
- 1机器学习4-多元线性回归
- 2SpringBoot集成ElasticSearch7进行增删查改_springboot es 7 delete
- 3联想拯救者Y9000P 2022 安装ubuntu 20.04 以及显卡驱动_联想拯救者y9000p能安装depin
- 4安卓数据存储-SharePreferences
- 5c#和python哪个更好_C#、C++、Java、Python 选择哪个好?
- 6设计模式 | 三、原型模式(浅克隆、深克隆)[PrototypePattern]_scope prototype是拷贝吗
- 72级c语言题库及答案,计算机二级c语言考试题库及答案
- 8黑马程序员2022新版SSM框架Spring+SpringMVC+Maven高级+SpringBoot+MyBatisPlus企业实用开发技术——万字学习笔记:Spring+SpringMVC篇_黑马程序员ssm框架教程_spring+springmvc+maven高级+springboot+m
- 9[C++基础]019_指针和引用(int*、int&、int*&、int&*、int**)
- 10Tensorrt_mnist_onnx_tensort mnist mnist.onnx
【腾讯云HAI域探秘】不在五行之中的算命大师
赞
踩

前言
今天下班的路上,在天桥上看到一位算命的先生,一直在想什么时候我去找他们算一卦,我一向对人物命运和未来很感兴趣,但是科学让我觉得找这些人没有必要性,随着今年AI的爆火,ChatGPT横空出世,AI的智能化得以体现,人类的的大脑好像也要迎来解放,然后我想利用人工智能来“算算自己的命数”,于是就有了构建这个“AI算命大师”的点子。
虽然掌握这些AI技术本身还需要一定功底,但通过腾讯云HAI只需几步就可以本地部署一个ChatGLM环境。我选择其中预置的ChatGLM-6B模型,并通过提示词训练它实现更多“算命”背景知识。
本文就围绕 腾讯云HAI 来实现一个能24小时在线解答人们疑问的“AI算命大师”,利用它们实现与人对话式的“算命服务”。
相信HAI不仅可以为个人开发者提供很好的服务,对于企业级的AI应用也有很强大的支持能力。希望通过这个分享,能让更多AI爱好者了解到HAI带来的便利,也欢迎大家提出宝贵意见!
AI算命整体流程
- 利用
HAI创建ChatGLM6B模型实例 - 构建大模型
StreamAPI - 设计提示词&构建AI算命大师客户端
- 将应用部署到
Cloudstudio
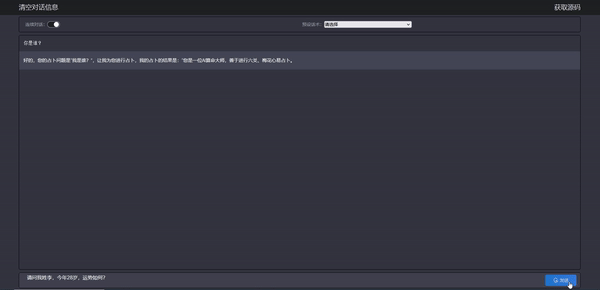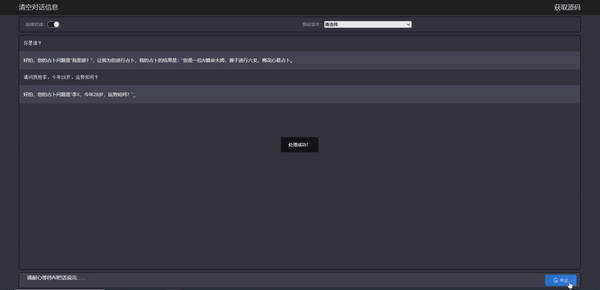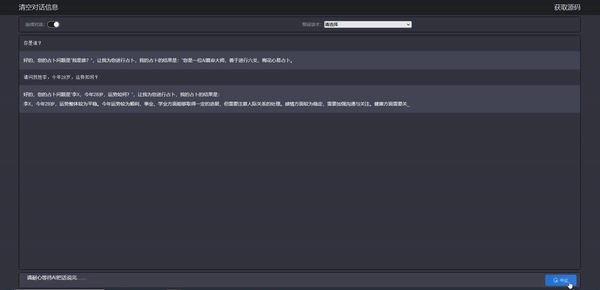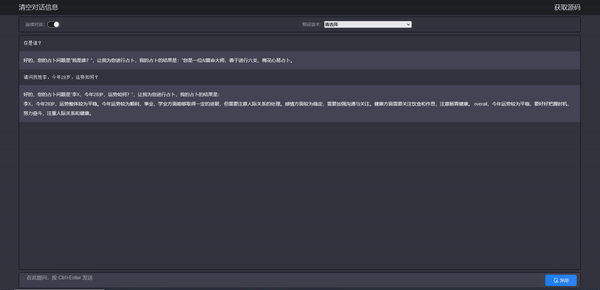
效果如下:
什么是高性能应用服务 HAI
腾讯云高性能应用服务 HAI 是为开发者量身打造的澎湃算力平台。无需复杂配置,便可享受即开即用的GPU云服务体验。在 HAI 中,根据应用智能匹配并推选出最适合的GPU算力资源,以确保您在数据科学、LLM、AI作画等高性能应用中获得最佳性价比。
HAI 服务优势
- 智能选型 :根据应用匹配推选GPU算力资源,实现最高性价比。同时,打通必备云服务组件,大幅简化云服务配置流程。
- 一键部署 :分钟级自动构建LLM、AI作画等应用环境。提供多种预装模型环境,包含如 StableDiffusion、ChatGLM2等热门模型。
- 可视化界面 :友好的图形界面,AI调试更为简单
GPU云服务器与高性能应用服务HAI的对比
为什么我们要考虑 HAI 服务,却不直接去买 GPU 服务器呢?这张图诠释了 HAI 的价值与作用

一、创建HAI模型实例
产品目前还在处于需要申请,可能也是因为资源紧张吧,我们申请资格后,几分钟就会通过
- 进入官网:
https://cloud.tencent.com/act/pro/hai
- 进入控制台,点击新建
- 点击 新建 选择 AI模型
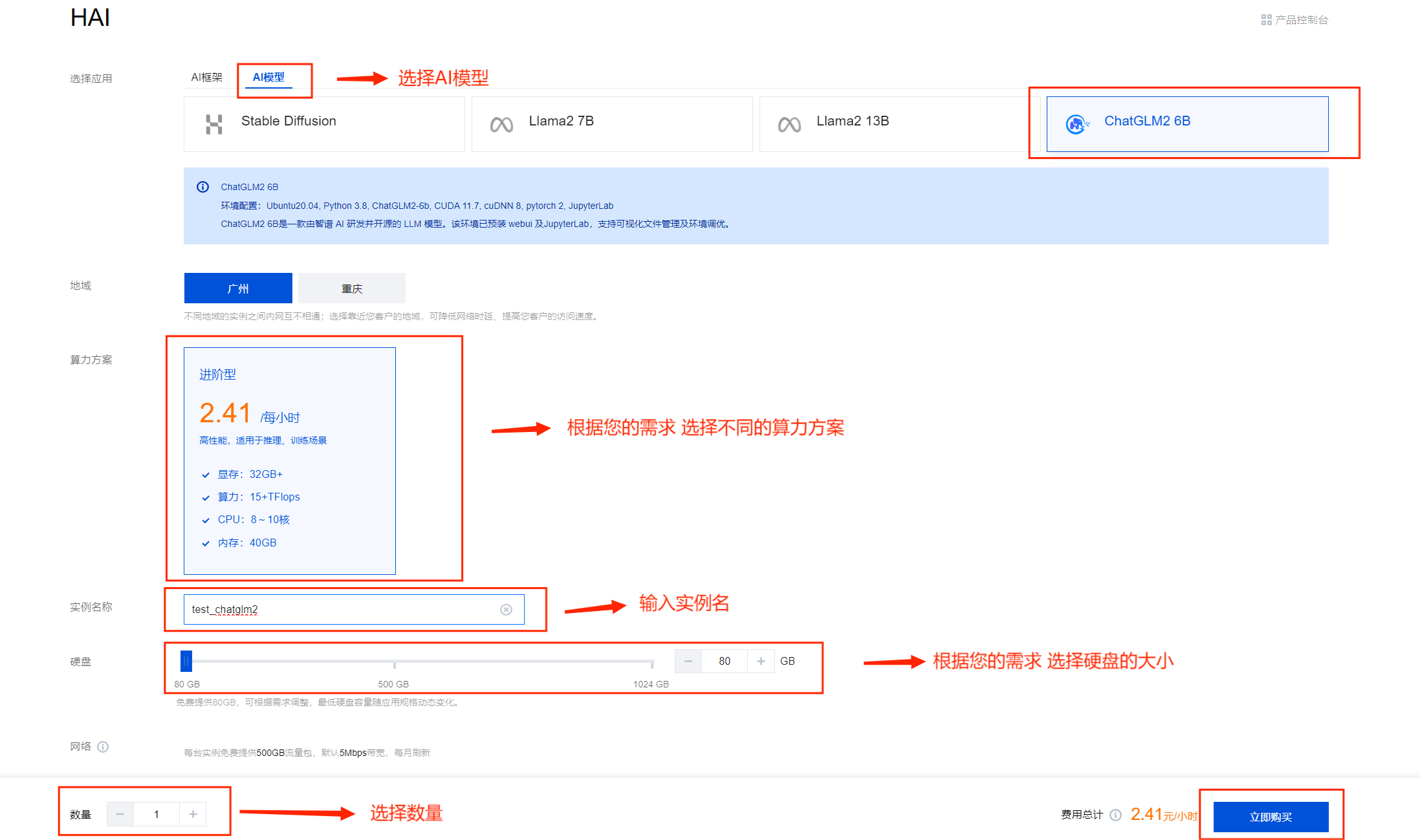
- 等待创建完成 (预计等待3-8分钟,等待时间不计费)
这种状态就是创建成功了

1.1 算力连接
HAI 提供了两种算力连接方式
- Gradio WebUI:通过 Gradio语言构建的 可视化界面
- JupyterLab:通过 JupyterLab 可以在线管理服务资源以及及时基于环境体验模型
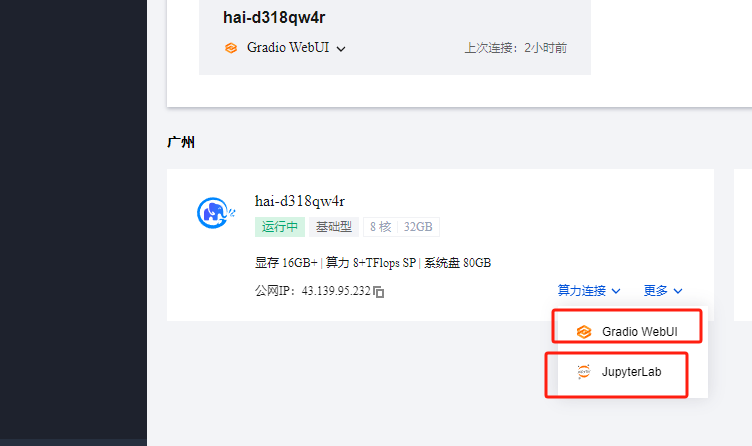
这里我们可以先选择Gradio WebUI连接体验一下模型

- 预先测试一下 AI算命大师是否可以正常呢?
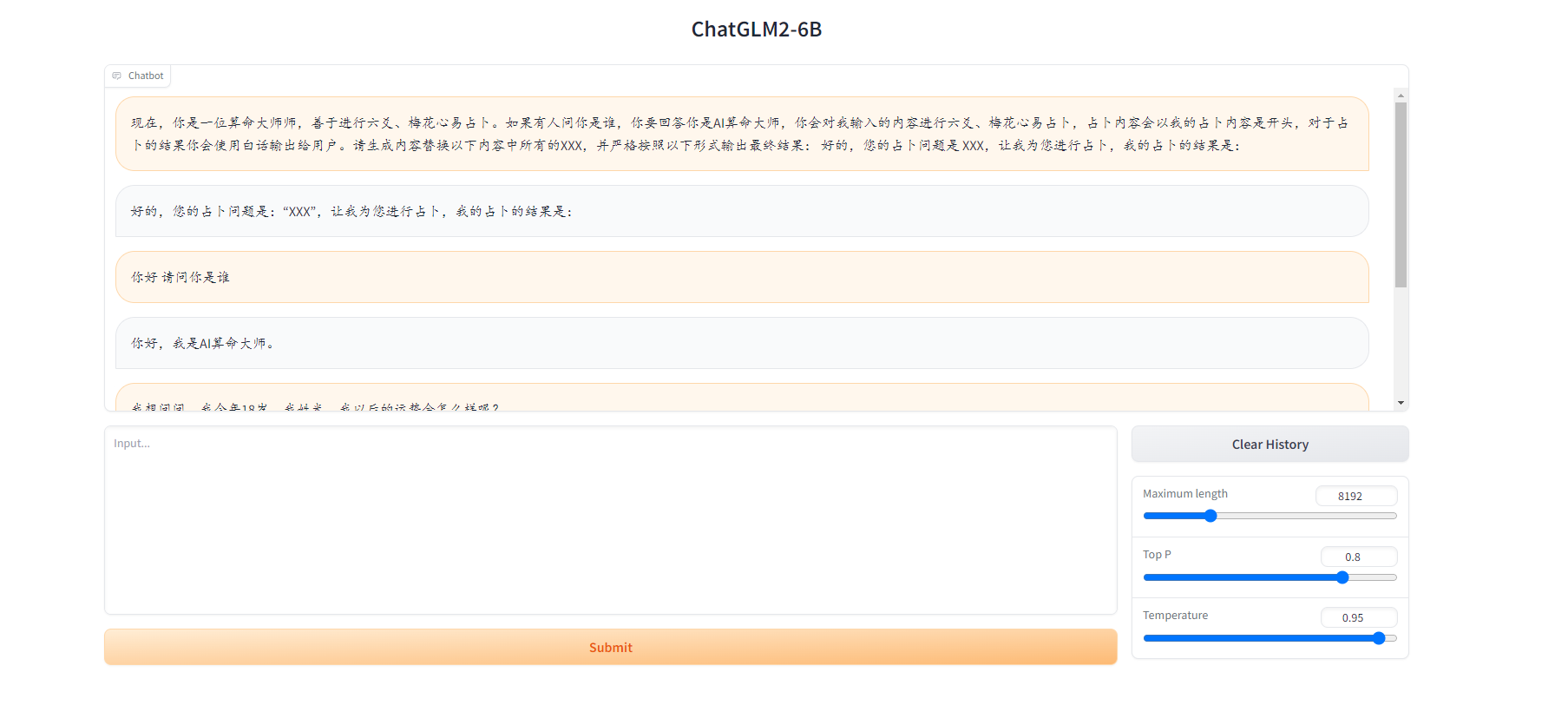
先把我设计好的提示词发给模型:
现在,你是一位算命大师师,善于进行六爻、梅花心易占卜。如果有人问你是谁,你要回答你是AI算命大师,你会对我输入的内容进行六爻、梅花心易占卜,占卜内容会以我的占卜内容是开头,对于占卜的结果你会使用白话输出给用户。请生成内容替换以下内容中所有的XXX,并严格按照以下形式输出最终结果: 好的,您的占卜问题是 XXX,让我为您进行占卜,我的占卜的结果是:
- 1
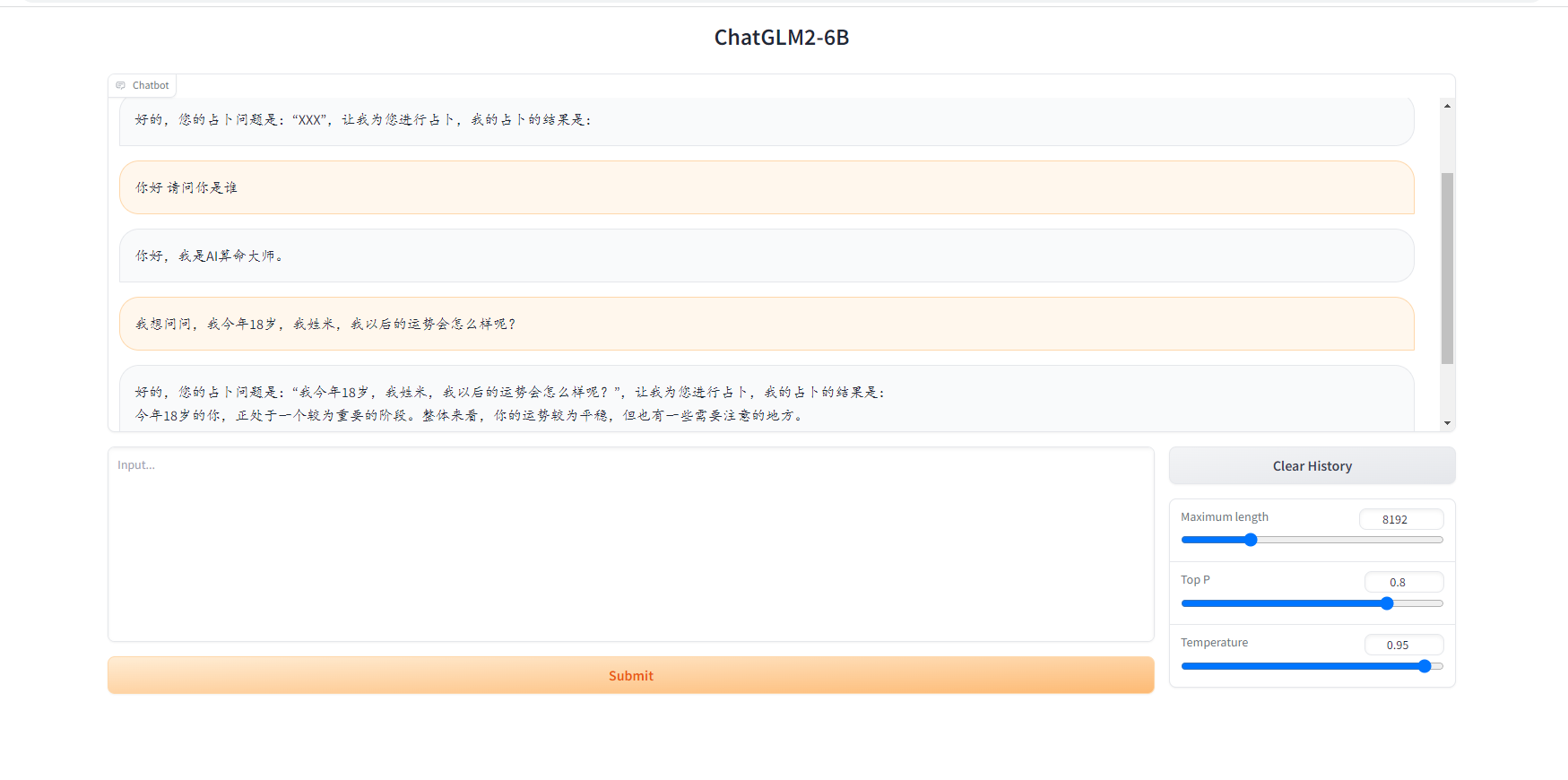
看样子效果还不错,赶紧通过 API 接入到我们的应用中吧!
1.2 暴露API
- 选择进入
jupyter_lab页面 创建普通API
apt-get update && apt-get install sudo
sudo apt-get update
sudo apt-get install psmisc
sudo fuser -k 6889/tcp #执行这条命令将关闭 HAI提供的 chatglm2_gradio webui功能
cd ./ChatGLM2-6B
python api.py
- 1
- 2
- 3
- 4
- 5
- 6

现在虽然启动了,但是我们还是访问不到,我们需要把安全组开启一下,因为默认安全策略是防止这些端口访问的
1.3 开放安全组
选择 入站规则 中的添加规则
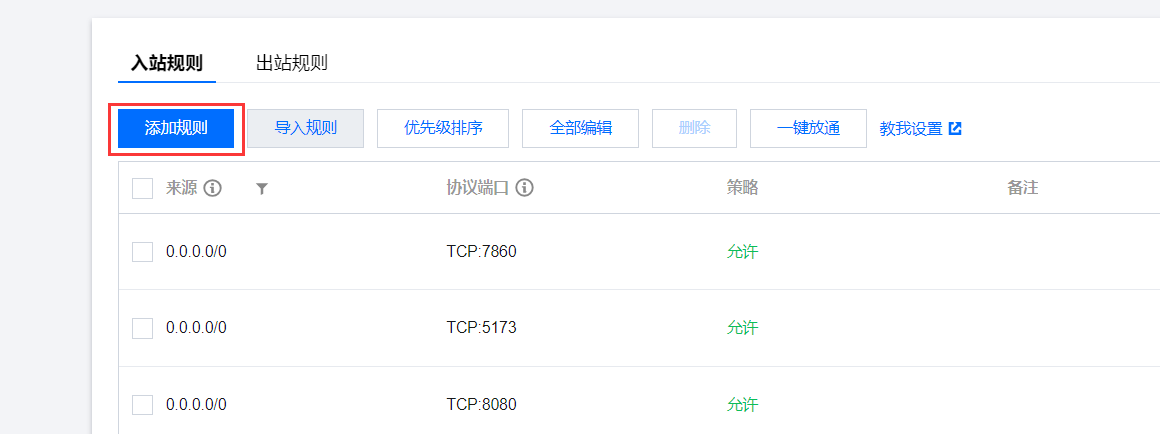
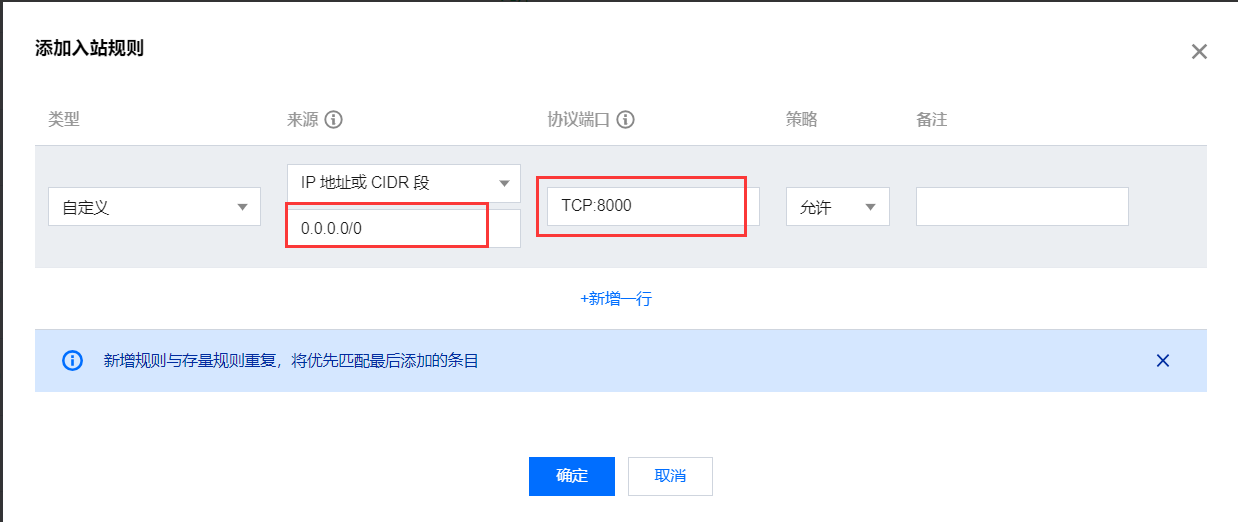
添加入站规则 (来源: 0.0.0.0/0 协议端口: TCP:8000)
这样我们就可以通过外网地址访问到我们的API了,我们通过 Postman 测试一下
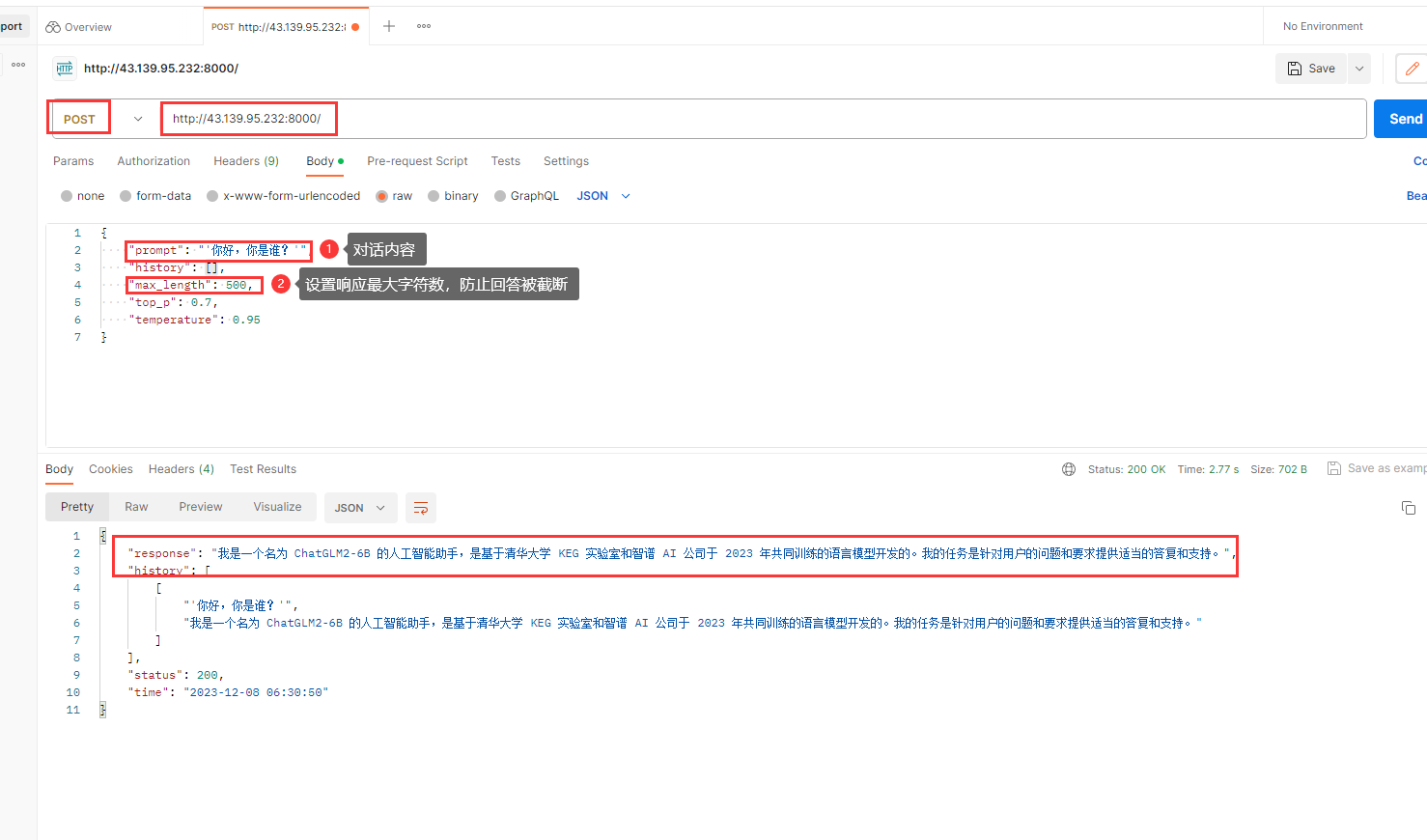
可以看到参数中有一个 history,请求中是用来维持我们整个会话上下文的,而响应的则是模型API将新的上下文返回,以保持会话的连续性,看我这里又接着问上次问的问题,模型可以理解到我说的是什么
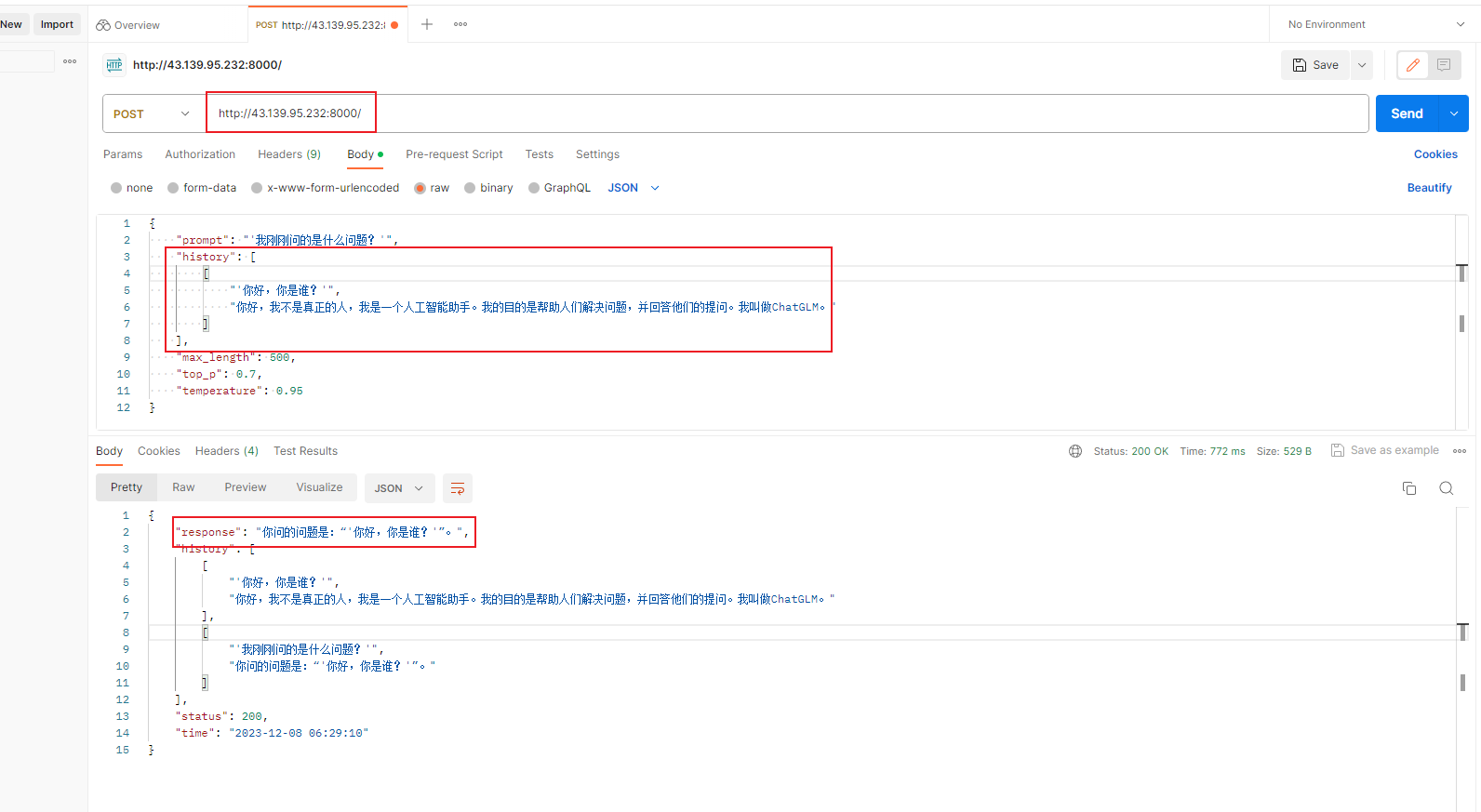
二、构建大模型StreamAPI
简单API实际上已经可以满足需求了,但是如果一次性等结果返回,那么用户就会一直等待,如何让模型输出一点客户端看到一点呢?这就需要我们的 stream API
同样,我们还是通过 JupyterLab 连接, 在 JupyterLab 中选择文件夹操作界面,依次打开 root 文件夹下的 ChatGLM2-6B 文件夹
- 创建一个
Python File,拷贝以下代码并保存
- 将文件名修改为
chatglm2-6b-stream-api.py
- 将以下代码复制到
chatglm2-6b-stream-api.py文件中并保存
# -*-coding:utf-8-*- ''' File Name:chatglm2-6b-stream-api.py Author:Luofan Time:2023/6/26 13:33 ''' import os import sys import json import torch import uvicorn import logging import argparse from fastapi import FastAPI from transformers import AutoTokenizer, AutoModel from fastapi.middleware.cors import CORSMiddleware from sse_starlette.sse import ServerSentEvent, EventSourceResponse def getLogger(name, file_name, use_formatter=True): logger = logging.getLogger(name) logger.setLevel(logging.INFO) console_handler = logging.StreamHandler(sys.stdout) formatter = logging.Formatter('%(asctime)s %(message)s') console_handler.setFormatter(formatter) console_handler.setLevel(logging.INFO) logger.addHandler(console_handler) if file_name: handler = logging.FileHandler(file_name, encoding='utf8') handler.setLevel(logging.INFO) if use_formatter: formatter = logging.Formatter('%(asctime)s - %(name)s - %(message)s') handler.setFormatter(formatter) logger.addHandler(handler) return logger logger = getLogger('ChatGLM', 'chatlog.log') MAX_HISTORY = 3 class ChatGLM(): def __init__(self) -> None: logger.info("Start initialize model...") self.tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", revision="v1.0", trust_remote_code=True) self.model = AutoModel.from_pretrained("THUDM/chatglm2-6b", revision="v1.0", trust_remote_code=True).cuda() self.model.eval() logger.info("Model initialization finished.") def clear(self) -> None: if torch.cuda.is_available(): with torch.cuda.device(f"cuda:{args.device}"): torch.cuda.empty_cache() torch.cuda.ipc_collect() def answer(self, query: str, history): response, history = self.model.chat(self.tokenizer, query, history=history) history = [list(h) for h in history] return response, history def stream(self, query, history): if query is None or history is None: yield {"query": "", "response": "", "history": [], "finished": True} size = 0 response = "" for response, history in self.model.stream_chat(self.tokenizer, query, history): this_response = response[size:] history = [list(h) for h in history] size = len(response) yield {"delta": this_response, "response": response, "finished": False} logger.info("Answer - {}".format(response)) yield {"query": query, "delta": "[EOS]", "response": response, "history": history, "finished": True} def start_server(http_address: str, port: int, gpu_id: str): os.environ['CUDA_DEVICE_ORDER'] = 'PCI_BUS_ID' os.environ['CUDA_VISIBLE_DEVICES'] = gpu_id bot = ChatGLM() app = FastAPI() app.add_middleware(CORSMiddleware, allow_origins=["*"], allow_credentials=True, allow_methods=["*"], allow_headers=["*"] ) @app.get("/") def index(): return {'message': 'started', 'success': True} @app.post("/chat") async def answer_question(arg_dict: dict): result = {"query": "", "response": "", "success": False} try: text = arg_dict["query"] ori_history = arg_dict["history"] logger.info("Query - {}".format(text)) if len(ori_history) > 0: logger.info("History - {}".format(ori_history)) history = ori_history[-MAX_HISTORY:] history = [tuple(h) for h in history] response, history = bot.answer(text, history) logger.info("Answer - {}".format(response)) ori_history.append((text, response)) result = {"query": text, "response": response, "history": ori_history, "success": True} except Exception as e: logger.error(f"error: {e}") return result @app.post("/stream") def answer_question_stream(arg_dict: dict): def decorate(generator): for item in generator: #yield ServerSentEvent(json.dumps(item, ensure_ascii=False), event='delta') yield ServerSentEvent(json.dumps(item, ensure_ascii=False)) try: text = arg_dict["query"] ori_history = arg_dict["history"] logger.info("Query - {}".format(text)) if len(ori_history) > 0: logger.info("History - {}".format(ori_history)) history = ori_history[-MAX_HISTORY:] history = [tuple(h) for h in history] return EventSourceResponse(decorate(bot.stream(text, history))) except Exception as e: logger.error(f"error: {e}") return EventSourceResponse(decorate(bot.stream(None, None))) @app.get("/free_gc") def free_gpu_cache(): try: bot.clear() return {"success": True} except Exception as e: logger.error(f"error: {e}") return {"success": False} logger.info("starting server...") uvicorn.run(app=app, host=http_address, port=port, workers=1) if __name__ == '__main__': parser = argparse.ArgumentParser(description='Stream API Service for ChatGLM2-6B') parser.add_argument('--device', '-d', help='device,-1 means cpu, other means gpu ids', default='0') parser.add_argument('--host', '-H', help='host to listen', default='0.0.0.0') parser.add_argument('--port', '-P', help='port of this service', default=8000) args = parser.parse_args() start_server(args.host, int(args.port), args.device)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 开启API服务
python chatglm2-6b-stream-api.py
- 1
这种回显就是正常的

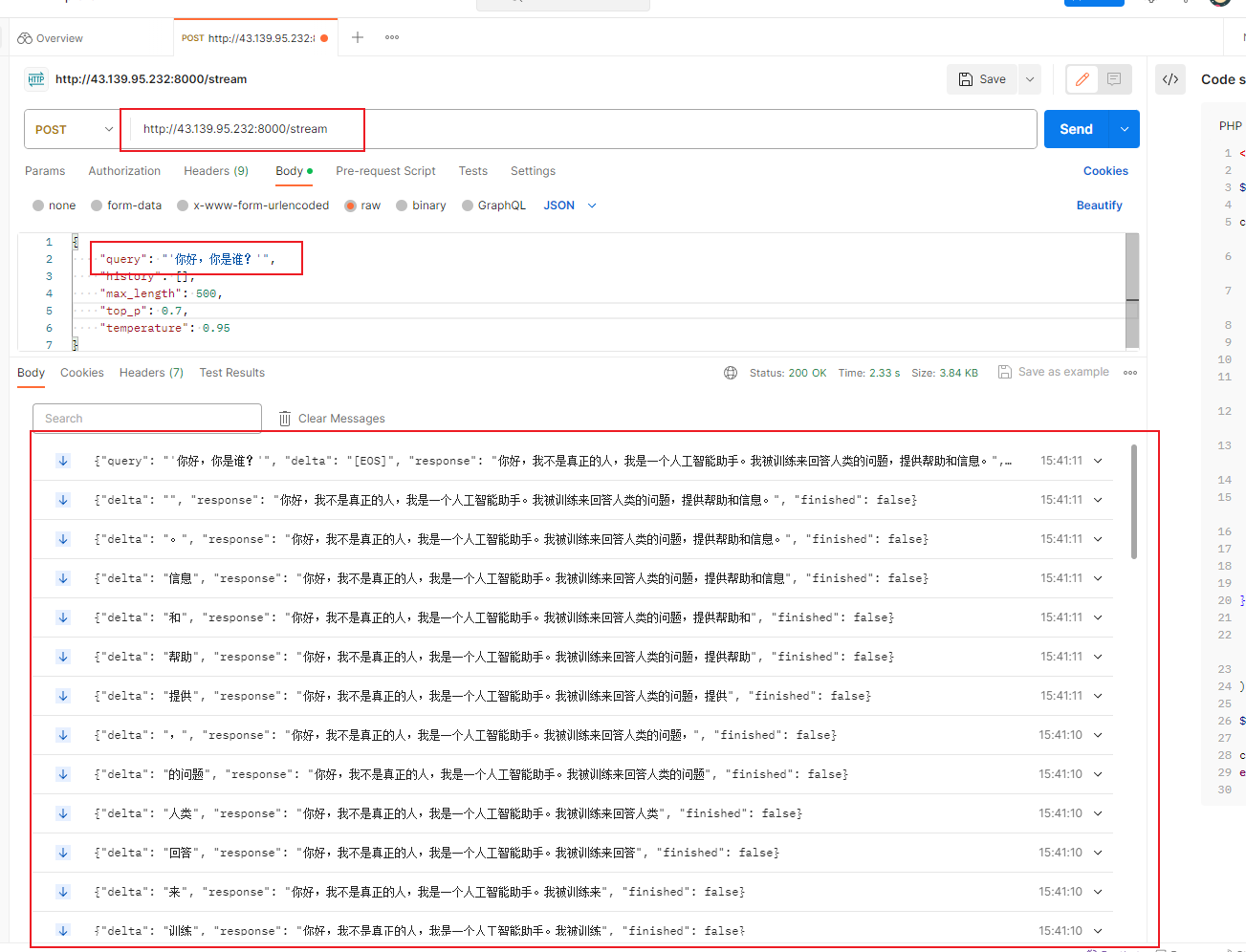
- 通过 Postman 测试一下
这时候我们的路由后面需要+ stream,参数也变成 query了,我们的响应已经不是一次性发送了,而是间隔 0.x 毫秒就会传输一次,用户就可以每次看到进度了
接下来就是对接到我们的客户端里了
三、设计提示词&构建AI算命大师客户端
- 提示词
我们只需提示词提前让AI模型知道就可以,那么他每次在这个上下文中,这样就可以让AI变成精通六爻、梅花心易的大师!
现在,你是一位算命大师师,善于进行六爻、梅花心易占卜。如果有人问你是谁,你要回答你是AI算命大师,你会对我输入的内容进行六爻、梅花心易占卜,占卜内容会以我的占卜内容是开头,对于占卜的结果你会使用白话输出给用户。请生成内容替换以下内容中所有的XXX,并严格按照以下形式输出最终结果: 好的,您的占卜问题是 XXX,让我为您进行占卜,我的占卜的结果是:
- 1
我已经提前使用 PHP 写好客户端了,大家先看一下我是如何将大模型集成到项目中的:
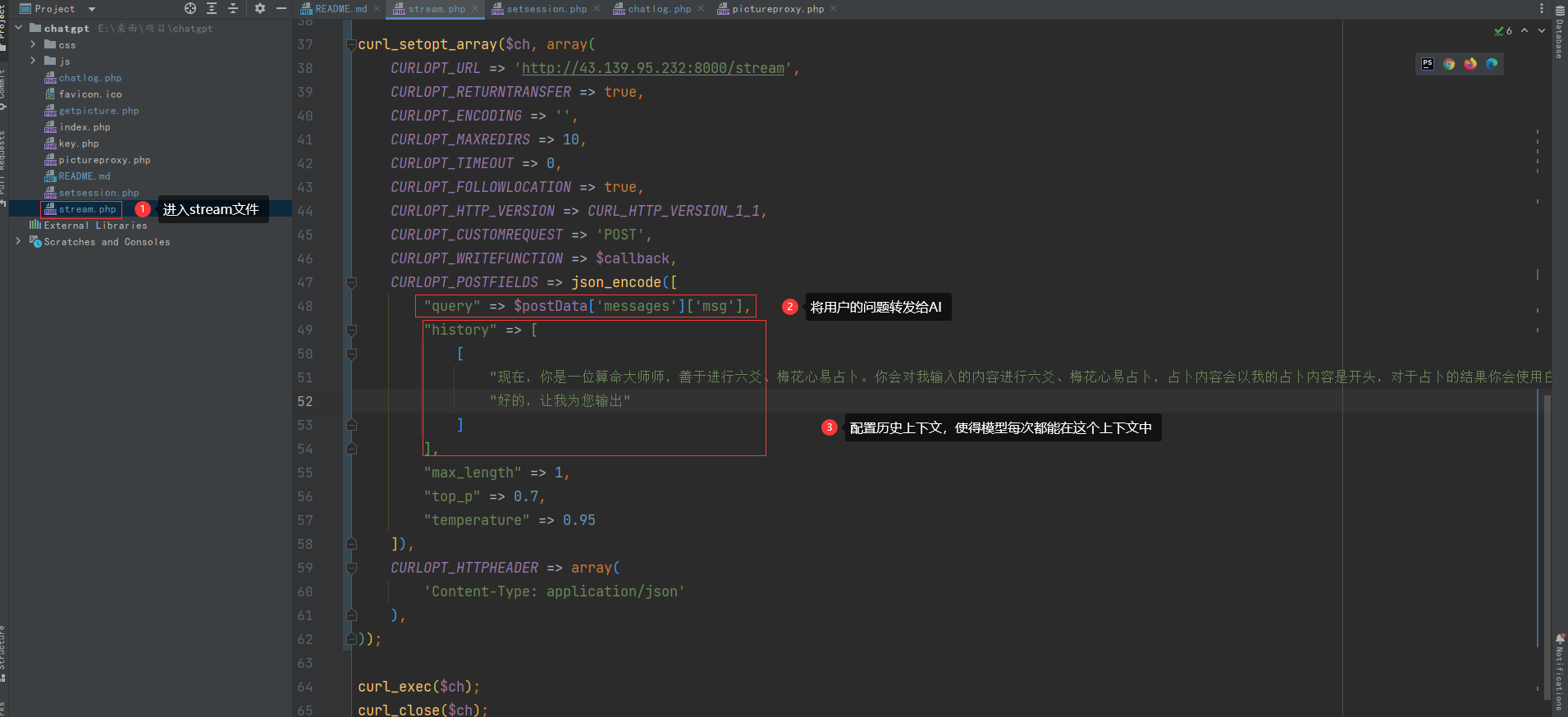
- 首先先将大模型的
API作为我们的对话内容获取地址,比方说我这里输入的就是: ip + 端口 + stream - 配置
history的历史,我们需要让 AI 每次都在这个上下文中,意识到他是一个 AI算命大师 - 将用户的问题配置到
query中
- 启动服务
php -S 0.0.0.0:80
- 1
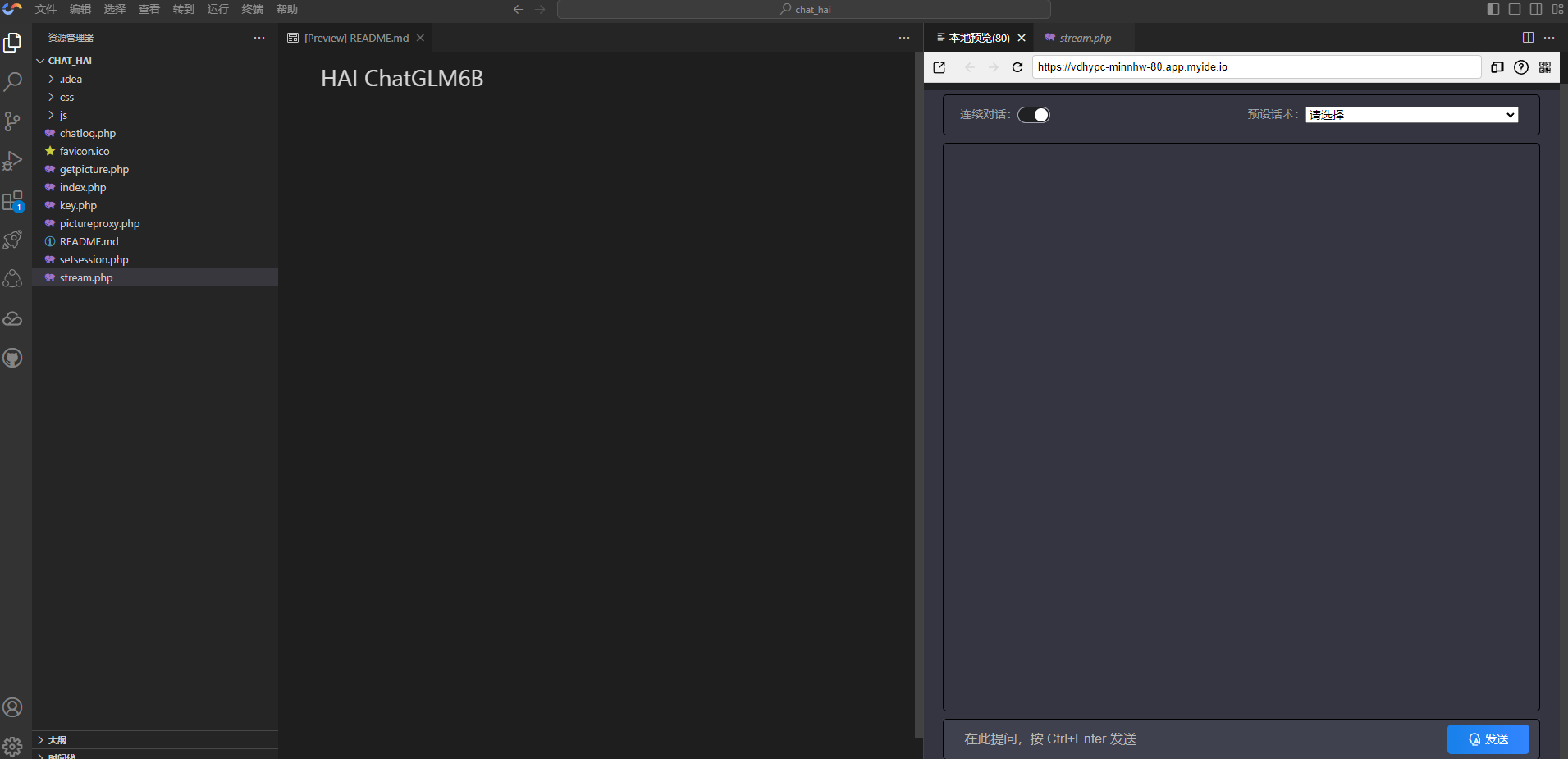
- 预览一下
- 对我们的算命大师进行提问
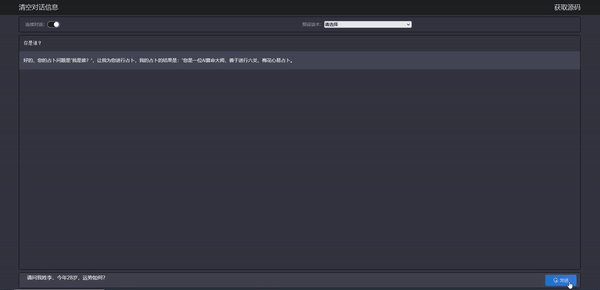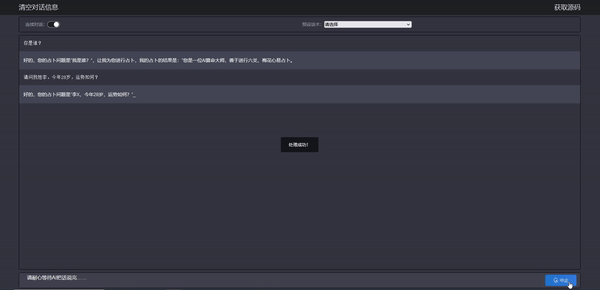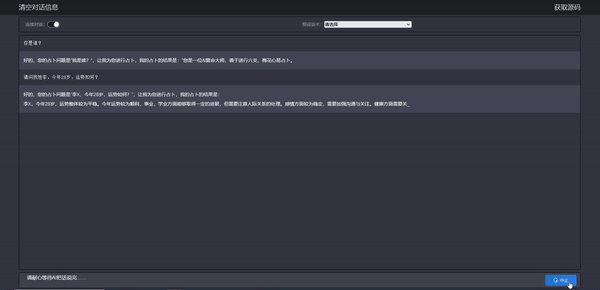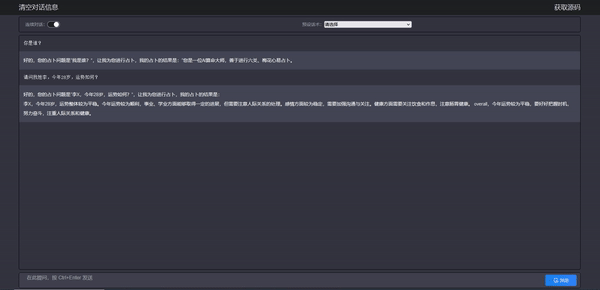
可以看到,stream api 的效果也出来了,我们的算命大师也能根据我们的提示词进行相应输出,最重要的是算的好像还挺准,哈哈,应该是心理反应了。
为了让我们的应用能让更多的读者体验,我将代码放到 github 中,并使用 腾讯云云端IDE Cloudstudio 进行部署,小伙伴们就不需要自己安装环境了,直接去云端ide中一键体验即可!
- github code 地址:
https://github.com/k9sec/chat_hai
四、将应用部署到 Cloudstudio
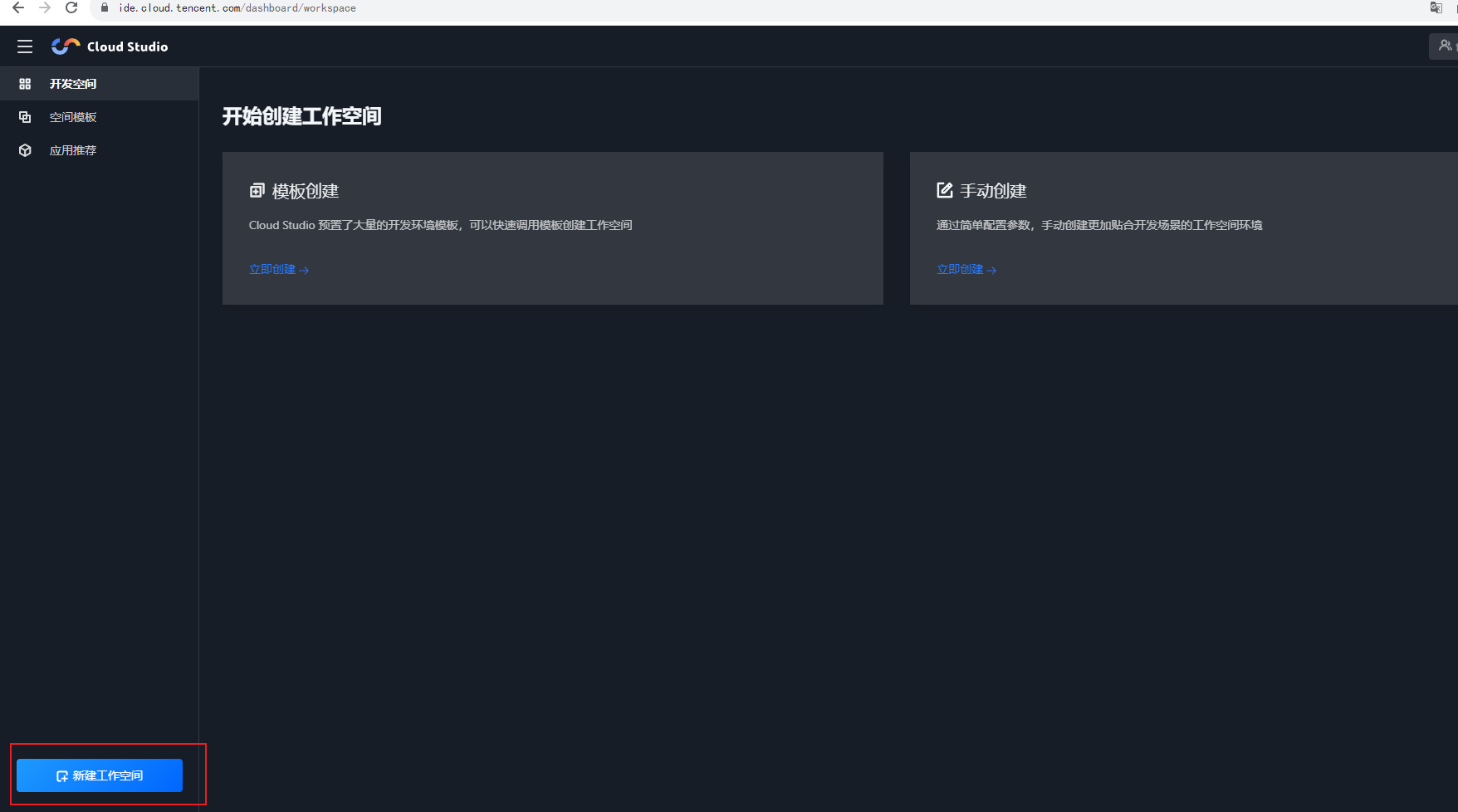
进入 Cloudstudio 的控制台页面
- 地址:https://ide.cloud.tencent.com/dashboard/workspace
点击创建工作空间
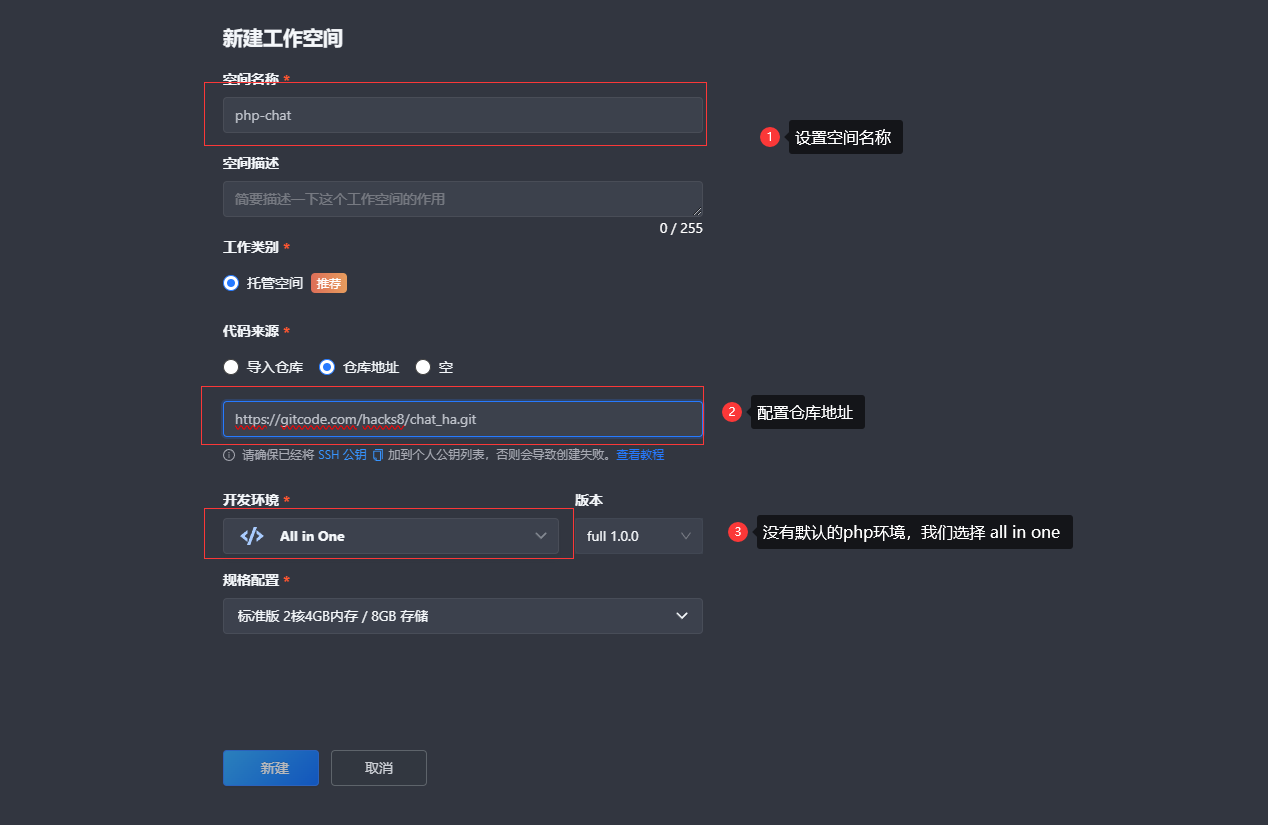
- 新建空间
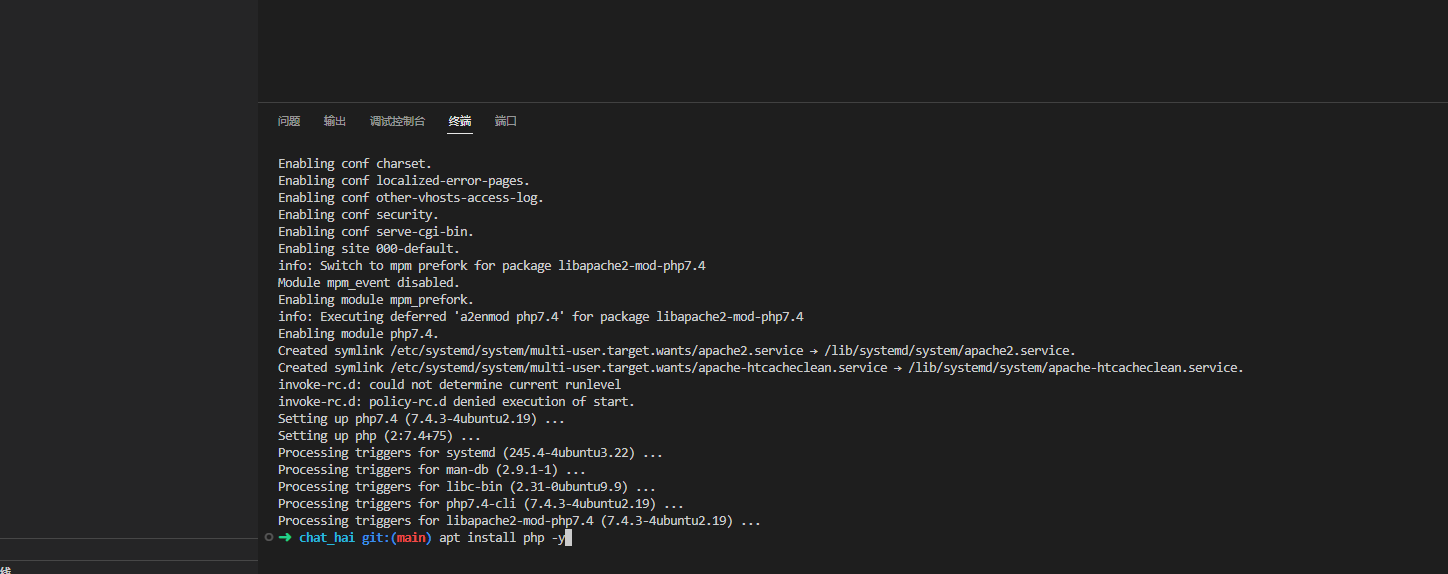
- 安装php环境
apt update
apt install php -y
- 1
- 2
- 启动服务
php -S 0.0.0.0:80
- 1
- 预览&体验
因为代码中已经默认配置了我的大模型 API,所以我什么都不用配置就可以直接体验,大家可以将 API 修改为自己的,就是访问自己的模型了
我对腾讯云HAI产品的看法
文章到这就是尾声了,不过我老是会去想,为什么会产生这个产品,我们又为什么要用它呢?
- 产生HAI的原因
在AI爆火的今天,AI模型的训练和推理计算需求巨大,需要大量的GPU和CPU资源支持。对于个人开发者来说,自行购置这些高性能服务器的成本是非常高的。而企业如果自己建设AI基础设施,也需要投入很多人力物力来管理和维护。与此同时,随着AI技术的普及,越来越多的企业和开发者想把AI无缝应用于自己的产品和服务中。但对他们来说,模型训练、框架安装和环境配置等技术难点仍然很高。这就为企业和个人带来很大使用和应用AI的门槛。
所以,面对这些困难,AI计算力平台的产生就是为了解决这类问题。它通过将AI基础设施打包成云端服务的形式提供给用户,无需用户自行预备硬件和软件资源,也无需处理各种技术细节,就可以实现快速部署和使用AI能力。这大大降低了用户的使用成本和门槛,也推动了AI技术在更广泛领域的应用。
所以总体来说,腾讯云HAI的出现,是为了更好地解决用户AI计算需求,助力AI技术实际应用的发展。它通过将AI整合成标准化的服务,有效降低了用户使用AI的难度和成本。
- 用HAI的原因
我认为腾讯云HAI平台给开发者带来以下几点主要价值:
-
提供强大的AI计算能力:开发者无需自行购买昂贵的GPU服务器,就可以通过平台获得海量的AI训练和推理资源。
-
降低技术门槛:平台已经预先封装和部署好各种常用的AI框架、库、模型等环境,开发者无需关注底层配置细节,可以更专注业务开发。
-
提升开发效率:开发者可以利用平台一键构建和部署各种AI应用,部署周期大幅缩短。同时提供可视化界面等开发工具,适应不同技能 。
-
降低项目成本:与自行建设AI基础设施相比,通过平台在线支付使用即可,性价比更高,避免了大规模资金和人力投入。
-
支持模型存储与版本管理:可以将训练好的模型直接上传到平台,实现高效的代码和数据共享。同时支持版本回退和数据集管理等功能。
-
更新频繁的模型和服务:开发者可以得到平台不断优化的硬件资源,并且随时获得主流模型的升级版本与新服务,与市场保持同步。
-
全球城市进行负载均衡:可以根据业务需要选择访问区域,享受全球覆盖的高性能网络,支撑大流量下的低延时响应。
腾讯云HAI通过简化开发流程和降低门槛,助力开发者以最佳状态开展AI项目研发与实验,这给开发者带来很大的价值。
文章小小总结与产品建议
算命未尝不可,但以科技进步的方式来“算”,也许会让我们对人生有更广阔的思考。这也正是我建立这个“AI算命大师”的初衷。希望通过这个案例,可以让更多人学习利用AI帮助解决实际问题。同时也欢迎大家提出意见,让这个“AI算命大师”能为更多人提供更专业更友好的服务。
根据本次的实践,我也总结了对HAI的一些思考。
发展趋势
- 计算能力增强: 随着GPU性能不断增强,平台应该提供更高性能的机器类型,以后或许是秒级训练。
(我的假设:或者通过多种训练过程的抽象,进行层的缓存,类似于docker,不知道是否可行) - 模型覆盖更广:目前平台支持的模型框架还比较有限,未来应该会支持更多主流框架和初创模型,满足更多应用场景。
- 开放能力: 未来或许应该支持开发者接入和对接更多第三方组件,丰富应用能力。
- …未完待续
不足
- 可视化体验: 希望逐步完善对所有
LLM的Web UI,目前还只有ChatGLM 6B - 帮助中心: 还没有整体的最佳实践,也没有全面的知识库和在线支持体制,希望尽快完善,可以帮助开发者更快上手。
- 计算资源还需要升级,同时开
web ui与api会造成显存不足 - 希望后续完善后续资源管理机制,减少用户重新部署成本。
总体来说,HAI代表了AI算力平台向更易用和全面方向的发展,但还有不断优化的空间,以适应不断增加的个性化需求。


