
热门标签
热门文章
- 1洛谷B2095 白细胞计数
- 2Java-Selenium自动化教程(学了不亏)_java selenium
- 3node报错_gyp err! system windows_nt 10.0.19044
- 4opencv图像处理—案例实战:全景图像拼接:特征匹配方法_cv2.bfmatcher
- 5卷积神经网络(LENET)_class lenet(nn.module): def __init__(self, in_chan
- 6Maven仓库路径以及下载链接配置_maven 项目中库下载地址缓存
- 7Unity DOTS系列之Struct Change核心机制分析
- 8解决CUDA error: out of memory
- 9Feign实现统一异常处理器_feign统一异常处理
- 10Linux常用服务器构建-ssh和scp_ssh scp -r
当前位置: article > 正文
机器学习之MATLAB代码--SMA_LSSVM(十一)_matlab中p_train = xlsread('data','training set','b2
作者:nx123 | 2024-01-29 17:47:29
赞
踩
matlab中p_train = xlsread('data','training set','b2:g191')';什么意思
代码
以下代码按照图中顺序依次:
1、
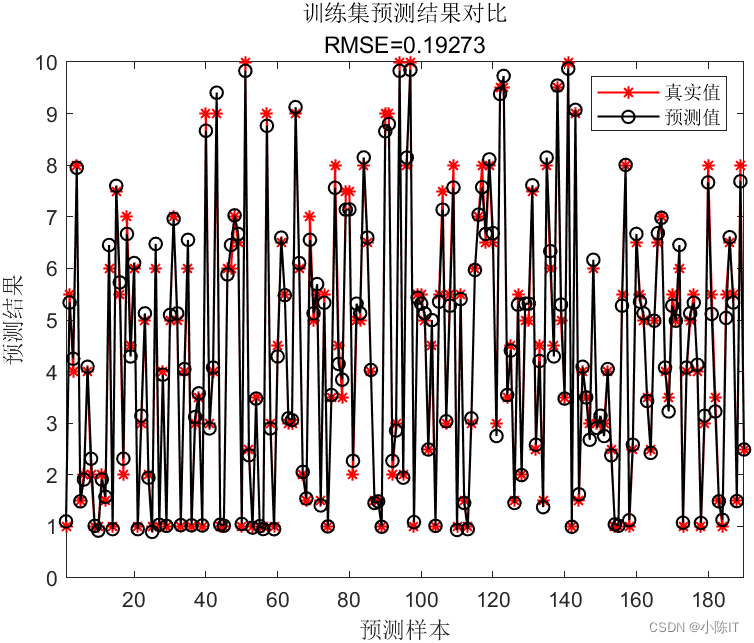
clc; clear all; close all addpath addpath %% 导入数据 % 训练集——190个样本 P_train = xlsread('data','training set','B2:G191')'; T_train= xlsread('data','training set','H2:H191')'; % 测试集——44个样本 P_test=xlsread('data','test set','B2:G45')';T_test=xlsread('data','test set','H2:H45')'; N = size(P_test, 2); % 测试集样本数 M = size(P_train, 2); % 训练集样本数 %% 数据归一化 [p_train, ps_input] = mapminmax(P_train, 0, 1); p_test = mapminmax('apply', P_test, ps_input); [t_train, ps_output] = mapminmax(T_train, 0, 1); t_test = mapminmax('apply', T_test, ps_output); %% 模型训练与预测 SearchAgents_no=20; Max_iteration=20; dim=2; lb=[0.001,0.001];%参数下限 ub=[500,100];%参数上限 type = 'function estimation'; %% c和g寻优 [sig2,gamma]=sma_ls(SearchAgents_no,Max_iteration,dim,ub,lb,type,p_train',t_train',p_test',t_test'); %%蝴蝶优化算法 [alpha,b] = trainlssvm({p_train',t_train',type,sig2,gamma,'RBF_kernel'}); %sig2,gamma, t_sim1= simlssvm({p_train',t_train',type,sig2,gamma,'RBF_kernel'},{alpha,b},p_train'); t_sim2= simlssvm({p_train',t_train',type,sig2,gamma,'RBF_kernel'},{alpha,b},p_test'); t_sim1=t_sim1';t_sim2=t_sim2'; %% 数据反归一化 T_sim1 = mapminmax('reverse', t_sim1, ps_output); T_sim2 = mapminmax('reverse', t_sim2, ps_output); %% 均方根误差 error1 = sqrt(sum((T_sim1 - T_train).^2) ./ M); error2 = sqrt(sum((T_sim2 - T_test ).^2) ./ N); %% 绘图 figure plot(1: M, T_train, 'r-*', 1: M, T_sim1, 'k-o', 'LineWidth', 1) legend('真实值','预测值') xlabel('预测样本') ylabel('预测结果') string = {'训练集预测结果对比'; ['RMSE=' num2str(error1)]}; title(string) xlim([1, M]) grid off figure plot(1: N, T_test, 'r-*', 1: N, T_sim2, 'k-o', 'LineWidth', 1) legend('真实值','预测值') xlabel('预测样本') ylabel('预测结果') string = {'测试集预测结果对比';['RMSE=' num2str(error2)]}; title(string) xlim([1, N]) grid off %% 相关指标计算 disp(['训练集数据误差:']) [mae_train,mse_train,rmse_train,mape_train,error_train,errorPercent_train,R_train]=calc_error(T_train,T_sim1); % disp(['测试集数据误差:']) [mae_test,mse_test,rmse_test,mape_test,error_test,errorPercent_test,R_test]=calc_error(T_test,T_sim2); %

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
2、
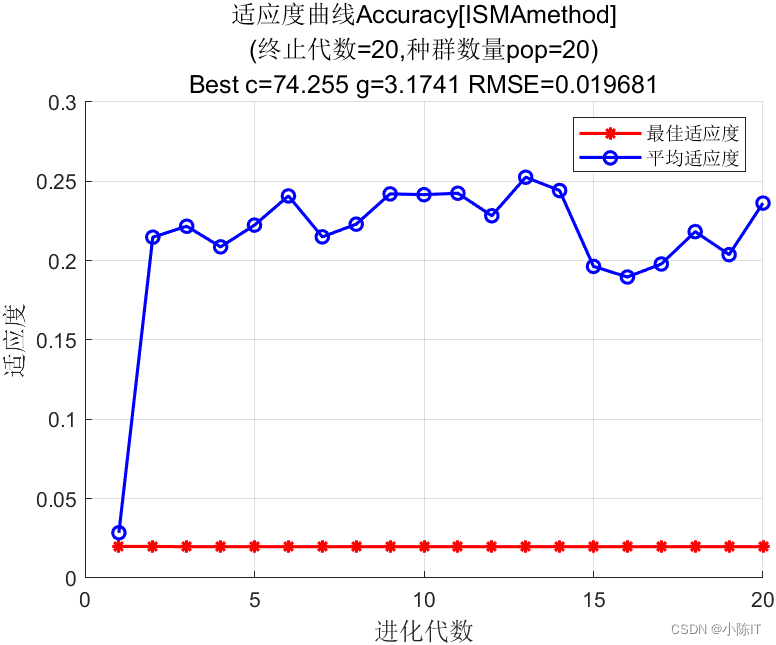
function [sig2,gamma]=sma_ls(N,Max_iter,dim,ub,lb,type,pn_train,tn_train,pn_test,tn_test); % 种群初始化 fobj=@(x)fun(x,pn_train,tn_train,pn_test,tn_test,type); bestPositions=zeros(1,dim); Destination_fitness=inf;%设置初始全最优适应度 AllFitness = inf*ones(N,1);%初始所有种群的适应度 weight = ones(N,dim);%每一个黏菌的权重 %种群初始化 X=initialization(N,dim,ub,lb); %%佳点集种群初始化 it=1; %初始迭代次数 lb=ones(1,dim).*lb; % 下界 ub=ones(1,dim).*ub; % 上界 z=0.02; % 初始参数z % 主循环 while it <= Max_iter it for i=1:N % 检查是否在范围内 Flag4ub=X(i,:)>ub; Flag4lb=X(i,:)<lb; X(i,:)=(X(i,:).*(~(Flag4ub+Flag4lb)))+ub.*Flag4ub+lb.*Flag4lb; AllFitness(i) = fobj(X(i,:)); end [SmellOrder,SmellIndex] = sort(AllFitness); %%筛选出最优和最差的种群 worstFitness = SmellOrder(N); bestFitness = SmellOrder(1); S=bestFitness-worstFitness+eps; %避免分母为0的操作 %计算每一个黏菌的权重 for i=1:N for j=1:dim if i<=(N/2) %参考源码,式2.5 weight(SmellIndex(i),j) = 1+rand()*log10((bestFitness-SmellOrder(i))/(S)+1); else weight(SmellIndex(i),j) = 1-rand()*log10((bestFitness-SmellOrder(i))/(S)+1); end end end %更新当前最优的种群和适应度 if bestFitness < Destination_fitness bestPositions=X(SmellIndex(1),:); Destination_fitness = bestFitness; end a = atanh(-(it/Max_iter)+1); %参考原式2.4 b = 1-it/Max_iter; % 更新每一代种群的位置 for i=1:N if rand<z %Eq.(2.7) X(i,:) = (ub-lb)*rand+lb; else p =tanh(abs(AllFitness(i)-Destination_fitness)); %Eq.(2.2) vb = unifrnd(-a,a,1,dim); %Eq.(2.3) vc = unifrnd(-b,b,1,dim); for j=1:dim r = rand(); A = randi([1,N]); % two positions randomly selected from population B = randi([1,N]); if r<p %Eq.(2.1) X(i,j) = bestPositions(j)+ vb(j)*(weight(i,j)*X(A,j)-X(B,j)); else X(i,j) = vc(j)*X(i,j); end end end end trace(it,1)=Destination_fitness; trace(it,2)=mean( AllFitness); it=it+1; end %% %%%%%%%%%%%%%用SMA算法优化LSSVM中的参数c和g结束%%%%%%%%%%%%%%%%%%%% bestX=bestPositions; sig2=bestX(1); gamma=bestX(2); %% figure; hold on; trace = round(trace*10000)/10000; plot(trace(1:Max_iter,1),'r*-','LineWidth',1.5); plot(trace(1:Max_iter,2),'bo-','LineWidth',1.5); legend('最佳适应度','平均适应度'); xlabel('进化代数','FontSize',12); ylabel('适应度','FontSize',12); axis([0 Max_iter-1 0 100]); grid on; axis auto; line1 = '适应度曲线Accuracy[ISMAmethod]'; line2 = ['(终止代数=', ... num2str(Max_iter),',种群数量pop=', ... num2str(N),')']; line3 = ['Best c=',num2str(sig2),' g=',num2str(gamma), ... ' RMSE=',num2str((Destination_fitness))]; title({line1;line2;line3},'FontSize',12);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
3、
%_________________________________________________________________________________ % Salp Swarm Algorithm (SSA) source codes version 1.0 % % Developed in MATLAB R2016a % % Author and programmer: Seyedali Mirjalili % % e-Mail: ali.mirjalili@gmail.com % seyedali.mirjalili@griffithuni.edu.au % % Homepage: http://www.alimirjalili.com % % Main paper: % S. Mirjalili, A.H. Gandomi, S.Z. Mirjalili, S. Saremi, H. Faris, S.M. Mirjalili, % Salp Swarm Algorithm: A bio-inspired optimizer for engineering design problems % Advances in Engineering Software % DOI: http://dx.doi.org/10.1016/j.advengsoft.2017.07.002 %____________________________________________________________________________________ % This function initialize the first population of search agents function Positions=initialization(SearchAgents_no,dim,ub,lb) Boundary_no= size(ub,1); % numnber of boundaries % If the boundaries of all variables are equal and user enter a signle % number for both ub and lb if Boundary_no==1 Positions=rand(SearchAgents_no,dim).*(ub-lb)+lb; end % If each variable has a different lb and ub if Boundary_no>1 for i=1:dim ub_i=ub(i); lb_i=lb(i); Positions(:,i)=rand(SearchAgents_no,1).*(ub_i-lb_i)+lb_i; end end
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
4、
function fitness=fun(Position,pn_train,tn_train,pn_test,tn_test,type)
sig2=Position(2);
gamma=Position(1);
[alpha,b] = trainlssvm({pn_train,tn_train,type,gamma,sig2,'RBF_kernel'});
predict_test = simlssvm({pn_train,tn_train,type,gamma,sig2,'RBF_kernel'},{alpha,b},pn_test);
fitness= sqrt(sum((tn_test-predict_test).^2)/size(tn_test,1));
end
- 1
- 2
- 3
- 4
- 5
- 6
- 7
5、
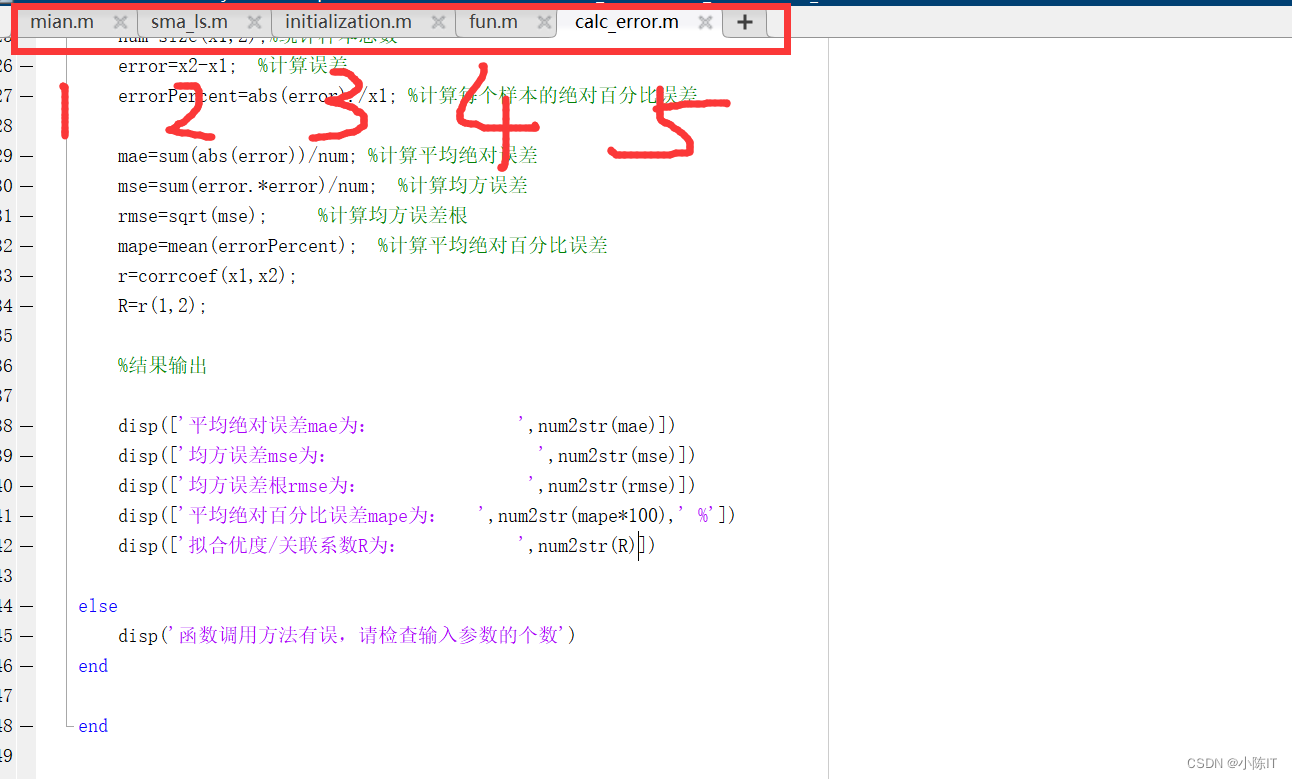
function [mae,mse,rmse,mape,error,errorPercent,R]=calc_error(x1,x2) %此函数用于计算预测值和实际(期望)值的各项误差指标 % 参数说明 %----函数的输入值------- % x1:真实值 % x2:预测值 %----函数的返回值------- % mae:平均绝对误差(是绝对误差的平均值,反映预测值误差的实际情况.) % mse:均方误差(是预测值与实际值偏差的平方和与样本总数的比值) % rmse:均方误差根(是预测值与实际值偏差的平方和与样本总数的比值的平方根,也就是mse开根号, % 用来衡量预测值同实际值之间的偏差) % mape:平均绝对百分比误差(是预测值与实际值偏差绝对值与实际值的比值,取平均值的结果,可以消除量纲的影响,用于客观的评价偏差) % error:误差 % errorPercent:相对误差 if nargin==2 if size(x1,2)==1 x1=x1'; %将列向量转换为行向量 end if size(x2,2)==1 x2=x2'; %将列向量转换为行向量 end num=size(x1,2);%统计样本总数 error=x2-x1; %计算误差 errorPercent=abs(error)./x1; %计算每个样本的绝对百分比误差 mae=sum(abs(error))/num; %计算平均绝对误差 mse=sum(error.*error)/num; %计算均方误差 rmse=sqrt(mse); %计算均方误差根 mape=mean(errorPercent); %计算平均绝对百分比误差 r=corrcoef(x1,x2); R=r(1,2); %结果输出 disp(['平均绝对误差mae为: ',num2str(mae)]) disp(['均方误差mse为: ',num2str(mse)]) disp(['均方误差根rmse为: ',num2str(rmse)]) disp(['平均绝对百分比误差mape为: ',num2str(mape*100),' %']) disp(['拟合优度/关联系数R为: ',num2str(R)]) else disp('函数调用方法有误,请检查输入参数的个数') end end
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
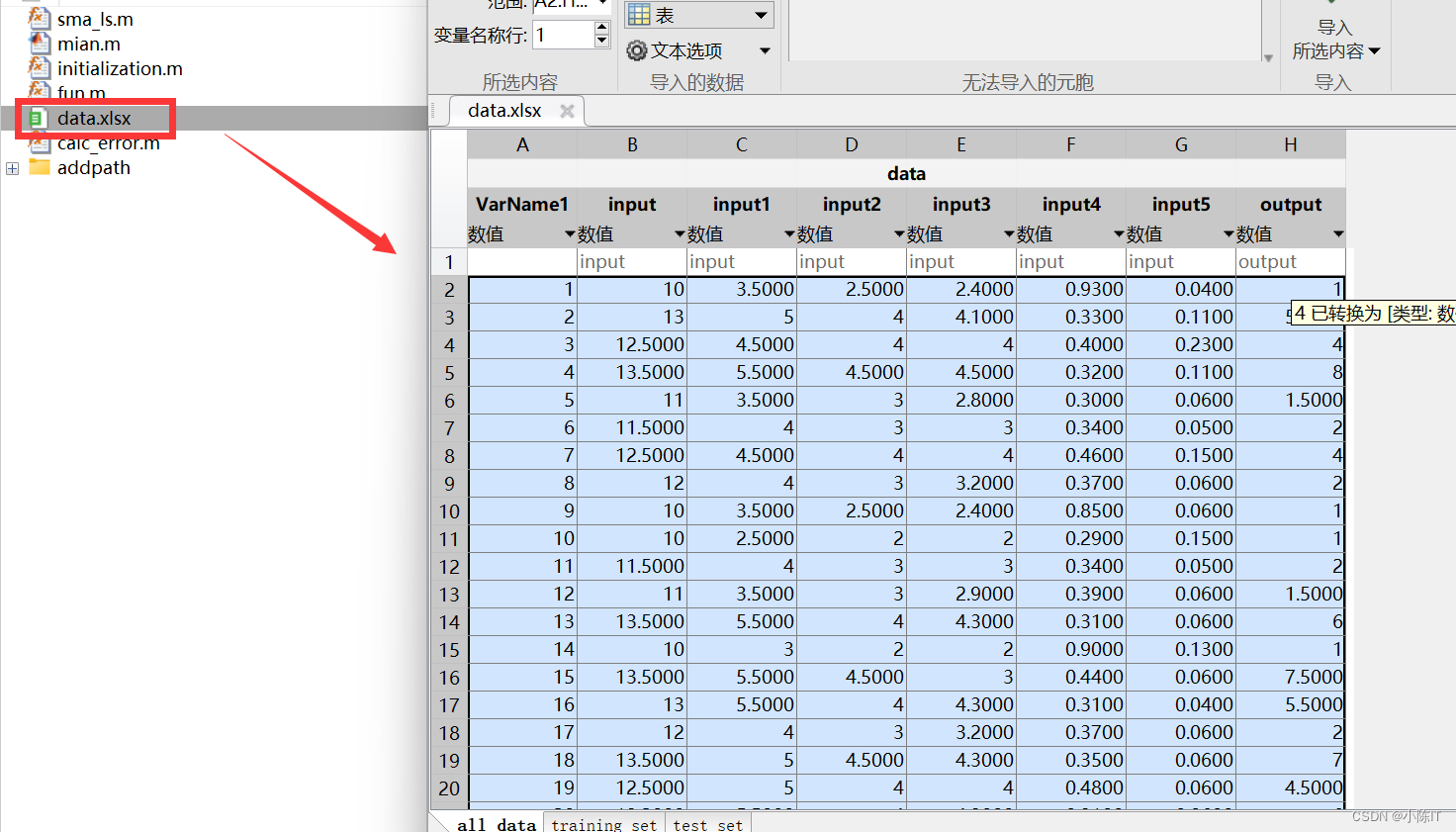
数据
结果
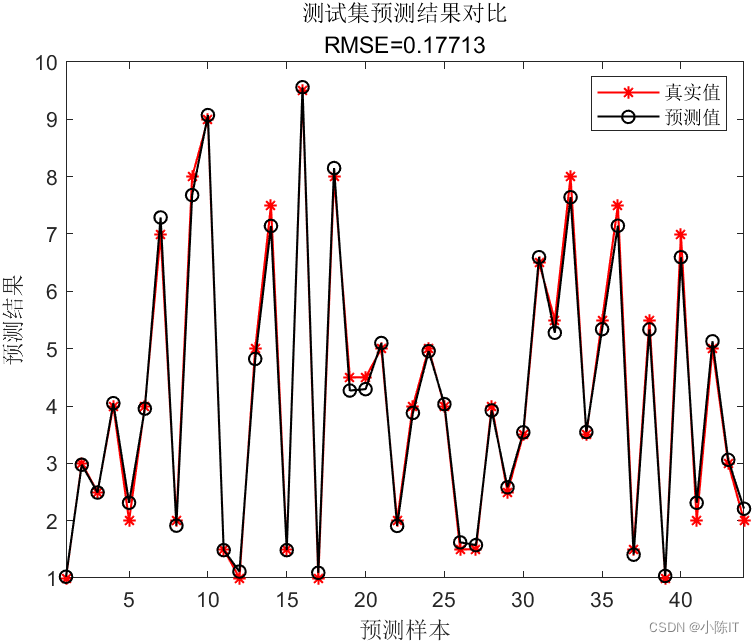
如有需要代码和数据的同学请在评论区发邮箱,一般一天之内会回复,请点赞+关注谢谢!!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/article/detail/43935
推荐阅读

相关标签

