.random.randint(0, 2, (25, 1)).astype(np.float32) # 创建SVM对象 svm = cv2.ml.SVM_create() svm.setType(cv2.ml.SVM_C_SVC) svm.setKernel(cv2.ml.SVM_LINEAR) # 定义SVM参数 svm.setC(1) # 正则化参数C svm.setGamma(0.5) # 核函数参数gamma # 定义停止准则 criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 1000, 0.01) # 训练SVM模型 svm.train(trainData, cv2.ml.ROW_SAMPLE, responses, criteria=criteria) # 准备测试数据 newcomer = np.random.randint(0, 100, (1, 2)).astype(np.float32) # 使用训练好的SVM模型进行预测 response = svm.predict(newcomer) print("预测结果:", response[1].ravel()[0])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
在这个扩展示例代码中,除了基本的训练和预测步骤之外,我们还添加了一些额外的功能:
-
设置SVM参数:通过调用svm.setC()和svm.setGamma()方法,可以设置SVM模型的正则化参数C和核函数参数gamma。这些参数可以根据数据集的特点进行调整。
-
定义停止准则:通过定义criteria变量,我们可以设置SVM训练的停止准则。在这个示例中,我们设置了最大迭代次数为1000,精度阈值为0.01。
通过调整SVM参数和停止准则,可以对模型的性能和收敛速度进行优化。
请注意,这仅是一个扩展示例代码,实际应用中可能需要更多的数据预处理、参数调优和模型评估。根据具体任务和数据集的特点,您可以进一步定制和优化SVM模型。
五、OpenCVK均值聚类示例代码
 以下是使用OpenCV进行K均值聚类的示例代码:
以下是使用OpenCV进行K均值聚类的示例代码:
import cv2 import numpy as np # 准备数据 data = np.random.randint(0, 100, (100, 2)).astype(np.float32) # 定义K均值聚类参数 criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0) k = 3 # 运行K均值聚类算法 ret, label, center = cv2.kmeans(data, k, None, criteria, 10, cv2.KMEANS_RANDOM_CENTERS) # 可视化结果 colors = [(0, 0, 255), (0, 255, 0), (255, 0, 0)] # 每个簇的颜色 image = np.zeros((500, 500, 3), dtype=np.uint8) for i in range(data.shape[0]): x, y = data[i] cluster_idx = int(label[i]) color = colors[cluster_idx] cv2.circle(image, (int(x * 5), int(y * 5)), 3, color, -1) cv2.imshow('K-means Clustering', image) cv2.waitKey(0) cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
在这个示例代码中,首先准备了一个随机生成的数据集data,其中每个样本有两个特征。
然后,定义了K均值聚类的参数。criteria变量用于设置停止准则,包括最大迭代次数和精度阈值。k表示要聚类的簇的数量。
接下来,调用cv2.kmeans()函数运行K均值聚类算法。该函数的参数包括数据集、簇的数量、初始聚类中心、停止准则、重复次数和初始中心点选择方法。
最后,根据聚类结果将数据点可视化在图像上。我们使用红色、绿色和蓝色分别表示不同的簇,通过绘制圆圈来表示每个数据点的位置。
运行代码后,将会显示出K均值聚类的可视化结果。
请注意,这只是一个简单的K均值聚类示例,实际应用中可能需要更多的数据处理、参数调整和结果分析。您可以根据自己的需求和数据特点进行相应的修改和优化。
六、OpenCVK均值聚类示例代码扩展
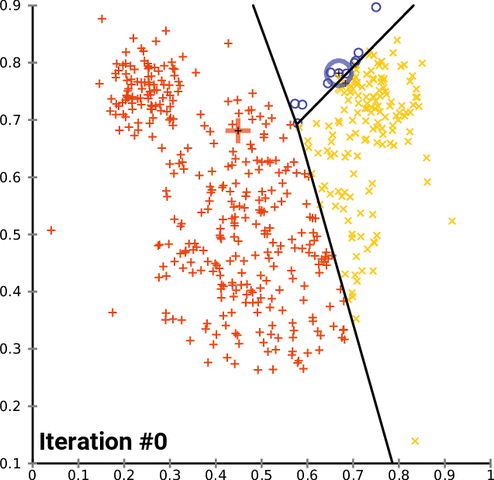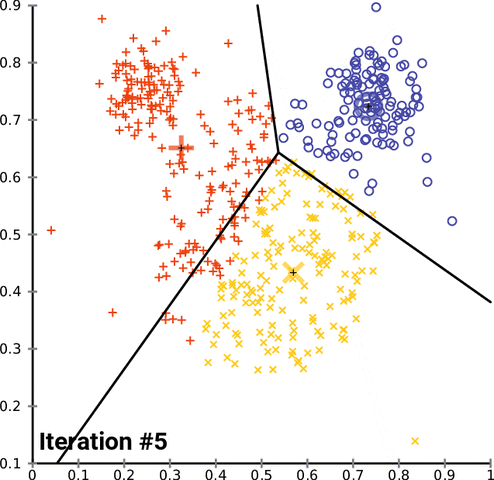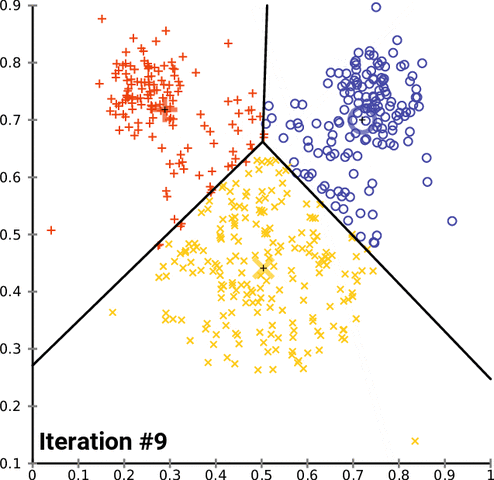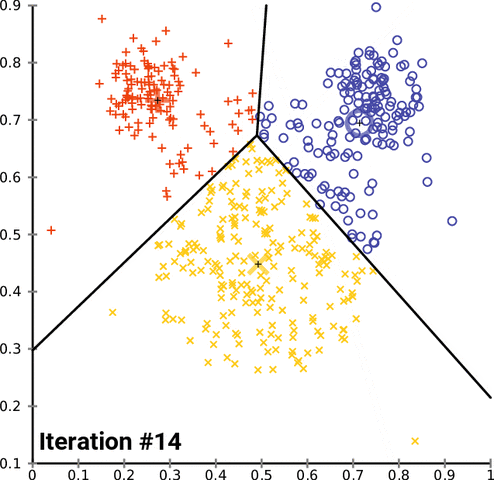 当使用OpenCV进行K均值聚类时,还可以对数据进行更详细的处理和可视化聚类结果。下面是一个扩展的示例代码:
当使用OpenCV进行K均值聚类时,还可以对数据进行更详细的处理和可视化聚类结果。下面是一个扩展的示例代码:
import cv2 import numpy as np # 准备数据 data = np.random.randint(0, 100, (100, 2)).astype(np.float32) # 定义K均值聚类参数 criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0) k = 3 # 运行K均值聚类算法 ret, label, center = cv2.kmeans(data, k, None, criteria, 10, cv2.KMEANS_RANDOM_CENTERS) # 可视化聚类结果 colors = [(0, 0, 255), (0, 255, 0), (255, 0, 0)] # 每个簇的颜色 image = np.zeros((500, 500, 3), dtype=np.uint8) for i in range(data.shape[0]): x, y = data[i] cluster_idx = int(label[i]) color = colors[cluster_idx] cv2.circle(image, (int(x * 5), int(y * 5)), 3, color, -1) # 绘制聚类中心 for c in center: cx, cy = c cv2.circle(image, (int(cx * 5), int(cy * 5)), 10, (0, 0, 0), -1) cv2.imshow('K-means Clustering', image) cv2.waitKey(0) cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
在这个扩展示例代码中,除了基本的K均值聚类和数据可视化之外,我们添加了一些额外的功能:
- 绘制聚类中心:在可视化聚类结果的基础上,我们通过绘制圆圈来表示每个簇的中心点。
通过调整K均值聚类参数、数据预处理和结果可视化的方式,可以进一步优化聚类效果。
请注意,这仅是一个扩展示例代码,实际应用中可能需要更多的数据处理、参数调优和结果分析。根据具体任务和数据集的特点,您可以进一步定制和优化K均值聚类模型。
七、OpenCV决策树示例代码
 以下是使用OpenCV进行决策树的示例代码:
以下是使用OpenCV进行决策树的示例代码:
import cv2 import numpy as np # 准备训练数据 trainData = np.random.randint(0, 100, (25, 2)).astype(np.float32) responses = np.random.randint(0, 2, (25, 1)).astype(np.float32) # 创建决策树对象 dtree = cv2.ml.DTrees_create() # 定义决策树参数 dtree.setCVFolds(1) # 设置交叉验证折数 dtree.setMaxDepth(5) # 设置最大深度 # 训练决策树模型 dtree.train(trainData, cv2.ml.ROW_SAMPLE, responses) # 准备测试数据 newcomer = np.random.randint(0, 100, (1, 2)).astype(np.float32) # 使用训练好的决策树模型进行预测 response = dtree.predict(newcomer) print("预测结果:", response[1].ravel()[0])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
在这个示例代码中,首先准备了一个随机生成的训练数据集trainData和对应的标签responses,其中每个样本有两个特征。
然后,创建了一个决策树对象dtree,并通过setCVFolds()和setMaxDepth()方法设置了决策树的参数,包括交叉验证折数和最大深度。
接下来,调用dtree.train()方法训练决策树模型,传入训练数据和标签。
最后,准备一个新的测试数据newcomer,并使用dtree.predict()方法进行预测。预测结果通过response[1].ravel()[0]获取。
请注意,这只是一个简单的决策树示例,实际应用中可能需要更多的数据预处理、参数调整和模型评估。您可以根据自己的需求和数据特点进行相应的修改和优化。
八、OpenCV决策树示例代码扩展
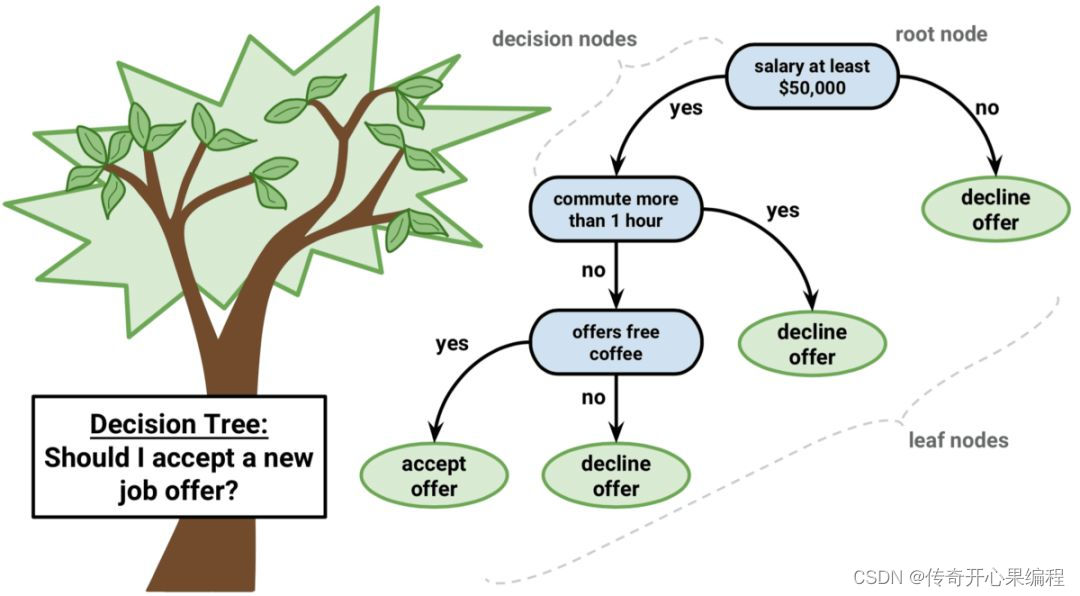 当使用OpenCV进行决策树的训练和预测时,还可以对数据进行更详细的处理和模型的调整。下面是一个扩展的示例代码
当使用OpenCV进行决策树的训练和预测时,还可以对数据进行更详细的处理和模型的调整。下面是一个扩展的示例代码
import cv2 import numpy as np #准备训练数据 trainData = np.random.randint(0, 100, (25, 2)).astype(np.float32) responses = np.random.randint(0, 2, (25, 1)).astype(np.float32) #创建决策树对象 dtree = cv2.ml.DTrees_create() #定义决策树参数 dtree.setCVFolds(3) # 设置交叉验证折数 dtree.setMaxDepth(5) # 设置最大深度 dtree.setMinSampleCount(2) # 设置每个叶节点的最小样本数 #定义停止准则 criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 100, 0.01) dtree.setTermCriteria(criteria) #训练决策树模型 dtree.train(trainData, cv2.ml.ROW_SAMPLE, responses) #准备测试数据 newcomer = np.random.randint(0, 100, (1, 2)).astype(np.float32) #使用训练好的决策树模型进行预测 response = dtree.predict(newcomer) print("预测结果:", response[1].ravel()[0])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
在这个扩展示例代码中,除了基本的训练和预测步骤之外,我们添加了一些额外的功能:
-
设置决策树参数:通过调用
setCVFolds()、setMaxDepth()和setMinSampleCount()方法,可以设置决策树模型的交叉验证折数、最大深度和每个叶节点的最小样本数。这些参数可以根据数据集的特点进行调整。 -
定义停止准则:通过定义
criteria变量,我们可以设置决策树训练的停止准则。在这个示例中,我们设置了最大迭代次数为100,精度阈值为0.01。
通过调整决策树参数和停止准则,可以对模型的性能和收敛速度进行优化。
 请注意,这仅是一个扩展示例代码,实际应用中可能需要更多的数据预处理、参数调优和模型评估。根据具体任务和数据集的特点,您可以进一步定制和优化决策树模型。
请注意,这仅是一个扩展示例代码,实际应用中可能需要更多的数据预处理、参数调优和模型评估。根据具体任务和数据集的特点,您可以进一步定制和优化决策树模型。
希望这个扩展示例对您有所帮助。如果您有更多问题,请随时提问。



