
- 1《Arduino家居安全系统构建实战》——1.5 介绍用于机器学习的F
- 2Javacv在Windows下正常运行,在Linux上报异常~Could not initialize class org.bytedeco.javacv.FFmpegFrameGrabber
- 3前端刷题 | 网站_前端刷题网站
- 4产品经理面试问题及答案大全《一》
- 5Codeforces700A As Fast As Possible 数学推理_codeforces 700a
- 6YOLO基础教程(九):YOLO训练过程中一些知识点_yolov9
- 7SpringMVC 中的数据绑定如何使用 @InitBinder 注解_springmvc binder
- 8GNU ARM汇编--(十八)u-boot-采用nand_spl方式的启动方法_gnu uboot
- 92021-2024年中国两轮电动车企业经营情况对比_台铃 净利润
- 10数据结构-合并链表算法
pytorch中的多种scheduler_pytorch 多个scheduler
赞
踩
pytorch中的多种scheduler
1. LambdaLR
-
公式
l r e p o c h = l r i n i t i a l ∗ L a m b d a ( e p o c h ) lr_{epoch}=lr_{initial}∗Lambda(epoch) lrepoch=lrinitial∗Lambda(epoch) -
代码
import torch import matplotlib.pyplot as plt model = torch.nn.Linear(2, 1) optimizer = torch.optim.SGD(model.parameters(), lr=100) lambda1 = lambda epoch: 0.65 ** epoch scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda1) lrs = [] for i in range(10): optimizer.step() lrs.append(optimizer.param_groups[0]["lr"]) # print("Factor = ", round(0.65 ** i,3)," , Learning Rate = ",round(optimizer.param_groups[0]["lr"],3)) scheduler.step() plt.plot(range(10),lrs)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
-
图片
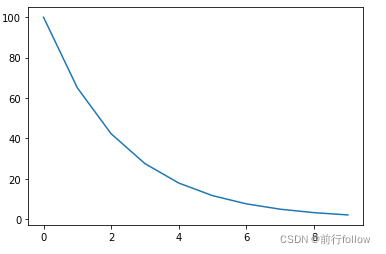
2. MultiplicativeLR
-
公式
l r e p o c h = l r e p o c h − 1 ∗ L a m b d a ( e p o c h ) lr_{epoch}=lr_{epoch - 1}∗Lambda(epoch) lrepoch=lrepoch−1∗Lambda(epoch) -
图片
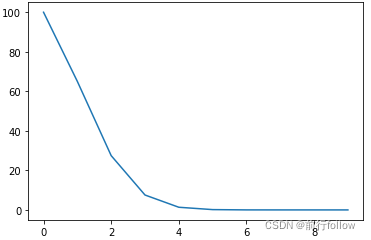
3. StepLR
-
公式

-
图片
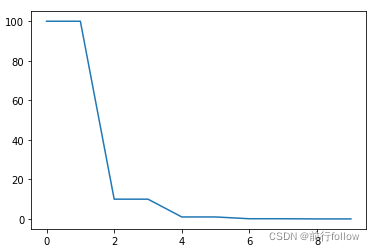
4. MultiStepLR
-
公式

-
代码
model = torch.nn.Linear(2, 1) optimizer = torch.optim.SGD(model.parameters(), lr=100) scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[6,8,9], gamma=0.1) lrs = [] for i in range(10): optimizer.step() lrs.append(optimizer.param_groups[0]["lr"]) # print("Factor = ",0.1 if i in [6,8,9] else 1," , Learning Rate = ",optimizer.param_groups[0]["lr"]) scheduler.step() plt.plot(range(10),lrs)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
-
图片
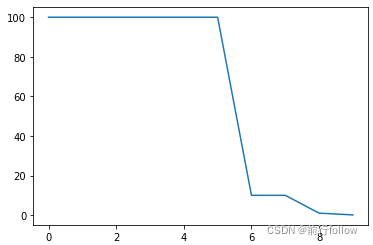
5. CosineAnnealingLR
-
公式
η t = η m i n + 1 2 ( η m a x − η m i n ) ( 1 + c o s ( T c u r T m a x π ) ) η_t=η_{min}+\frac12(η_{max}−η_{min})(1+cos(\frac {T_{cur}}{T_{max}}π)) ηt=ηmin+21(ηmax−ηmin)(1+cos(TmaxTcurπ)) -
代码
model = torch.nn.Linear(2, 1) optimizer = torch.optim.SGD(model.parameters(), lr=100) scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=10, eta_min=0)#T_max表示半个周期的大小 lrs = [] for i in range(100): optimizer.step() lrs.append(optimizer.param_groups[0]["lr"]) # print("Factor = ",i," , Learning Rate = ",optimizer.param_groups[0]["lr"]) scheduler.step() plt.plot(lrs)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
-
图片
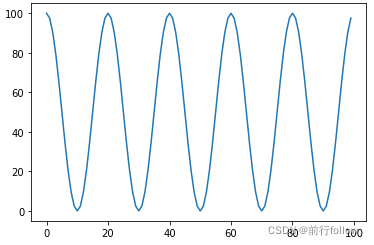
6. CosineAnnealingWarmRestarts
-
公式
η t = η m i n + 1 2 ( η m a x − η m i n ) ( 1 + c o s ( T c u r T i π ) ) η_t=η_{min}+\frac12(η_{max}−η_{min})(1+cos(\frac {T_{cur}}{T_{i}}π)) ηt=ηmin+21(ηmax−ηmin)(1+cos(TiTcurπ)) -
代码
import torch import matplotlib.pyplot as plt model = torch.nn.Linear(2, 1) optimizer = torch.optim.SGD(model.parameters(), lr=0.1) lr_sched = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=10, T_mult=1, eta_min=0.001, last_epoch=-1) #每经过T_0轮后,开始重新启动scheduler lrs = [] for i in range(100): lr_sched.step() lrs.append( optimizer.param_groups[0]["lr"] ) plt.plot(lrs)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17


