
热门标签
热门文章
- 1Flutter 2.2 升级了哪些东西?_找到stable通道
- 2交换机与路由器技术:以太网MAC和以太网帧、交换机工作原理及基本配置_路由器 以太网帧
- 3什么是open3D?
- 4CNN经典网络模型(五):ResNet简介及代码实现(PyTorch超详细注释版)_resnet代码
- 5FPGA开发
- 6用极大似然法估计因子载荷矩阵_因子分析(利用Minitab或Excel Xlstat)
- 7Tensorflow中Variable变量_tensorflow.variablefang
- 8Web前端--HTML+CSS+JS实现3D立体魔方小游戏_3d魔方网页
- 9VUE页面设置背景图片的方法,以及显示el-dialog弹窗时背景会变灰色的问题解决。_el-dialog设置背景图片无效
- 10AIGC是什么?一文读懂人工智能生成内容技术!_互联网聊天型生成式aigc内容服务
当前位置: article > 正文
Java使用Selenium+ChromeDriver 爬取中国知网_java爬取知网
作者:算法编织者 | 2024-01-25 09:46:18
赞
踩
java爬取知网
Java使用Selenium 爬取中国知网
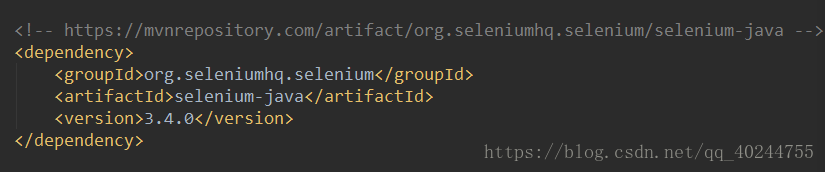
所需Jar包
中国知网的网页结构,我就不在这里赘述了,自己去看,这里我操作的是爬取博硕论文,只抓取前十页
当Selenium无法调取ChromeDriver时可参考以下建议:
1.chromedriver是否与当前Chrome版本兼容
2.chromedriver是否放置在Chrome安装目录下
3.chromedriver是否配置环境变量
4.selenium版本是否与chromedriver相冲突,换个版本测试
附上代码
package com.qdcz.plugins; import org.openqa.selenium.By; import org.openqa.selenium.WebDriver; import org.openqa.selenium.WebElement; import org.openqa.selenium.chrome.ChromeDriver; import java.util.List; import java.util.Set; public class Test { public static void main(String args[]) throws Exception { //调用chrome driver System.setProperty("webdriver.chrome.driver", "C:/Program Files (x86)/Google/Chrome/Application/chromedriver.exe"); //调用chrome WebDriver driver = new ChromeDriver(); //调整高度 ((ChromeDriver) driver).executeScript("window.scrollTo(0, document.body.scrollHeight);"); //获取网址 ((ChromeDriver) driver).get("http://epub.cnki.net/KNS/brief/result.aspx?dbprefix=CMFD"); //高级搜索 WebElement high = driver.findElement(By.xpath("//*[@id=\"1_3\"]/a")); high.click(); Thread.sleep(1000); //定位元素 WebElement in = ((ChromeDriver) driver).findElementByName("txt_1_value1"); //定义搜索内容 String searchWord = ""; searchWord = "基因芯片"; //发送搜索内容 in.sendKeys(searchWord); ((ChromeDriver) driver).findElementByXPath("//*[@id='ddSubmit']/span").click(); ((ChromeDriver) driver).findElementByXPath("//*[@id='btnSearch']").click(); Thread.sleep(2000); //清除分类获得所有 ((ChromeDriver) driver).findElementByXPath("//*[@id='XuekeNavi_Div']/div[1]/input[1]").click(); ((ChromeDriver) driver).findElementByXPath("//*[@id='B']/span/img[1]").click(); Thread.sleep(2000); //分割符 System.out.println("-----------------------"); //定位iframe WebElement iframe = driver.findElement(By.id("iframeResult")); //也可直接这样写((ChromeDriver) driver).switchTo().frame("id=iframeResult"); //线程休眠 Thread.sleep(2000); for (int i = 0; i <10; i++) { //获取窗口 String now_handle = driver.getWindowHandle(); Set<String> all_handles = driver.getWindowHandles(); //判断窗口是否一致 for (String handle : all_handles) { if (handle != now_handle) { driver.switchTo().window(handle); ((ChromeDriver) driver).switchTo().frame(iframe); //选择50页 WebElement btn = ((ChromeDriver) driver).findElementByXPath("//*[@id=\"id_grid_display_num\"]/a[3]"); btn.click(); //获取页面内容 //String content=driver.getPageSource(); //System.out.println(content); //获取iframe元素内容直至tr List<WebElement> tb = driver.findElements(By.xpath("//*[@id=\"ctl00\"]/table/tbody/tr[2]")); for (WebElement t : tb) { List<WebElement> tbod = t.findElements(By.tagName("tbody")); for (WebElement tr : tbod) { List<WebElement> td = tr.findElements(By.tagName("tr")); td.remove(0); for (WebElement tds : td) { List<WebElement> tdss = tds.findElements(By.tagName("td")); String title = tdss.get(1).getText(); String author=tdss.get(2).getText(); String college=tdss.get(3).getText(); String year=tdss.get(4).getText(); System.out.println(title+"--"+author+"--"+college+"--"+year); } } } } } //线程休眠 Thread.sleep(1000); WebElement nextBtn=((ChromeDriver) driver).findElementByXPath("//*[@id=\"Page_next\"]"); nextBtn.click(); } //关闭driver driver.close(); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
附上结果
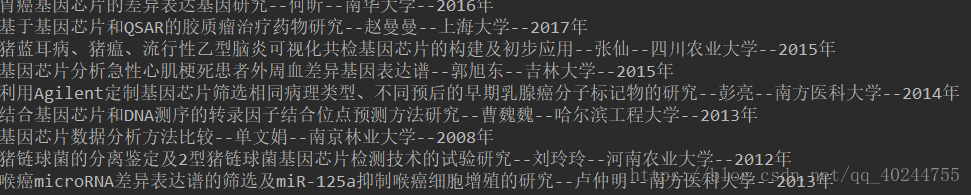
我在想如何抓取全,中国知网的论文题目,作者,导师等等信息,一直没有什么大的思路进展,因为中国知网有Piwik.js写了追踪函数,其次的url参数里有时间加密,所以获取url也不能正确的保证访问到原网页,这让我很是苦恼,目前已知的有一种时间 参数时Unix时间格式,具体页面后面的我不知道是如何进行加密的,破解不了。另外有一种思路是通过post请求大学页面抓取,这是可行的,但与我想要的数据有差异,故不尝试。
诸位有什么好的想法或建议,可以告诉我,一起交流~
本文在一定程度上借鉴了https://blog.csdn.net/hensonwells/article/details/77126819这篇文章(python)的思想,有兴趣的同学可以去看看。
如果你想进一步抓取知网的信息(非论文)可以看看我写的另一篇文章
https://blog.csdn.net/qq_40244755/article/details/88689814

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/article/detail/41890
推荐阅读
![[ 云计算 | AWS 实践 ] 使用 Java 更新现有 Amazon S3 对象](https://img-blog.csdnimg.cn/direct/f6b4b45ef01445aa9a147e7c5f1a8f15.png?x-oss-process=image/resize,m_fixed,h_300,image/format,png)



相关标签

