
热门标签
热门文章
- 1leetcode刷题笔记-144. 二叉树的前序遍历(java实现)_给你二叉树的根节点 root ,返回它节点值的 前序 遍历。
- 2微信授权登录并获取用户信息接口开发_微信接口开发获取个人微信信息
- 3如何配置Pycharm服务器并结合内网穿透工具实现远程开发
- 4okhttp3的使用和封装_okhttp3依赖
- 5Softmax分类器
- 6Kubernetes CRD 系列(四):ClientSet 和 Informer_client-set,informer是干啥的
- 7kali的下载与安装(VM虚拟机)_kali下载
- 8Codeforces Round #737 (Div. 2)部分题解_codeforces737 div2
- 9(Linux) WSL 适用于Linux的Windows子系统_适用于 linux 的 windows 子系统 (wsl)
- 10Innodb_buffer_pool_pages_innodb_buffer_pool_pages_data
当前位置: article > 正文
HBase的shell操作_hbase shell操作
作者:代码维护者 | 2024-01-04 00:57:53
赞
踩
hbase shell操作
HBase的相关使用
HBase的基本shell操作
- 1- 如何进入HBase的操作命令的控制台
hbase shell
- 1
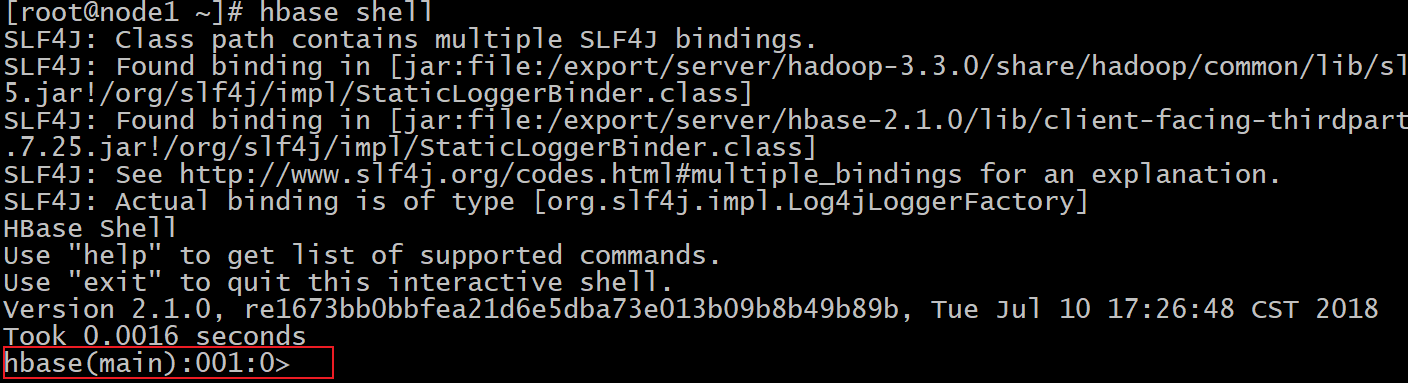
- 2- 如何查看HBase的命令帮助文档
help
- 1
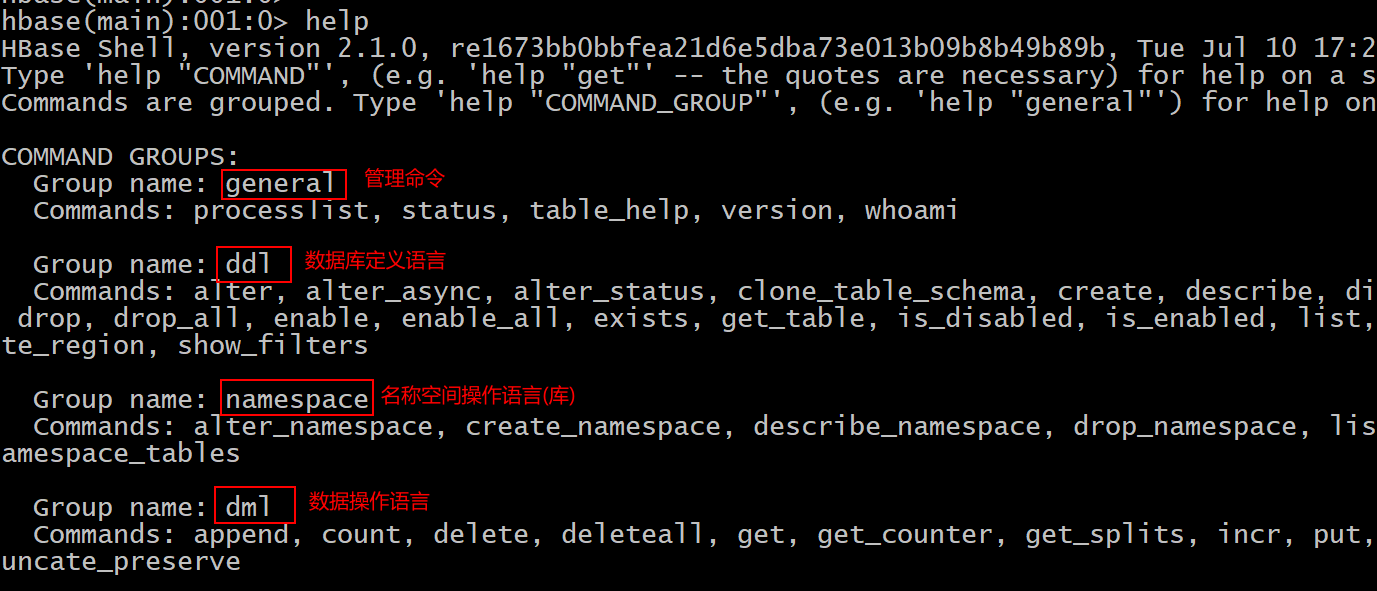
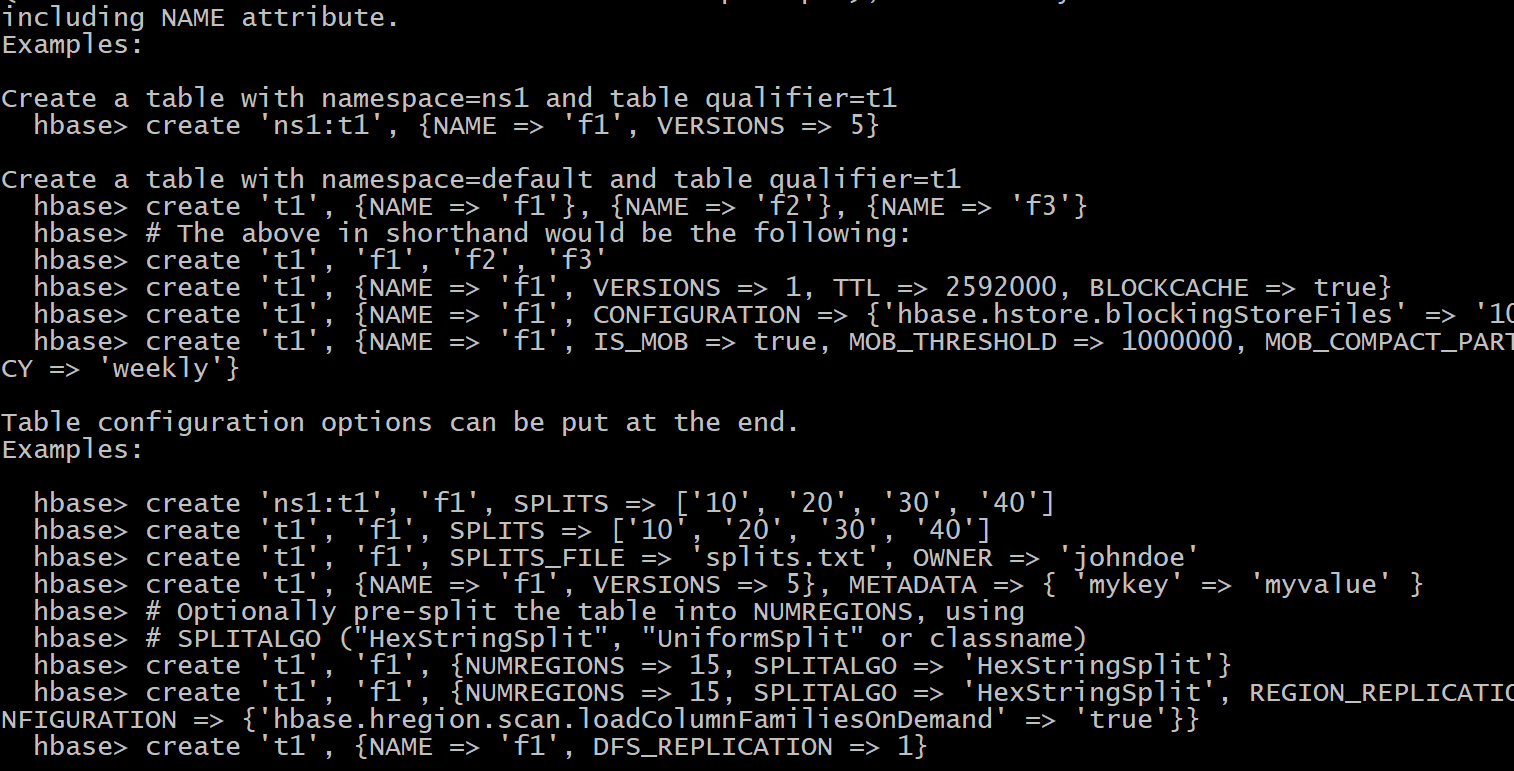
查看某一个命令如何使用:
格式: help '命令'
例如: hbase(main):002:0> help 'create'
- 1
- 2
- 3
- 4
- 5
- 3- 查看集群状态: status

- 4- 查看HBase有那些表: list
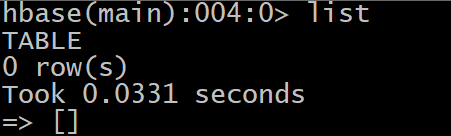
- 5- 如何创建一张表
格式:
create '表名', '列族1','列族2'......
- 1
- 2

- 6- 如何向表中添加数据: put
格式:
put '表名', 'rowkey值','列族:列名','列值'
- 1
- 2

- 7- 如何读取某一个rowkey的数据呢?
格式:
get '表名','rowkey值'[,'列族1','列族2'... || '列族1:列名1','列族2:列名2'... || '列族1','列族1:列名1'... ]
- 1
- 2
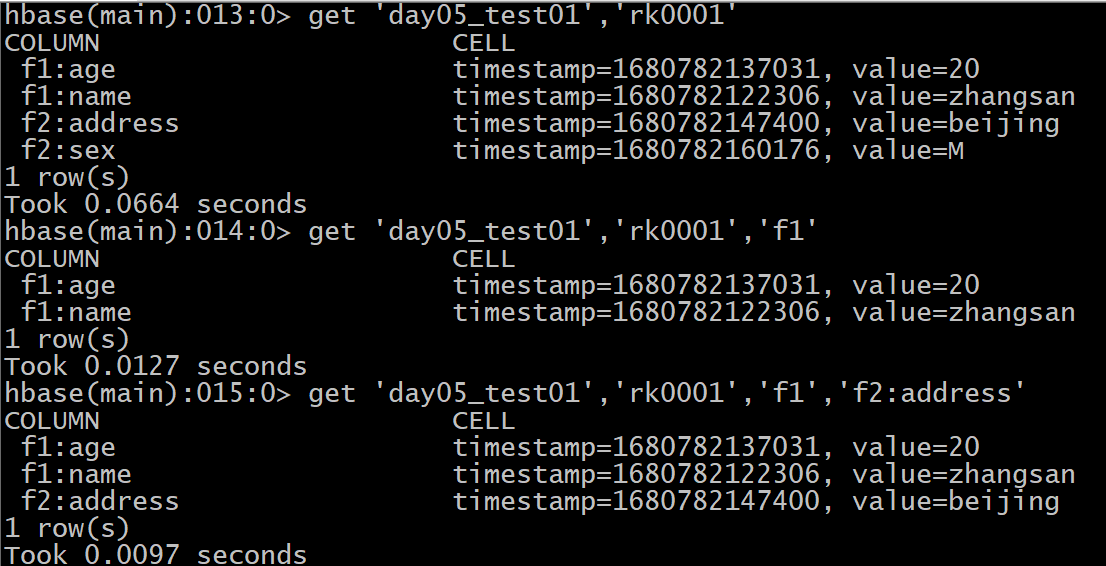
- 8- 如何修改表中数据
修改与添加数据的操作,是一致的, 只需要保证rowkey相同, 就是修改操作
- 1
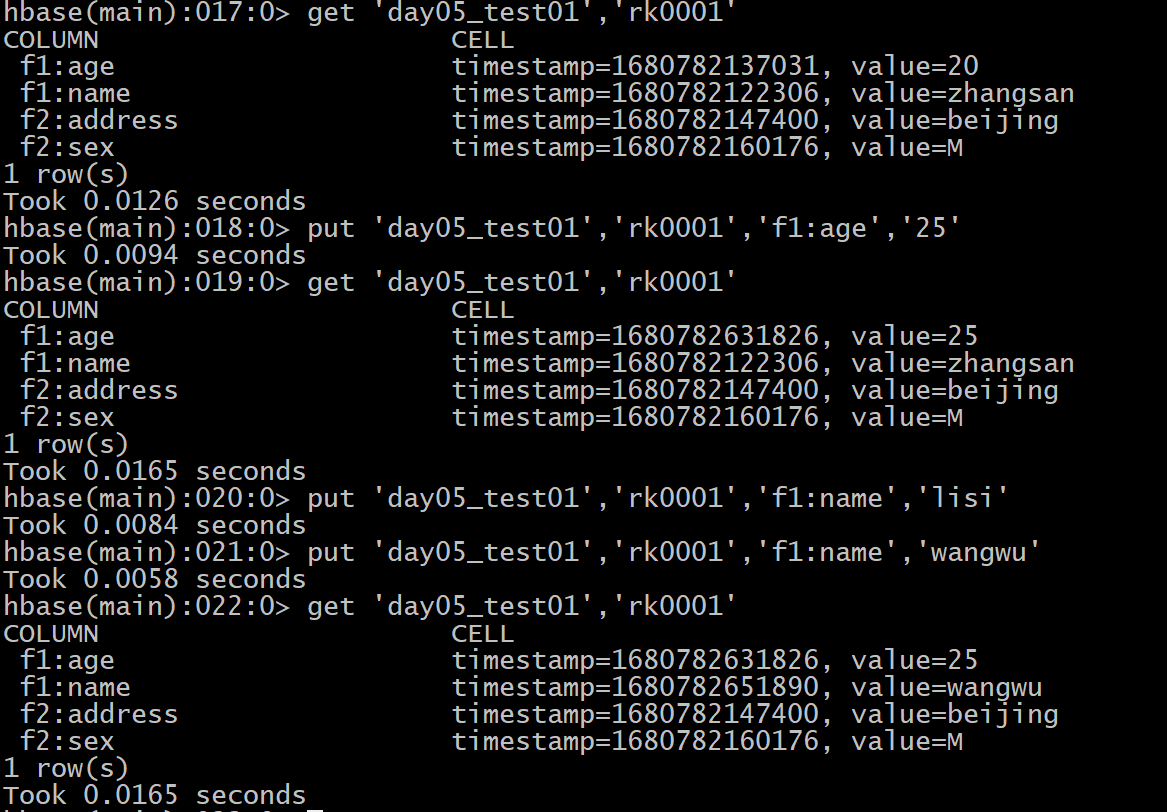
- 9- 删除数据: delete 和 deleteAll
格式:
delete '表名','rowkey','列族:列名'
- 1
- 2
格式:
deleteall '表名','rowkey' [,'列族:列名']
- 1
- 2
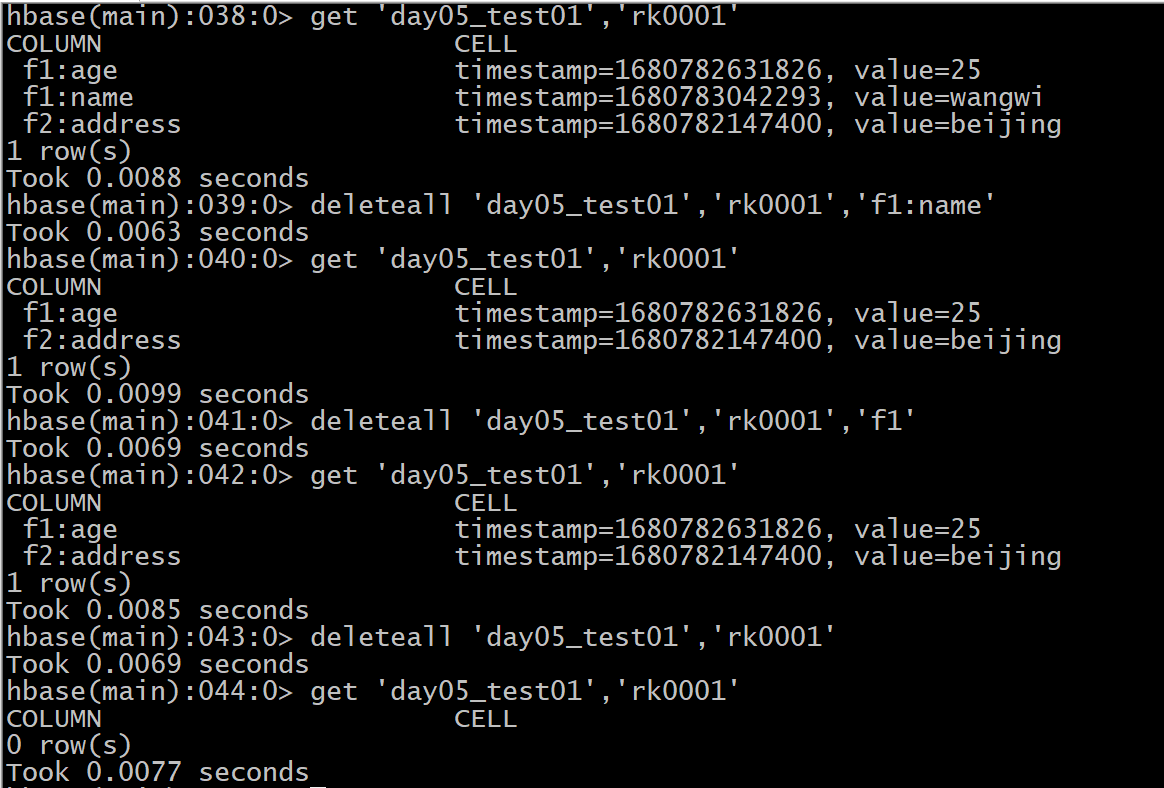
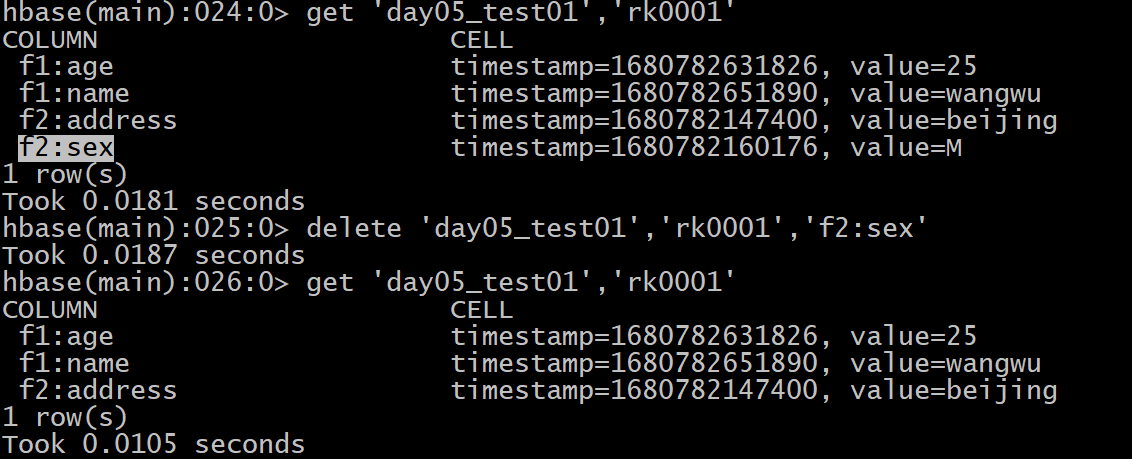
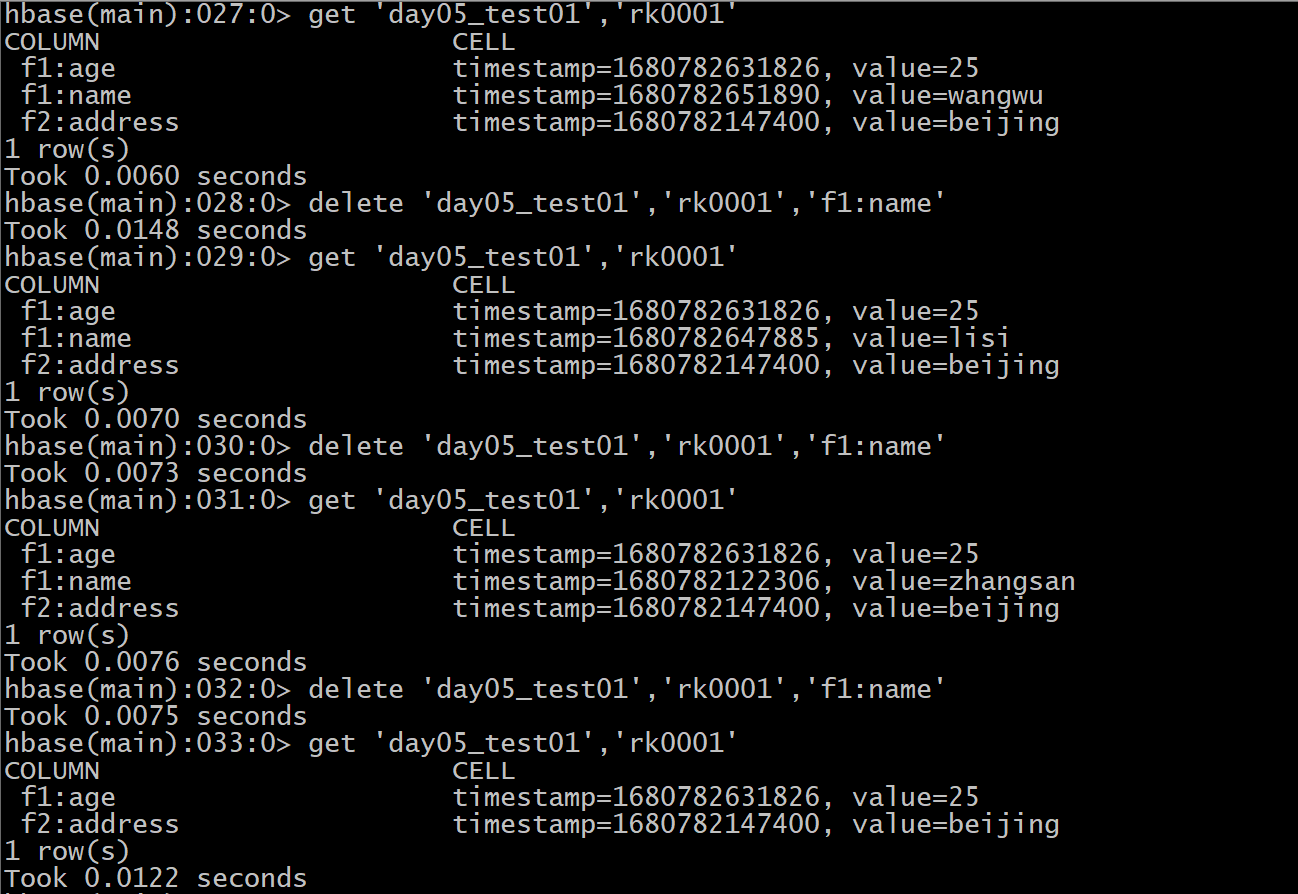
delete 和 deleteall 区别:
共同点: 都是用于执行删除数据的操作
区别点:
1) delete操作, 只能删除某个列的数据, deleteall 支持删除整行数据
2) 通过delete删除某个列的数据时候, 默认只删除最新的版本, 而deleteall直接将所有的版本全部都删除
- 1
- 2
- 3
- 4
- 5
- 6
- 7
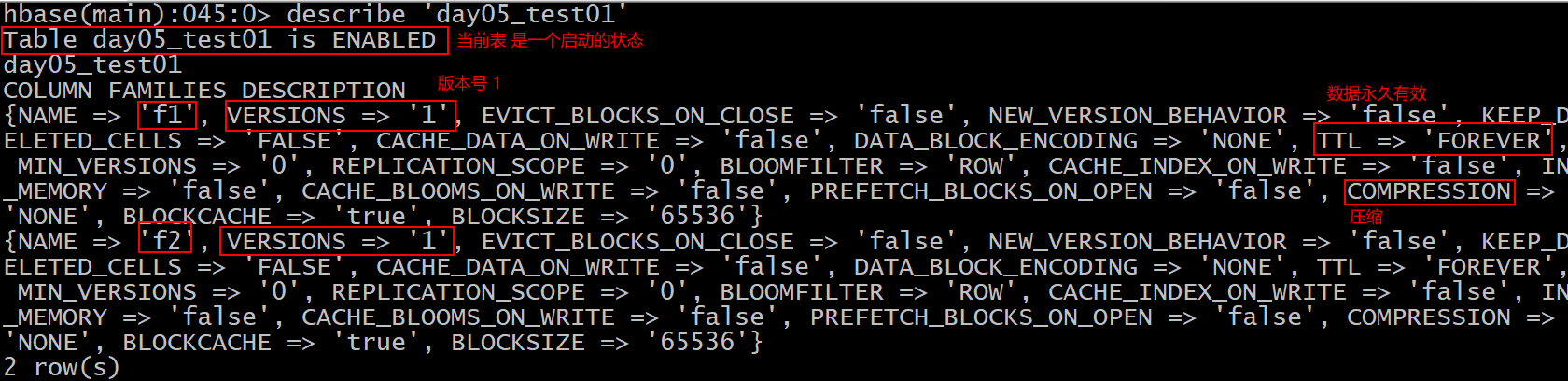
- 10- 如何查看表结构
格式:
describe '表名'
- 1
- 2
- 11- 如何清空表
格式:
truncate '表名'
底层: 先将表禁用 --> 删除表 --> 创建表
- 1
- 2
- 3
- 4

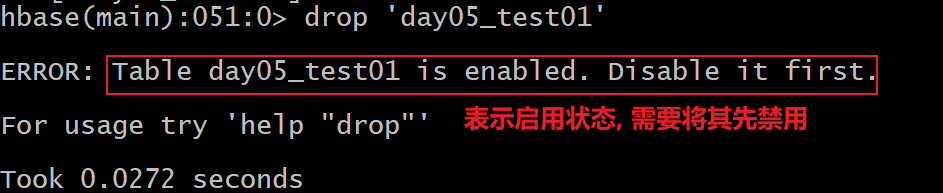
- 12- 如何删除表
格式:
drop '表名'
- 1
- 2
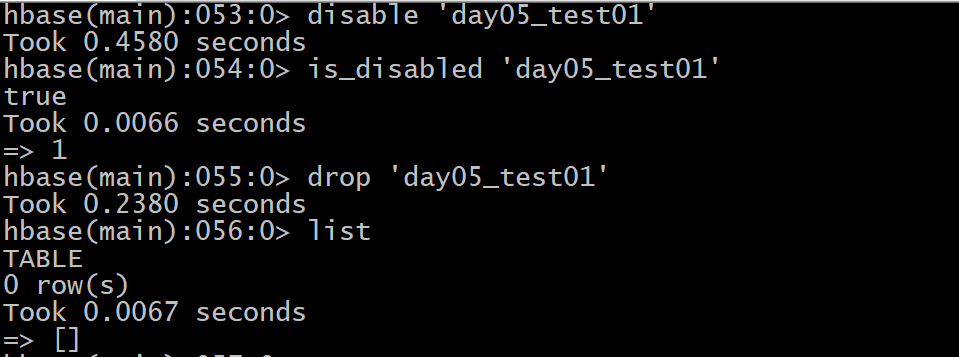
如何禁用表:
disable '表名'
如何启用表:
enable '表名'
如何判断表是否是禁用/启用:
is_disabled '表名'
is_enabled '表名'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 13- 如何查询多个数据
初始化一些相关数据:
create 'test01','f1','f2'
添加数据:
put 'test01','rk0001','f1:name','zhangsan'
put 'test01','rk0001','f1:age',20
put 'test01','rk0001','f2:address','beijing'
put 'test01','rk0001','f2:sex','M'
put 'test01','rk0002','f1:name','lisi'
put 'test01','rk0002','f1:age',25
put 'test01','rk0002','f2:address','上海'
put 'test01','rk0002','f2:sex','F'
put 'test01','rk0003','f1:name','wangwu'
put 'test01','rk0003','f1:age',22
put 'test01','rk0003','f2:address','guangzhou'
put 'test01','rk0003','f2:sex','F'
put 'test01','rk0004','f1:name','赵六'
put 'test01','rk0004','f1:age',26
put 'test01','rk0004','f2:address','深圳'
put 'test01','rk0004','f2:sex','M'
put 'test01','0001','f1:name','tianqi'
put 'test01','0001','f1:age',29
put 'test01','0001','f2:address','hangzhou'
put 'test01','0001','f2:sex','M'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
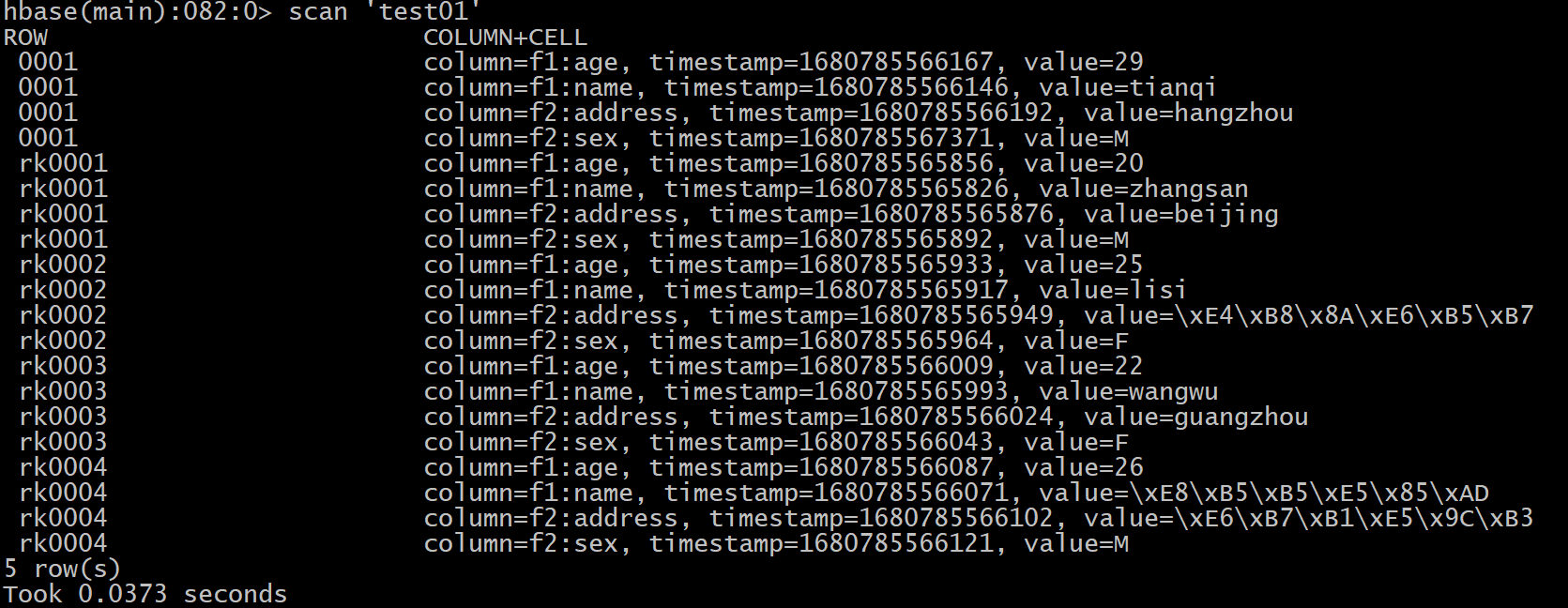
查询多条数据: scan
格式:
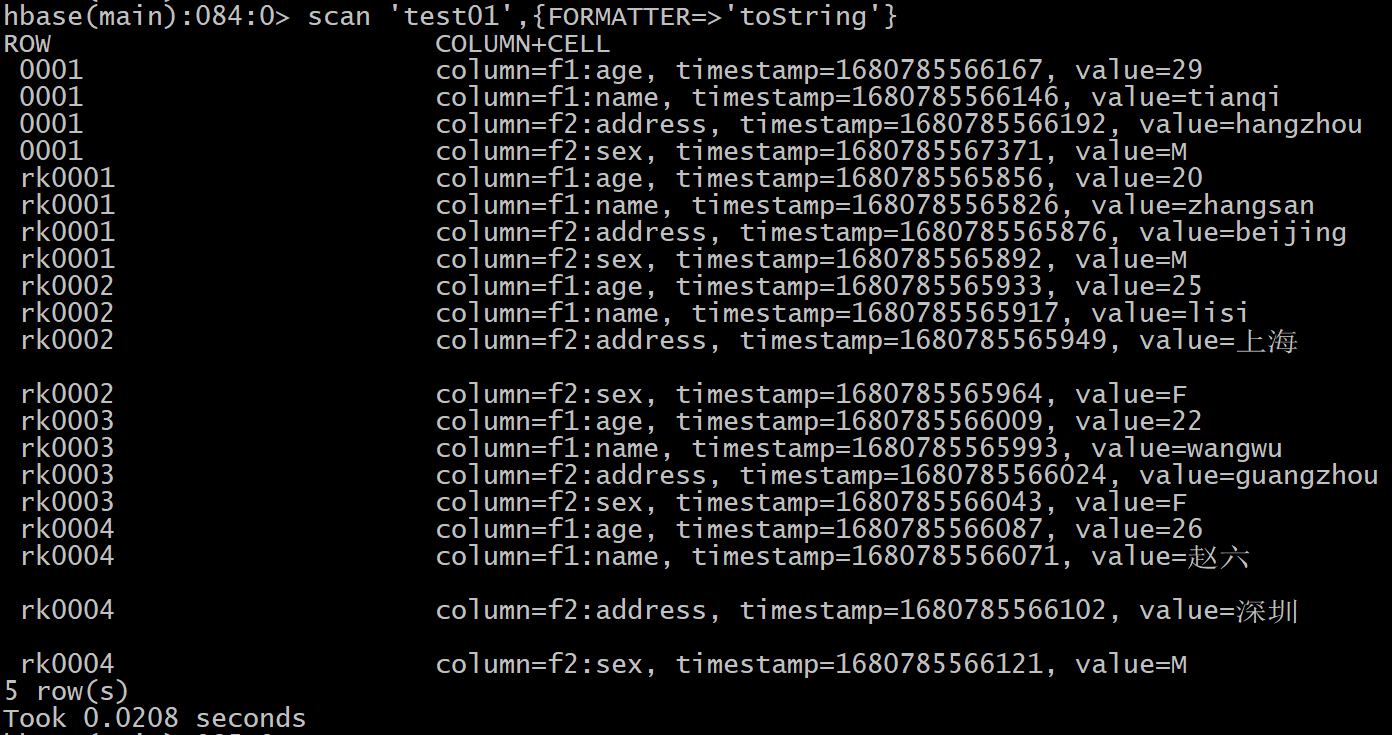
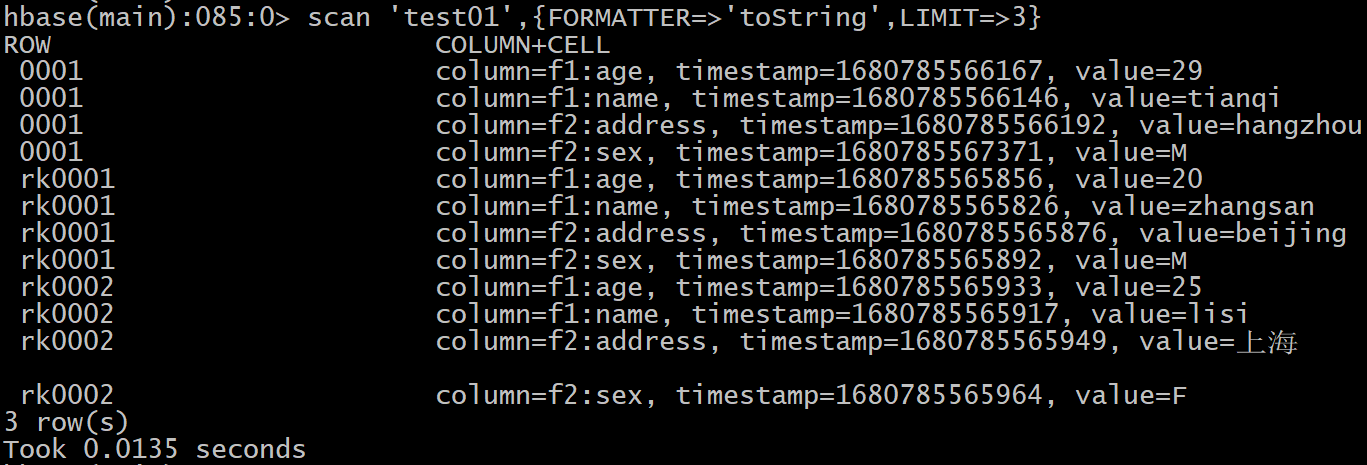
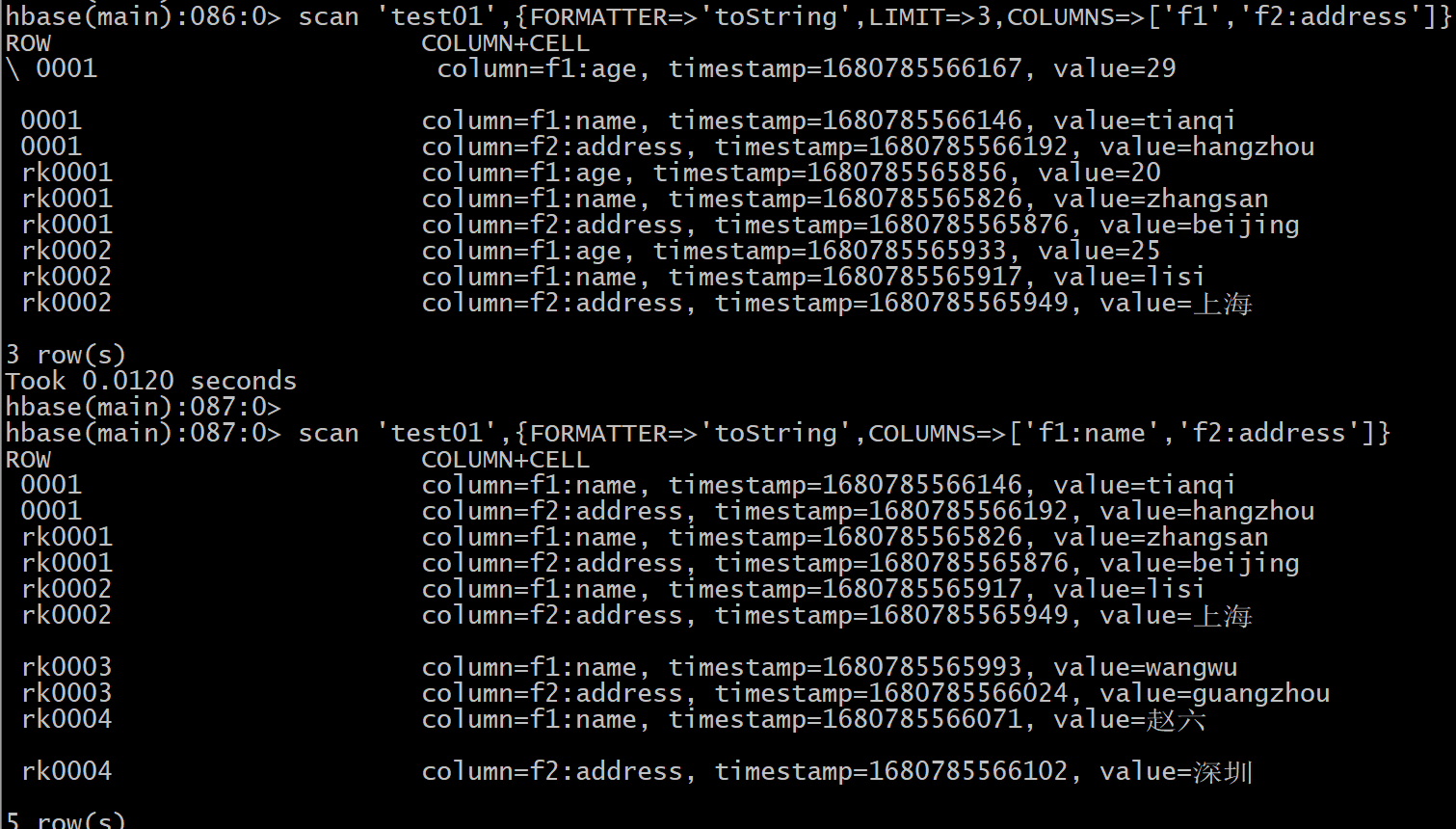
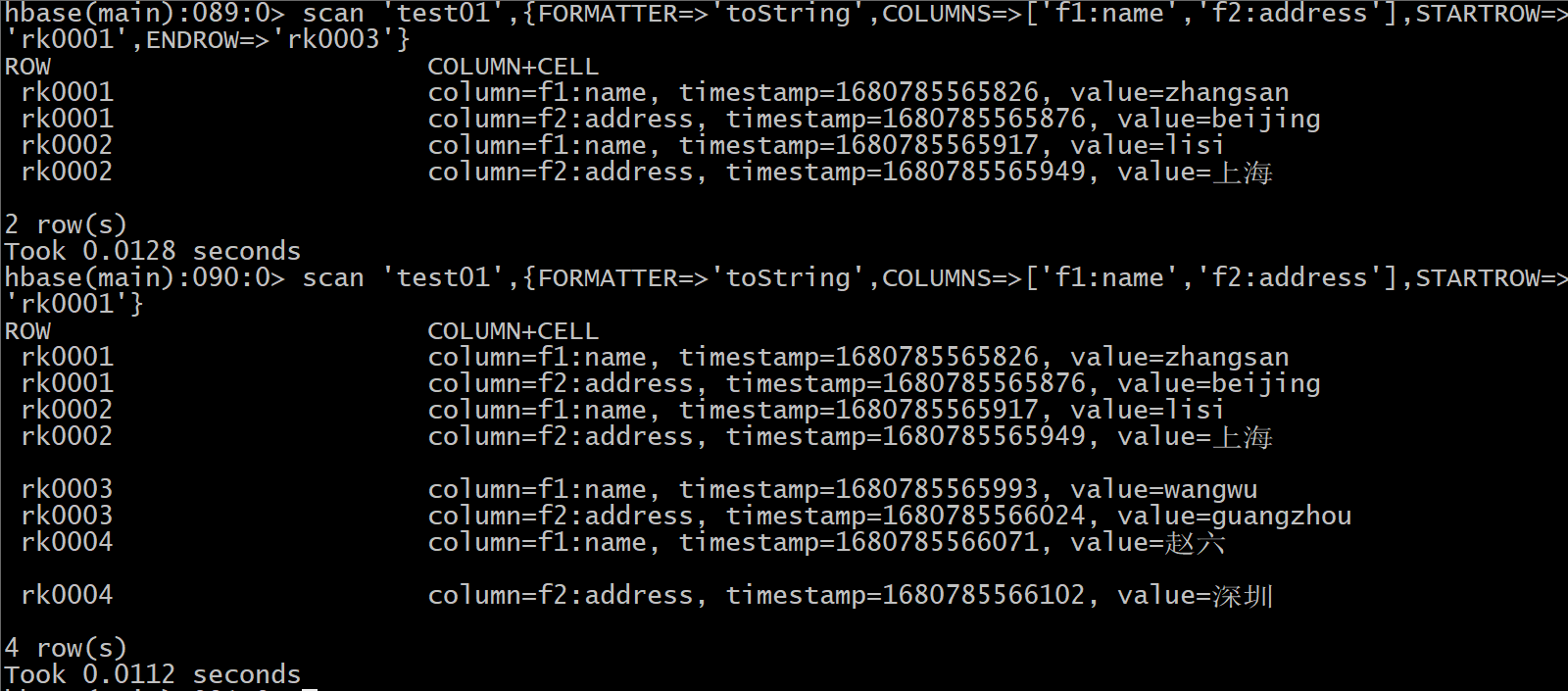
scan '表名'[,{COLUMNS=>['列族1','列族2'] || COLUMNS=>['列族1','列族2:列名'] || COLUMNS=>['列族1:列名','列族2:列名'], FORMATTER=>'toString', LIMIT=>N,STARTROW=>'起始rowkey', ENDROW=>'结束rowkey']
范围查询:
STARTROW=>'起始rowkey', ENDROW=>'结束rowkey'
包头不包尾
注意: 当只写STARTROW 不写 ENDROW, 表示 从指定的rowkey开始 直到结束
说明:
FORMATTER=>'toString' 用于显示中文
LIMIT=>N : 显示前N行数据
注意:
1- 每一个属性 都可以随意使用, 并不是必须组合在一起
2- 也不存在先后的顺序
3- 大小写是区分, 不要写错
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 14- 查看表共计有多少条数据
格式:
count '表名'
- 1
- 2

HBase的高级shell操作
- 1- HBase的过滤器查询操作
格式:
scan '表名',{FILTER=>"过滤器的名字(比较运算符,比较器表达式)"}
常见的过滤器:
rowkey相关的过滤器:
RowFilter: 实现行键字符串的比较和过滤操作
PrefixFilter: rowkey的前缀过滤器
列族过滤器:
FamilyFilter: 列族过滤器
列名过滤器:
QualifierFilter: 列名过滤器
列值过滤器:
ValueFilter: 列值过滤器, 找到符合对应列的数据值
SingleColumnValueFilter: 在指定的列族和列名中进行比较具体的值, 将符合的数据全部都返回(包含条件的内容字段)
SingleColumnValueExcludeFilter: 在指定的列族和列名中进行比较具体的值, 将符合的数据全部都返回(不包含条件的内容字段)
比较运算符: > < >= <= !=
比较器:
比较器 比较器表达式
BinaryComparator binary:值 完整匹配字节数据
BinaryPrefixComparator binaryprefix: 值 匹配字节数据的前缀
NullComparator null 匹配null值
SubstringComparator substring:值 模糊匹配操作
HBase的 API 文档: https://hbase.apache.org/2.1/apidocs/index.html
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
需求:
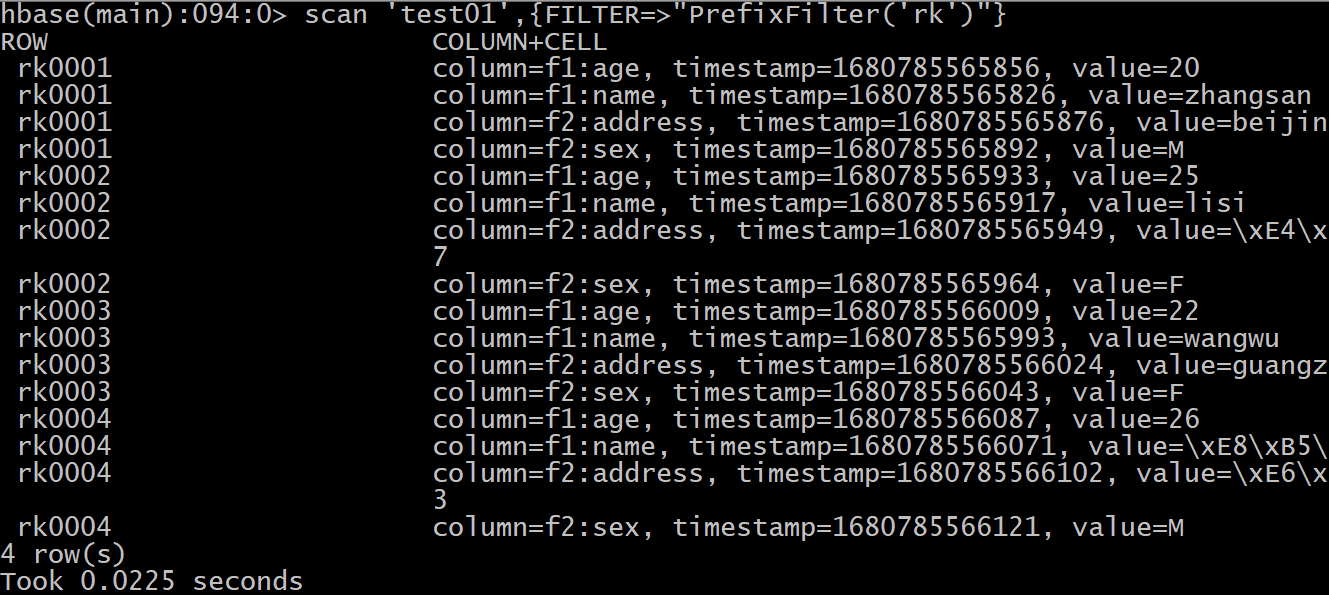
- 1- 查询rowkey中以 rk 开头的数据
scan 'test01',{FILTER=>"PrefixFilter('rk')"}
- 1
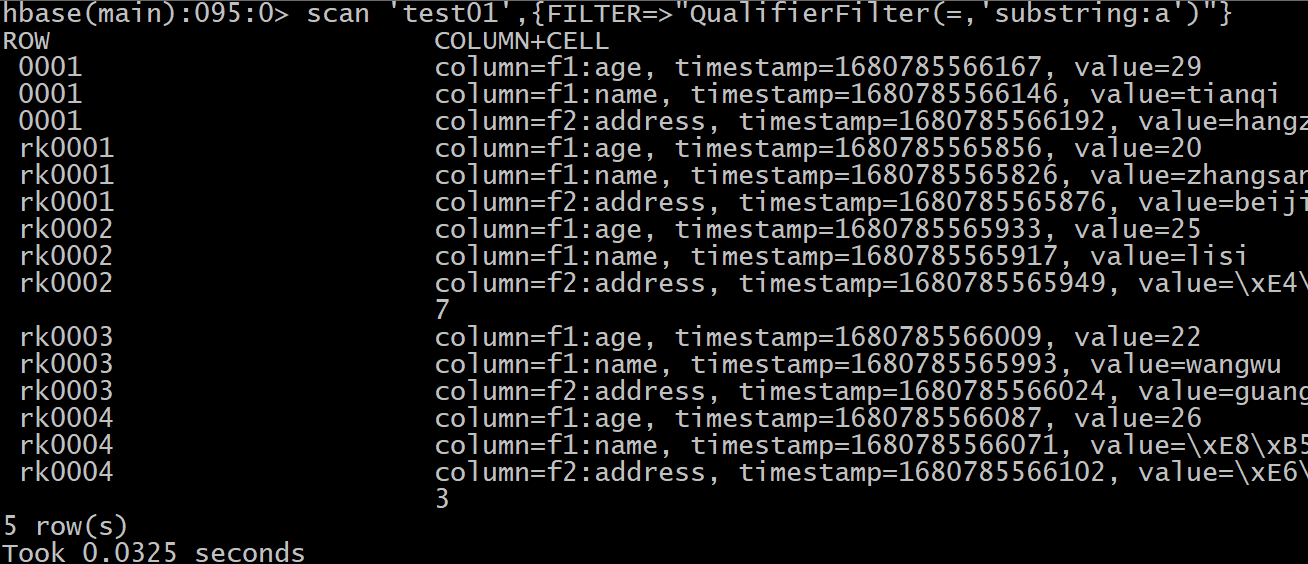
- 2- 查询在列名中包含 a字段的列有哪些?
scan 'test01',{FILTER=>"QualifierFilter(=,'substring:a')"}
- 1
- 3- 查询在f1列族下 name列中 包含 z 展示出来
scan 'test01',{FILTER=>"ValueFilter(=,'substring:z')"} -- 不满足要求
- 1

scan 'test01',{FILTER=>"SingleColumnValueFilter('f1','name',=,'substring:z')"} -- 找到后, 将整个数据全部都返回了
- 1

scan 'test01',{FILTER=>"SingleColumnValueExcludeFilter('f1','name',=,'substring:z')"}
- 1

- 2- whoami: 显示HBase当前登录使用用户
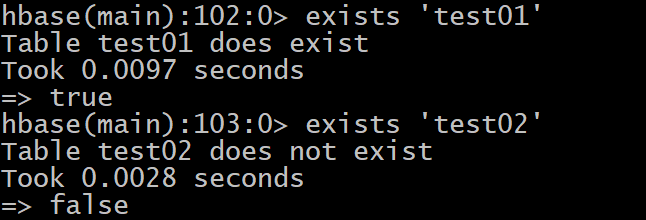
- 3- exists: 判断表是否存在
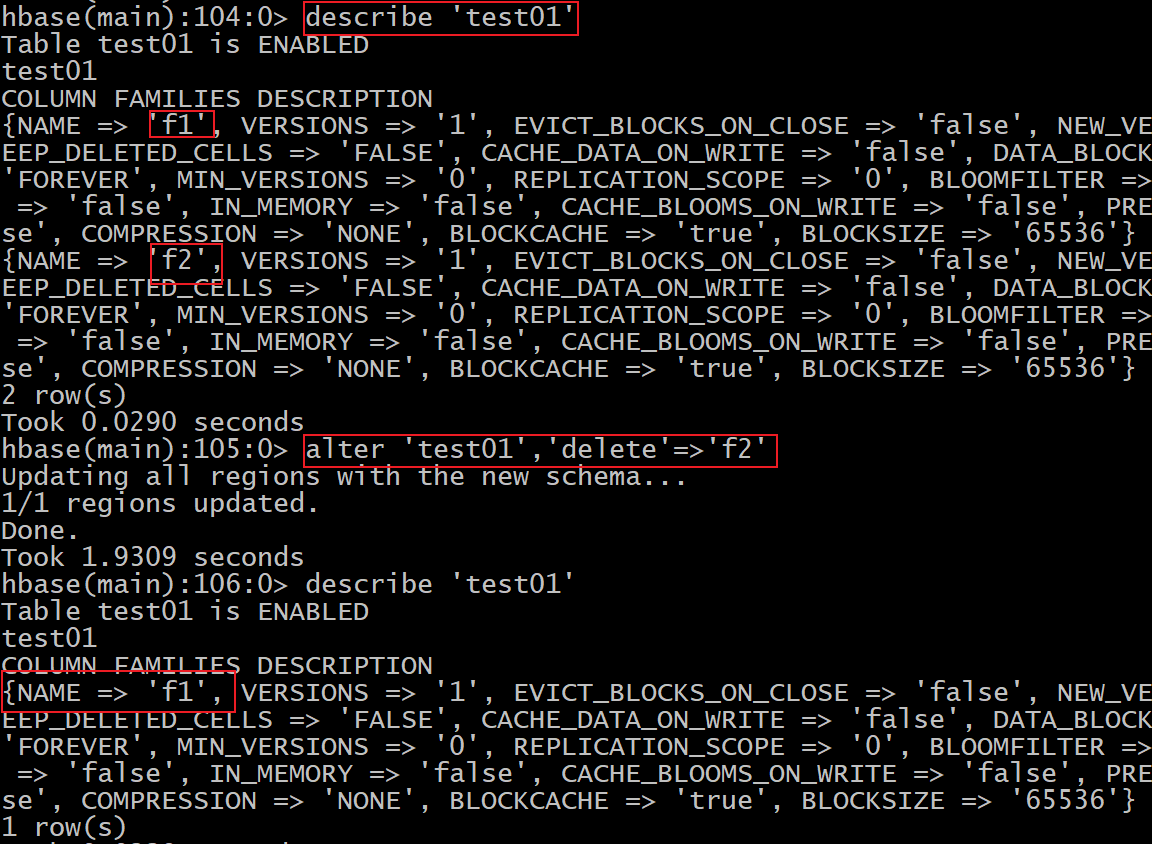
- 4- alter 修改表结构信息
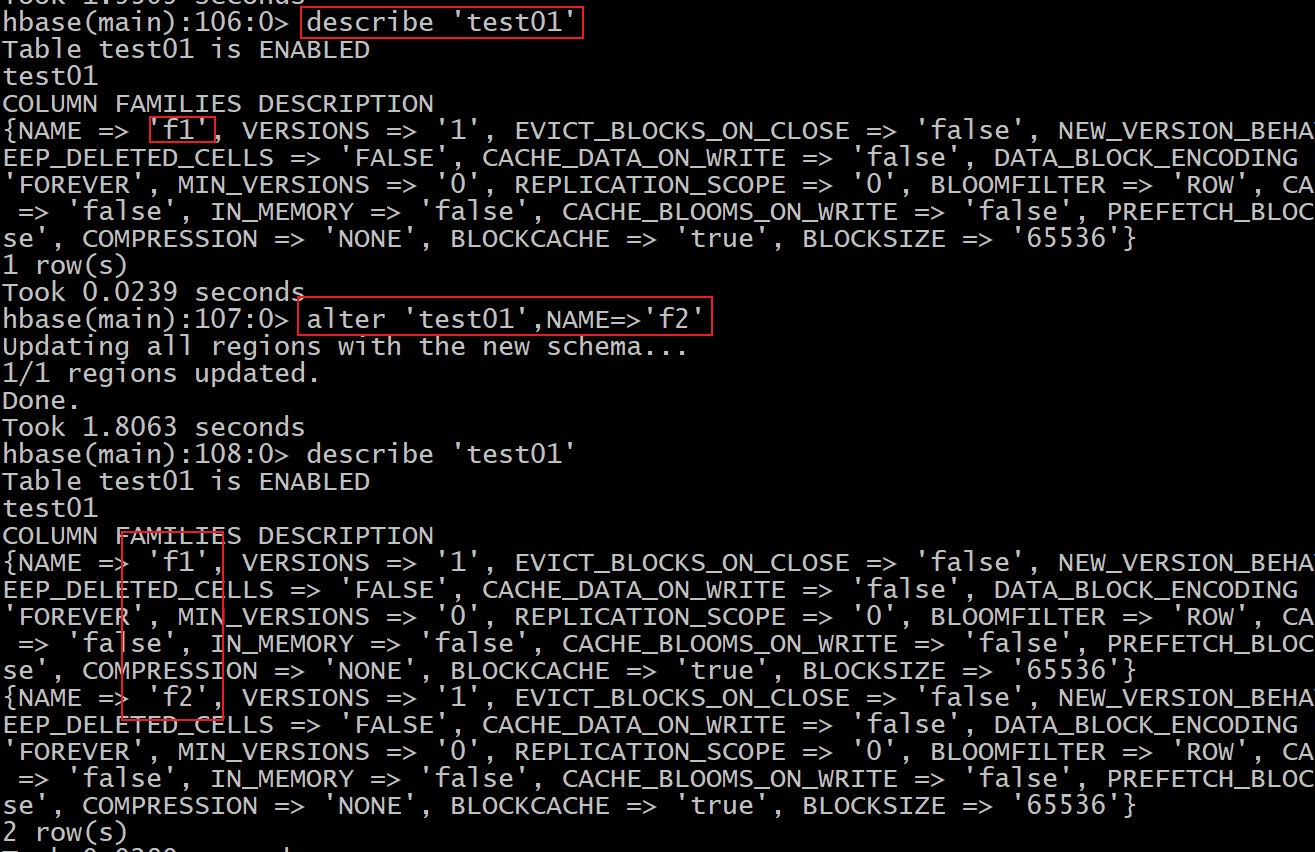
添加列族:
alter '表名' , NAME =>'新列族'[,VERSION=>N]
删除列族:
alter '表名','delete' =>'旧列族'
- 1
- 2
- 3
- 4
- 5
删除列族:
增加列族
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/article/detail/37956
推荐阅读

相关标签

